






17讲
一个磁盘的若干盘面可以同时旋转,位于不同盘面上的磁头可以同时移动。一次磁盘操作可以一次性读写多个盘面上相同磁道位置的扇区,即一次性读写多个扇区。
不同柱面上的扇区是不能一次性读写完成的,因此不能缩短磁盘读写数据的时间。
顺序文件是按照某一键值的顺序(升序或降序)存储;
堆文件是无序记录文件,通常是按照记录的输入顺序存储的,但如要利用被删除记录的空间,则也可能将其插入到被删除记录的空间中。
散列文件是按照关于键值的某一散列函数值确定的位置进行存储。
聚簇文件是将一个表或多个表的数据集中在一起进行存储。
数据库以排序文件来组织,每当新增一条记录,将其写入溢出文件,DBA周期性地执行数据库命令以将溢出文件并入到排序文件中;
股票交易重要的是增删改数据的快速性,而不是检索速度,因此宜选用堆文件(无序文件)来组织数据。
数据库操纵,是对数据表的记录进行调整,如Update语句;
数据库重组,是对数据表的物理存储进行调整;
数据库重构,改变数据表的结构或者说改变模式的定义。
流水线技术不是RAID可能采取的技术。
RAID可能采取的技术,盘内奇偶校验与盘间校验相结合,比特级拆分。
Create Table语句有三个方面的功能:定义关系模式,定义完整性约束和定义物理存储结构;
读写16KB数据的时间:最小时间为0.52毫秒,最长时间为26.23 ms,平均时间为11.15ms
18讲
主索引是DBMS自动建立和维护的,关于其他数据项上的索引需要DBA来建立,DBMS可自动维护DBA建立的索引。
一个主文件只能有一个聚簇索引文件,但可以有多个非聚簇索引文件;
用B+树建立主索引,非叶结点某索引项X的左侧指针指向键值<X记录所在的索引文件存储块;叶结点某索引项X的左侧指针,指向键值=X记录所在的主文件存储块;
已知一个存储块可存放主文件的5条记录,或存放索引文件的20个索引项。已知主文件有n条记录, 则创建稠密索引和稀疏索引各需要的存储块数是n/20和n/100。主文件有n条记录,则索引键值个数可能有n个,即索引项个数可能有n个,一块可存放20个索引项,故创建稠密索引需要的存储块数是n/20。而稀疏索引可以是为每一主文件的磁盘块建立一索引项,主文件n条记录,每存储块可存放5条记录,因此共需n/5个磁盘块,即有n/5个稀疏索引的索引项,一块可存放20个索引项,故创建稀疏索引所需要的存储块数是n/5/20,即n/100。
