







 本文详细介绍了MySQL中数据的管理操作,包括使用INSERT、REPLACE、LOAD DATA INFILE进行数据插入,DELETE、TRUNCATE进行数据删除,UPDATE与REPLACE进行数据更新,以及SELECT进行复杂查询。内容涵盖基本查询、集合函数、分组查询、子查询和连接查询等,适合MySQL初学者和进阶学习者参考。
本文详细介绍了MySQL中数据的管理操作,包括使用INSERT、REPLACE、LOAD DATA INFILE进行数据插入,DELETE、TRUNCATE进行数据删除,UPDATE与REPLACE进行数据更新,以及SELECT进行复杂查询。内容涵盖基本查询、集合函数、分组查询、子查询和连接查询等,适合MySQL初学者和进阶学习者参考。
纸上得来终觉浅,绝知此事要躬行,不要只看不做,要多动手哦!
目录
1、数据的添加,insert、repalce、load data infile
1.2、添加本地文件中的数据(还可导出),load data infile
1、数据的添加,insert、repalce、load data infile
1.1 、insert、repalce
注:repalce相较于insert多出了修改功能,对于repalce来说当添加的数据主键或唯一表示相同时会对原数据进行修改
/*insert、repalce、load data infile*/
create table if not exists s1(
id int unsigned not null auto_increment primary key,
name varchar(20) not null
)engine=innodb default charset=utf8mb4;
insert s1 value (null,'wzt');
insert into s1 value(null,'yz');
insert into s1 values(null,'w'),(null,'z'),(null,'t');
replace into s1 values(null,'y'),(null,'z');/*replace与insert作用一样,区别是当主键或唯一约束出现数据重复时会自动修改*/
replace into s1 value(1,'xk');/*主键id出现重复自动修改*/
select * from s1;1.2、添加本地文件中的数据(还可导出),load data infile
注:需要开启服务端和客户端的一些权限local-infile=1 secure_file_priv=''。文件中的数据也要符合格式 :假如待导入用户信息表的文本文件名为 my_user_info.txt,内容如下所示,换行符采用 \n ,每行代表对应表的一行记录,其中 || 作为字段分隔符,而 \N 表示对应字段为空值 null。如下图所示
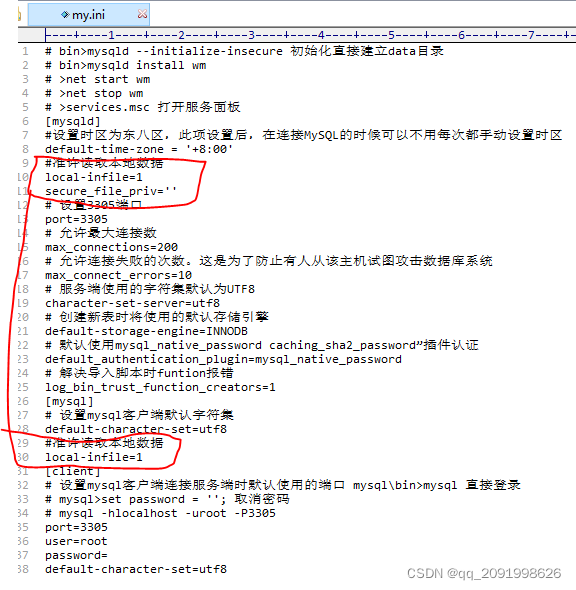
3||张三||22||北京||2012-09-19 00:00:00
4||李明||32||\N||2017-05-12 00:00:00
5||孙权||12||广州||\N
/*load data infile,读取文件中的数据进行表数据的添加删除*/
create table if not exists s2(
id int unsigned not null auto_increment primary key,
bookname varchar(50) not null,
zhuzhe varchar(50),
price float
)engine=innodb default charset=utf8mb4 auto_increment=20220221000;
load data local infile 'd:/xiaoshuo.txt' into table s2
character set utf8
fields terminated by ','
optionally enclosed by ''
escaped by '\\'
lines terminated by '\n';/*将txt中的数据读取到表中*/
select * from s1 into outfile 'd:/xiaoshuo.txt';
select * from s2;2、数据的删除、delete、truncate
注:delete 一条记录一条记录删除,删除所有的时候,效率低,但它灵活 可以加上条件会触发删除触发器
truncate 直接截断数据,auto_increment 恢复默认 , 不触发删除触发器也没有影响行,删除所有的时候,效率高,只能删除截断数据
create table if not exists s3(id int);
insert into s3 values (1),(2);
select * from s3;
delete from s3;/*删除表中所有记录*/
delete from s1 where id=1;/*删除id为1的数据*/
delete from s1 where name='wzt';/*删除名为wzt的数据*/
delete from s1 where name='%z%';/*删除名含z的数据*/
truncate table s3;/*truncate 直接截断数据,auto_increment 恢复默认 ,*/3、数据的修改、update、replace
注:replace只有在主键或唯一标识相同时才会进行修改,否则以新数据进行添加
/*改 update、replace*/
insert into s2 values(2,'斗罗大陆','唐家三少',255),(3,'天珠变','唐家三少',33.2),(4,'酒神','唐家三少',22);
select * from s2;
update s2 set bookname='完美世界',zhuzhe='辰东',price=66.6 where id=1;
update s2 set price=price-10 where zhuzhe='唐家三少';
update s2 set price=price+100 where zhuzhe like '%三%';
replace into s2 value(1,'遮天','辰东',66.6);
4、数据的查询
4.1、select 基本查询
| ifnull()如果为空查询 | if()真假查询 |
| 简单查询 | limit条数查询(分页) |
| order by 排序查询(asc升,desc降) | 控制位置和别名 |
| where条件查询 | null查询、is null、is not null |
| 计算列查询 | 指定多个查询in()、in not() |
| 范围查询between and、not between and | regexp 正则表达式查询 |
| like 模糊查询 | distinct 消除重复查询 |
select ifnull(null,4),if(0,'真','假');/*ifnull(c1,c2)判断c1是否为空,如果c1为空输出c2,如果不为空输出c1,。if(f,c1,c2)如果f为真则输出c1反之c2*/
create table if not exists t13(
id int unsigned not null auto_increment,
uname varchar(20) not null,
gender enum('男','女') default '男',
sfzh varchar(20) not null,
brith varchar(20) generated always as (concat(mid(sfzh,7,4),'-',mid(sfzh,11,2),'-',mid(sfzh,13,2))),
st1 varchar(10) not null,
st2 varchar(10) not null,
ywcj int not null,
sxcj int not null,
yycj int not null,
zcj int generated always as (ywcj+sxcj+yycj),
zst varchar(30) generated always as (concat(st1,' ',st2)),
zgender varchar(10) generated always as (if(gender='男','先生','女士')),
