







 本文介绍了如何使用Spark进行流处理,包括通过命令行和独立应用程序两种方式。首先,在命令行中创建目录和启动spark-shell,然后输入代码读取并处理文件流。接着,通过创建独立的Scala应用程序`WordCountStreaming`,实现了同样的文件流处理,并使用sbt工具进行编译打包及运行。在不同终端中观察处理结果。文章最后展示了如何结束程序运行。
本文介绍了如何使用Spark进行流处理,包括通过命令行和独立应用程序两种方式。首先,在命令行中创建目录和启动spark-shell,然后输入代码读取并处理文件流。接着,通过创建独立的Scala应用程序`WordCountStreaming`,实现了同样的文件流处理,并使用sbt工具进行编译打包及运行。在不同终端中观察处理结果。文章最后展示了如何结束程序运行。
一、命令行方式实现
1.1 创建目录logfile
cd spark-3.1.1-bin-hadoop2.7/Testmkdir -p streaming/logfile1.2 进入spark-shell
cdcd spark-3.1.1-bin-hadoop2.7/bin/spark-shell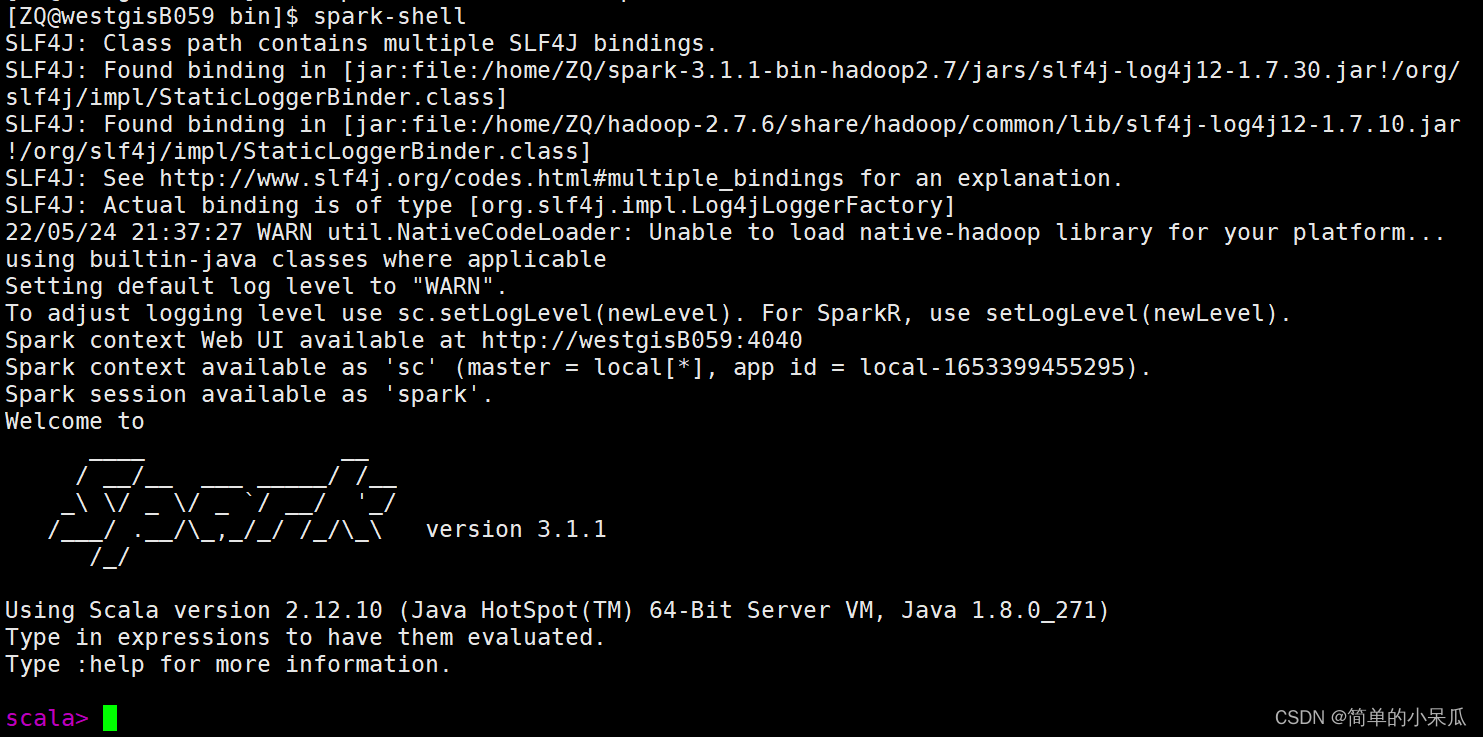
1.3 命令行依次输入以下代码查看实验结果
import org.apache.spark._
import org.apache.spark.streaming._
val ssc=new StreamingContext(sparkConf,Seconds(2))
