






第1章 初识Java与面向对象程序设计
1.1 Java概述
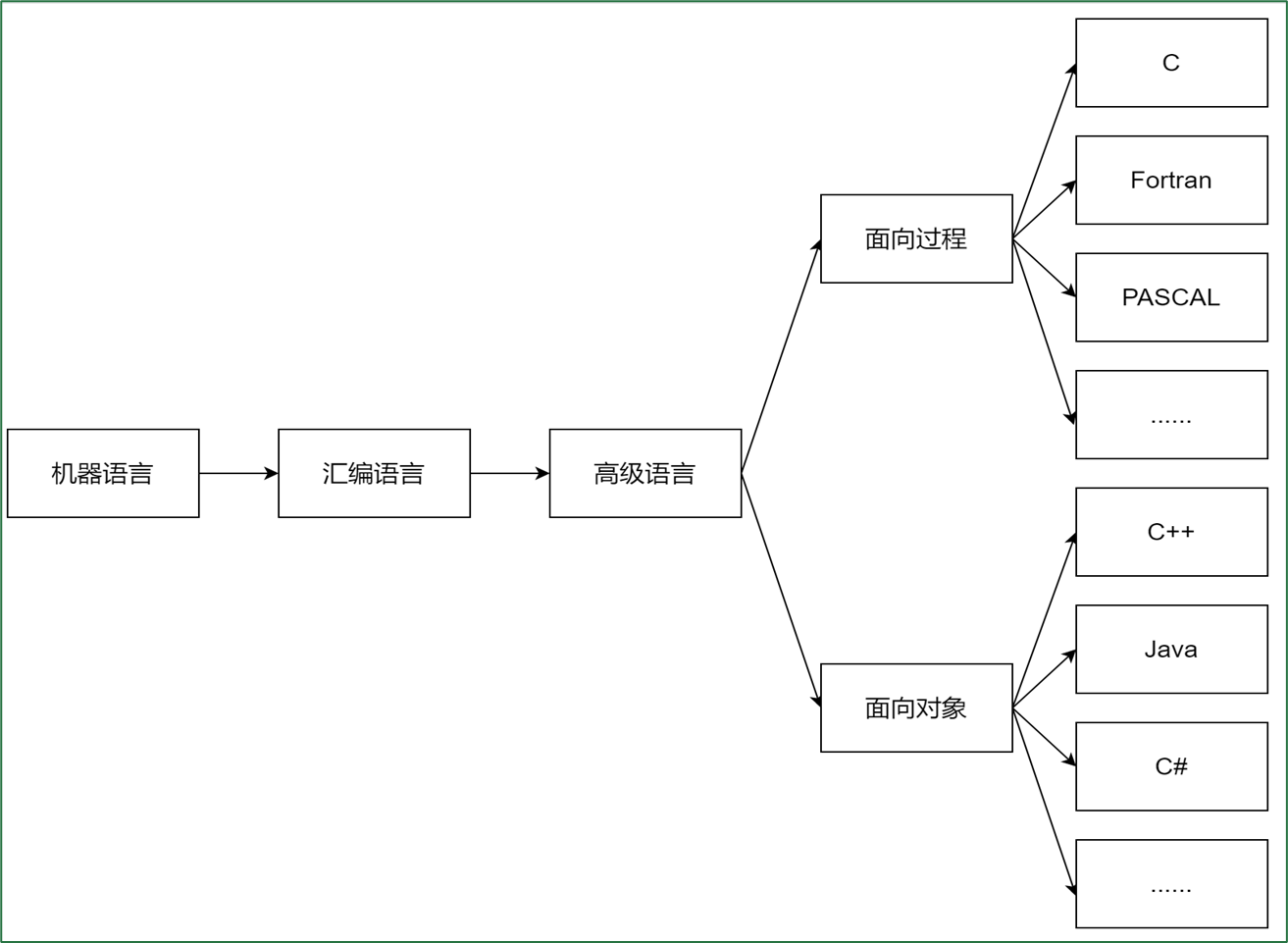
计算机编程语言发展史:机器语言→汇编语言→高级语言
Java语言特点:
Java是一门简单的、面向对象的优秀编程语言,
它具有跨平台性、可移植性、安全性、健壮性、编译和解释性、高性能和动态性等特点,
支持多线程、分布式计算与网络编程等高级特性。
1.2 面向对象程序设计思想
1.3 Java开发环境搭建
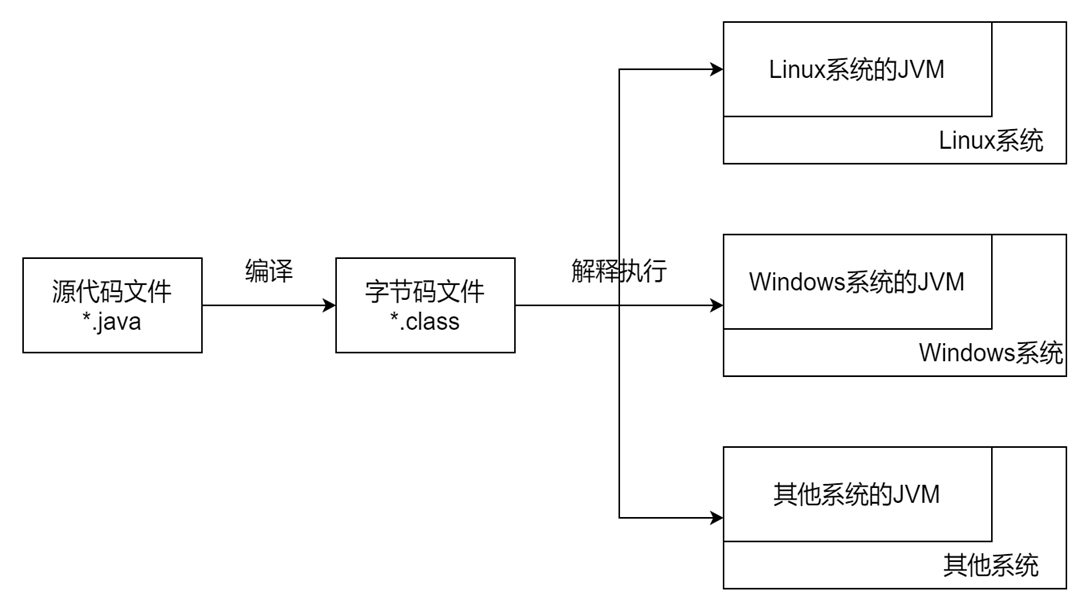
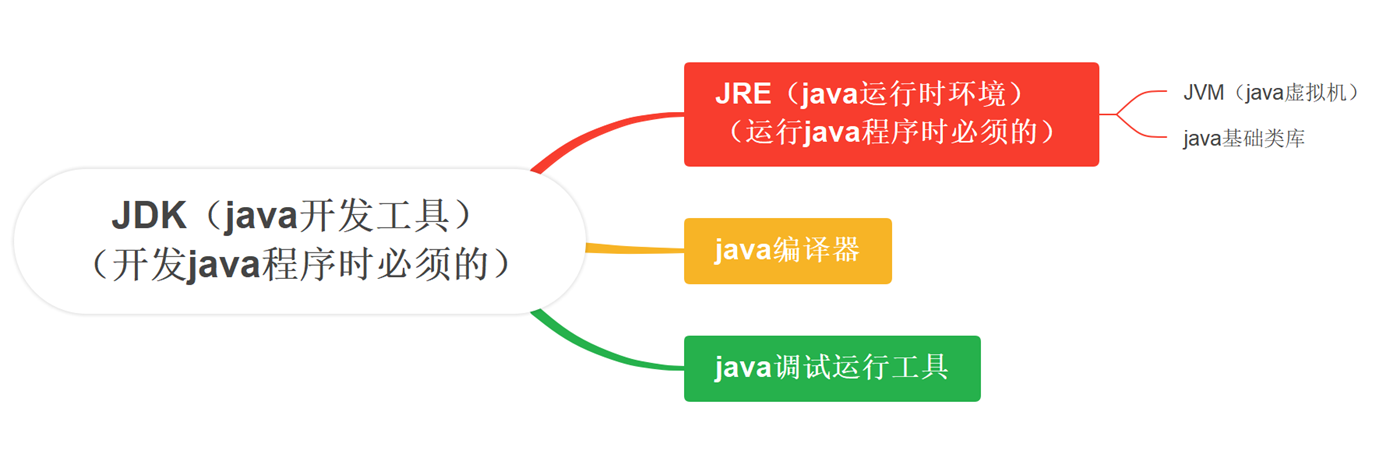
JRE(Java Runtime Environment)是Java程序的运行环境,
它包含了java虚拟机、Java基础类库,当一台计算机想运行Java编写的程序时,至少需要安装JRE。
JDK(Java Development Kit)是Java开发工具包,
它包含了JRE,同时还包含了编译器以及很多Java程序调试和分析的工具,是提供给开发者用来编写Java程序的。
如果想运行Java程序,在计算机中安装JRE即可。
如果想开发Java程序,就需要在计算机中安装JDK。
1.3.1 JDK安装
官网下载任意版本:https://www.oracle.com/java/technologies/

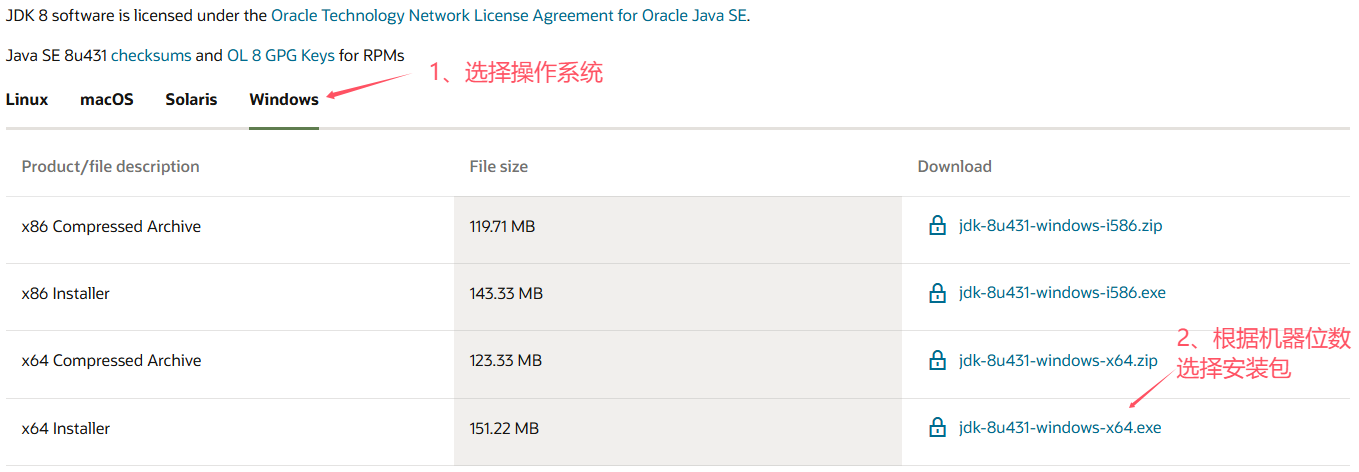
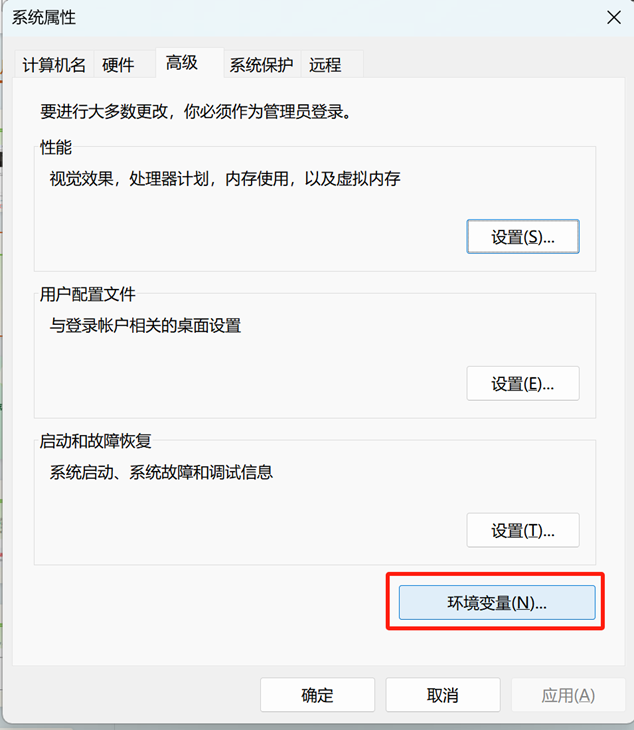
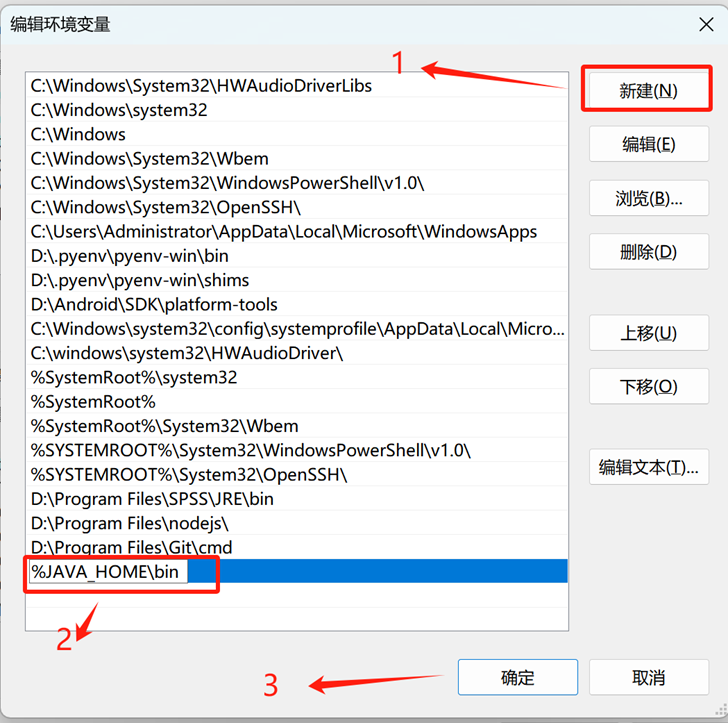
1.3.2 JDK环境变量配置
一、新建环境变量
JAVA_HOME
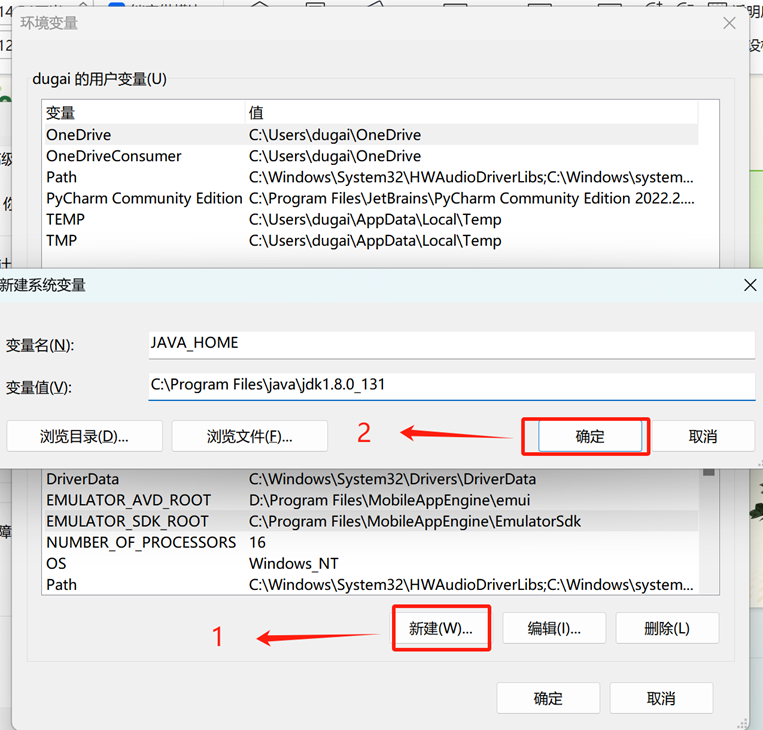
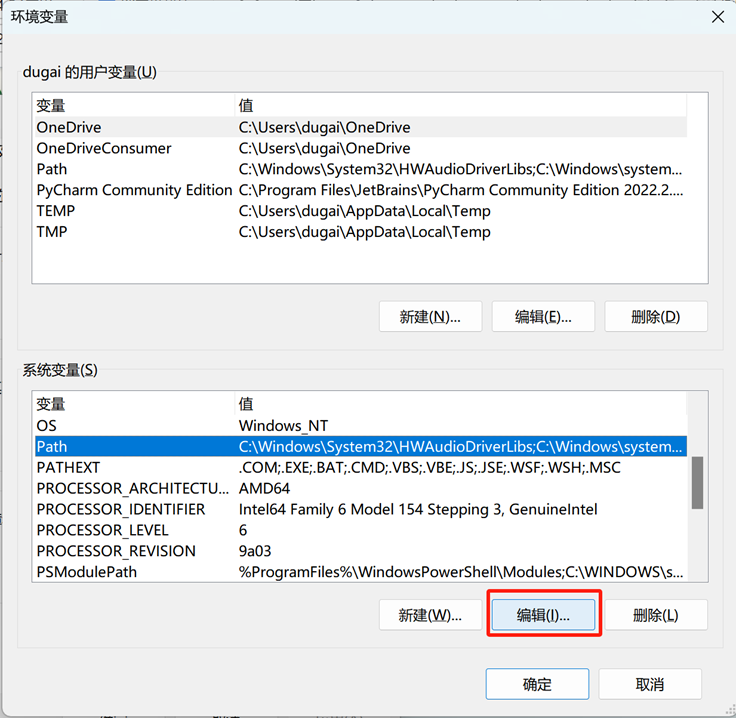
二、编辑 PATH,加入 java 的 bin 目录
%JAVA_HOME\bin
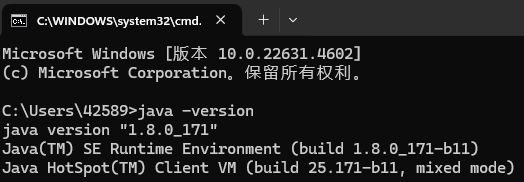
三、按 win + R 输入 cmd 在命令行窗口输入 java -version 查看 java 版本
java -version
1.4 第一个Java程序: HelloWorld!