primary key(id)
)engine=InnoDb default charset=utf8mb4 auto_increment=2022021800;
insert into t13(uname,gender,sfzh,st1,st2,ywcj,sxcj,yycj) value('yz','男','412525199903038888','hello','wold',50,25,30);
insert into t13(uname,gender,sfzh,st1,st2,ywcj,sxcj,yycj) value('xk','男','412525199903038888','hello','wold',25,25,10);
insert into t13(uname,gender,sfzh,st1,st2,ywcj,sxcj,yycj) value('王小红','女','412525200403038888','hello','wold',60,29,40);
insert into t13(uname,gender,sfzh,st1,st2,ywcj,sxcj,yycj) value('李小丽','女','412525200403038888','hello','wold',70,23,50);
insert into t13(uname,gender,sfzh,st1,st2,ywcj,sxcj,yycj) value('夏雨荷','女','412525200403038888','hello','wold',97,55,80);
insert into t13(uname,gender,sfzh,st1,st2,ywcj,sxcj,yycj) value('夏紫薇','女','412525008803038888','hello13125999780kljoi','wold',97,55,80);
insert into t13(uname,gender,sfzh,st1,st2,ywcj,sxcj,yycj) value('小燕子','女','412525008803038888','hello13125999780kljoi','123',97,55,80);
insert into t13(uname,gender,sfzh,st1,st2,ywcj,sxcj,yycj) value('yaozeng','女','412525008803038888','hello13125999780kljoi','66663',97,55,80);
insert into t13(uname,gender,sfzh,st1,st2,ywcj,sxcj,yycj) value('尔康','男','412525008803038888','hello13125999780kljoi','66663',97,55,80);
insert into t13(uname,gender,sfzh,st1,st2,ywcj,sxcj,yycj) value('迪迦','男','412525008803038888','hello13125999780kljoi','计科',97,55,80);
insert into t13(uname,gender,sfzh,st1,st2,ywcj,sxcj,yycj) value('赛罗','男','412525008803038888','hello13125999780kljoi','经管',97,55,80);
insert into t13(uname,gender,sfzh,st1,st2,ywcj,sxcj,yycj) value('卡尔蜜拉','女','412525008803038888','hello13125999780kljoi','计科',97,55,80);
insert into t13(uname,gender,sfzh,st1,st2,ywcj,sxcj,yycj) value('银河','男','412525008803038888','hello13125999780kljoi','教艺',97,55,80);
select * from t13;
select id '学号', uname '姓名' from t13;/*查询学生学号和姓名,并标注列名*/
select * from t13 limit 2;/*查询两条数据*/
select * from t13 limit 3,5;/*查询第三条到第五条的数据,可用于分页*/
select * from t13 order by zcj asc ;/*按总成绩升序查询*/
select * from t13 order by zcj desc;/*按总成绩降序查询*/
select * from t13 order by zcj desc,yycj desc;/*先按照总成绩降序如果总成绩一样在按照英语成绩降序*/
select id '学号',uname '姓名', gender '性别',sfzh '身份证号',brith '出生日期',st1 '备用一',st2 '备用二',ywcj '语文成绩',sxcj '数学成绩',yycj '英语成绩',zcj '总成绩',zst '备用',zgender '称呼'
from t13 order by id asc;/*查询、添加别名显示并按照学号升序排序*/
select t.id,t.uname,t.gender,t.sfzh,t.brith,t.st1,t.st2,t.ywcj,t.sxcj,t.yycj,t.zcj from t13 t;/*为表起别名查询,可防止连表查询时出现字段名重复冲突*/
show create table t13;/*查询列的位置列的个数*/
/*查询计算列*/
select 2*3,25*25;
select 3*3 from dual;
select uname '姓名',3+3 '成绩' from t13;
select uname '姓名',ywcj+100 '语文成绩' from t13;
/*条件查询 where*/
select * from t13 where gender='男';
select * from t13 where gender!='男';
select * from t13 where zcj>=100;
select * from t13 where zcj<>143;/*除了143之外说的数据*/
select * from t13 where 1=1;/*where后面为真是执行查询,反之查询为空*/
select * from t13 where 1!=1;
select * from t13 where true;
select * from t13 where false;
select * from t13 where not false;
select * from t13 where not true;
/*null、is null、is not null*/
alter table t13 add age tinyint unsigned after brith;
select * from t13 where age=null;/*语句没有错误,但是没有结果,应该用下面的方法*/
select * from t13 where age is null;
select * from t13 where gender is not null;
/*in()、not in()*/
select * from t13 where id in(2022021800,2022021804,2022021802);/*查询这三条数据*/
select * from t13 where id not in(2022021800,2022021804,2022021802);/*查询这三条以外的数据*/
/*between and、not between and 一般用于数字、时间*/
select * from t13 where zcj between 100 and 130;/*查询总成绩在100-130*/
select * from t13 where zcj not between 100 and 130;/*查询总成绩在100-130范围以外的*/
/*模糊查询 like、 %代表一个或多个符号、 _代表一个符号 */