val lines=ssc.textFileStreaming("file:///home/Group10/bigdata/smartdata")
val words=lines.flatMap(_.split(" "))
val wordCounts=words.map(x=>(x,1)).reduceByKey(_+_)
wordCounts.print()
ssc.start()
ssc.awaitTermination()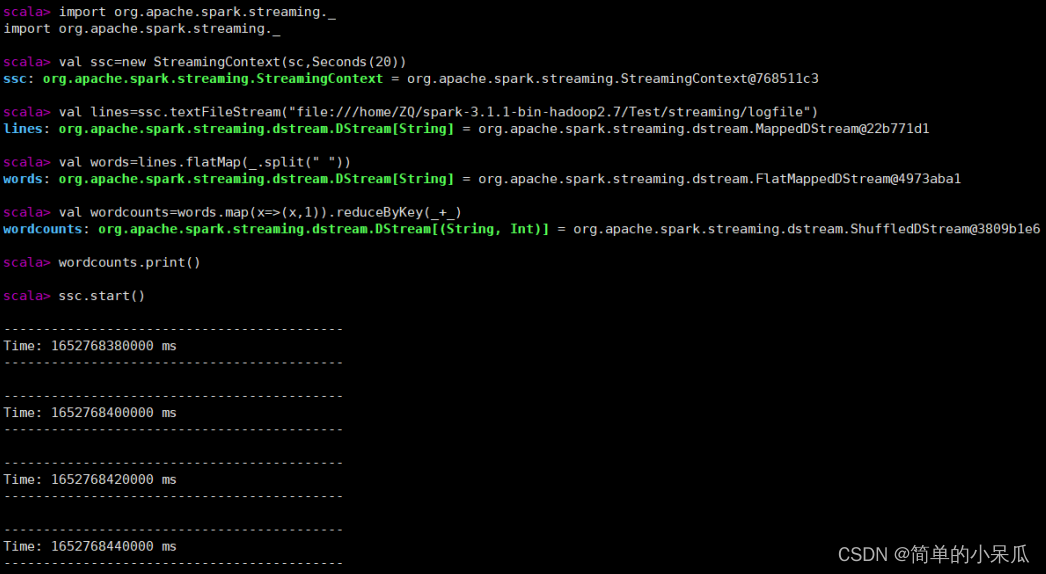
1.4 重新打开一个终端10.103.105.59之后在spark-3.1.1-bin-hadoop2.7/Test/streaming/logfile目录下创建文件log.txt
cd spark-3.1.1-bin-hadoop2.7/Test/streaming/logfilevim log.txt 在log.txt中输入
在log.txt中输入
spark is good
hadoop is good
1.5 回到第一个终端查看实验结果
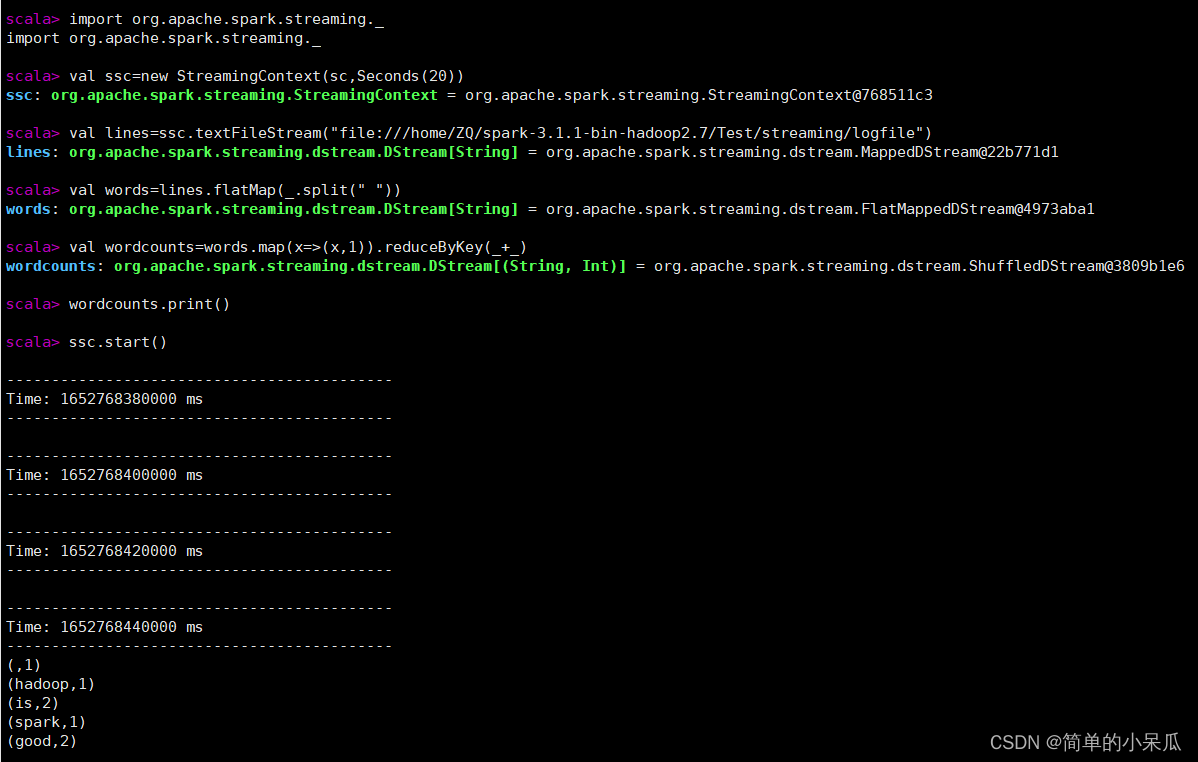
二、采用独立应用程序方式创建文件流(10.103.105.59)
2.1 创建目录file
cd spark-3.1.1-bin-hadoop2.7/Test/streamingmkdir -p file/src/main/scala2.2 创建文件TestStreaming.scala