1、用记事本编写Java程序
新建HelloWorld.java:
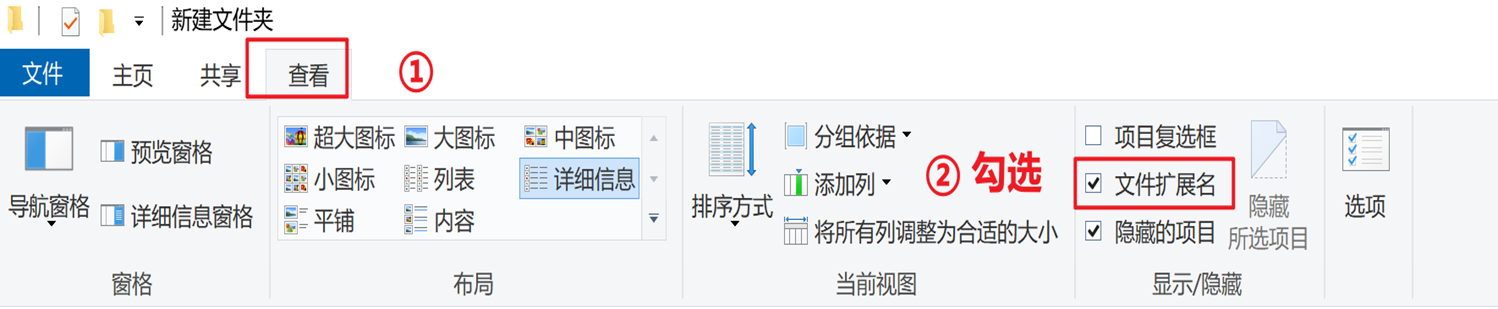
在任意一个位置新建一个文本文件,此时如果在你的计算机中显示的文件名不是“新建文本文档.txt”的话,就说明你的系统没有开启文件扩展名显示。
以Windows 10系统为例,单击“查看”,勾选“文件扩展名”,即可显示出文件的扩展名,如图所示。之后,将新建的文本文件名称修改为“HelloWorld.java”。
右击HelloWorld.java文件,在弹出的快捷菜单中选择“编辑”命令,将代码输入文件中。
public class HelloWorld {
public static void main(String[] args) {
System.out.println("HelloWorld");
}
}
直接在当前文件管理器上方输入cmd并按回车键,打开命令行。
在命令行中输入javac HelloWorld.java并按回车键进行编译,如果没有任何输出,说明编译成功。
再输入java HelloWorld并按回车键,查看程序运行结果,如图所示。

代码解析:

二、编写代码时,依然需要注意以下书写规范。
- 类名的首字母大写,单词之间的第一个字母也需要大写。
- 类名只能由数字、字母、下划线、美元符号$组成,并且第一个字符不能是数字。因为类名要与文件名一致,因此文件名也需要遵循这个规则。
- 一个Java源文件中至多只有一个类能用public声明,并且public修饰的类必须和文件名保持一致。
- 大括号用于划分程序的各个部分,方法和类的代码都必须以“{”开始,以“}”结束。
- 代码中每条语句以英文的分号“;”结束。
- Java代码对字母大小写敏感,如果出现了大小写拼写错误,程序无法运行(例如string)。
注释就是程序员为程序代码阅读者作说明的,是一种提高程序可读性的手段。
源文件编译后,注释不会出现在字节码文件中,即Java编译器编译时会跳过注释语句。
Java中的注释分为单行注释、多行注释、文档注释三种:
1、单行注释,符号后面的内容均为注释
// 注释文本
2、多行注释,注释内容可以随意换行
/*
注释文本
注释文本
*/
3、文档注释,注释中包含一些说明性的文字及一些JavaDoc标签
/**
* @author 雪银星月
* @version 1.0
*/
1.5 Java常用开发工具
Eclipse和IntelliJ IDEA(通常简称IDEA)都是流行的Java集成开发环境(IDE),但它们有各自的特点,适用于不同需求的开发者。
如果你是一个经验丰富的开发者,喜欢高度可定制的工作环境,并且倾向于使用免费工具,那么Eclipse可能是更好的选择。
如果你追求更高的生产力,享受更智能的编码辅助,愿意为额外的功能支付费用,或者正在寻找一个更适合初学者的IDE,那么IntelliJ IDEA Ultimate可能更适合你。
1.5.1 Eclipse
- 性能与资源占用:相对轻量级,启动速度较快,适合配置较低的计算机。处理小型项目时表现优异。
- 用户界面:定制性高,可以调整布局、安装各种插件来适应个人的工作流程,但初学者可能觉得不够直观。
- 智能感知与编码辅助:提供基本的代码补全和重构工具,对于复杂的语言特性支持可能不如IDEA全面。
- 调试与测试:拥有强大的调试工具,包括断点设置、变量检查、表达式求值等,并且很好地集成了JUnit等测试框架。
- 插件生态系统:拥有庞大的插件市场,几乎涵盖了所有你能想到的功能扩展,使得Eclipse非常灵活。
- 社区与支持:作为一个开源项目,有一个活跃的社区,可以获得大量的文档、教程和帮助。许多企业级应用和框架都基于Eclipse构建。
- 价格:完全免费,是开源软件。
- 跨平台支持:支持Windows、macOS和Linux,具有良好的跨平台一致性。
1.5.2 IntelliJ IDEA
- 性能与资源占用:相对较重,尤其是Ultimate版本,提供了更多功能和插件支持。在处理大型项目或复杂代码库时可能会更消耗资源。
- 用户界面:现代化且直观,设计上更加用户友好,易于导航,学习曲线较浅,特别适合新手。
- 智能感知与编码辅助:以其强大的代码分析和智能感知著称,能够提供更深入的代码理解、自动完成、错误检测和快速修复建议,支持更广泛的重构操作。
- 调试与测试:具备优秀的调试能力,测试运行器和覆盖率工具更加直观易用,对测试驱动开发(TDD)的支持尤为出色。
- 插件生态系统:虽然插件数量不及Eclipse多,但质量较高,官方维护良好,确保了插件的稳定性和兼容性。
- 社区与支持:由JetBrains公司开发,提供专业的技术支持。Ultimate版包含了更多的商业特性和高级功能,适用于专业开发团队。
- 价格:Community版本免费,适用于非商业和个人使用;Ultimate版本则是付费的,但提供了更多的功能,如Web开发、数据库工具等。
- 跨平台支持:同样支持Windows、macOS和Linux,在不同平台上的一致性体验略优于Eclipse。
总结
在学习Java的过程中,我深刻体会到了面向对象编程(OOP)思想对软件开发的深远影响。通过将现实世界中的实体抽象为类,不仅使代码结构更加清晰、易于理解和维护,还极大地提升了开发效率。这种编程范式帮助我们更好地模拟和处理复杂的业务逻辑,使得程序设计更加直观和模块化。
掌握Java的基础语法后,编写简单程序的过程激发了我对如何运用代码解决实际问题的浓厚兴趣。每一个新功能的实现,每一次bug的修复,都让我感受到编程的魅力和成就感。这不仅仅是技术上的进步,更是思维能力的提升,培养了我分析问题、分解任务和创造性解决问题的能力。
同时,我也意识到开发环境的搭建和调试技巧对于后续的学习和项目开发至关重要。一个稳定且高效的开发环境是编写高质量代码的前提,而熟练掌握调试工具和技术则能显著提高解决问题的速度和准确性。打好这些基础,不仅能避免许多不必要的错误,还能让我的代码更加健壮和优化,从而为未来的项目开发打下坚实的基础。
第2章 Java编程基础
2.1 变量与常量
2.1.1 关键字和保留字
关键字:预先定义好的有特别意义的单词。
保留字:预先保留,在以后的版本中可能使用到的特殊标识符。
| void | assert | boolean | break | byte | case |
| char | class | const | continue | default | do |
| else | enum | extends | final | finally | float |
| goto | if | abstract | import | instanceof | int |
| long | native | new | package | private | protected |
| return | strictfp | short | static | super | switch |
| this | throw | throws | transient | try | implements |
| while | catch | double | for | interface | synchronized |
| public | volatile |
2.1.2 标识符与命名规范
标识符是给Java中的类、方法、变量、包命名的符号。标识符需要遵守一定的规则
- 标识符只能由字母、数字、下划线、美元符号组成,并且不能以数字开头。
- Java标识符大小写敏感,长度无限制。
- 标识符不可以是Java关键字和保留字
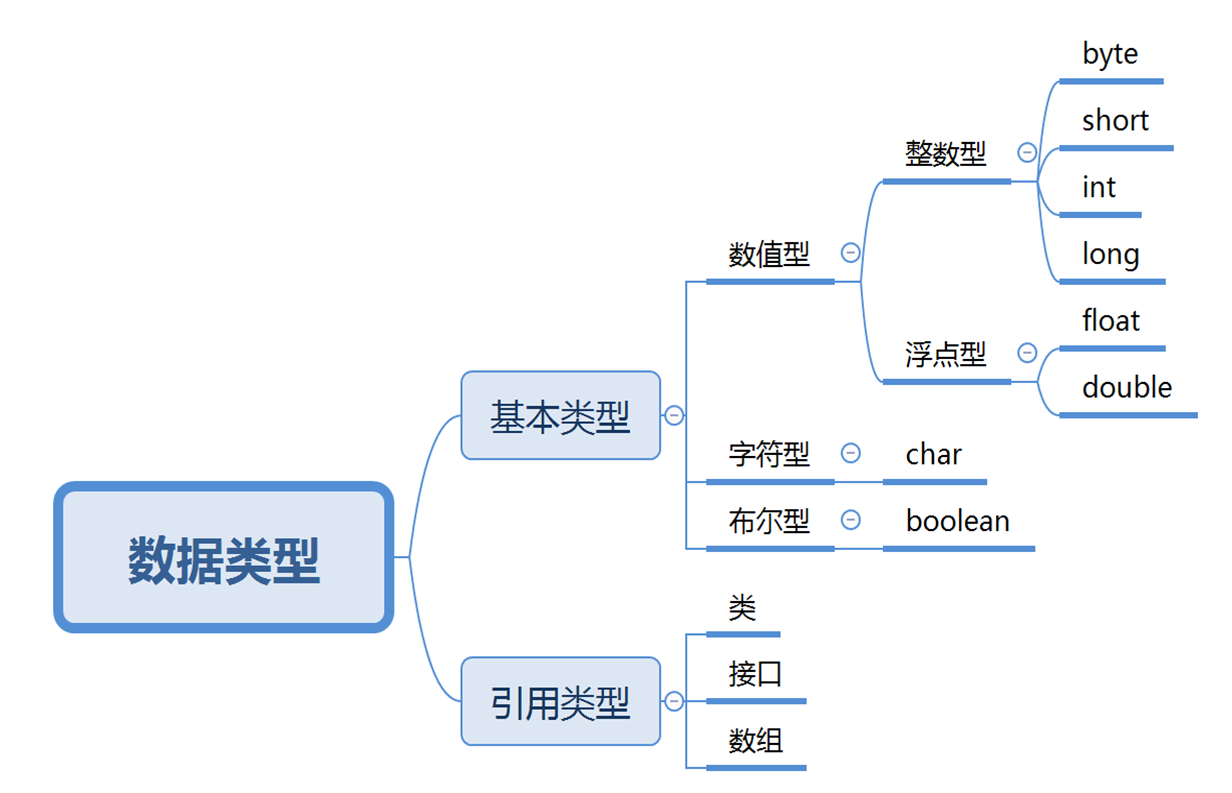
2.1.3 数据类型
| 数据类型 | 占用空间 | 备注 |
|---|---|---|
| byte | 1 字节 | -27 ~ 27-1 (-128 ~ 127) |
| short | 2 字节 | -215 ~ 215-1 (-32768 ~ 32767) |
| int | 4 字节 | -231 ~ 231-1 |
| long | 8 字节 | -263 ~ 263-1 |
| float | 4 字节 | -3.403×1038 ~ 3.403×1038 |
| double | 8 字节 | -1.798×10308 ~ 1.798×10308 |
| boolean | 官方没有明确指出 | 只有 true 和 false 两个值 |
| char | 2 字节 | 能够表示任何 Unicode 字符,并且在一定范围内可以与 int 互相转换 |
2.1.4 变量的定义与赋值
变量的本质就是一个“可操作的存储空间”,声明变量时即在内存在为其分配空间,空间位置是确定的,但是里面放置什么值不确定。
变量必须先声明再使用。变量声明的语法如下:
// 声明一个变量
数据类型 变量名;
// 一次声明多个变量
数据类型 变量名1,变量名2,变量名3;
变量的值是可以改变的,在声明一个变量之后,它的值可被改变任意次。
变量名的命名遵守小写字母开头的驼峰规则。
// 声明一个变量
数据类型 变量名;
// 之后赋值
变量名 = 变量值;
// 声明变量时就赋值
数据类型 变量名 = 变量值;
// 一次声明多个变量并赋值
数据类型 变量名1 = 变量值1, 变量名2 = 变量值2, 变量名3 = 变量值3;
2.1.5 常量
常量与变量的语法类似,只在变量声明语法前加上final关键字即可。变量是可以改变值的量,而常量一旦被赋值后,就不可以改变了。
常量名的命名,一般要求所有字母大写,单词之间使用“_”隔开。
常量声明语法如下:
// 声明一个常量
final 数据类型 常量名 = 常量值;
常量也可以先声明后赋值,只要保证一个常量自始至终只被赋值一次就好。
2.1.6 变量的类型转换变量的类型转换
Java中的数据类型转换主要分为两种:
- 自动类型转换:
在Java中,占用字节数少的数据类型的值,可以直接赋值给占用字节数多的数据类型的变量,比如short类型的值可以直接赋值给int类型的变量,或者把int类型的值赋值给double类型的变量。
如下所示:
int num1 = 10;
double num2 = num1;
其中有个特例:int类型的常量可以直接赋值给char、short、byte,只要不超过它们能够表示的值的范围即可。
- 强制类型转换:
可以强制性地将占用字节数多的数据类型的数据转换成占用字节数少的数据类型的数据,但这个转换过程可能会存在数据精度丢失的问题。
强制类型转换的语法如下:
数据类型 变量名 = (数据类型) 变量值;
2.1.7 Scanner 的使用
借助 Scanner 类,用户可通过键盘输入内容。
Scanner 类在 java.util 包下,使用时需要导包,不过好在所使用的开发工具会自动导包,因此并不需要关心。
首先需要使用 new 关键字创建 Scanner 的对象,再通过 Scanner 类的next()方法获取用户在控制台输入的字符串,通过nextByte()、nextShort()、nextInt()、nextLong()、nextFloat()、nextDouble()获取用户在控制台输入的基本数据类型。
2.2 运算符与表达式
算术运算符
| 一元运算符 | 描述 |
|---|---|
+ | 可以进行加法运算,也可以进行字符串的拼接 |
- | 减法运算 |
* | 乘法运算 |
/ | 除法运算,需要注意整数之间除法运算结果依然是整数 |
% | 取模运算,即求余数 |
| 二元运算符 | 描述 |
|---|---|
num++ | 自增运算符,先返回 num 的值,再将 num 加 1 |
++num | 自增运算符,先将 num 加 1,再返回 num 的值 |
num-- | 自减运算符,先返回 num 的值,再将 num 减 1 |
--num | 自减运算符,先将 num 减 1,再返回 num 的值 |
赋值运算符
| 运算符 | 描述 |
|---|---|
= | 将右边的值赋值给左边的变量,如 num = 5 |
+= | 如 num += 5,相当于 num = num + 5 |
-= | 如 num -= 5,相当于 num = num - 5 |
*= | 如 num *= 5,相当于 num = num * 5 |
/= | 如 num /= 5,相当于 num = num / 5 |
%= | 如 num %= 5,相当于 num = num % 5 |
关系运算符(注:运算结果为:布尔类型)
| 运算符 | 描述 |
|---|---|
> | 大于 |
< | 小于 |
== | 等于,注意,一个“=”是赋值运算符 |
>= | 大于等于 |
<= | 小于等于 |
!= | 不等于 |
逻辑运算符
| 运算符 | 描述 |
|---|---|
& | 与运算。当两边表达式都为 true 时,结果为 true,否则结果为 false |
| | 或运算。当两边表达式都为 false 时,结果为 false,否则结果为 true |
^ | 异或运算。当两边结果不同时,结果为 true,否则为 false |
! | 非运算。如果表达式结果为 true,那么计算结果为 false,反之亦然 |
&& | 短路与运算。计算结果与 & 运算符一致,但当第一个表达式为 false 时,第二个表达式就不再运算 |
|| | 短路或运算。计算结果与 |
位运算符
位运算是直接对二进制进行的计算,性能极高,很多框架中都会使用位运算。
但在实际开发中应用较少,因为相较于这些细微的性能提升,代码可读性更加重要,因此了解即可。
| 运算符 | 描述 |
|---|---|
<< | 将二进制位左移指定位数。移动 n 位就相当于 * 2n |
>> | 将二进制位右移指定位数。移动 n 位就相当于 / 2n |
>>> | 无符号右移,结果会连同二进制最高位的符号位也移动 |
& | 与运算,类似于逻辑运算符。参与运算的两个数字位都为 1,结果才为 1,否则结果为 0 |
| | 或运算,类似于逻辑运算符。参与运算的两个数字位都为 0,结果才为 0,否则结果为 1 |
^ | 异或运算,类似于逻辑运算符。参与运算的两个数字位不相同结果为 1,相同为 0 |
~ | 按位取反运算,将二进制位每一位如果为 0 就变成 1 |
三元运算符
三元运算符可用于做一些简单的逻辑判断,比如获取两个数中的较大值。
条件表达式 ? 表达式 1 : 表达式 2;
运算符的优先级
在实际开发中,可能同时使用到多种运算符,而运算符之间的优先级是不同的,
优先级越低的运算符越先执行。
| 优先级 | 描述 | 运算符 | 结合性 |
|---|---|---|---|
| 1 | 括号 | () | - |
| 2 | 正负号 | +, - | 从右到左 |