select * from t13 where uname like '李%';/*所有姓李的*/
select * from t13 where uname like '%小%';/*所有名字中右小的*/
select * from t13 where uname like '李_';/*姓李,且只有单个名字如:李丽*/
select * from t13 where uname like '__';/*两个字的名字如:小米、小黑*/
select * from t13 where uname like '%小%' or zcj=6;/*名字中有小或成绩为6*/
/*正则表达式*/
select 'abkc' regexp '[a-z]{4}';/*是否有四位小写字母组成,是1,否0*/
alter table t13 modify st1 varchar(100);
select * from t13 where uname regexp '^..$';/*查询名字只有两个字的*/
select * from t13 where uname regexp '^[a-z][A-Z]$';/*查询名字全是英文的的*/
select * from t13 where st1 regexp '.*1[3,5,8][0-9]{9}';/*查询st1里有电话号码的*/
/*消除重复*/
select distinct * from t13;/*distinct消除重复*/4.2、集合函数、分组查询、子查询
注:所需的‘t13’表格在4.1标题中
| count(*)统计人数 | max()最大 |
| min()最小 | avg() 平均 |
| sum()和 | row_number()排号 |
| rank() dense_rank()排名 | 等级查询 |
| group by 分组查询 | 分组条件 having |
| 子查询 |
/*集合函数、分组查询*/
select count(*) from t13;/*查询有几条数据*/
select count(1) from t13;/*查询有几条数据*/
select count(0) from t13;/*查询有几条数据*/
select count(distinct st2) from t13 where id in(2022021811,2022021812,2022021813,2022021814);/*查询st2这几条数据有几个专业*/
select max(zcj)'最高成绩',min(zcj) '最低成绩',avg(zcj) '平均成绩',sum(zcj) '成绩总合',count(zcj) '学生人数' from t13;
select max(zcj) from t13;
/*select * from t13 where zcj=max(zcj);注:语句错误,集合函数不能直接在函数中使用,正确语句如下*/
select * from t13 where zcj=(select max(zcj) from t13 );/*使用子语句查询最高分数的学生信息*/
/*排号*/
select row_number() over () 序号,id,uname from t13;
select row_number() over (order by zcj desc) 序号, id,uname,zcj from t13;
/*排名*/
select id,uname,zcj,concat('第',rank() over(order by zcj desc),'名') 名次 from t13;/*如果成绩一样会出现如:第1名、第1名、第3名*/
select id,uname,zcj,concat('第',dense_rank() over (order by zcj desc),'名') 名次 from t13;/*如果成绩一样会出现如:第1名、第1名、第2名*/
select first_value(zcj) over (partition by id order by zcj desc),uname,gender from t13;
/*查询第二名学生信息 as可以保证输出多条数据,如果有多个第二名*/
select * from (select concat(dense_rank() over (order by zcj desc)) as lev,t13.* from t13) as a where lev=2 ;
/*查询第二名的成绩*/
select distinct zcj from (select concat(dense_rank() over (order by zcj desc)) as lev,zcj from t13) as a where lev=2;
/*分组查询 group by*/
select gender '性别', count(*) '人数' from t13 group by gender;
select st2 '专业', count(*) '人数' from t13 where id in(2022021811,2022021812,2022021813,2022021814) group by st2;
/*分组条件 having*/
select concat(ifnull(st2,'没有'),'专业') 专业,count(*) '人数' from t13 group by st2 having count(*)>1;
/*根据性别分组统计每组中的最高成绩*/
select gender '性别',max(zcj) from t13 group by gender;
create table s(
id int unsigned auto_increment,
name varchar(30),
course varchar(30),
score tinyint unsigned,
primary key(id)
);
insert into s value(null,'李四','语文',30);
insert into s value(null,'李四','数学',30);
insert into s value(null,'李四','英语',30);
insert into s value(null,'张三','语文',60);
insert into s value(null,'赵强','英语',68);
select * from s;
/*查询各科人数*/
select course '课程', count(*) '人数' from s group by course;
/*查询各科最高成绩的学生信息*/
select * from (select row_number() over(partition by course order by score desc) as num,s.* from s) as a where num=1;
/*查询各科前两名的学生信息*/
select * from (select row_number() over(partition by course order by score desc) as num,s.* from s) as a where num<=2;
/*学生英语成绩,优秀>=90,良好>=80,及格>=60 补考<60*/
select id,uname,yycj,if(yycj>=90,'优秀',if(yycj>=80,'良好',if(yycj>=60,'及格','补考'))) '等级' from t13;
select id,uname, yycj,
case
when yycj>=90 then '优秀'
when yycj>=80 then '良好'
when yycj>=60 then '及格'
else '补考'
end '等级'
from t13;
/*查看各等级有多少人*/
select dj '等级', count(*) '人数' from (select case when yycj>=90 then '优秀' when yycj>=80 then '良好' when yycj>=60 then '及格' else '补考' end as dj from t13) as a group by dj;4.3、多表查询
注:没有连接查询效率高,t13表在4.1标题中
select 1,2,3;
select * from (select 1,2,3) as t1 , (select 4,5,6) as t2;
