







梯度下降法
基本思想
- 梯度下降法其实就是一个随机加上根据梯度变化情况调整变化方向的方法。其中需要注意的是如果仅仅如同前文中按照导数为0的方式所求判断是否为最低点,是容易导致找到的是局部最优值,因此要当迭代loss减小的幅度不再变化可以认为停止在最低点。
- 学习率:在每次判断了方向后,需要进行变化,变化的幅度设置参数,通常设置为0.1,0.01等较小的数值,避免过度振荡。
- 导函数求解:
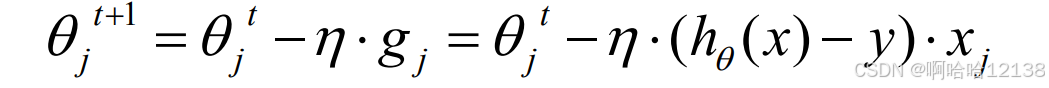
这里存在问题除了x,其他的内容都相同,会存在如果不同的维度的变化幅度不同,造成变化情况会较为不满足最佳的变化率。
- 剃度下降法步骤:
- 通过random随机生成部分数值
- 求出梯度,及时进行调整,如果梯度小于0,将theta往大调整。
- 判断是否收敛,收敛跳出循环,否则返回第二步继续。
常见梯度下降方法
三种梯度下降思想
- 全量梯度下降(Batch Gradient Descent)即在进行参数调整的时候,所有的样本都会参与其中,因此理论上更新的幅度较大,优点是每次更新会朝向正确的方向进行,缺点是当样本量过大时,在时间和内存上消耗过大。
- 随机梯度下降(Stochastic Gradient Descent)即在进行参数调整的时候,从训练集中随机选取一个样本进行学习,,这样的学习是非常快速的,但是缺点是每次更新可能不会按照正确的方向进行,因此会带来扰动。
- 小批次梯度下降(Mini-Batch Gradient Descent)即结合上述两种方法,每次更新在训练集中随机选择batch_size进行学习,降低了收敛波动性同时降低了参数更新的方差,使得其更新更加稳定。
三种梯度下降实现
- 全量梯度下降
import numpy as np
np.random.seed(1)
#通过设置随机种子,保证随机的可重复性
X = 2*np.random.rand(100,1)
y = 4 + 3*X + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)),X]
learning_rate = 0.0001
n_iterations = 10000
theta = np.random.randn(2, 1)
for i in range(n_iterations):
gradients = X_b.T.dot(X_b.dot(theta)-y)
theta = theta - learning_rate * gradients
print(theta)- 随机梯度下降
#随机梯度下降
X = 2*np.random.rand(100,1)
y = 4 + 3*X + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)),X]
#迭代的轮次
n_epochs=10000
m = 100
learning_rate = 0.001
theta = np.random.randn(2, 1)
for epoch in range(n_epochs):
for i in range(m):
#随机选取一个序号
random_index = np.random.randint(m)
xi = X_b[random_index:random_index+1]
yi = y[random_index:random_index+1]
gradients = xi.T.dot(xi.dot(theta)-yi)
theta = theta - learning_rate * gradients
print("_____________")
print(theta)- 小批次梯度下降
#迭代的轮次
n_epochs=10000
m = 100
learning_rate = 0.001
batch_size = 10
num_batches = int(m/batch_size)
theta = np.random.randn(2, 1)
for epoch in range(n_epochs):
for i in range(num_batches):
random_index=np.random.randint(m)
x_batch = X_b[random_index:random_index+batch_size]
y_batch = y[random_index:random_index+batch_size]
gradients = x_batch.T.dot(x_batch.dot(theta)-y_batch)
theta = theta - learning_rate*gradients
print("_______________")
print(theta)优化
归一化
- 常见的归一化方法:最大最小值归一化(可以将数据都化为0-1,缺点是若存在离群值则对整组数据影响较大)、标准归一化(无法化为0-1,但是离群值的影响较小)
- 可以使用sklearn中的方法进行标准归一化
from sklearn.preprocessing import StandardScaler
#标准归一化
data = [[1],[2],[3],[5],[5]]
scaler = StandardScaler()
print(scaler.fit(data))
print(scaler.mean_)
print(scaler.scale_)
print(scaler.var_)
#将标准归一化的结果进行展示
print(scaler.transform(data))正则化
- 即防止过拟合和欠拟合
- 本质牺牲模型在训练集上的正确率来提高推广能力,常用的惩罚项有两种:
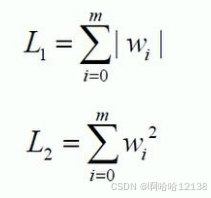
- Ridge方法实现(L2惩罚项)
#Ridge的两种方法
from sklearn.linear_model import Ridge
from sklearn.linear_model import SGDRegressor
x = 2 * np.random.rand(100, 1)
y = 4 + 3 * x + np.random.randn(100, 1)
#此处的alpha是正则系数,solver sag是随机梯度下降的方法
ridge_reg = Ridge(alpha=0.4, solver='sag')
#进行拟合
ridge_reg.fit(x,y)
#输出截距、系数
print(ridge_reg.predict([[1.5]]))
print(ridge_reg.intercept_)
print(ridge_reg.coef_)
#使用SGD来完成
sgd_reg = SGDRegressor(penalty='l2', max_iter=1000)
#y.ravel是将多维数组化为一维数组
sgd_reg.fit(x, y.ravel())
print('_____________')
print(sgd_reg.predict([[1.5]]))
print(sgd_reg.intercept_)
print(sgd_reg.coef_)- Lasso(L1惩罚项)
#Lasso
from sklearn.linear_model import Lasso
from sklearn.linear_model import SGDRegressor
X = 2 * np.random.rand(100, 1)
y = 4 + 3*X + np.random.randn(100, 1)
lasso_reg = Lasso(alpha=0.15, max_iter=30000)
lasso_reg.fit(X, y)
print(lasso_reg.predict([[1.5]]))
print(lasso_reg.intercept_)
print(lasso_reg.coef_)
#使用SGD来完成
sgd_reg = SGDRegressor(penalty='l1', max_iter=30000)
#y.ravel是将多维数组化为一维数组
sgd_reg.fit(x, y.ravel())
print('_____________')
print(sgd_reg.predict([[1.5]]))
print(sgd_reg.intercept_)
print(sgd_reg.coef_)
- 优化方法:Elastic-Net
#Elastic-Net
from sklearn.linear_model import ElasticNet
elastic_net = ElasticNet(alpha=0.4, l1_ratio=0.15)
elastic_net.fit(X, y)
print(elastic_net.predict([[1.5]]))
#SDG同上,只是将penalty = ‘elasticnet’

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