| 3 | 一元运算符 | ++, --, ! | 从右到左 |
| 4 | 乘除 | *, /, % | 从左到右 |
| 5 | 加减 | +, - | 从左到右 |
| 6 | 移位运算 | >>, >>>, << | 从左到右 |
| 7 | 比较大小 | >, <, >=, <= | 从左到右 |
| 8 | 比较是否相等 | ==, != | 从左到右 |
| 9 | 按位与运算 | & | 从左到右 |
| 10 | 按位异或运算 | ^ | 从左到右 |
| 11 | 按位或运算 | | | 从左到右 |
| 12 | 逻辑与运算 | &&(简短逻辑与)、&(非简短逻辑与) | 从左到右 |
| 13 | 逻辑或运算 | ||(简短逻辑或)、|(非简短逻辑或) | 从左到右 |
| 14 | 三元运算符 | ?: | 从右到左 |
| 15 | 赋值运算符 | = | 从右到左 |
2.3 选择结构
选择结构用于在代码中做一些逻辑判断,当满足某些条件时,执行某段代码。
2.3.1 if 语句
if 语句就是选择结构的代表。通过 if 语句,能够实现各种各样的逻辑判断。
其中,一个if语句之后可以有0至多个else if语句,可以有0或1个else语句。
if 语句的语法格式如下所示:
if (条件表达式 1) {
// 代码块 1
} else if (条件表达式 2) {
// 代码块 2
} else if (条件表达式 3) {
// 代码块 3
} else {
// 代码块 n
}
/*
程序执行到 if 语句后会进行判断:
当条件表达式1为 true 时,执行代码块1;
否则,当条件表达式2为 true 时,执行代码块2;
否则,当条件表达式3为 true 时,执行代码块3;
否则,执行代码块n。
*/
if 语句在使用过程中还需要注意以下两点:
- 如果 if 选择结构只需执行一条语句,那么可以省略{}。为了提高代码的易读性,建议不要省略{}。
- {}中的代码语句也称为代码块,在代码块定义的常量或变量的作用域仅限于代码块中,在代码块之外不能被使用。
2.3.2 switch 语句
switch 语句判断的变量中,类型只能是byte、short、int、char、String(JDK1.7)和枚举,因此它的适用范围较窄,但对于精确值的判断,switch依然是非常方便的。
switch语句一般用于做一些精确值的判断,其语法格式如下所示。
switch (变量) {
case 值1:
// 代码块 1
break;
case 值2:
// 代码块 2
break;
case 值3:
// 代码块 3
break;
...
default:
// 代码块 n
break;
}
/*
switch 语句会根据表达式的值从相匹配的 case 标签处开始执行,
一直执行到 break 语句处或者是 switch 语句的末尾。
如果 case 全都不匹配,则进入 default 语句。
*/
2.3.3 选择结构的嵌套和对比
选择结构在使用上可以嵌套,if 中的代码块也可以是 switch 语句,switch 语句中的代码块也可以是 if 语句。通过嵌套,可以去判断更加复杂的逻辑。
if 语句和 switch 语句都可以实现逻辑判断,但它们的使用场景有所不同。
if 语句一般用于区间值的判断,而 switch 语句只能用于确定值的判断。
凡是 switch 语句能够实现的,if 语句都可以实现,反之则不行。
2.4 循环结构
一、循环语句
for 语句
for (循环初始化表达式; 循环条件表达式; 循环后的操作表达式) {
// 循环体
}
while 语句
while (条件表达式) {
// 循环体
}
do…while 语句
do {
// 循环体
} while (条件表达式);
二、break 和 continue 语句
在任何循环语句的主体部分,均可用 break 控制循环的流程。
break 用于强行退出循环,不执行循环中剩余的语句。
而 continue 则只能终止某次循环,继续下一次循环。
三、3种循环结构应用场景
如同选择结构一样,循环结构也可以任意嵌套。
三种循环在任何场景下都是可以互相替换的,但实际开发中应当根据合适的需求场景选择不同的循环语句:
- 如果能够确定循环次数,建议使用for循环。
- 如果不能确定循环次数,或者想让循环永远执行,建议使用while循环。
- 如果想让循环体至少执行一次,建议使用do…while循环。
当然,这三种循环可以互相通用。
2.5 方法
2.5.1 方法声明与调用
方法的声明包含了很多组成部分,每个组成部分的含义如下。
- 修饰符:用于控制方法的访问权限,目前学习阶段全部写为 public static 即可。
- 返回值类型:方法需要返回给调用者数据的数据类型,如无返回值,必须声明返回值类型为 void。
- 方法名:方法的名字,命名规范在标识符规范的基础之上,采用首字母小写的驼峰命名规则。
- 形参列表:由参数类型和参数名组成,也称作形式参数(形参),形参可以为任意多个,用于调用者给方法内部传递数据。
- 方法体:该方法需要实现的具体逻辑。
- 返回值:方法执行完毕后提供给调用者的数据。
如果定义了返回值类型,那么返回值和返回值类型必须保持一致;
如果定义的返回值类型为 void,那么需要省略返回值,也就是直接用语句 “return;” 返回或者省略该语句直至该方法执行结束。
当方法在执行过程中遇到 return 语句,就会返回而结束该方法的执行。
修饰符 返回值类型 方法名(参数类型 参数名1, 参数类型 参数名2, ...) {
// 方法体
return 返回值;
}
//例如
public int add(int a, int b) {
// 方法体
return a + b;
}
当声明了一个方法之后,就可以使用代码在其他方法中调用它了。
方法调用时的参数列表称为实际参数(实参)。
实参列表的数据类型和参数个数必须与方法声明时完全一致。
调用方法的语法格式如下所示。
方法名(实际参数 1, 实际参数 2, ...);
2.5.2 方法重载
如果出现了很多功能类似的方法,为了让方法能够做到见名知意,这些方法的命名就需要类似,如果这些方法很多,就会导致方法名非常混乱。为了解决这种问题,就出现了方法的重载。
在同一个类中,允许存在一个以上的同名方法,只要它们的参数个数或者参数类型不同即可,这种现象称作方法重载。需要注意的是,方法重载只与参数和方法名有关,返回值类型不同,不构成方法的重载;形参的名称不同,不构成方法的重载;方法修饰符不同,不构成方法的重载。
从输出结果可以看出,虽然方法名都相同,但是根据传入的参数不同,JVM会自动调用对应的重载方法。System.out.println方法就是个非常典型的重载方法,该方法为了能够打印任何数据类型,就重载了大量的println()方法,为的就是能够支持所有的数据类型,如下图所示。

2.5.3 方法递归
编程语言中,方法直接或间接调用方法本身,则称该方法为递归方法。合理的使用递归,能够解决很多使用循环难以解决的问题。
典型的斐波那契数列问题:指的是这样一个数列:0、1、1、2、3、5、8、13、21、34、……,在数学上,斐波那契数列被以如下递推的方式定义:
F(0)=0,F(1)=1,F(n)=F(n - 1)+F(n - 2) (n ≥ 2,n ∈ N*)。
2.6 数组
数组就是一种能够存放相同数据类型的有序集合,或者说它是一个存储数据的容器。可以创建出一个指定长度的数组,这样就可以存储对应条数的数据了。
在Java中,数组的创建方式分为3种,语法格式如下所示。
方式一:创建指定长度的数组
数据类型[] 数组名 = new 数据类型[数组长度];
方式二:创建数组的同时初始化元素
数据类型[] 数组名 = new 数据类型[]{元素1, 元素2, 元素3, ...};
方式三:简写方式
数据类型[] 数组名 = {元素1, 元素2, 元素3, ...};
数组的常见操作
- 通过索引操作元素
数组元素的操作都是通过索引(也称作下标)进行的,当创建了一个长度为 n 的数组后,它的索引范围是 [0, n-1]。 - 数组的遍历
当数组元素很多时,不可能一个一个使用索引获取元素,而是希望能够通过循环的方式取出数组中每一个元素,这个操作称作遍历。数组的遍历一般使用 for 循环遍历,从0遍历到数组长度-1即可。
事实上,如果只是想获取数组中的每一个元素,并不需要给数组元素赋值,也不需要操作索引,还有一种更为简便的遍历方式:foreach 循环,又称作 增强for循环。
foreach 循环的语法格式如下所示
for (数据类型 变量 : 数组) {
System.out.println(变量);
}
foreach循环比普通的for循环语法更简洁,但是无法获取到索引。当不需要使用数组索引的时候,可以考虑使用这种循环方式。
-
获取数组的最值
当需要获取到数组的最大值或最小值时,通过常规的思路可能不太好处理,此时可以使用“假设法”。首先假设索引0处的元素是最大值,之后遍历整个数组,每次遍历取出当前元素与所假设的最大值进行比较,如果当前元素比假设的最大值还大,就再假设该元素是最大值,直到数组遍历完毕为止,最后所假设的最大值就是真正的最大值。 -
通过值获取索引
有时可能需要查询数组中某个值所在的索引位置,这个操作也可以通过遍历实现,但需要注意,待查找的值可能在数组中不存在,因此需要先假设待查找值的索引为-1。因为-1这个值不可能是数组的索引,因此当遍历结束后如果索引还是-1,就说明没有找到该值。 -
数组元素的反转
有时候可能需要反转一个数组,将数组元素首尾互换,这可以借助一个新的数组。
2.6.3 数组排序算法
冒泡排序
核心思想:在要排序的序列中,对当前还未排好序的全部元素,自上而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的数往上冒,就好像水泡上浮一样,如果它们的顺序错误,就把它们交换过来,如下图所示。
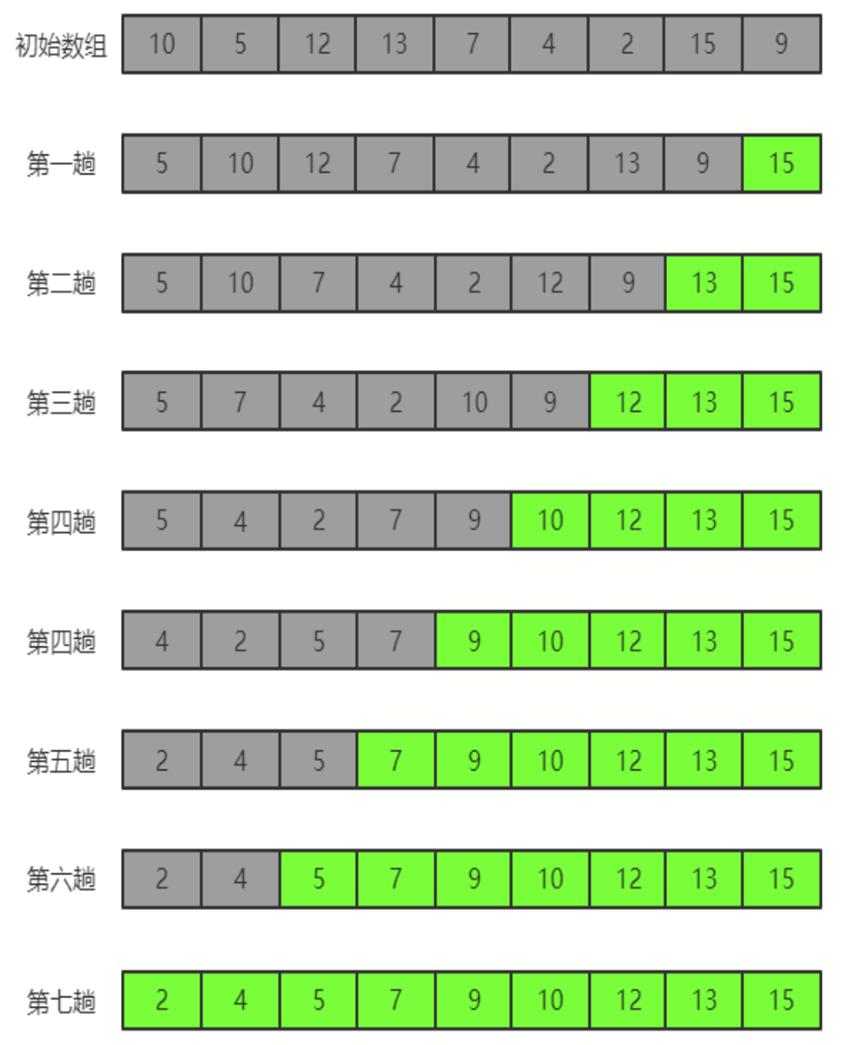
选择排序
核心思想:在要排序的一组数中选出最小(或者最大)的一个数与第1个位置的数交换;然后在剩下的数中再找最小(或者最大)的与第2个位置的数交换,依次类推,直到第n-1个元素(倒数第二个数)和第n个元素(最后一个数)比较为止,每一轮排序都是找出它的最小值或者最大值的过程,如下图所示。
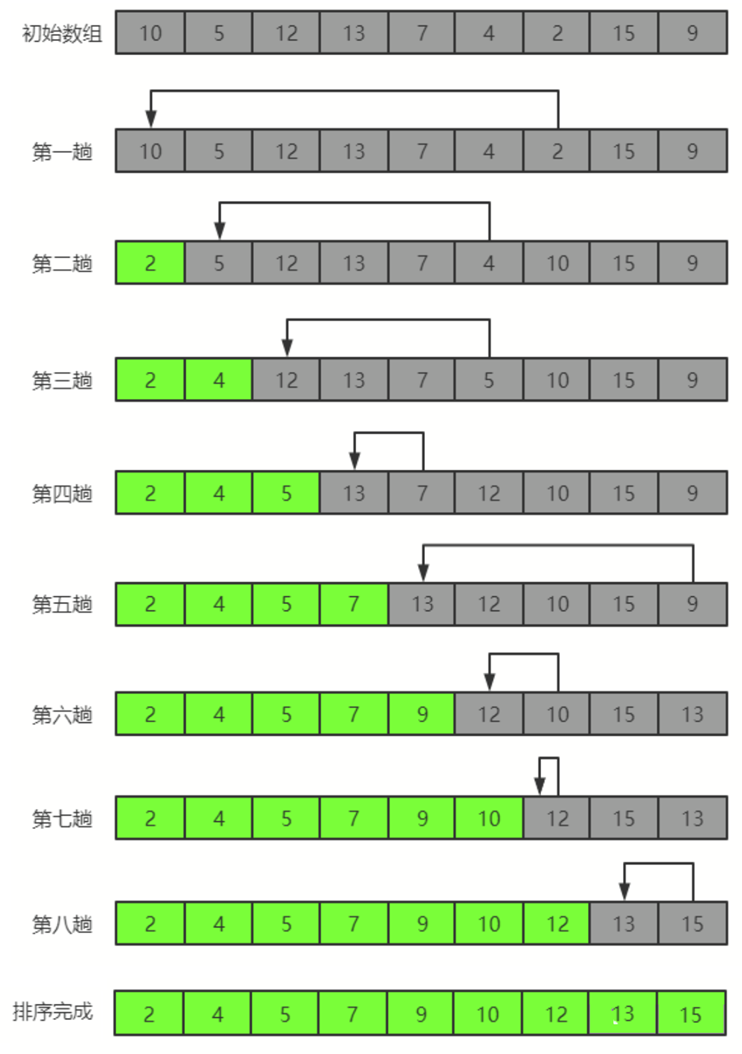
二分查找法
二分查找法 又称 折半查找法,其算法思想是每次查找数组最中间的值,通过比较大小关系,决定再从左边还是右边查询,直到查找到为止。
优点:比较次数少,查找速度快,平均性能好;
缺点:要求待查表为有序表,且插入、删除操作困难。
因此,折半查找法适用于不经常变动而查找频繁的有序列表,二分查找法依然需要使用到循环,但由于不知道循环次数,所以最好使用while循环实现。
方法中的可变参数
当一个方法中的参数个数不确定,但参数的类型确定时,可以使用可变参数。
在实际处理时,可变参数会被当作数组进行处理。可变参数的语法格式如下所示。
public static void method(数据类型 ...参数名)
当使用可变参数后,add()方法就可以传入任意个数的int参数,并且在处理时,nums可以当作数组进行处理。
当参数个数不确定时,合理使用可变参数可以大大地简化程序代码的开发。
二维数组
二维数组的每一个元素都是一个数组,简单来说,二维数组就是“数组的数组”。创建二维数组的语法格式如下所示。
数据类型[][] 数组名 = new 数据类型[m][n];
Arrays 工具类
Arrays是Java中提供的操作数组的工具类,通过Arrays类,可以很方便地操作数组。
Arrays中提供了大量的方法,其中常见方法如下表所示。
| 方法签名 | 描述 |
|---|---|
static String toString(Type[] arr) | 按照特定的格式将数组转换成字符串 |
static boolean equals(Type[] arr1, Type[] arr2) | 比较两个数组中所有的内容是否相同 |
static void sort(Type[] arr) | 对数组元素进行排序 |
static int binarySearch(Type[] arr, Type value) | 二分法查找某个值在数组中的索引位置 |
直接用Arrays.方法名即可调用。
2.7 JVM中的堆内存与栈内存
2.7.1 堆和栈
JVM是基于堆栈的虚拟机,堆栈是一种数据结构,是用来存储数据的。
对于一个Java程序来说,它的运行就是通过对堆栈的操作来完成的。
栈内存:
用于存储局部变量,以及对象的引用,它是一个连续的内存空间,由系统自动分配,性能较高。
栈内存具有先进后出、后进先出的特点,虚拟机会为每条线程创建一个虚拟机栈,当执行方法时,虚拟机会创建出该方法的一个栈帧,该方法中所有的局部变量都会存储到这个栈帧中,方法执行完毕后,栈帧弹栈。
堆内存:
用于存储引用类型的数据,主要是对象和数组。全局只有一个堆内存,所有的线程共用一个堆内存。
在堆中产生了一个数组或对象后,还可以在栈中定义一个特殊的变量,让栈中这个变量的取值等于数组或对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量。引用变量就相当于是为数组或对象起的一个名称,以后就可以在程序中使用栈中的引用变量访问堆中的数组或对象了。
堆内存与栈内存,演示示例的代码在内存中的堆栈结构如下图所示:
import java.util.Arrays;
public class Demo {
public static void main(String[] args) {
int num1 = 10;
int num2 = 20;
int[] arr = {1, 2, 3};
method(arr);
}
public static void method(int[] arr) {
int num1 = 30;
int num2 = 40;
int[] arr2 = arr;
}
}
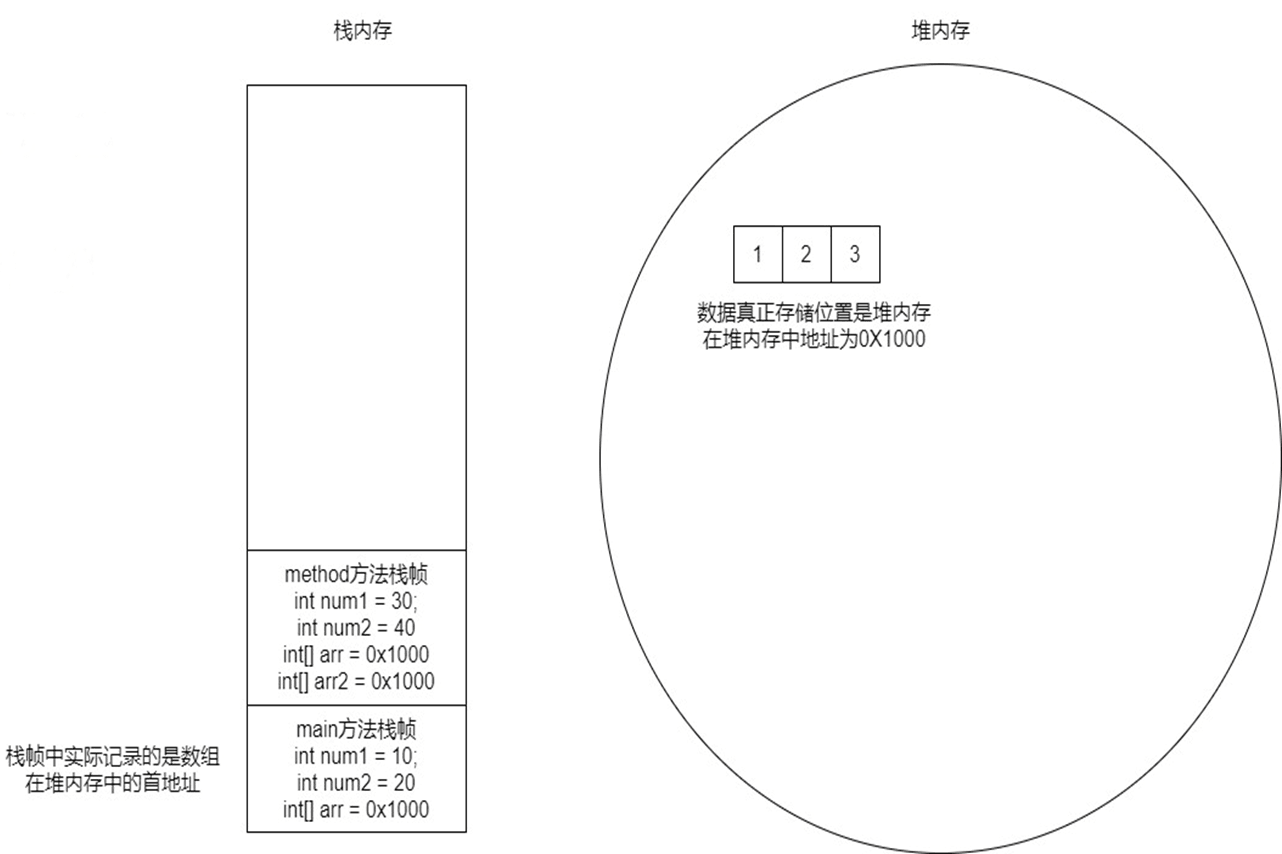
2.7.2 数据类型传递
编程语言中数据类型传递的方式有值传递和引用传递两种,而Java中只有值传递。
尽管Java中存在着引用类型,但实际上在栈内存中引用类型变量记录的是对象在堆内存中的地址值,当引用类型变量互相赋值时,也是赋值的地址值,并没有将引用复制一份出来。
比如上面的代码中,method 栈帧和main()方法栈帧中的 arr 变量是完全不同的变量,它们仅仅是值相同。
总结
数据类型与变量
通过实践,我认识到选择合适的数据类型对程序效率和内存使用至关重要。合理使用基本数据类型(如byte、short、int、double等)可以显著优化性能和资源利用。