select * from t13,s;
create table if not exists zhuanye(
zid int unsigned not null auto_increment primary key,
zname varchar(20) not null unique,
zxid int unsigned
/*constraint zyfk foreign key (zxid) references xueyuan(xid)*/
)engine=innodb default charset=utf8mb4 auto_increment=00;
insert into zhuanye values(null,'计算机科学与技术',20220),(null,'软件工程',20220),(null,'会计',20221),(null,'临床护理',20222);
insert into zhuanye values(1,'计算机科学与技术',20220),(2,'软件工程',20220);
select * from zhuanye order by zid asc ;
desc zhuanye;
create table if not exists stu(
sid int unsigned not null auto_increment primary key,
sname varchar(20) unique,
sxid int unsigned,
szid int unsigned
/*constraint stfk foreign key (sxid) references xueyuan(xid),foreign key (szid) references zhuanye(zid)*/
)engine=innodb default charset=utf8mb4 auto_increment=000;
insert into stu values (null,'张三',20222,4),(null,'李四',20222,3),(null,'王二',20221,2),(null,'麻子',20221,2),(null,'wzt',20220,1),(null,'yz',20220,1),(null,'xk',20220,1);
select * from stu order by sid asc;
desc stu;
select * from stu;
select * from zhuanye;
select sid,sname,zname from stu,zhuanye where szid = zid;/*查询学生的信息,及这个学生的专业*/4.4、连接查询
注:JOIN的含义就如英文单词“join”一样,连接两张表,大致分为内连接,外连接,右连接,左连接,自然连接。这里描述先甩出一张用烂了的图,然后插入测试数据。
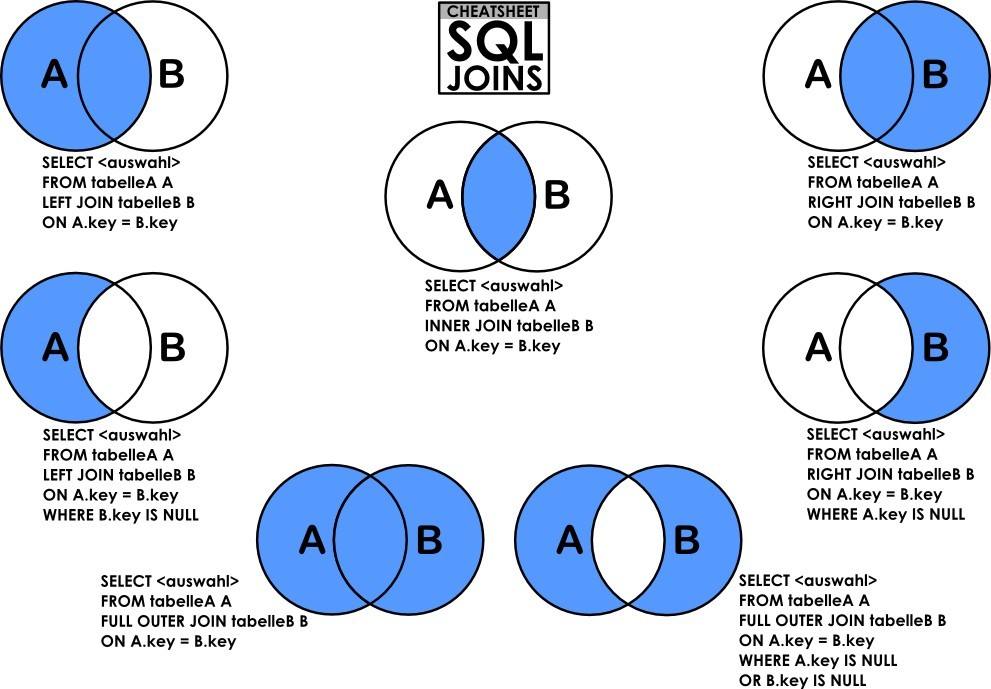
/*连接查询 left join,比多表查询效率高*/
create table if not exists t_department(
id int unsigned not null auto_increment primary key,
department varchar(50)
)engine=innodb default charset=utf8mb4;
insert into t_department values(null,'产品部'),(null,'设计部'),(null,'开发部'),(null,'销售部');
select * from t_department;
create table if not exists t_users(
id int unsigned not null auto_increment primary key,
name varchar(20) not null,
department_id int unsigned,
owner varchar(50),
constraint fkid foreign key (department_id) references t_department(id)
)engine=innodb default charset=utf8mb4;
insert into t_users value(null,'张三',null,'php');
insert into t_users value(null,'王五',2,'java');
insert into t_users value(null,'李四',1,'test webs');
insert into t_users value(null,'刘德华',3,'test webs');
insert into t_users value(null,'刘倩倩',null,'test webs');
insert into t_users value(null,'李宗盛',3,'test webs');
insert into t_users value(null,'郭富城',1,'test webs');
insert into t_users value(null,'大张伟',null,'test webs');
insert into t_users value(null,'马化腾',2,'test webs');
insert into t_users value(null,'马云',null,'C webs');
-- 内连接:inner join 查A、B两表都有的
select t.id,t.name,d.id,d.department from t_users t inner join t_department d on t.department_id=d.id;
-- 链接:left join,left outer join, right join, right outer join, union
select t.id,t.name,d.id,d.department from t_users t left join t_department d on t.department_id=d.id;/*t全,d可空*/
select t.id,t.name,d.id,d.department from t_users t left outer join t_department d on t.department_id=d.id;
select t.id,t.name,d.id,d.department from t_users t left join t_department d on t.department_id=d.id where d.id is null ;/*t不全,d都是空的*/
select t.id,t.name,d.id,d.department from t_users t right join t_department d on t.department_id=d.id;/*t可空,d全*/
select t.id,t.name,d.id,d.department from t_users t right outer join t_department d on t.department_id=d.id;
select t.id,t.name,d.id,d.department from t_users t right join t_department d on t.department_id=d.id where t.id is null;/*t都是空的,d不全*/
select t.id,t.name,d.id,d.department from t_users t left join t_department d on t.department_id=d.id union select t.id,t.name,d.id,d.department from t_users t right join t_department d on d.id = t.department_id;/*t,d都全*/