虽然索引文件存在与否不改变主文件的物理存储,但更新主文件数据时要同步更新所有的索引;
索引文件比主文件存储小很多,通常先查索引再找主文件速度会快很多;
索引文件存在与否不改变主文件的物理存储,所以索引可以随时被删除并重建;
稠密索引 通常是按 索引字段值 进行排序的一个有序文件。稠密索引的索引项的个数x与主文件索引字段上的不同值个数y有密切关系,稠密索引要求x>=y,即至少要包含主文件索引字段上的每一个不同值;主索引通常是关于主码的稀疏索引;“每一存储块有一个索引项”通常是稀疏索引。
稠密索引对于Table中的每一个记录,并不总是有一个索引项,而对于Table中索引字段的每一个不同值总是有一个索引项;
稀疏索引是对于Table中的部分记录有索引项。稀疏索引是对于Table中索引字段的部分取值有索引项。主索引是对每一个存储块都有一个索引项;
B+树索引的所有叶子结点构成主文件的一个排序索引;B+树中只有叶子结点的索引项包含指向主文件存储块的指针。B+树的索引字段值可以重复出现于叶结点和非叶结点中。B树是所有结点的索引项才能覆盖主文件的完整索引,但B+树仅需要所有叶子结点的索引项,即可覆盖主文件的完整索引。
用B+树可义建立非候选键属性/候选键属性上的稠密索引;主文件可以按该属性排序存储,也可以不按该属性排序存储;用B+树可义建立候选键属性上的稀疏索引,但主文件必须按该属性排序存储;
B+树合并可能会调整左右相邻结点的索引项,不一定会增加索引存储块的数目。
主索引 是按 索引字段值 进行排序的一个 有序文件。
主索引是关于主码的稀疏索引;
主索引是对每一个存储块都有一个索引项;
主索引通常建立在有序主文件的基于主码的排序字段上;主索引并不能保证对索引字段上的每一个不同值有一个索引项,因其通常是稀疏索引;
主索引通常是确定“表”数据物理存储顺序的索引。
已知存储块大小为4096字节,在整型属性(一个整型数值占有4个字节)上建立B树索引,一个指针占有8个字节,则该非叶结点存储块最多能有204个索引项和410个指针。
19讲
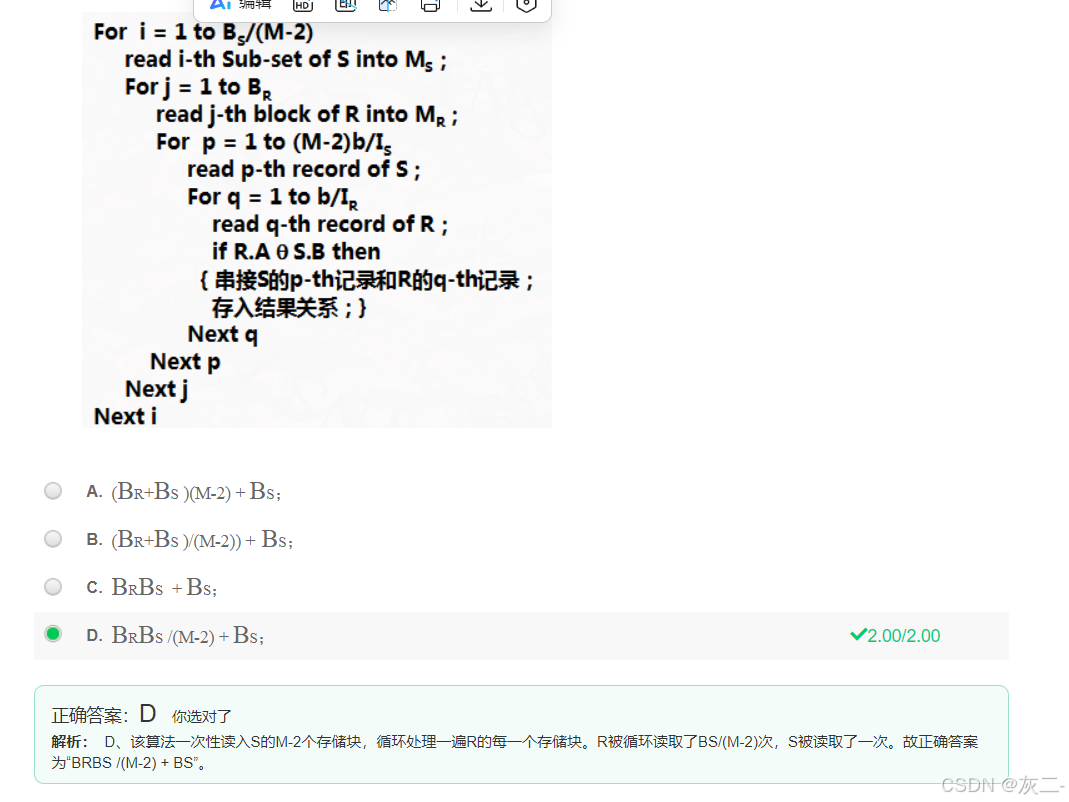
选择操作和包上的并操作,在任何时候都可以用一趟算法实现之。
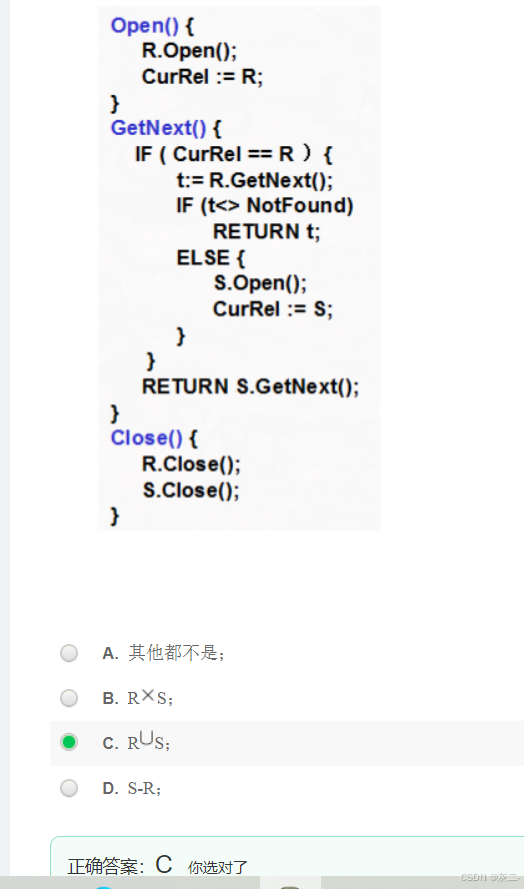
A. R∩S