控制结构
条件语句(如if, switch)和循环语句(如for, while, do…while)是控制程序执行流程的核心工具,增强了程序的灵活性和逻辑性。
数组
数组提供了方便管理和操作一组数据的方式,尽管其大小不可变,但通过合理设计程序结构,可以有效应对这一限制。数组的简洁语法和高效访问方式使其成为处理集合数据的理想选择。
方法
方法提高了代码的可读性和复用性,尤其在处理复杂逻辑时,通过分解成多个功能明确的方法,可以提升代码清晰度和维护性。
面向对象编程
初步接触面向对象编程(OOP),我感受到它在编程中的重要性。通过定义类和创建对象,可以更好地模拟现实世界的事物,增强代码的结构化和模块化,促进代码重用和维护。
第3章 面向对象程序设计(基础)
3.1 面向对象的概念
3.1.1 什么是面向对象
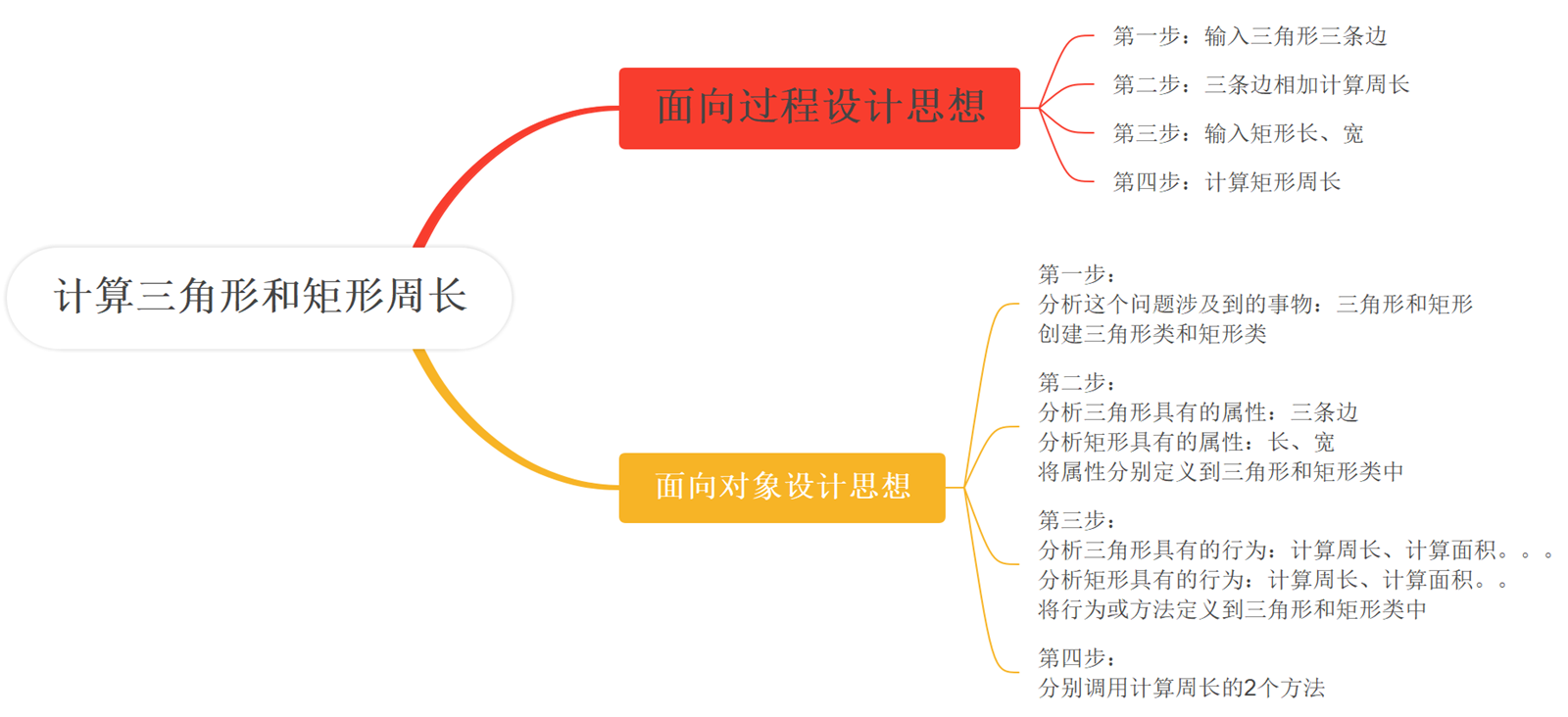
面向对象程序设计的思维方式是一种更符合人们思考习惯的方式。
面向对象分析问题涉及到的事物或对象,创建对应的类,分析事物的属性和行为,将这些属性和行为定义到类中,在解决问题的过程中按需创建对象,通过对象调用类中的行为,最终解决问题。
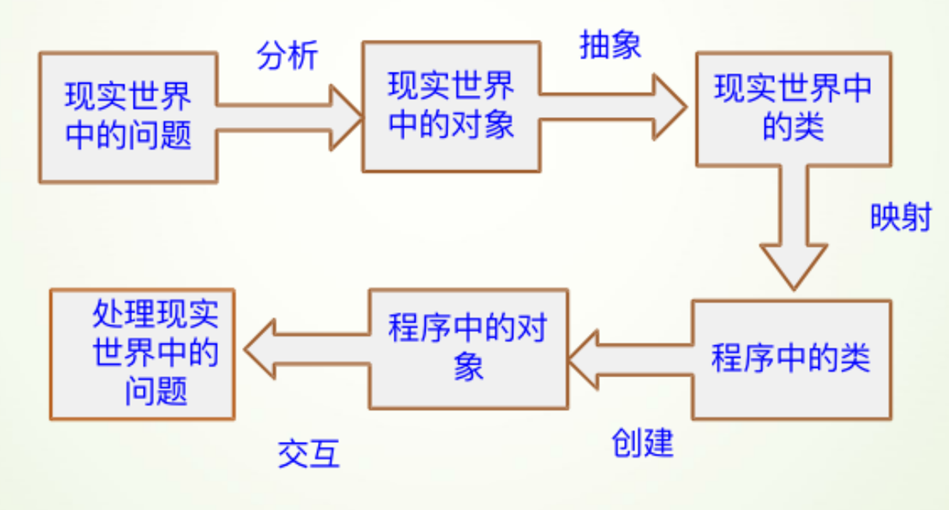
3.1.2 类和对象
万物皆对象,现实中存在的任何一个具体的事物都是一个对象,比如一张桌子、一台电脑、一个人、一支笔。将现实中一类事物抽象化,提取出这一类事物共有的属性和行为,就形成了类。
类是抽象的概念,对象是具体的概念。
3.1.3 面向对象的特性
面向对象具有封装、继承、多态的特性,更符合程序设计中“高内聚、低耦合”的主旨,其编写的代码的可维护性、可读性、复用性、可扩展性远比面向过程思想编写的代码高,但是性能相比面向过程要偏低一些。
- 封装:指隐藏对象的属性和实现细节,仅对外提供公共的访问方式
- 继承:子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例属性和方法,或子类从父类继承方法,使得子类具有父类相同的行为
- 多态:指的是同一个方法调用,由于对象不同可能会有不同的行为
3.2 面向对象编程
3.2.1 类的定义
Java使用 class 关键字来定义一个类。
一个Java文件中可以有多个类,但最多只能有一个public修饰的类,并且这个类的类名必须与文件名完全一致。
类名需要符合标识符规则,并且遵循大写字母开头的驼峰规则。
public class DemoObject {
}
class Entity1 {
}
class Entity2 {
}
类主要由变量(字段)和方法组成。
变量(字段field) 其定义格式:
修饰符 变量类型 变量名 = [默认值] ;
方法(行为action) 其定义格式:
修饰符 返回值类型 方法名(形参列表) {}
public class Student {
// 变量,此处也称为成员变量
String name;
int age;
// 方法,此处也称为成员方法
void eat(String food) {
System.out.println(name + "吃" + food);
}
void study() {
System.out.println(name + "年龄" + age + "岁,在学习java");
}
}
创建一个Student类,拥有name和age变量,以及eat()和study()方法,并且这两个方法也称作成员方法。
3.2.2 对象的创建与使用
要创建一个对象,必须先有一个类,然后通过new关键字来创建一个对象。
对象创建语法如下。
类名称 对象名称 = new 类名称();
成员变量和成员方法隶属于对象,不同对象之间的成员变量占用不同的地址空间,互不影响。
3.2.3 成员变量默认值
为一个类定义成员变量时,可以显式地为其初始化。如果不为成员变量初始化,Java虚拟机也会默认给成员变量进行初始化。下表为Java虚拟机为每种数据类型的成员变量赋予的默认值。
| 数据类型 | 默认值 |
|---|---|
| 整型 (short、byte、int、long) | 0 |
| 浮点型 (float、double) | 0.0 |
| 字符型 | ‘\u0000’ |
| 布尔型 | false |
| 引用类型 | null |
成员变量与上一章的局部变量不同。局部变量必须要赋值才可以使用,而成员变量即使不赋值,Java虚拟机也会默认为其赋值。
3.2.4 匿名对象
通过使用 new 关键字来创建对象,这种对象分为两种:匿名对象与非匿名对象。
何为匿名对象,何为非匿名对象呢? 匿名对象就是没有名字的对象,是定义对象的一种简写方式。
当方法的参数只需要一个对象,或者仅仅想调用一下某个对象的成员方法时,大可不必为这个对象单独创建一个变量,此时就可以使用匿名对象。
3.2.5 对象内存分析
Java对象在内存中的存储
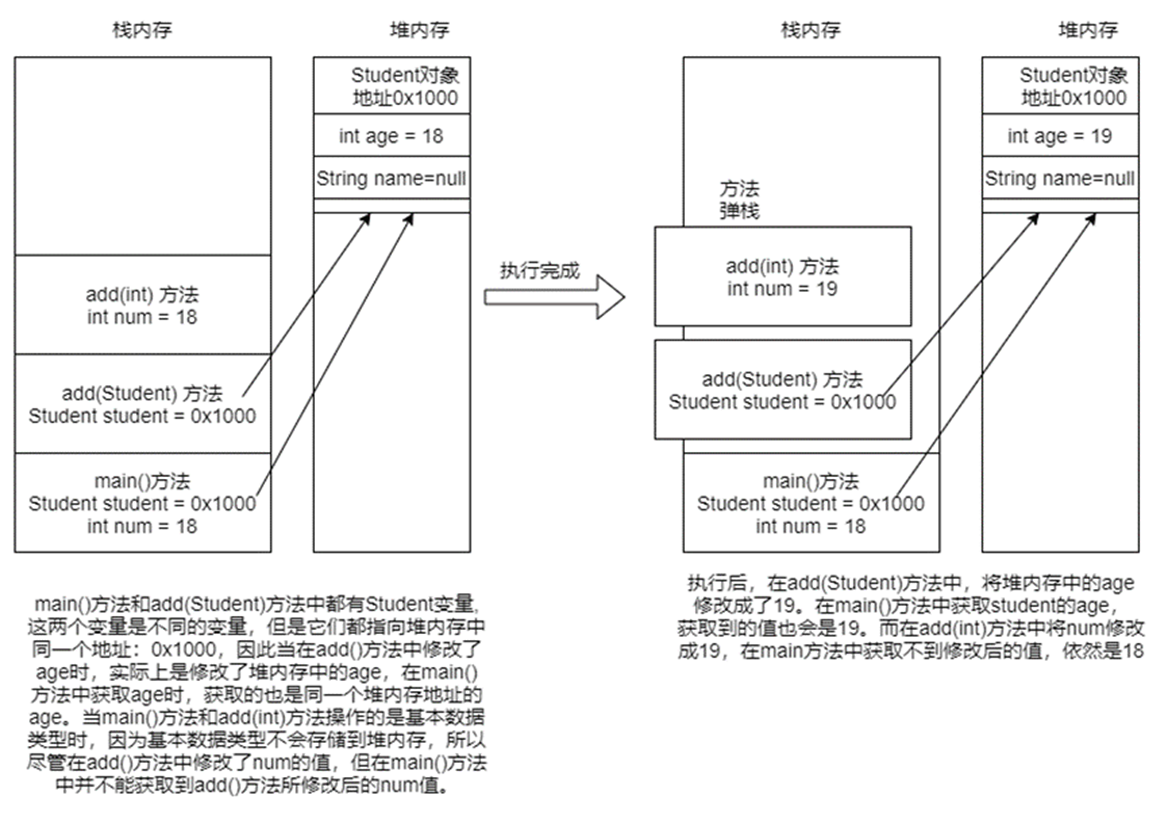
成员变量和局部变量的存储位置是不同的。尽管成员变量也可能是基本数据类型,但它的生命周期是跟随对象的,也会随着对象一并存储到堆内存中,而局部变量的基本数据类型只会存储到栈内存中。
num是基本类型,存储在栈内存中,main()方法和add()方法是两个不同的栈帧。由于Java只有值传递的特点,在调用add方法时虽然把num传递给了方法,但两个栈帧中的num却是完全不同的变量,因此在add方法中改变num的值并不会影响到main方法。
而Student是引用类型,存储在堆内存中,栈内存中只存储“值”,这个值是Student对象在堆内存中的地址。虽然Java只有值传递,main()方法和add()方法两个栈帧中的Student变量是不同的变量,但它们的值相同。由于引用类型数据的特点,操作值最终都需要到堆内存中进行,因此在add()方法中对堆内存中age的操作,在main()方法中也能感知到,如上图所示。
3.3 构造方法
构造方法也称作构造器(constructor),用于给对象进行初始化操作,即为对象成员变量赋初始值。
构造方法名称必须与类名相同,并且不能定义返回值,不能出现return关键字。
Java中要求每一个类必须要有构造方法。
构造方法的调用必须通过new关键字调用,语法格式如下所示。
修饰符 类名(形参列表) {
// 构造方法体
}
public class Student {
// 变量,此处也称为成员变量
String name;
int age;
// 无参构造方法
public Student() {
System.out.println("无参构造执行了");
}
// 有参构造方法
public Student(String stuName, int stuAge) {
name = stuName;
age = stuAge;
System.out.println("有参构造执行了");
}
// 方法,此处也称为成员方法
void eat(String food) {
System.out.println(name + "吃" + food);
}
void study() {
System.out.println(name + "年龄" + age + "岁,在学习java");
}
}
构造方法的重载
在 Java 中,构造方法也可以重载,构造方法重载是方法重载中的一个典型特例。
当创建一个对象时,JVM 会自动根据当前对方法的调用形式在类的定义中匹配形式相符合的构造方法,匹配成功后执行该构造方法。
public class Student {
String name;
int age;
// 无参构造方法
public Student() {
System.out.println("无参构造执行了");
}
// 有参构造方法(包含姓名和年龄)
public Student(String stuName, int stuAge) {
name = stuName;
age = stuAge;
System.out.println("有参构造执行了");
}
// 有参构造方法(仅包含年龄)
public Student(int age) {
this.age = age;
}
// 有参构造方法(仅包含姓名)
public Student(String name) {
this.name = name;
}
}
注意:当局部变量和成员变量的变量名相同时,此时编译器无法区分,应当将其中一处的变量名进行改名或者显式使用this关键字调用成员变量。
3.4 this关键字
this 关键字可以调用成员变量、成员方法、构造方法。
需要注意的是,成员方法中不能使用this关键字调用构造方法,只能在构造方法中使用this关键字调用其它构造方法,并且它必须在构造方法的第一行。
/*
编写程序,定义一个坐标类(Point),用于表示二维空间中的一个坐标位置。
通过坐标类的方法,实现计算两个坐标位置之间的距离。
*/
public class Point {
double x;
double y;
public Point(double x, double y) {
this.x = x;
this.y = y;
}
public double calcLength(Point p) {
double xLen = this.x - p.x;
double yLen = this.y - p.y;
return Math.sqrt(xLen * xLen + yLen * yLen);
}
}
3.5 static关键字
静态变量
在类中,将与成员变量同级的用 static 修饰的变量称为静态变量或类变量。
静态变量优先于对象存在,随着类的加载就已经存在了,该类的所有实例共用这个静态变量,即共用同一份地址空间。
当想调用静态变量时,可以使用对象名.变量名进行调用,但不推荐,建议使用类名.变量名进行调用。
public class Student {
String name;
int age;
static String grade;
// 无参构造方法
public Student() {
System.out.println("无参构造执行了");
}
// 有参构造方法(包含姓名和年龄)
public Student(String stuName, int stuAge) {
name = stuName;
age = stuAge;
System.out.println("有参构造执行了");
}
// 有参构造方法(仅包含年龄)
public Student(int age) {
this.age = age;
}
// 有参构造方法(仅包含姓名)
public Student(String name) {
this.name = name;
}
// 成员方法:吃
void eat(String food) {
System.out.println(name + "吃" + food);
}
// 成员方法:学习
void study() {
System.out.println(name + "年龄" + age + "岁,在学习java");
}
}
静态方法
static 关键字也可以修饰方法,用 static 修饰的方法称之为 静态方法 或 类方法。静态方法同样是属于类的,优先于对象存在,调用方式与静态变量相同,也是建议使用类名.方法名进行调用。
public class Student {
String name;
int age;
static String grade;
// 无参构造方法
public Student() {
System.out.println("无参构造执行了");
}
// 有参构造方法(包含姓名和年龄)
public Student(String stuName, int stuAge) {
name = stuName;
age = stuAge;
System.out.println("有参构造执行了");
}
// 有参构造方法(仅包含年龄)
public Student(int age) {
this.age = age;
}
// 有参构造方法(仅包含姓名)
public Student(String name) {
this.name = name;
}
// 成员方法:吃
void eat(String food) {
System.out.println(name + "吃" + food);
}
// 成员方法:学习
void study() {
System.out.println(name + "年龄" + age + "岁,在学习java");
}
// 静态方法:回家
static void goHome() {
// 静态方法中不能调用成员变量和成员方法,不能使用 this
// System.out.println(this.name + "回家");
System.out.println("学生回家");
}
}
静态代码块
带有static关键字的方法、变量、代码块只能调用带有static关键字的方法、变量,而不带有static关键字的可以随意调用。
public class Student {
// 构造代码块 1
{
System.out.println("构造代码块 1 被执行了");
}
// 构造代码块 2
{
System.out.println("构造代码块 2 被执行了");
}
// 静态代码块 1
static {
System.out.println("静态代码块 1 被执行了");
}
// 静态代码块 2
static {
System.out.println("静态代码块 2 被执行了");
}
// 无参构造方法
public Student() {
System.out.println("无参构造执行了");
}
}
结论:
(1)同一个类中,成员变量不能赋值给静态变量,静态变量可以赋值给成员变量和静态变量。
(2)同一个类中,静态方法不能调用成员变量和成员方法,成员方法可以调用静态或非静态的方法和变量。
(3)同一个类中,静态代码块不能调用成员变量和成员方法,构造代码块可以调用静态或非静态的方法和变量。
3.6 包
包是 Java 中重要的类管理方式,开发中会遇到大量同名的类,通过包给类加上一个命名空间,很容易就能解决类重名的问题,也可以实现对类的有效管理。包对于类,相当于,文件夹对于文件的作用。
Java 通过 package 关键字声明一个包,之后根据功能模块将对应的类放到对应的包中即可。包名的命名要求遵循标识符规则,在企业中一般以反着写企业域名的方式命名,比如 com.baidu 和 com.jd,唯独需要注意的一点是,包名不能以 java 开头。
声明一个包的语法格式:
package com.yyds.unit3.demo;
类的访问与导包