cd file/src/main/scalavim TestStreaming.scala在文件中增加
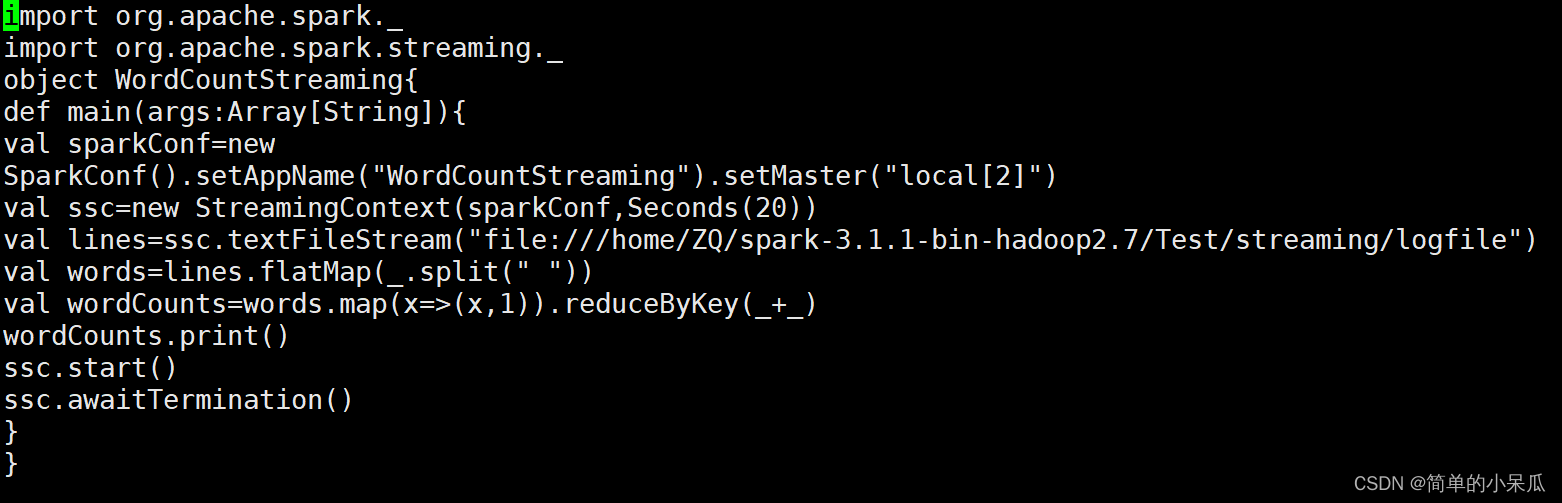
import org.apache.spark._
import org.apache.spark.streaming._
object WordCountStreaming{
def main(args:Array[String]){
val sparkConf=new
SparkConf().setAppName("WordCountStreaming").setMaster("local[2]")
val ssc=new StreamingContext(sparkConf,Seconds(20))
val lines=ssc.textFileStream("file:///home/ZQ/spark-3.1.1-bin-hadoop2.7/Test/streaming/logfile")
val words=lines.flatMap(_.split(" "))
val wordCounts=words.map(x=>(x,1)).reduceByKey(_+_)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
2.3 在spark-3.1.1-bin-hadoop2.7/Test/streaming/ file目录下创建simple.sbt
vim siple.sbt增加如下内容
name := "Simple Project"