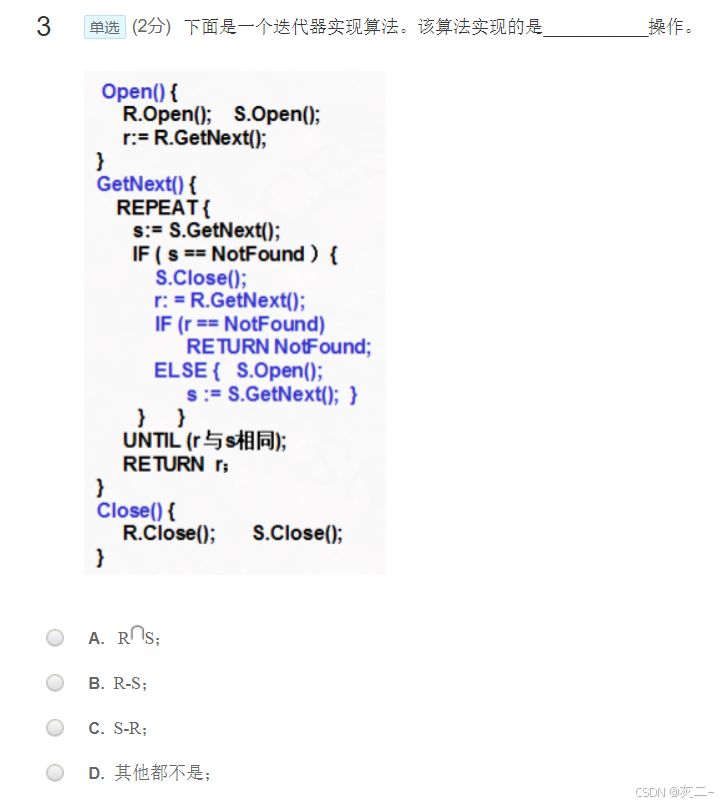
此迭代器算法实现的是R-S。

解析: A、该选项是不正确的,如果R是聚簇存储的且使用索引,则查询代价=B(R)/V(R,A)=1000/100=10个I/O。
B、该选项是不正确的,如果使用索引,则其执行代价通常是远小于B(R)的。
C、该选项是正确的,聚簇存储且不使用索引,查询代价为B(R)。
D、该选项是不正确的,因为如果R是非聚簇存储的,则其执行代价可能是T(R)=20,000,此时要看R是聚簇存储的还是非聚簇存储的。

假设关系R的元组个数为T(R),元组的大小为I(R),存储块的大小为b,B(R)=T(R)*I(R)/b。关于表空间扫描算法,表空间扫描算法的复杂性可能为B(R),也可能为T(R);
如果是聚簇关系(一个块中仅是该关系的元组),则其复杂性为B(R);
但如果是非聚簇关系,如果一个块中多个关系的元组混合存放,则可能一个元组在一个块中,则其复杂性为T(R)。

解析: A、该选项说法是不正确的,有些分组聚集计算是在建立起完整的数据结构后才能进行,但有些是可以的。 B、非精确的讲,算法的应用前提是B(R) < =M,其中M为可用内存块数,B(R)为R中数据所占用的磁盘块数。该选项说法是正确的,只要内存块数足以装得下整个关系,即可执行。更严格的说,只要内存块数足以装得下关系中所有的分组及其每一分组上的不同值,即可执行。 C、该选项说法是正确的,可以通过散列,将具有相同分组值的元组散列到同一内存块中。 D、该选项说法是正确的,需要首先对R的所有数据建立内存数据结构(将相同组的数据聚集在一起),然后再分组聚集计算即可。


B、该选项说法不正确,不需要首先对R的所有数据建立内存数据结构,可以边执行边建立即可。

以上算法是一次性将R完整的读入到内存,将S一块一块的读入内存进行处理,因此只要BR<M,则无论S有多大都能被处理,因此“BS> BR,BR <M”是正确的。
20讲