select t.id,t.name,d.id,d.department from t_users t left join t_department d on t.department_id=d.id where d.id is null union select t.id,t.name,d.id,d.department from t_users t right join t_department d on d.id = t.department_id where t.id is null;
4.5、查询语句练习、你想要的查询语句都在这里
create table `dept`(
`deptno` int(2) not null,
`dname` varchar(14),
`loc` varchar(13),
constraint pk_dept primary key(deptno)
) engine=innodb default charset=utf8;
insert into dept values (10,'ACCOUNTING','NEW YORK');
insert into dept values (20,'RESEARCH','DALLAS');
insert into dept values (30,'SALES','CHICAGO');
insert into dept values (40,'OPERATIONS','BOSTON');
create table `emp` (
`empno` int(4) not null primary key,
`ename` varchar(10),
`job` varchar(9),
`mgr` int(4),
`hiredate` date,
`sal` float(7,2),
`comm` float(7,2),
`deptno` int(2),
constraint fk_deptno foreign key(deptno) references dept(deptno)
) engine=innodb default charset=utf8;
insert into EMP values (7369,'SMITH','CLERK',7902,'1980-12-17',800,null,20);
insert into EMP values (7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);
insert into EMP values (7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);
insert into EMP values (7566,'JONES','MANAGER',7839,'1981-04-02',2975,null,20);
insert into EMP values (7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);
insert into EMP values (7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,null,30);
insert into EMP values (7782,'CLARK','MANAGER',7839,'1981-06-09',2450,null,10);
insert into EMP values (7788,'SCOTT','ANALYST',7566,'1987-07-13',3000,null,20);
insert into EMP values (7839,'KING','PRESIDENT',null,'1981-11-07',5000,null,10);
insert into EMP values (7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30);
insert into EMP values (7876,'ADAMS','CLERK',7788,'1987-07-13',1100,null,20);
insert into EMP values (7900,'JAMES','CLERK',7698,'1981-12-03',950,null,30);
insert into EMP values (7902,'FORD','ANALYST',7566,'1981-12-03',3000,null,20);
insert into EMP values (7934,'MILLER','CLERK',7782,'1982-01-23',1300,null,10);
create table `salgrade` (
`grade` int,
`losal` int,
`hisal` int
) engine=innodb default charset=utf8;
insert into SALGRADE values (1,700,1200);
insert into SALGRADE values (2,1201,1400);
insert into SALGRADE values (3,1401,2000);
insert into SALGRADE values (4,2001,3000);
insert into SALGRADE values (5,3001,9999);
select * from emp;
select dname from dept where deptno=(select deptno from emp where empno=7788);/*查询员工号为7788所在的部门*/
select distinct deptno from emp where sal>2000 order by deptno;/*查询sal>2000的部门号*/
select dname from dept where deptno in (select distinct deptno from emp where sal>2000);/*查询雇员薪水sal>2000所在的所有部门*/
select deptno, dname from dept where deptno=any(select distinct deptno from emp where sal>2000);
select deptno, dname from dept where deptno>any(select distinct deptno from emp where sal>2000);/*>any大于最小值,计10,20,30中最小的一个,所以输出部门号大于10的部门*/
select deptno, dname from dept where deptno<any(select distinct deptno from emp where sal>2000);/*<any小于于最大值,计10,20,30中最大的一个,所以输出部门号小于30的部门*/
select deptno, dname from dept where deptno>all(select distinct deptno from emp where sal>2000);/*>any大于最大值,计10,20,30中最大的一个,所以输出部门号大于30的部门*/
select deptno, dname from dept where deptno<all(select distinct deptno from emp where sal>2000);/*<any小于最小值,计10,20,30中最小的一个,所以输出部门号小于10的部门*/
/*练习*/
select * from dept;
select * from emp;
select * from salgrade;
-- 1、 选择部门30中的雇员
select * from emp where deptno=30;
-- 2、 检索emp表中的员工姓名、月收入及部门编号
select ename,sal,deptno from emp;
-- 3、 检索emp表中员工姓名、及雇佣时间(雇佣时间按照yyyy-mm-dd显示)
select ename,hiredate from emp;
select ename, date_format(hiredate,'%Y年%m月%d日') from emp;
-- 4、 检索emp表中的部门编号及工种,并去掉重复行
select distinct deptno,job from emp;
-- 5、 检索emp表中的员工姓名及全年的月收入