version := "1.6.1"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "3.1.1" 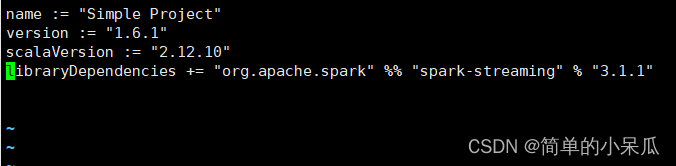
2.4 使用sbt工具对代码进行编译打包(在cd spark-3.1.1-bin-hadoop2.7/Test/streaming/file路径下)
/home/ZQ/sbt/sbt package
2.5 启动程序查看结果
/home/ZQ/spark-3.1.1-bin-hadoop2.7/bin/spark-submit --class "WordCountStreaming" ./target/scala-2.12/simple-project_2.12-1.6.1.jar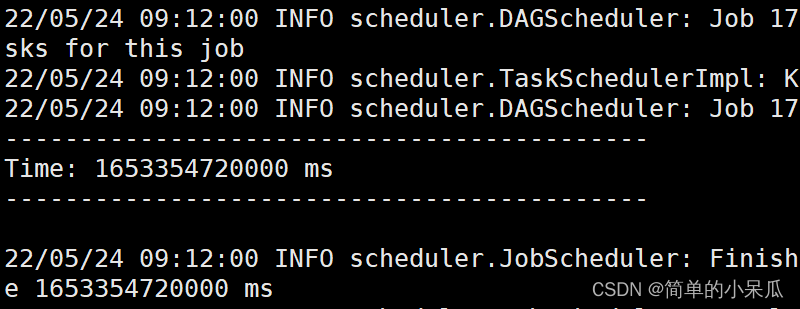
2.6 新建一个终端(59),
在cd spark-3.1.1-bin-hadoop2.7/Test/streaming/logfile目录下再创建一个log2.txt文件保存后回到之前的终端查看结果


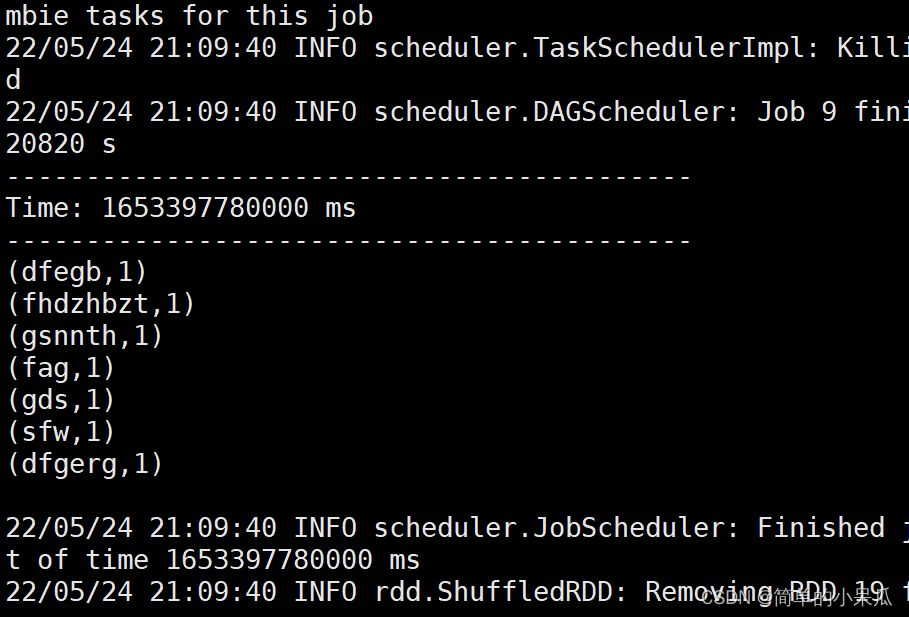
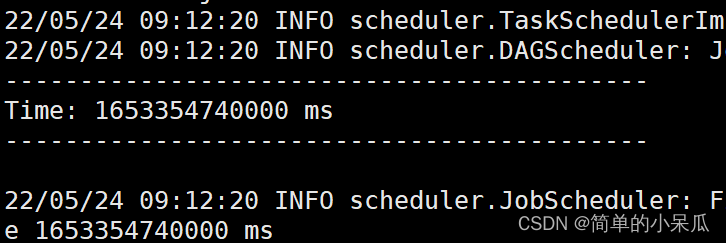
2.7 结束程序运行
直接按ctrl +c


















 2845
2845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