解析: A、少量内存排序大规模数据,首先是要划分子集合并进行子集合排序。划分原则是子集合块数<=可用内存块数,然后将其装入内存并进行排序后再写回磁盘。此一步骤四个方案都满足要求,且磁盘读写次数都是70*2=140次(读一次,写一次)。关键是多路归并的磁盘读写次数的差异。方案I,先做三路归并(3个子集合*(8块子集合+8块子集合+6块子集合)*2次=44次—因有一个集合为6块),再做7路归并(70*2=140次),所以总的磁盘读写次数为140+140+44=324次。方案II,先做五路归并(5个子集合*7块每个子集合*2次=70次,再做六路归并(70*2=140次),所以总的磁盘读写次数为140+140+70=350次。方案III,先做七路归并(7个子集合*8块每个子集合*2次=112次,再做三路归并(70*2=140次),所以总的磁盘读写次数为140+140+112=392次。方案IV,先做五路归并(5个子集合*8块每个子集合*2次=80次,再做五路归并(70*2=140次),所以总的磁盘读写次数为140+140+80=360次。通过比较:该选项方案I的磁盘读写次数最少。
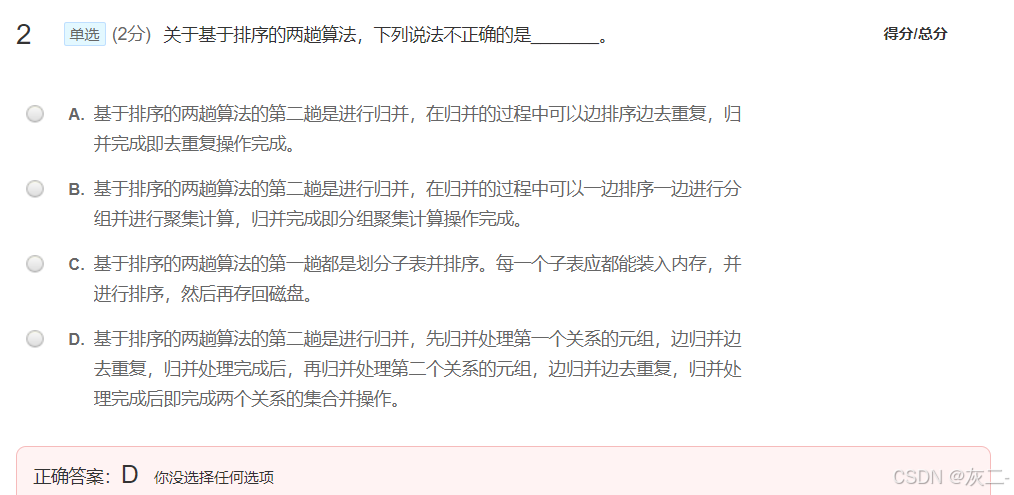
D、该选项说法是不正确的,按该选项说法是不能完成集合并操作的,集合并操作的关键是在归并过程中是否存在R与S相同的元组,相同的元组只保留一个。应该将R与S同时进行归并,并区分是R的元组还是S的元组,然后判断R的元组和S的元组是否相同,只保留一个。

解析: B、基于排序的算法总是可以均匀地划分子表(即每个子表的大小都一样,除最后一块外),它是先划分子表,再一个一个将其装载入内存进行排序,然后再存回磁盘,所以总是均匀是可以做到的;基于散列的算法不能保证总是均匀地划分子表,它依赖于散列函数的选择以及主文件数据的分布,通常情况下可以做到准均匀的分布,但不能保证总是均匀分布。故该选项的说法是正确的。

解析: C、该选项说法是正确的。第一趟散列的目的是使数据子集具有某一种特性(如具有相同的散列值),以便于将“大规模数据全集上的操作”等价地 转换为“(数据子集上操作)的简单并集”。而第二趟散列的目的是提高数据处理的速度,散列到不同内存块中,使得比较时快速地和少量内存块中的数据进行比较。

解析: C、该选项说法是正确的。
排序算法是先划分子表,独立处理子表(第一趟),然后再对各子表进行关联性处理(第二趟);散列算法是先从关联性角度处理,形成子表(第一趟),然后再独立处理每一个子表(第二趟)。