一般来说,定义的类都需要定义在包下。当要使用一个类时,这个类与当前程序在同一个包中,或者这个类是 java.lang 包中的类时通常可以省略掉包名,直接使用该类。其余情况下使用某一个类,必须导入包。
使用 import 关键字导入 java 中的包,语法格式如下:
import 包名.类名;
通过 import 关键字指定要导入哪个包下的哪个类,比如import java.util.Scanner就导入了java.util包下的Scanner类,而其它包中的Scanner类则不受影响。
此外,前面使用到了String类,而该类在java.lang包下,因此可以省略导包。
而上面的案例中,Student类与Demo类都是在同一个包下,也可以省略导包。
当要使用到两个名称一样的类时,就需要以包名.类名的方式使用了,包名.类名的形式也称之为一个类的全类名。
总结
在第三章的学习中,我深入理解了面向对象编程(OOP)的基本概念。OOP不仅显著提高了代码的重用性和可维护性,还使程序结构更加清晰和模块化。
封装的重要性
封装是OOP的核心原则之一,它有效地隐藏了实现细节,降低了类之间的耦合度。通过封装,我可以更好地保护数据,确保代码的安全性和稳定性。
UML类图的应用
UML类图帮助我在设计阶段规划和思考类之间的关系,明确了类的属性和方法,以及它们之间的关联、继承和依赖关系。这使得程序的逻辑结构更加清晰,便于后续的开发和维护。
总结与展望
面向对象编程的思想为我提供了一种强大的工具,能够更高效地组织和管理代码。反思学习过程,我认识到理解和实践OOP的原则和设计方法将是未来学习和工作中需要重点关注的方向。掌握这些技能将有助于我编写出更高质量、更易维护的软件系统。
第4章 面向对象程序设计(进阶)
4.1 封装
访问修饰符可以修饰类、接口、变量、方法,用于控制它们的访问权限。
通过访问修饰符,可以灵活地控制哪些细节需要封装,哪些细节需要对外暴露。
Java中的访问修饰符: private、默认(无修饰符)、protected、public
| 修饰符 | 同一个类 | 同一个包 | 子类 | 所有类 |
|---|---|---|---|---|
| private | √ | |||
| 默认(无修饰符) | √ | √ | ||
| protected | √ | √ | √ | |
| public | √ | √ | √ | √ |
get()/set()方法
创建Student类,拥有姓名和年龄变量,并为其提供get()、set()方法,如下所示。
public class Student {
// private 修饰,让其他类无法直接操作变量
private String name;
private int age;
public Student() {
// 默认构造方法
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
// 通过 set 方法获取值,并在这里处理 age 的范围
if (age < 0) {
age = 0;
}
if (age > 200) {
age = 200;
}
this.age = age;
}
}
当一个类中拥有 age 成员变量,但没有getAge()和setAge()方法,此时认为这个类中没有 age 属性,只有 age 变量。
而如果拥有getAge()和setAge()方法,不管类中是否有 age 成员变量,该类都拥有 age 属性。这就是属性和成员变量的区别。
4.2 继承
Java中使用extends关键字表示继承,语法格式如下所示
class 父类 {
}
class 子类 extends 父类 {
}
注意:
Java 中类之间只有单继承,因此一个子类只能有一个直接父类。
Java 支持多层继承,即 A 类继承 B 类,B 类还可以继承 C 类,此时 C 类称为 A 类的间接父类。
如果一个类没有继承任何类,那么它会默认继承 java.lang.Object。在Java中,Object 类是所有类的父类,也就是说 Java 的所有类都继承了 Object 类,子类可以使用 Object 类的所有方法。
创建People类,拥有姓名、年龄属性,并提供它的get()和set()方法。
之后,分别创建 Teacher 类和 Worker 类,这两个类继承 People 类,其中 Teacher 类拥有teach()方法,Worker 类拥有work()方法,如下所示:
public class People {
private String name;
private int age;
public void eat() {
System.out.println(this.age + "岁的" + this.name + "正在吃饭");
}
// 省略 get/set 方法
}
public class Teacher extends People {
public void teach() {
// 通过继承,teacher 也拥有 age 和 name,只不过由于它们被 private 修饰,只能通过 get 方法访问
System.out.println(getAge() + "岁的" + getName() + "正在教书");
}
}
public class Worker extends People {
public void work() {
System.out.println(getAge() + "岁的" + getName() + "正在工作");
}
}
当父类的方法不能满足子类的需求时,可以在子类中重写父类的方法,重写也称为复写或者覆盖。方法的重写需要注意以下四点:
- 子类重写的方法必须与父类方法的方法名和参数列表完全一样。
- 子类重写的方法修饰符权限要大于或等于父类方法的修饰符权限,如父类的修饰符是protected,那么子类重写该方法的修饰符必须是public或者protected,但父类方法如果是private或者static修饰,则不能重写。
- 子类重写方法的返回值所属的类型为引用类型时,子类方法的返回值类型必须小于或等于父类方法的返回值所属的类型。比如父类方法返回值是People类,则子类重写该方法返回值必须是People类或者其子类。
- 父类方法返回值所属的类型如果是基本数据类型,子类重写该方法时,返回值类型必须与父类方法完全一致。
在 Teacher 和 Worker 类中重写 People 类的eat()方法,如下所示:
public class Teacher extends People {
public void teach() {
// 通过继承,teacher 也拥有 age 和 name,只不过由于它们被 private 修饰,只能通过 get 方法访问
System.out.println(getAge() + "岁的" + getName() + "正在教书");
}
@Override
public void eat() {
System.out.println(getAge() + "岁的" + getName() + "老师正在食堂吃饭");
}
}
public class Worker extends People {
public void work() {
System.out.println(getAge() + "岁的" + getName() + "正在工作");
}
@Override
public void eat() {
System.out.println(getAge() + "岁的" + getName() + "工人正在工地吃饭");
}
}
4.3 super 关键字
- super 可以理解为直接父类对象的引用,或者说 super 指向子类对象的父类对象存储空间。
- 可以通过 super 访问父类中被子类覆盖的方法或属性。
- 除 private 修饰的属性和方法外,子类可以通过 super 关键字调用父类中的属性和方法,它的作用是解决子类和父类中属性、方法重名问题的。
super 关键字可以调用父类的属性、方法(包括构造方法、成员方法),它的使用方式与 this 关键字非常相似,这里以 Teacher 类为例,在 Teacher 类的eat()方法中调用父类的 eat 方法,如下所示。
public class Teacher extends People {
public void teach() {
// 通过继承,teacher 也拥有 age 和 name,只不过由于它们被 private 修饰,只能通过 get 方法访问
System.out.println(getAge() + "岁的" + getName() + "正在教书");
}
@Override
public void eat() {
// 调用父类的方法,必须要使用 super 关键字
super.eat();
System.out.println(getAge() + "岁的" + getName() + "老师正在食堂吃饭");
}
}
- super关键字也可以用来调用父类的构造方法,使用方法是super(参数1, 参数2…)。
- 如果子类的构造方法中不存在 super 调用父类的构造方法,子类的构造方法第一行代码默认会被加上 super(),来调用它的父类无参构造方法,因此如果父类不存在无参构造方法,程序编译就会出错,此时需要手动调用父类的有参构造方法。
super 与 this 的对比
- 创建对象并不是完全由构造方法决定,因此即使使用 super 调用了父类的构造方法,但并没有创建父类对象。
- 创建子类的对象,JVM 会将该对象在堆内存中划分存储空间,父类中定义的属性和方法存储在父类的存储空间中,子类中定义的属性和方法存储在子类的存储空间中,二者都属于这一个对象。
super 关键字指向的其实是该对象的父类存储空间,this 关键字则指向整个对象,如下图所示。
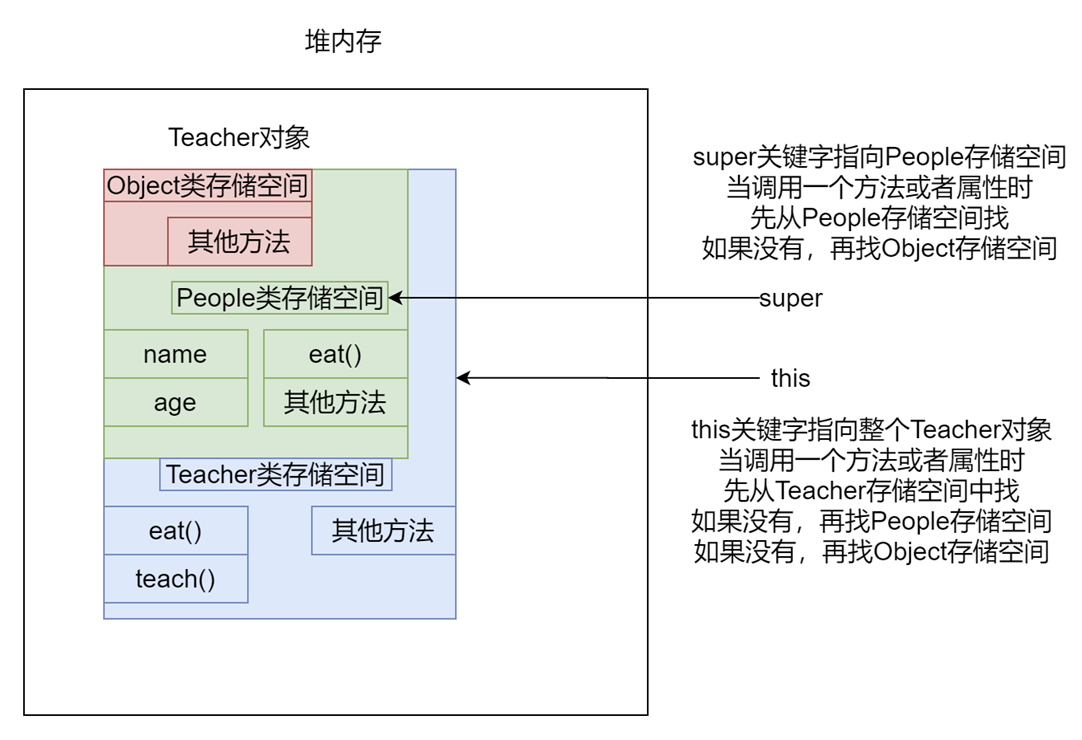
| 区别点 | this | super |
|---|---|---|
| 引用 | this 代表本类对象的引用 | super 代表父类存储空间 |
| 使用方式 | this.属性, this.方法, this() | super.属性, super.方法(), super() |
| 调用构造方法 | 调用本类构造方法,放在第一条语句 | 调用父类构造方法,放在第一条语句 |
| 查找范围 | 先从本类找,找不到查找父类 | 直接查找父类 |
4.4 final 关键字
final 关键字可用来将一个变量声明成常量,事实上,final 关键字还有其他场景的用法。final 是一个修饰符,它可以用来修饰类、类中的属性和方法以及局部变量,但是不能修饰构造方法。
final 的用法主要有下面4点:
- final 修饰的类不可以被继承,但是可以继承其他类。
- final 修饰的方法不可以被重写。
- final 修饰的变量是常量,只能被赋值一次。
- final 修饰的引用类型变量不能改变它的引用地址,但是可以改变对象内部属性的值。
// 被 final 修饰的类不能被继承
public final class Teacher extends People {
// final 修饰的变量称作常量,只能赋值一次
private final String school = "北京大学";
public void teach() {
// 通过继承,teacher 也拥有 age 和 name,只不过由于它们被 private 修饰,只能通过 get 方法访问
System.out.println(getAge() + "岁的" + getName() + "正在教书");
}
@Override
// 加上 final 关键字后,该方法不能被子类重写
public final void eat() {
// 调用父类的方法,必须要使用 super 关键字
super.eat();
System.out.println(getAge() + "岁的" + getName() + "老师正在食堂吃饭");
}
}
事实上,Java 中有很多类都用关键字 final 修饰,比如最常见的 String 类。使用 final 修饰这些类的目的是不想让其他人扩展这些类,防止这些子类被使用到多态中,从而改变 String 类以及其他类本身具有的特性。
在软件开发中,对工具类,私有化它的构造方法,让外界无法创建工具类的对象,并使用 final 关键字修饰类,让它无法被其他类继承,从而保证工具类的安全性。
4.5 Object 类
java.lang.Object 类是 Java 中所有类的父类(包括数组),如果一个类没有用 extends 关键字继承其他类,那么它默认就继承 Object 类。
Java 中这么设计的目的是让所有的类都拥有一些基本的方法,这些方法都定义在了 Object 类中,并且它们中的一部分可以被重写。
| 方法签名 | 方法描述 |
|---|---|
String toString() | 返回该对象的字符串表示形式 |
boolean equals(Object obj) | 判断两个对象是否相等 |
native int hashCode() | 返回该对象的哈希码值 |
final native Class<?> getClass() | 得到一个对象或者类的结构信息 |
final void wait() | 使当前线程进入等待 |
final native void notify() | 唤醒一个等待的线程 |
- toString() 方法
Object类中的toString()方法返回该对象的字符串表示,默认情况下,执行 Object 类中toString()方法得到的结果是对象的类型@哈希码,比如 User@6267c3bb。
这个结果很明显不太满足日常需要,因此在开发中一般会重写一个类的toString()方法,使其能够返回对象的所有属性值。
public class People {
private String name;
private int age;
public void eat() {
System.out.println(this.age + "岁的" + this.name + "正在吃饭");
}
// 省略 get()和 set()方法
@Override
public String toString() {
return "People{" + "name='" + name + '\'' + ", age=" + age + '}';
}
}
- equals() 方法
Object 类中的equals()方法的作用是比较两个对象的地址是否相同,实际上在Java中,“==”运算符比较引用类型已经是比较地址是否相同了,equals()方法的功能与它相比略显多余,因此在开发中很少使用equals()方法本身的功能。