select ename,sal*12 from emp;
-- 6、 用姓名显示员工姓名,用年收入显示全年月收入。
select ename '姓名',sal*12 '年收入' from emp;
-- 7、 检索月收入大于2000的员工姓名及月收入
select ename '姓名',sal '月收入' from emp where sal>2000;
-- 8、 检索月收入在1000元到2000元的员工姓名、月收入及雇佣时间
select ename '姓名',sal '月收入',hiredate '雇佣时间' from emp where sal>1000 and sal<2000;
select ename '姓名',sal '月收入',hiredate '雇佣时间' from emp where sal between 1000 and 2000;
-- 9、 检索以S开头的员工姓名及月收入
select ename '姓名',sal '月收入' from emp where ename like 'S%';
-- 10、检索emp表中月收入是800的或是1250的员工姓名及部门编号
select ename '姓名',deptno '部门编号' from emp where sal=800 or sal=1250;
select ename '姓名',deptno '部门编号' from emp where sal in(800,1250);
-- 11、显示在部门20中岗位是CLERK的所有雇员信息
select * from emp where deptno=20 and job='CLERK';
-- 12、显示工资高于2500或岗位为MANAGER的所有雇员信息
select * from emp where sal>2500 or job='MANAGER';
-- 13、检索emp表中有奖金的员工姓名、月收入及奖金
select ename,sal,comm from emp where comm is not null;
-- 14、检索emp表中部门编号是30的员工姓名、月收入及提成,并要求其结果按月收入升序、然后按提成降序显示
select ename,sal,comm from emp where deptno=30 order by sal asc,comm desc;
-- 15、列出所有办事员的姓名、编号和部门
select empno,ename,d.dname from emp e,dept d where e.deptno=d.deptno;
select empno,ename,d.dname from emp e left join dept d on e.deptno=d.deptno;
-- 16、找出佣金高于薪金的雇员
select * from emp where comm>sal;
-- 17、找出部门10中所有经理和部门20中的所有办事员的详细资料
select * from emp where (deptno=10 and job='MANAGER') or (deptno=20 and job='CLERK');
select * from emp where deptno=10 and job='MANAGER' union select * from emp where deptno=20 and job='CLERK';
-- 18、找出部门10中所有经理、部门20中所有办事员,既不是经理又不是办事员但其薪金>=2000的所有雇员的详细资料
select * from emp where (deptno=10 and job='MANAGER') or (deptno=20 and job='CLERK') or (job not in('MANAGER','CLERK') and sal>=2000);
-- 19、找出收取奖金的雇员的不同工作
select distinct job,count(*) from emp where comm is not null group by job;
-- 20、找出不收取奖金或收取的奖金低于100的雇员
select * from emp where comm is null or comm<100;
-- 21、找出各月倒数第三天受雇的所有雇员
select month(hiredate) from emp;/*月份*/
select * from emp where hiredate=date_add(last_day(hiredate),interval -2 day );
-- 22、获取当前日期所在月的最后一天
select last_day(hiredate) from emp;/*月份最后一天*/
-- 23、找出早于25年之前受雇的雇员
select * from emp where hiredate<date_add(current_date,interval -25 year );
-- 24、显示正好为6个字符的雇员姓名
select * from emp where ename like '______';
select * from emp where char_length(ename)=6;
select * from emp where ename regexp '^.{6}$';
-- 25、显示不带有'R'的雇员姓名
select * from emp where ename not like '%R%';
select * from emp where not ename like '%R%';
select * from emp where instr(ename,'R')=0;
-- 26、显示雇员的详细资料,按姓名排序
select * from emp order by ename asc;/*升序*/
select * from emp order by ename desc;/*降序*/
-- 27、显示雇员姓名,根据其服务年限,将最老的雇员排在最前面
select ename,hiredate from emp order by hiredate asc;
-- 28、显示所有雇员的姓名、工作和薪金,按工作的降序顺序排序,而工作相同时按薪金升序
select ename, job, sal from emp order by job desc,sal asc;
-- 29、显示所有雇员的姓名和加入公司的年份和月份,按雇员受雇日所在月排序,将最早年份的项目排在最前面
select ename '姓名',Year(hiredate) '年份',MONTH(hiredate) '月份' from emp order by year(hiredate) asc,month(hiredate) asc ;
-- 30、显示在一个月为30天的情况下所有雇员的日薪金
select ename,sal,round(sal/30) from emp ;
-- 31、找出在(任何年份的)2月受聘的所有雇员
select * from emp where MONTH(hiredate)=2;
-- 32、对于每个雇员,显示其加入公司的天数
select ename,timestampdiff(day,hiredate,current_date) '天数' from emp;
-- 33、显示姓名字段的任何位置,包含 "A" 的所有雇员的姓名
select ename from emp where ename like '%A%';
-- 34、以年、月和日显示所有雇员的服务年限
select ename,timestampdiff(year ,hiredate,current_date) '年',
timestampdiff(month ,date_add(hiredate,interval timestampdiff(year ,hiredate,current_date) year ),current_date) '月',
timestampdiff(day,date_add(hiredate,interval timestampdiff(month ,hiredate,current_date) month ),current_date) '天数'
from emp;
-- 35、选择公司中有奖金 (COMM不为空,且不为0) 的员工姓名,工资和奖金比例,按工资逆排序,奖金比例逆排序.