解析: C、该选项说法是不正确的,正确的说法是“散列过程中,R必须以A属性值作为散列函数的键值,S必须以B属性值作为相同散列函数的键值”。

D、该选项说法是不正确的,如果选择与第一趟相同的散列函数,则相当于没有散列,因为同一散列子表俱有相同的散列值。
21讲
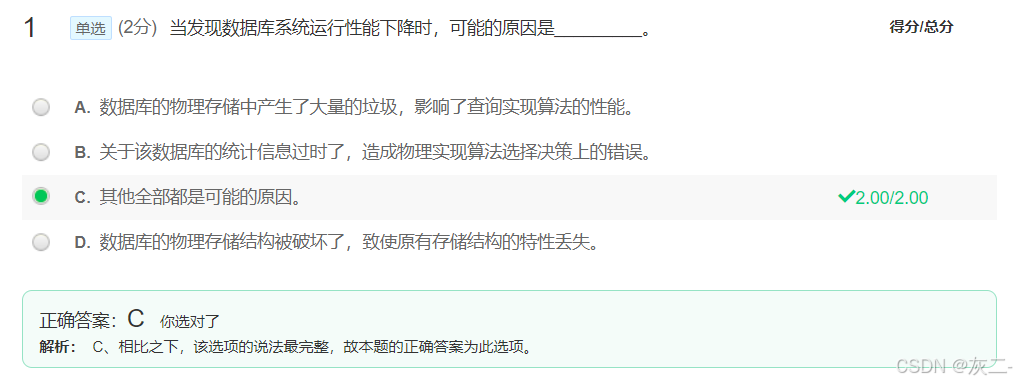

已知关系Student(S#, Sname, Sage, Sclass),Course(C#, Cname, Credit, Cteacher),SC(S#, C#, Score)。给定SQL语句如下:
“SELECT Score FROM Student, Course, SC WHERE Cname=‘Database System’and Sname=‘张伟’ and Student.S# = SC.S# and Course.C#=SC.C#”
请用语法树给出其最终的优化结果,正确的是____________。
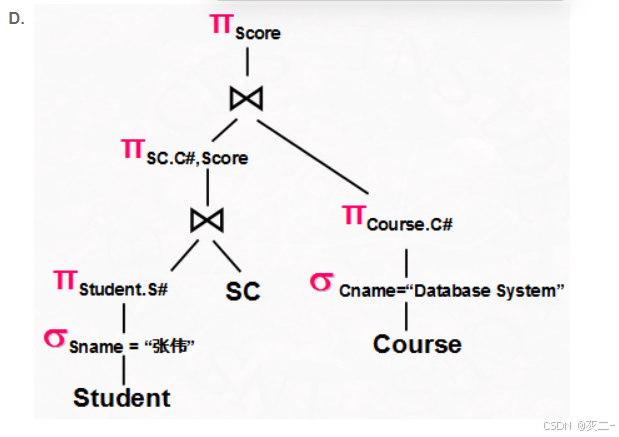

解析: C、R和S的连接在元组Y上值相等的概率为1/max(V(R,Y), V(S,Y)),再乘以R和S的元组的组合数目T(R)*T(S)。按上式计算正确的只有该选项。

A 等值条件的估计概率为1/V(R,A),不等值条件的估计概率为1/3,这里是或条件。故代价估计式为T(R)[1- (1- 1/V(R,A))(1-1/3)],计算值为33667。如果按简单方法估计则为T(R)/3=100000/3=33333
A 33667

解析: C、等值条件的估计概率为1/V(R,A),不等值条件的估计概率为1/3,又是与条件,二者概率应相乘。故代价估计式为T(R)/(V(R,A)*3)。计算值为167。

解析: B、不等值条件的估计概率为1/3。括号中的或运算的估计概率为 [1- (1- 1/3)(1-1/3)]=0.5555。外层是与条件,代价估计式为T(R)*1/3*0.5555,计算值为18518。 故此选项的值是最接近的。
逻辑查询优化是关系代数操作次序的优化;物理查询优化是关系代数操作实现算法选择的优化。

解析: C、该选项说法是不正确的,虽然从逻辑上来看,笛卡尔积操作的次序不影响中间结果元组的数目,但其次序却影响物理查询优化的效率,是需要考虑的。

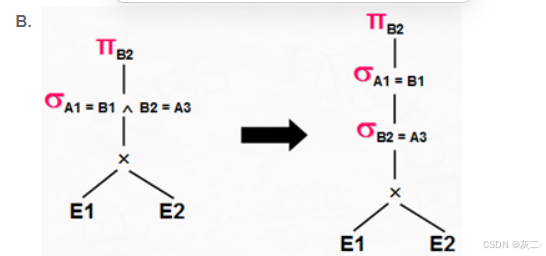
解析: C、该选项是不正确的,因为先做差运算再投影,和先投影再做差运算,结果可能不一样,你可比较以下:假设上式的n=3,即投影三个属性,而E1和E2有6个属性。六个属性上的差运算和三个属性上的差运算结果可能是不同的。
假设A1,…,An是E1相关的属性,B1,B2,…,Bm是E2相关的属性。下列哪个变换是正确的_______。
22讲
封锁机制是并发控制的主要方法;