一般情况下,如果需要使用到equals()方法,会将其重写成比较内容是否相同。比如 String 类中的equals()方法就进行了重写,它的作用是比较两个字符串内容是否相同。
import java.util.Objects;
public class People {
private String name;
private int age;
public void eat() {
System.out.println(this.age + "岁的" + this.name + "正在吃饭");
}
// 省略 get()和 set()方法
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
People people = (People) o;
return age == people.age && Objects.equals(name, people.name);
}
@Override
public String toString() {
return "People{" + "name='" + name + '\'' + ", age=" + age + '}';
}
}
- hashCode() 方法
Object 类中的hashCode()方法用于计算一个对象的 hash 码值,hash 码的作用是使用一串数字来示一个对象。
一般来说,如果一个类中重写了equals()方法,就必须重写hashCode()方法,并且参与计算 hash 码值的属性必须与equals()方法中参与比较的属性一致。这么做是为了让对象在 hash 表中尽可能均匀地分散,比如后面将会学到的 HashMap,底层比较对象是否相同时,就同时用到了equals()和hashCode()方法。
import java.util.Objects;
public class People {
private String name;
private int age;
public void eat() {
System.out.println(this.age + "岁的" + this.name + "正在吃饭");
}
// 省略 get()和 set()方法
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
People people = (People) o;
return age == people.age && Objects.equals(name, people.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public String toString() {
return "People{" + "name='" + name + '\'' + ", age=" + age + '}';
}
}
4.6 多态
- 多态是面向对象的三大特性之一,指的是同一个方法调用,由于对象不同可能会有不同的行为。
- 多态的前提是必须存在继承,并且子类重写了父类的方法,最重要的一点是父类引用要指向子类对象。
- 何为父类引用指向子类对象呢?比如Teacher类和Worker类继承自People类,那么当创建Teacher类对象或者Worker类对象时,是可以使用People类型的变量接收的,如下所示。
People people = new Teacher();
多态的实现主要表现在父类和继承该父类的一个或多个子类对某些方法的重写,多个子类对同一方法的重写可以表现出不同的行为。
public class Rubbish {
public void classify() {
System.out.println("垃圾分类");
}
}
public class DryRubbish extends Rubbish {
@Override
public void classify() {
System.out.println("干垃圾");
}
// 干垃圾独有的方法
public void showInfo() {
System.out.println("干垃圾分类完可以直接扔");
}
}
引用类型数据转换
- 引用数据类型也存在着类型转换,与其说是类型转换,不如说是转换一个对象的引用。
- 引用类型数据转换分为以下两种。
向上转型:父类引用指向子类对象,属于自动类型转换。
格式:父类类型 变量名 = 子类对象;
向下转型:子类引用指向父类对象,属于强制类型转换。
格式:子类类型 变量名 = (子类类型) 父类对象; - 向上转向隐藏了子类类型,提高了代码的扩展性,可以使一个方法的参数能够传入某个类的任意子类对象,但是多态会导致程序只能使用父类共性的内容,不能调用子类特有的方法。
- 向下转型则可以调用子类特有的方法,一般也可以称为强制类型转换。
- 使用向下转型时,一般会与instanceof关键字一起使用。instanceof关键字的作用是判断左边对象是否为右边类的实例,若是,则返回的boolean类型为true,否则,返回的boolean类型为false。
People people = new Teacher();
Java多态中变量与方法调用时的一套口诀是:编译时看左边;运行时,非静态方法看右边,成员变量、静态变量和静态方法看左边。
即在编译期间看左边的类中有无该方法或变量,如果没有则会报编译错误。在运行时,非静态方法子类会覆盖父类方法,因此实际运行的是右边子类对象的方法;成员变量不存在覆盖因此看左边的类;静态方法属于类不属于对象,因此也看左边的类。
4.7 抽象类
抽象的关键字是 abstract,不管是抽象类还是抽象方法,都用 abstract 关键字修饰,语法格式如下所示。
权限修饰符 abstract class 类名 {}
权限修饰符 abstract 返回值类型 方法名(参数列表);
注意:
- 抽象方法只有方法声明,没有方法体,它必须交给子类重写。子类重写抽象方法,也称作“实现”抽象方法。
- 子类如果也是抽象类,则不一定需要实现父类的抽象方法,而如果不是抽象类,则必须要实现父类中所有的抽象方法。
- 抽象方法必须被子类重写,因此抽象方法的访问修饰符不能是 private。
- 由于抽象方法没有具体的方法体,无法用一个抽象的对象调用它,因此抽象类不能被实例化。
- 抽象类可以有构造方法,它的构造方法作用是方便子类创建对象时给抽象类的属性赋值。
以一个图形类为案例。首先创建图形类、三角形类、矩形类、圆类,其中图形类具有名称属性、计算周长方法,另外三个类则继承自图形类;三角形类则拥有3条边a、b、c,矩形类拥有长width和高height,圆类则拥有半径radius,如下所示。
public abstract class Graph {
private String name;
public Graph(String name) {
this.name = name;
}
public abstract double calcPerimeter();
public void showPerimeter() {
double perimeter = calcPerimeter();
System.out.println(getName() + "的周长为:" + perimeter);
}
// 省略 get()/set()方法,下同
}
public class Triangle extends Graph {
private double a;
private double b;
private double c;
public Triangle(double a, double b, double c) {
super("三角形");
this.a = a;
this.b = b;
this.c = c;
}
@Override
public double calcPerimeter() {
return a + b + c;
}
}
public class Square extends Graph {
private double width;
private double height;
public Square(double width, double height) {
super("矩形");
this.width = width;
this.height = height;
}
@Override
public double calcPerimeter() {
return (width + height) * 2;
}
}
public class Circle extends Graph {
private double radius;
public Circle(double radius) {
super("圆形");
this.radius = radius;
}
@Override
public double calcPerimeter() {
return 2 * radius * 3.14;
}
}
4.8 接口
接口的作用主要有两种:
- 提供一种扩展性的功能,比如实现了 Serializable 接口的类就拥有了序列化的功能,实现了 Clonable 接口的类就拥有了克隆的功能。
- 提供一种功能上的约束,或者说是一种规范。比如在面向接口开发的编程思想中,创建了 OrderService 接口,规定了接口中拥有订单的增加、删除、修改、查询方法,那么不管是什么订单,只要实现了 OrderService 接口,就必须拥有这四个方法。
定义接口不是使用关键字class,而是用interface修饰,语法格式如下所示。
interface 接口名 [extends 父接口1, 父接口2, ...] {
// 常量定义
// 方法定义
}
在JDK 8以前,接口中的方法全部都是抽象方法,它们默认被 public abstract 修饰,因此在接口中定义方法就可以省略这两个关键字。在JDK 8及其之后,这个特性得到保留,并且还提供了 static() 方法和 default() 方法。
对于接口,可以通过子类去实现。实现接口的“子类”,往往称之为实现类。
接口中的抽象方法,必须要“子类”去“继承”接口并“重写”这些方法。
其语法格式为:
修饰符 class 类名 implements 接口1, 接口2... {
@Override
修饰符 返回值 抽象方法1() {
// 方法实现
}
@Override
修饰符 返回值 抽象方法2() {
// 方法实现
}
}
Java中类与类之间只有单继承,但是类与接口之间却允许有多实现。当一个类实现了多个接口时,只需要用逗号将这些接口隔开即可,如下所示:
class 类 implements 接口1, 接口2 {
// 方法实现
}
接口也允许继承,并且接口之间的继承允许多继承
接口的 static 方法和 default 方法
- 在 JDK8 之前,接口中的所有方法都是抽象方法,但这样就存在一个问题:一个接口可能会有很多的实现类,如果在未来的某个版本中,该接口新增了一个方法,那么在版本升级后,这个接口所有的实现类都会报错,开发者就不得不面临着大量的修改,这是极其不友好的。
- 因此在 JDK8 及以后的版本中,接口新增了用关键字 static 和 default 修饰的方法,分别为 static 方法和 default 方法,它们允许接口的方法有方法体。
接口的所有方法默认都是 public 修饰的,static 和 default 方法也一样,因此这两个关键字直接使用即可,语法格式如下所示。
public interface 接口 {
static void method1() {
// 方法实现
}
default void method2() {
// 方法实现
}
}
一个类实现一个接口时,可以不实现它的 default 方法,default 方法的使用方式就像是普通的成员方法一样。而 static 方法则更简单了,它的使用方式与类中的静态方法没有任何区别。
接下来给USB接口添加一个 static 方法和一个 default 方法,如下所示。
public interface USB {
void transfer();
default void charge() {
System.out.println("USB 接口正在充电");
}
static void install() {
System.out.println("正在安装 USB 驱动");
}
}
当给USB接口添加了这两个方法之后,其他类并没有报错,因为这两个方法并不强制实现类必须重写。
4.9 内部类
- 在描述事物时,若一个事物内部还包含其他事物,比如在描述汽车时,汽车中还包含发动机,这时发动机就可以使用内部类描述。
- 一个定义在其他类内部的类称为内部类,而这个其他类则称为外部类。
- 内部类分为成员内部类、静态内部类、局部内部类、匿名内部类四种。
成员内部类
- 成员内部类定义的位置与成员变量、成员方法同级。
- 成员内部类定义语法格式如下所示。
class 外部类 {
修饰符 class 内部类 {
// 内部类的成员变量和方法
}
}
//当访问成员内部类时必须通过外部类的对象访问,如下所示:
外部类名.内部类名 变量名 = new 外部类名(实参列表).new 内部类名(实参列表);
内部类与外部类之间的成员变量可以互相访问。
外部类访问内部类变量时非常简单,使用内部类的对象名.变量名即可获取内部类的变量,而内部类访问外部类变量时,则需要通过外部类名.this.变量名获取。
静态内部类
静态内部类的定义与成员内部类很相似,它与静态变量和静态方法平级,使用static关键字进行修饰,语法格式如下所示。
class 外部类 {
static class 内部类 {
// 内部类的成员变量和方法
}
}
//当访问静态内部类时,可以直接通过外部类名来创建对象,如下所示:
外部类名.静态内部类名 变量名 = new 外部类名.静态内部类名(实参列表);
静态内部类的定义与成员内部类的定义区别并不大,但需要注意的是,静态内部类中无法访问外部类的非静态属性和方法。
局部内部类
局部内部类定义方式与前面两个内部类的定义方式相似,只不过它是定义到代码块中,与局部变量平级,如下所示。
class 外部类 {
修饰符 返回值类型 方法名(参数列表) {
class 内部类 {
// 其他代码
}
}
}
匿名内部类
- 匿名内部类是局部内部类的一个引申。
- 当某个类可能只在某个代码块中才会使用到,并且这个类是某个接口的实现类,或者某个类的子类时,不必特意写这个类,直接创建接口或者抽象类即可。在创建过程中“顺便”重写它们的方法,这样就是一个匿名内部类的对象。
语法格式如下所示。
new 接口() | 父类() {