select ename '姓名',sal '工资',round(sal/comm) '工资和奖金比例' from emp where comm is not null and comm!=0 order by sal desc,round(sal/comm) desc;
-- 36、选择公司中没有管理者的员工姓名及job
select ename,job from emp where mgr is null;
-- 37、选择在1987年雇用的员工的姓名和雇用时间
select ename,hiredate from emp where year(hiredate)=1987;
-- 38、选择在20或10号部门工作的员工姓名和部门号
select ename,deptno from emp where deptno in(10,20);
-- 39、选择雇用时间在1981-02-01到1981-05-01之间的员工姓名,职位(job)和雇用时间,按从早到晚排序.
select ename,job,hiredate from emp where hiredate between date('1981-02-01') and date('1981-05-01') order by hiredate asc ;
-- 40、选择工资不在5000到12000的员工的姓名和工资
select ename,sal from emp where sal not between 5000 and 12000;
-- 41、查询员工号为7934的员工的姓名和部门号
select empno,ename,deptno from emp where empno=7934;
-- 42、查询工资大于1200的员工姓名和工资
select ename,sal from emp where sal>1200;
/*复杂查询*/
-- 1. 列出与“SCOTT”从事相同工作的所有员工及部门名称,部门人数
select e3.*,d.dname,(select count(*) from emp where deptno = e3.deptno) count from
(select e2.* from emp e2 join (select job,deptno from emp where ename = 'scott') e1 on e2.job = e1.job) e3 join dept d on e3.deptno = d.deptno;
-- 2. 列出公司各个工资等级雇员的数量、平均工资。
select g.grade, count(*),avg(e.sal) from emp e left join salgrade g on e.sal between g.losal and g.hisal group by g.grade;
-- 3. 列出薪金高于在部门30工作的所有员工的薪金的员工姓名和薪金、部门名称。
select sal from emp where deptno=30;/*部门30所有员工薪资*/
select e.ename,e.sal,d.dname from emp e left join dept d on e.deptno =d.deptno where e.sal>all(select sal from emp where deptno=30);
-- 4. 列出在每个部门工作的员工数量、平均工资和平均服务期限。
select d.dname '部门',count(*) '数量',avg(e.sal) '平均薪资',avg(timestampdiff(day,e.hiredate,current_date)) '平均服务期限/天' from emp e left join dept d on e.deptno = d.deptno group by e.deptno;
-- 5. 列出所有员工的姓名、部门名称和工资。
select e.ename,d.dname,e.sal from emp e left join dept d on e.deptno = d.deptno;
-- 6. 列出所有部门的详细信息和部门人数。
select d.*,ifnull(e.sl,0) '人数' from dept d left join (select deptno,count(*) sl from emp group by deptno) e on d.deptno=e.deptno;
-- 7. 列出各种工作的最低工资及从事此工作的雇员姓名。
select e.ename,e2.job,e2.zxgz from emp e left join (select job,min(sal) zxgz from emp group by job) e2 on e.job=e2.job;
-- 8. 列出各个部门的MANAGER(经理)的最低薪金、姓名、部门名称、部门人数。
select m.ename,t.dname,t.zdxz,t.dname, zdxz, rs from emp m inner join
(select d.dname,e.zdxz,count(*) rs from (select deptno,min(sal) zdxz from emp where job='MANAGER' group by deptno) e
left join dept d on e.deptno=d.deptno group by e.deptno) t on m.sal=t.zdxz ;
-- 9. 列出所有员工的年工资,所在部门名称,按年薪从低到高排序。
select e.ename '姓名',round(e.sal*12) '年薪',d.dname '部门' from emp e left join dept d on e.deptno = d.deptno order by e.sal asc;
-- 10. 查出某个员工的上级主管及所在部门名称,并要求出这些主管中的薪水超过3000
select y.ename ,l.ename ,l.sal,d.dname from emp y left join emp l on y.mgr=l.empno left join dept d on l.deptno=d.deptno;
select y.ename ,l.ename ,l.sal,d.dname from emp y left join emp l on y.mgr=l.empno left join dept d on l.deptno=d.deptno where l.sal>3000;
select y.ename ,l.ename ,l.sal,d.dname from emp y left join emp l on y.mgr=l.empno left join dept d on l.deptno=d.deptno where l.sal>3000 and y.ename='JONES';
-- 11. 求出部门名称中,带‘S’字符的部门员工的、工资合计、部门人数。
select d.dname '部门',count(*) '人数',sum(sal) '工资合计' from emp e left join dept d on e.deptno = d.deptno where d.dname like '%S%' group by d.dname;
-- 12. 给任职日期超过45年或者在87年雇佣的雇员加薪,加薪原则:10部门增长10%,20部门增长20%,30部门增长30%,依次类推。
select ename '员工',deptno '部门',sal '原工资',round(sal*(1+deptno/100)) '加薪后' from emp where hiredate<date_add(current_date,interval -40 year) or year(hiredate)=1987;
-- 13. 列出至少有一个员工的所有部门的信息:
select * from dept d left join (select deptno, count(*) rs from emp group by deptno) e on d.deptno=e.deptno where e.rs>=1;
-- 14. 列出薪金比SMITH多的所有员工:
select * from emp where sal>(select sal from emp where ename='SMITH');
-- 15. 列出所有员工的姓名以及其直接上级的姓名:
select y.ename,l.ename from emp y left join emp l on y.mgr=l.empno;