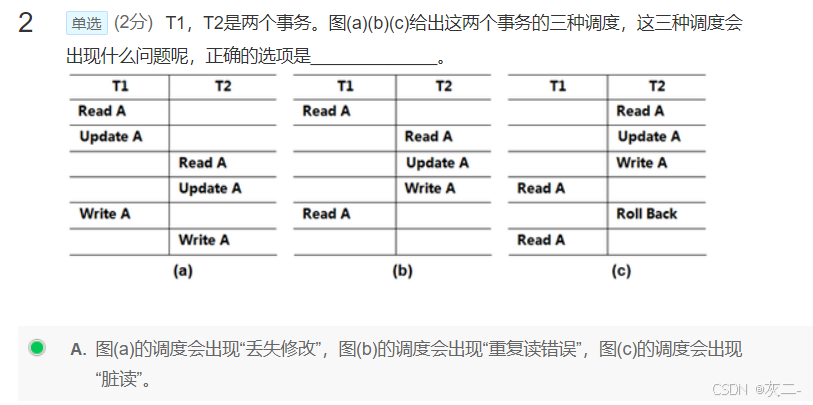
A、该选项的说法是不正确的,可串行化的调度可以是“非冲突可串行化”的,冲突可串行化比可串行化要严格。 B、该选项的说法是不正确的,两阶段封锁法一定可以产生可串行化的调度,但可能会产生死锁现象。 C、两阶段封锁法是可串行化的并行调度算法;该选项的说法是正确的,两阶段封锁法一定可以产生可串行化的调度。 D、该选项的说法是不正确的,可串行化的调度一定是正确的并行调度,反之则不然。

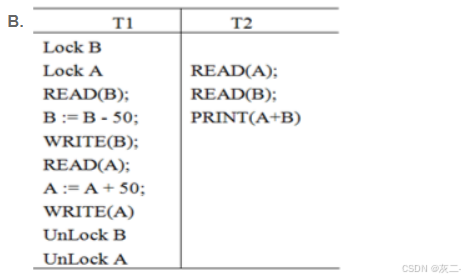
B、该选项是不正确的,T2不符合两段封锁法协议的“读写数据库数据前需要加锁”的规定。
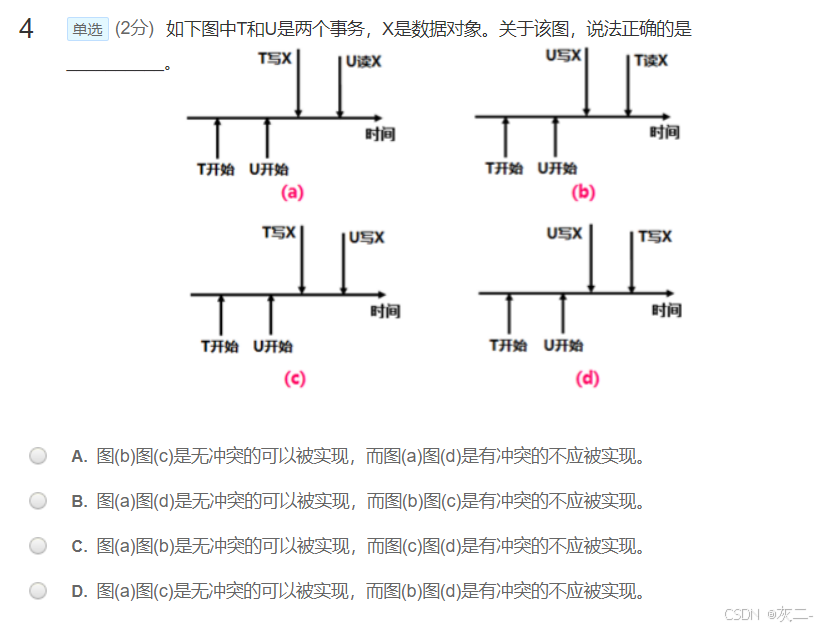
解析: D、图(a)先执行的事务先写,后执行的事务后读,无冲突应被实现。图(b)先执行的事务后读,后执行的事务先写,此为过晚的读,有冲突不应被实现。图(c)先执行的事务先写,后执行的事务后写,无冲突应被实现。图(d)先执行的事务后写,后执行的事务先写,有冲突不应被实现。由此可知该选项是正确的。