// 其他代码
}
总结
通过深入学习面向对象编程(OOP)的进阶内容,我对对象模型、设计原则和设计模式的应用有了更全面的理解。这种编程范式不仅显著提升了我的代码复用性和组织能力,还让我能够更好地应对复杂程序的设计挑战。
对象模型与设计原则
继承与多态:合理使用继承和多态极大地增强了程序的灵活性和扩展性。继承允许我们基于现有类创建新类,而多态则提供了动态绑定的能力,使得代码更加灵活和可维护。
SOLID原则:遵循SOLID原则(单一职责、开闭原则、里氏替换、接口隔离、依赖倒置)使我在设计阶段就能预见并避免潜在的问题,降低了后续维护的复杂度。这些原则帮助我编写出结构清晰、易于扩展和修改的代码。
团队合作与项目管理
面向对象编程强调了团队合作和项目管理的重要性。通过定义清晰的接口和抽象类,团队成员可以更容易地协同开发,减少了沟通成本和误解。良好的接口设计确保了模块之间的松耦合,提高了项目的可维护性和可测试性。
设计模式的应用
学习各种设计模式(如单例模式、工厂模式、观察者模式等)为我提供了处理复杂问题的有效工具。设计模式不仅是解决常见问题的最佳实践,还能帮助我在面对新问题时快速找到高效的解决方案。它们提供了一种标准化的方式,使得代码更加一致和易于理解。
总结与展望
这一章的学习让我对面向对象编程有了更深刻的认识,使我能够更自信地面对实际项目中的设计挑战。通过掌握这些高级概念和设计模式,我不仅提升了编程能力,还增强了软件工程意识。未来,我将继续探索更多设计模式和最佳实践,不断优化我的开发流程,以应对日益复杂的软件开发需求。
第5章 异常
5.1 异常概述
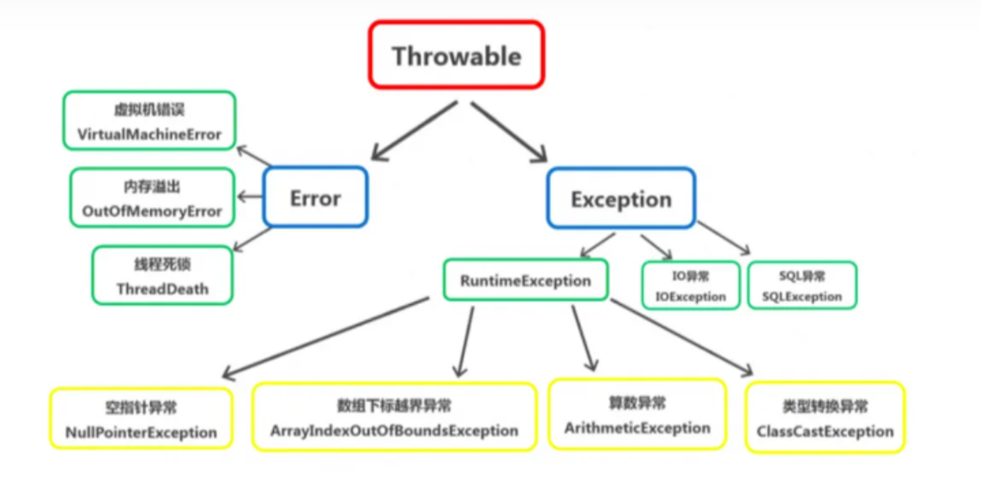
Java 中 异常(Exception) 与 错误(Error) 都继承自 Throwable 类。
Exception 分为 运行时异常(RuntimeException) 和 编译时异常 ,运行时异常 以外的异常称为 编译时异常。
RuntimeException 由于在编译时不会进行检查,因此又称为 不检查异常(UncheckedException),而编译时异常会在编译时进行检测,又称为 可检查异常(CheckedException)。
Java中异常体系结构如图所示。
Throwable 中定义了所有异常都会用到的3个重要方法:
| 方法签名 | 方法描述 |
|---|---|
String getMessage() | 返回此 throwable 的详细消息字符串。 |
String toString() | 返回此 throwable 的简短描述。 |
void printStackTrace() | 打印异常的堆栈跟踪信息。 |
- RuntimeException 和它的所有子类都是运行时异常,比如 NullPointerException、ArrayIndexOutOfBoundsException 等,这些异常在程序编译时不能被检查出,不强制处理。这些异常往往是由逻辑错误引起的,因此在编写程序时,应该从逻辑的角度尽可能避免这种异常情况。
- Exception和它的子类(不包括RuntimeException及其子类)统称为编译时异常。比如IOException、SQLException。
- 这些异常在编译时会被检查出,程序员必须对其进行显式处理,需要在方法中通过throws声明或try-catch捕获。
5.2 异常处理
一、抛出异常
Java 中提供了一个 throw 关键字,该关键字用于抛出异常。
Java 中的异常本质上也是类,抛出异常时,实际上是抛出一个异常的对象,并提供异常文本给调用者,最后结束该方法的运行。
抛出异常语法格式如下:
throw new 异常名称(参数列表);
对于数组的操作,可以定义一个方法用来获取数组指定索引的值,当索引不合法时,通过抛出异常的方式来通知调用者。
二、声明异常
- 程序仅仅抛出异常,而不对异常进行处理,是没有任何意义的,但处理异常之前,需要知道调用的方法可能会抛出哪些异常,从而有针对性地处理。
- 因此,需要将异常声明到方法上,让调用者知道这个方法可能会抛出什么异常。
声明异常使用throws关键字,语法格式如下:
修饰符 返回值类型 方法名(参数列表) throws 异常类名1, 异常类名2, ... {
// 方法体
}
如果方法中抛出的是运行时异常,编译期就不会强制要求开发者将异常声明在方法上,而如果抛出的是编译时异常,则必须将这些异常全部声明在方法上。
三、捕获异常
- 如果程序出现了异常,自己又解决不了,就需要将异常声明出来,交给调用者处理。
- 在上面已经将异常进行了声明,此时调用者如果已经知道被调用方法可能出现哪些异常,就可以针对这些异常进行不同的处理。
- 处理异常使用 try…catch…finally 结构,try 用于包裹住可能出现异常的代码块,在 catch 中进行异常捕获,并处理异常,finally则是在抛出异常或者异常处理后执行,一般是清理资源,比如关闭文件或数据库连接。
- 当异常不进行处理时,发生异常的方法就会立即结束运行,而如果使用 try…catch 来处理,程序就会继续运行下去。
- 一个 try 必须跟随至少一个 catch 或者 finally 关键字。即 try…catch 结构、try…finally 结构和try…catch…finally 结构都是合法的。
- 异常的处理是链式的,如果存在着 main -> methodA -> methodB -> methodC 的调用链,此时 methodC 发生了异常,就会抛给 methodB 去处理。如果 methodB 处理不了或者没有处理,就会再抛给 methodA 处理,如果 methodA 依然没法处理,就会抛给 main 方法处理,也就是交给虚拟机处理,而虚拟机处理异常的方式简单粗暴:直接打印异常堆栈信息并停止程序的运行。因此,在开发中为了防止死机,程序能进行处理的异常要尽可能交由程序处理。
- 此外,如果一个异常并没有在方法上声明,则在代码中依然可以捕获这个异常。声明异常只是为了方便开发者知道要处理哪些异常。
5.3 异常进阶
一、自定义异常
自定义异常语法很简单,就是创建一个类并继承 Exception 或者 RuntimeException,提供相应的构造方法。
自定义异常语法格式如下:
修饰符 class 自定义异常名 extends Exception 或 RuntimeException {
public 自定义异常名() {
// 默认调用父类无参构造方法
}
public 自定义异常名(String msg) {
// 调用父类具有异常信息的构造方法
super(msg);
}
}
二、方法重写中的异常
子类重写父类方法时,编译时异常声明遵循如下两点即可。运行时异常不受这两点约束。
- 父类方法没有声明异常,子类重写该方法不能声明异常,如下所示。
public class Demo7Parent {
public static void main(String[] args) {
}
// 1 usage 1 inheritor
class Parent {
// no usages 1 override
public void method() {
}
}
// no usages
class Child extends Parent {
// 编译错误,父类方法没有声明异常,子类重写时也不能声明
public void method() throws Exception {
}
}
}
- 父类方法声明了异常,子类重写该方法可以不声明异常,或者只声明父类的异常或该异常的子类,如下所示:
public class Demo8Parent {
public static void main(String[] args) {
}
// 1 usage 1 inheritor
class Parent {
// no usages 1 override
public void method1() throws IOException {
}
}
// no usages
class Child extends Parent {
@Override
public void method1() throws FileNotFoundException {
}
}
}
总结
通过学习第5章的异常处理,我对程序中的错误处理有了更深入的理解。掌握异常的分类和处理方式,使我能更有效地维护代码的健壮性和可靠性。
内置异常:了解常见的内置异常类(如NullPointerException, ArrayIndexOutOfBoundsException),帮助我在编写代码时预见并预防潜在问题。
检查型 vs 非检查型异常:合理区分这两类异常,设计出更加严谨和灵活的错误处理机制。
try-catch-finally块:使用try捕获异常,catch处理特定类型的异常,finally确保必要的清理操作,增强了代码的稳定性和可读性。
自定义异常:创建自定义异常类,使代码更加清晰和有针对性,提高了异常处理的精确度和可维护性。
最佳实践:
避免过度捕获,只处理确实需要处理的异常。
提供有意义的错误信息,便于调试。
不要忽略异常,适当处理或记录。
使用日志记录异常信息,方便后续分析。
第6章 Java常用类
6.1 包装类
让基本数据类型也可以像对象一样进行操作,在设计类时为每个基本数据类型设计了一个对应的类,这样,与这8个基本数据类型对应的类统称为包装类(Wrapper Class) 。
| 包装类 | 基本数据类型 |
|---|---|
| Boolean | boolean |
| Character | char |
| Byte | byte |
| Short | short |
| Integer | int |
| Long | long |
| Float | float |
| Double | double |
基本数据类型与包装类
Integer中提供了大量让字符串-包装类-基本类型之间进行转换的方法,如下表所示。
| 构造方法 | 方法描述 |
|---|---|
Integer(int value) | 创建一个 Integer 对象,它的值为 value 的值。 |
Integer(String value) | 创建一个 Integer 对象,它的值为 value 对应的 int 的值。 |
| 静态方法 | 方法描述 |
|---|---|
static Integer valueOf(int value) | 将 int 类型的 value 转换成 Integer 对象。 |
static Integer valueOf(Stringt value) | 将 value 对应的 int 类型的值转换成 Integer 对象。 |
static int parseInt(String value) | 将 String 类型的 value 转换成 int 类型。 |
static String toString(int value) | 将 int 类型的 value 转换成字符串。 |
| 成员方法 | 方法描述 |
|---|---|
byte byteValue() | 将 Integer 转换成 byte 值。 |
int intValue() | 将 Integer 转换成 int 值。 |
String toString() | 将当前 Integer 对象转换成字符串。 |
自动装箱与拆箱
- 基本类型数据处于需要对象的环境中时,会自动转换为包装类,这就称为自动装箱。
- 而包装类在需要数值的环境中时,会自动转换成基本类型,这称为自动拆箱。
- 自动装箱可以把基本数据类型直接赋值给包装类,而自动拆箱可以把包装类直接赋值给基本数据类型。
大数字运算
- BigInteger
BigInteger 是 Java 中表示大整型的类,它可以用来计算远大于 long 类型的数值。
| 方法签名 | 方法描述 |
|---|---|
BigInteger add(BigInteger num) | 加法运算 |
BigInteger subtract(BigInteger num) | 减法运算 |
BigInteger multiply(BigInteger num) | 乘法运算 |
BigInteger divide(BigInteger num) | 除法运算 |
BigInteger[] divideAndRemainder(BigDecimal num) | 求余运算 |
int intValue() | 将 BigInteger 转换成 int 类型 |
- BigDecimal
BigDecimal 保留小数位使用的是 setScale() 方法,指定保留小数位个数以及保留方式,保留方式都是以 BigDecima 中静态常量的方式定义的,如下表所示。
| 保留方式 | 描述 |
|---|---|
| ROUND_CEILING | 向正无穷方向舍入,即向上取整。 |
| ROUND_DOWN | 向0方向舍入,对于正数而言是向下取整,对于负数而言是向上取整。 |
| ROUND_FLOOR | 向负无穷方向舍入,即向下取整。 |
| ROUND_HALF_DOWN | 向最近的一边舍入,如果两边距离相等,则向下舍入,比如1.55保留一位小数为1.5。 |
| ROUND_HALF_EVEN | 向最近的一边舍入,如果两边距离相等,保留位数是奇数就采用ROUND_HALF_UP,偶数就采用ROUND_HALF_DOWN。 |
| ROUND_HALF_UP | 四舍五入。 |
| ROUND_UP | 向远离0的方向舍入,对于正数而言是向上取整,对于负数而言是向下取整。 |
6.2 String 类
- String 类对象代表不可变的 Unicode 字符序列,内部使用了一个用 final 修饰的字符数组存储数据,一旦 String 的值确定了,就不能再改变了,每次通过截取、拼接等操作字符串时,都产生一个新的字符串。
- Java 为了方便起见,在使用字符串时也可以像基本数据类型一样直接对其进行赋值,但依然需要了解 String 的构造方法,如下表所示。
| 方法签名 | 方法描述 |
|---|---|
String() | 创建一个空字符串。 |
String(String s) | 创建一个字符串对象,该字符串的内容与 s 相同。 |
String(char[] value) | 创建一个字符串对象,使用字符数组作为该字符串的内容。 |
String(byte[] bytes) | 创建一个字符串对象,使用默认编码将字节数组转换成字符串。 |
String 类查找方法
字符串中提供了大量的查找方法,通过这些方法可以很方便地获取字符串的一些信息。String类中与查找相关的方法如下表所示。
| 方法签名 | 方法描述 |
|---|---|
int length() | 获取字符串长度。 |