-- 16. 列出受雇日期早于其直接上级的所有员工的编号、姓名,部门名称
select y.empno,y.ename '员工姓名',y.hiredate '员工入职时间',l.hiredate '老板入职时间',d.dname '部门' from emp y
left join emp l on y.mgr=l.empno left join dept d on y.deptno = d.deptno
where y.hiredate<l.hiredate;
-- 17. 列出部门名称和这些部门的员工信息,同时列出那些没有员工的部门
select d.dname,e.* from dept d left join emp e on d.deptno = e.deptno;
-- 18. 列出所有"CLERK(工作)"的姓名以及部门名称,部门的人数
select a.ename,a.job,b.dname,b.cc from emp a join
(select d.deptno,d.dname,count(*) cc from dept d left join emp e on d.deptno = e.deptno group by e.deptno) b
on b.deptno = a.deptno and a.job = 'CLERK';
-- 19. 列出最低薪金大于1500的各种工作以及从事此工作的全部雇员人数
select e.job,d.rs from emp e left join (select job,min(sal) zx,count(*) rs from emp group by job) d on e.job=d.job where d.zx>1500;
-- 20. 列出在部门"SALES"工作的员工的姓名,假定不知道销售部的部门编号
select ename from emp where deptno=(select deptno from dept where dname='SALES');
select e.ename from emp e left join dept d on e.deptno = d.deptno where d.dname='SALES';
-- 21. 列出薪金高于公司平均薪金的所有员工,所在部门,上级领导,公司的工资等级
select avg(sal) from emp ;
select y.ename,y.sal,g.grade,d.dname,l.ename from emp y left join emp l on y.mgr=l.empno left join dept d on y.deptno = d.deptno left join salgrade g on y.sal between g.losal and g.hisal where y.sal>(select avg(sal) pjxz from emp);
-- 22. 列出至少有一个员工的所有部门编号、名称,并统计出这些部门的平均工资、最低工资、最高工资。
select d.deptno,d.dname,avg(e.sal),min(e.sal),max(e.sal) from dept d join emp e on d.deptno = e.deptno group by d.deptno;
-- 23. 列出薪金比“SMITH”或“ALLEN”多的所有员工的编号、姓名、部门名称、其领导姓名。
select y.*,l.* from emp y left join emp l on y.mgr=l.empno;
select y.empno,y.ename,y.sal,d.dname,l.ename from emp y left join emp l on y.mgr=l.empno left join dept d on y.deptno=d.deptno where y.sal>(select min(sal) from emp where ename in('ALLEN','SMITH'));
-- 24. 列出所有员工的编号、姓名及其直接上级的编号、姓名,显示的结果按领导年工资的降序排列。
select y.empno,y.ename,l.empno,l.ename,l.sal*12 '年薪' from emp y left join emp l on y.mgr=l.empno order by l.sal desc;
-- 25. 列出受雇日期早于其直接上级的所有员工的编号、姓名、部门名称、部门位置、部门人数。
select y.empno,y.ename,d.dname,d.loc,d.rs from emp y left join emp l on y.mgr=l.empno left join (select dn.*,count(*) rs from dept dn join emp e on dn.deptno = e.deptno group by e.deptno) d on y.deptno = d.deptno where y.hiredate<l.hiredate;
-- 26. 列出部门名称和这些部门的员工信息(数量、平均工资),同时列出那些没有员工的部门。
select d.deptno,d.dname,count(e.ename),avg(sal) from dept d left join emp e on d.deptno = e.deptno group by d.deptno;
-- 27. 列出所有“CLERK”(办事员)的姓名及其部门名称,部门的人数,工资等级。
select e.ename,d.dname,d.rs,g.grade,e.sal from emp e left join (select dn.*,count(*) rs from dept dn left join emp en on dn.deptno=en.deptno group by dn.deptno) d on e.deptno=d.deptno left join salgrade g on e.sal between g.losal and g.hisal where e.job='CLERK';
-- 28. 列出最低薪金大于1500的各种工作及此从事此工作的全部雇员人数及所在部门名称、位置、平均工资。
select e1.ename,e1.sal,e1.job,e2.rs,e2.pjgz,d.dname,d.loc from (select * from emp) e1 inner join (select job,count(*) rs,avg(sal) pjgz,min(sal) zx from emp group by job) e2 on e1.job=e2.job left join dept d on e1.deptno=d.deptno where e2.zx>1500;
-- 29. 列出在部门“SALES”(销售部)工作的员工的姓名、基本工资、雇佣日期、部门名称,假定不知道销售部的部门编号。
select e.ename,e.sal,e.hiredate,d.dname from emp e left join dept d on e.deptno = d.deptno where d.dname='SALES';
-- 32. 查询dept表的结构
desc dept;
describe dept;
show create table dept;
show columns from dept;
-- 33. 检索emp表,用is a 这个字符串来连接员工姓名和工种两个字段。注:is a 是oracle数据库,mysql无法使用
select concat(ename,job) from emp;
select concat(ename,' ',job) from emp;
select concat_ws('-',ename,job) from emp;
select group_concat(distinct job) from emp;
select group_concat(distinct job order by job asc separator '=') from emp;
-- 34. 检索emp表中有提成的员工姓名、月收入及提成。
select ename,sal,comm from emp where comm is not null and comm>0;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