解析: A、TS方法和VA方法都是以撤销事务并重启事务来解决事务之间的冲突;该选项的说法是正确的 B、该选项的说法是不正确的,TS方法是为每一数据库元素保存一个读时间戳和写时间戳,以便于事务时间戳与数据库元素的时间戳进行比较判断冲突;而VA方法则是为每一个事务保存一个读数据集合和一个写数据集合,以便于数据集合之间的比较判断冲突,故该选项的说法是不正确的。 C、TS方法和VA方法都是利用时间戳表征事务的启动时刻,表征事务的执行次序;该选项的说法是正确的 D、TS方法是比较事务的时间戳与数据库元素的时间戳来判断是否有冲突,而VA方法是通过比较两个事务的读写数据集合是否有交集来判断是否有冲突;该选项的说法是正确的
两阶段封锁法一定会产生可串行化的调度,保证数据更新的一致性。
两阶段封锁法有可能会产生死锁现象的。
可串行化的调度一定是正确的并行调度,反之则不然。

解析: A、解析:总的循环次数是5次。每次循环过程中,可能会产生一个事务,也可能不会产生事务。因此, DBMS会产生<=5个事务。因此该选项是正确的。

S不是冲突可串行化调度,但却是可串行化调度,是正确的并行调度。

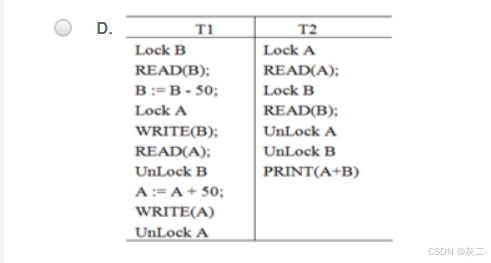
符合两段封锁法协议,即解锁段中没有加锁,加锁段中没有解锁,读写数据前需要加锁。PRINT是对内存数据操作,不涉及加锁解锁问题。
若要使事务的执行是可恢复的,则对有写有求的数据对象加排他锁后,须在该事务提交时刻解锁才能保证可恢复性。
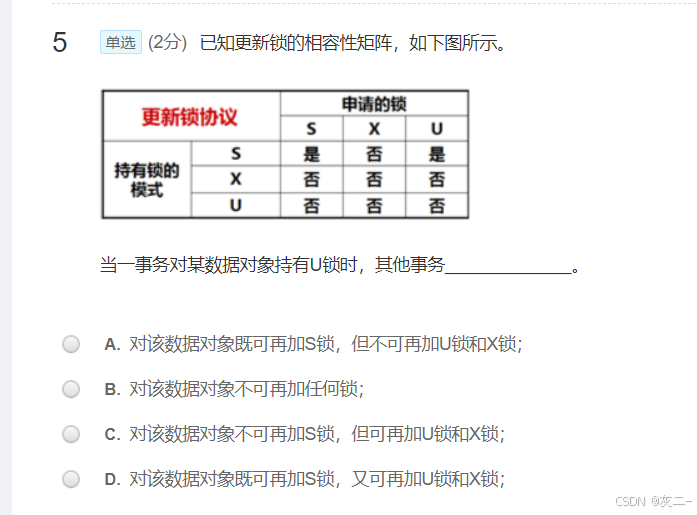
解析: B 当一事务对某数据对象持有U锁时,其他事务对该数据对象不可再加任何类型的锁。

若事务T对数据R已加X锁,则其它事务对R不能加任何锁;
锁被分为X锁和S锁。X锁又称为写锁、排他锁,而S锁又称为读锁、共享锁。一个事务对数据已经加上排他锁,则不允许任何事务再对其加任何锁。
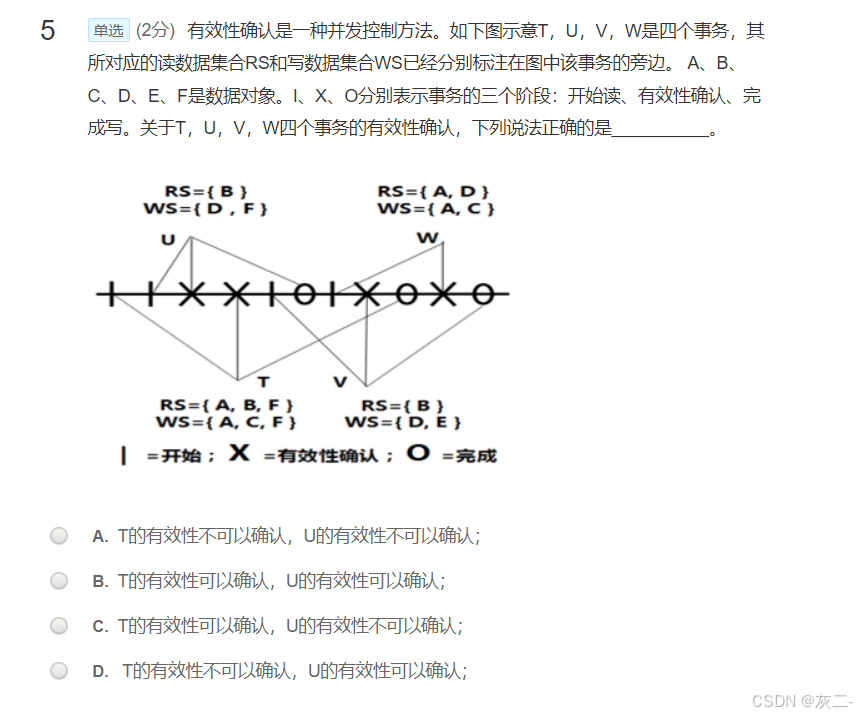
解析: D、T的有效性不可以确认,U的有效性可以确认;图中,U进行有效性确认之前,没有任何事务进行过有效性确认,所以U的有效性可以直接确认。T的有效性确认,由于T开始于U完成之前,且U的完成在T的有效性确认之后,所以要比较RS(T)∩WS(U)和WS(T)∩WS(U)是否为空,若都为空,则无冲突,T的有效性可以确认,否则不可确认。由图知:两个交集均不为空,所以T的有效性不能确认,T将被撤销并重启。