char charAt(int i) | 获取字符串指定索引位置的字符。 |
int indexOf(int ch) | 查找指定字符在字符串中的索引位置。 |
boolean startsWith(String s) | 判断字符串是否以指定字符串开头。 |
boolean endsWith(String s) | 判断字符串是否以指定字符串结尾。 |
boolean contains(String s) | 判断字符串中是否包含指定字符串。 |
String 类转换方法
用户查找字符串的一些信息,为的是根据查询结果对字符串进行一些处理,因此 String 类中还定义了一些转换字符串的方法,如下表所示。
| 方法签名 | 方法描述 |
|---|---|
String[] split(String regex) | 将一个字符串按照某些字符串分割成字符串数组。 |
char[] toCharArray() | 将字符串转换成字符数组。 |
byte[] getBytes() | 将字符串按照默认编码转换成字节数组。 |
String trim() | 去除字符串前后的所有空格。 |
String toUpperCase() | 将字符串中所有字母转大写。 |
String toLowerCase() | 将字符串中所有字母转小写。 |
String substring(int index) | 从 index 开始截取字符串,直到字符串末尾结束。 |
String substring(int beginIndex, int endIndex) | 从 beginIndex 开始截取字符串,到索引 endIndex-1 结束。 |
String replace(String target, String value) | 将字符串中所有的 target 替换成 value。 |
String 类中的其他方法
除了查找、转换一类的方法之外,String类还提供了一些其他的方法,比如比较字符串是否相同、判断字符串是否为空等方法,如下表所示。
| 方法签名 | 方法描述 |
|---|---|
boolean isEmpty() | 判断一个字符串是否为空字符串。 |
boolean equals(String s) | 判断两个字符串内容是否相同。 |
boolean equalsIgnoreCase(String s) | 判断两个字符串内容是否相同,忽略大小写。 |
int compareTo(String s) | 按照字典顺序比较两个字符串前后顺序。 |
6.3 StringBuffer 类与 StringBuilder 类
一、StringBuffer类
- String代表着不可变的字符序列,每次拼接、截取字符串操作,都是重新创建一个字符串对象,如果这类操作过多,就会在内存中留下大量的无用字符串,比较占用内存。
- StringBuffer类是抽象类AbstractStringBuilder的子类,代表可变的Unicode字符序列,即对StringBuffer执行转换操作时,都不会创建新的StringBuffer对象,自始至终操作的都是同一个字符串。
- StringBuffer并没有像String一样提供了简单的赋值方式,必须创建它的构造方法才可以。
StringBuffer 类中的构造方法如下表所示。
| 方法签名 | 方法描述 |
|---|---|
StringBuffer() | 创建一个没有字符的 StringBuffer 对象。 |
StringBuffer(String s) | 创建一个字符串为 s 的 StringBuffer 对象。 |
StringBuffer 类中的主要方法如下表所示:
| 方法签名 | 方法描述 |
|---|---|
StringBuffer append(Type t) | 将指定内容添加到字符串末尾。 |
StringBuffer delete(int start, int end) | 删除从 start 开始到 end-1 结束的字符串。 |
int indexOf(String s) | 获取指定字符串在该 StringBuffer 中第一次出现的索引位置。 |
StringBuffer replace(int start, int end, String value) | 将 start 到 end-1 位置的字符串替换成 value。 |
StringBuffer reverse() | 反转当前字符串。 |
void setLength(int length) | 设置字符串长度,超出长度的内容会被舍弃。 |
二、StringBuilder 类
- StringBuffer 类和 StringBuilder 类非常类似,都是继承自抽象类 AbstractStringBuilder 类,均代表可变的Unicode字符序列。
- StringBuilder 类和 StringBuffer 类方法一模一样,这里不再演示。不过 StringBuilder 不是线程安全的,这是与 StringBuffer 的主要区别:
(1)StringBuffer 做线程同步检查,因此线程安全,效率较低。
(2)StringBuilder 不做线程同步检查,因此线程不安全,效率较高。 - 因此在开发中如果不涉及字符串的改变,建议使用String,如果涉及并发问题,建议使用StringBuffer,如果不涉及并发问题,建议使用StringBuilder。
三、链式编程
在前面介绍 StringBuffer 时,提到它的append()方法返回的值其实是当前对象,如下所示。
public synchronized StringBuffer append(int i) {
toStringCache = null;
super.append(i);
return this;
}
该方法返回的是当前的 StringBuffer 对象,这也就意味着可以在调用方法完毕之后再立即调用 StringBuffer 的其他方法,这种调用方式习惯上称之为链式编程。
6.4 时间和日期相关类
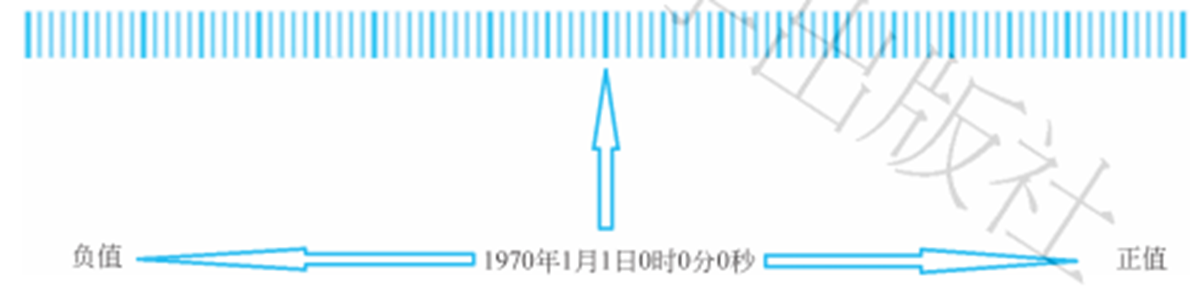
- 以1970 年1月1日 00:00:00(unix纪元)为基准时间,定义为0刻度,时间向前为负值,向后为正值,每一个刻度为1毫秒,称为时间戳,如下图所示。
- 因为时间戳可能会非常长,因此 Java 中使用long类型来记录时间戳,用 long 类型的变量来表示时间,从基准时间往前几亿年,往后几亿年都能表示。
- 获取当前时间的“时刻数值”的方式非常简单,可以使用:
long now=System.currentTimeMillis();
Date 类
| 构造方法 | 方法描述 |
|---|---|
Date() | 创建一个 Date 对象,该对象代表着当前时间。 |
Date(long time) | 创建一个 Date 对象,该对象代表着传入的时间戳对应的时间。 |
| 成员方法 | 方法描述 |
|---|---|
boolean before(Date when) | 判断当前 Date 是否在指定时间之前。 |
boolean after(Date when) | 判断当前 Date 是否在指定时间之后。 |
boolean equals(Object obj) | 比较两个日期是否相等。 |
long getTime() | 返回当前 Date 对应的时间戳。 |
long setTime(long time) | 将当前 Date 时间修改为指定的时间戳。 |
SimpleDateFormat 类
- SimpleDateFormat 类是 Java 中的时间格式化类,通过该类可以将时间转换成用户想要的格式。
- SimpleDateFormat 对象在创建时需要指定时间格式,时间的格式通过一些特定的字符表示,当格式化时间遇到这些格式字符时,就会转换成对应的时间。
时间格式字符如下表所示。
| 格式字符 | 描述 |
|---|---|
y | 当出现 y 时,会将 y 替换为年。 |
M | 当出现 M 时,会将 M 替换为月。 |
d | 当出现 d 时,会将 d 替换为日。 |
h | 当出现 h 时,会将 h 替换为时(12 小时制)。 |
H | 当出现 H 时,会将 H 替换为时(24 小时制)。 |
m | 当出现 m 时,会将 m 替换为分。 |
s | 当出现 s 时,会将 s 替换为秒。 |
S | 当出现 S 时,会将 S 替换为毫秒。 |
D | 当出现 D 时,获得当前时间是今年的第几天。 |
w | 当出现 w 时,获得当前时间是今年的第几周。 |
W | 当出现 W 时,获得当前时间是本月的第几周。 |
Calendar 类
Date 类一般用于表示时间,如果想计算时间,虽然通过时间戳也可以实现,但比较麻烦。Calendar 是 Java 中的日历类,提供了日期时间的计算方式,通过 Calendar 类,可以准确地对年、月、日、时、分、秒进行计算。
Calendar类中的主要方法如下表所示
| 方法签名 | 方法描述 |
|---|---|
static Calendar getInstance() | 获取当前时间的 Calendar 对象。 |
int get(int field) | 获取指定字段的时间,如 Calendar.HOUR 是获取小时。 |
void set(int field, int value) | 将指定时间字段的值设置为 value。 |
void set(int y, int mon, int d, int h, int m, int s) | 直接设置年月日时分秒。 |
void set(int y, int m, int d) | 直接设置年月日。 |
void add(int field, int value) | 为指定时间字段增加 value。 |
Date getTime() | 获取当前 Calendar 对应的 Date 对象。 |
void setTime(Date date) | 将当前 Calendar 的时间修改为 date 代表的时间。 |
在Calendar中可以设置指定字段的时间,如年、月、日,但方法中的时间字段是整数,Calendar中定义了很多静态常量,用这些静态常量可定义时间字段,如下表所示。
| 时间字段 | 字段描述 |
|---|---|
YEAR | 表示年份。 |
MONTH | 表示月份,0 表示 1 月,1 表示 2 月,…11 表示 12 月。 |
DAY_OF_MONTH | 获取日。 |
DAY_OF_YEAR | 获取本年的第几天。 |
HOUR_OF_DAY | 获取时,24 小时制。 |
HOUR | 获取时,12 小时制。 |
MINUTE | 获取分。 |
SECOND | 获取秒。 |
MILLISECOND | 获取毫秒。 |
DAY_OF_WEEK | 获取星期,1 表示星期日,2 表示星期一,…7 表示星期六。 |
6.5 其他常用类
Math 类
| 方法签名 | 方法描述 |
|---|---|
static double ceil(double num) | 向上取整。 |
static double floor(double num) | 向下取整。 |
static long round(double num) | 四舍五入。 |
static int max(int num1, int num2) | 获取 num1 和 num2 之间的较大值。 |
static int min(int num1, int num2) | 获取 num1 和 num2 之间的较小值。 |
static double pow(double num1, double num2) | 计算 num1 的 num2 次幂。 |
static double sqrt(double num) | 计算 num 的平方根。 |
static double random() | 获取 [0, 1) 之间的随机数。 |
Random 类
| 方法签名 | 方法描述 |
|---|---|
int nextInt() | 获取一个随机整数。 |
int nextInt(int bound) | 获取一个在 [0, bound) 之间的随机整数。 |
long nextLong() | 获取一个随机 long 值。 |
double nextDouble() | 获取一个随机浮点数。 |
boolean nextBoolean() | 获取一个随机 boolean 值。 |
UUID 类
UUID 是通用唯一识别码(Universally Unique Identifier)的缩写,其目的是让分布式系统中的所有元素都能有唯一的辨识信息,而不需要通过中央控制端做辨识信息的指定。如此一来,每个人都可以创建不与其他人冲突的UUID。
UUID由一组32位十六进制数字和4个“-”组成,编写程序生成之。
枚举类
枚举是Java 5之后新增的特性,它是一种新的类型,允许用常量表示特定的数据片段,而且全部都以类型安全的形式来表示。
枚举使用enum关键字定义,如下所示。
修饰符 enum 枚举类名 {
枚举值 1,
枚举值 2,
枚举值 3,
...
}
枚举值的命名方式与常量相同,要求以大写字母命名,单词之间使用下划线分隔。
如下代码就是定义了一个季节枚举。
public enum Season {
SPRING, SUMMER, AUTUMN, WINTER;
}
枚举的目的是列举出某个字段所有允许的取值,这些取值可能存在中文,因此在不少企业中放开了对中文的限制,允许枚举值使用中文定义。
下面的枚举在一些企业里也是符合开发规范的。
// 类名依然不允许中文
public enum Week {
星期一, 星期二, 星期三, 星期四, 星期五, 星期六, 星期日;
}
总结
包装类与字符串处理
包装类:Java为基本类型提供包装类(如Integer, Double),支持自动装箱和拆箱,简化代码。
String:不可变字符序列,使用+拼接。常用方法包括查找、替换、分割等。
StringBuffer/Builder:可变字符序列,StringBuffer线程安全,StringBuilder性能更优。
时间日期API
java.time:Java 8引入的新API,如LocalDate, LocalTime, LocalDateTime,替代旧的Date和Calendar,更直观易用。
常用工具类
Math:数学运算。
Random:生成随机数。
File:文件操作。
异常处理类和集合类:管理和处理错误及数据结构。

















 976
976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