S1是不可串行化调度,S2 是可串行化调度。
可串行化是指一个并发调度可以转换为一个等效的串行调度,即其结果与某个串行执行的结果相同。
调度S1:T1和T2的操作之间存在数据依赖(T1对A的操作影响T2对B的操作,T1对B的操作影响T2对C的操作)。这种依赖关系使得S1不能简单地转换为一个串行调度,因此S1是不可串行化的。
调度S2:T1和T2的操作之间没有数据依赖,可以重新排序而不改变结果。例如,可以先执行T1的所有操作,再执行T2的所有操作,或者反过来。因此,S2是可串行化的。
23讲

答案:D 操作次序:ABC
日志文件是用于记录对数据的所有更新操作;
检查点是DBMS强制使内存DB Buffer中的内容与介质DB中的内容保持一致的时刻点。
事务故障仅影响事务本身,可通过撤销事务和重做事务来进行恢复。介质故障在将备份恢复到系统中后还需要利用运行日志才能恢复到故障点时刻的正确状态。
DBMS管理数据库缓冲区有四种策略:No Steal, Steal, No Force, Force。
Force,内存中的数据最晚在commit的时候写入磁盘。
No force,内存中的数据可以一直保留,在commit之后过一段时间再写入磁盘。
No steal,不允许在事务commit之前把内存中的数据写入磁盘。
Steal,允许在事务commit之前把内存中的数据写入磁盘。
效率较低但不会出现问题的策略组合是No Steal+ Force
效率最高最常用但会出现问题的策略组合是Steal + No Force。

解析: C、本题需要理解这四种策略。
Force + No Steal可以保证事务的持久性,不需恢复;
No Steal+No Force,会出现当发生系统故障时,已经提交事务却并未写入磁盘等问题,所以需要Redo型日志,以便重做事务保证持久性;
Steal + Force,会出现当发生系统故障时,未提交事务提早写入磁盘等问题,所以需要Undo型日志,以便撤销事务保证持久性;
而Steal + No Force,则在系统发生故障时,既会出现已经提交事务却并未写入磁盘等问题,也会出现未提交事务提早写入磁盘等问题,所以需要Undo/Redo结合型日志既执行已完成事务的重做,又执行未完成事务的撤销,才能保证持久性。
Undo型日志保留的是旧值,而Redo型日志保留的是新值,Undo/Redo结合型日志是既保留旧值又保留新值;
Redo型日志是先将Commit记录写入日志,再将数据写回磁盘OUTPUT;
Undo型日志是先将数据写回磁盘OUTPUT,再将Commit记录写入日志;
Undo/Redo结合型日志则可以不限制它们的次序。
关于用Undo型日志和Redo型日志进行数据库恢复,
Undo型日志是从日志的尾部开始恢复,按日志记录的反序处理,直至遇到第一个检查点为止结束。Redo型日志是按日志记录的正序处理,由前向后进行。Redo型日志是先从日志尾部开始由后向前扫描直至遇到第一个检查点,然后自该检查点开始恢复,按日志记录正序处理,直至日志记录的尾部结束。
用Redo型日志恢复是对已完成的事务,将日志记录的值写回磁盘;而对未完成的事务,跳过;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









