







 本文详细介绍了如何在Hadoop环境中安装Spark 2.1.1,包括上传、解压、配置环境变量、修改spark-env.sh和slaves文件,以及同步文件至各个节点,确保Spark在集群中的正确运行。
本文详细介绍了如何在Hadoop环境中安装Spark 2.1.1,包括上传、解压、配置环境变量、修改spark-env.sh和slaves文件,以及同步文件至各个节点,确保Spark在集群中的正确运行。
配之前准备
将spark-2.1.1-bin-hadoop2.7.tgz安装包上传到xshell
在xshell上解压压缩包
输入解压命令:
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz配置
1、配置环境变量
vim .bashrc在文件末尾添加如下内容:
#Spark
export SPARK_HOME=/home/hadoop/spark-2.1.1-bin-hadoop2.7
export PATH=${SPARK_HOME}/bin:$PATH

并将环境变量文件传到所有节点(以62为例)
scp -r .bashrc hadoop@10.103.105.62:/home/hadoop使环境变量生效(每个节点都需要使环境变量生效)
source .bashrc
2、配置文件$SPARK_HOME/conf/spark-env.sh
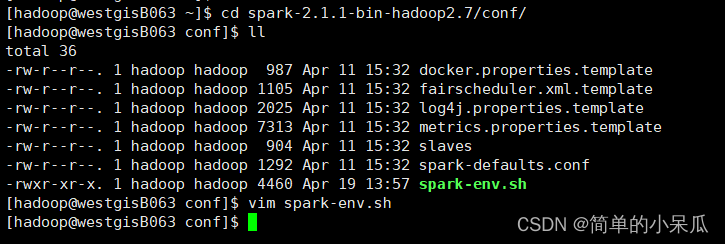
cd spark-2.1.1-bin-hadoop2.7/confvim spark-env.sh在文件末尾加上:
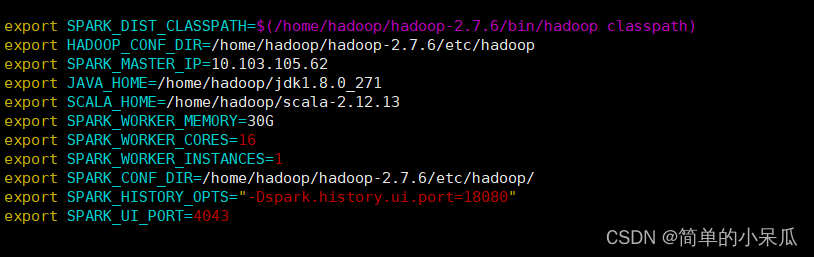
export SPARK_DIST_CLASSPATH=$(/home/hadoop/hadoop-2.7.6/bin/hadoop classpath)
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.7.6/etc/hadoop
export SPARK_MASTER_IP=10.103.105.62
export JAVA_HOME=/home/hadoop/jdk1.8.0_271
export SCALA_HOME=/home/hadoop/scala-2.12.13
export SPARK_WORKER_MEMORY=30G
export SPARK_WORKER_CORES=16
export SPARK_WORKER_INSTANCES=1
export SPARK_CONF_DIR=/home/hadoop/hadoop-2.7.6/etc/hadoop/
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080"
export SPARK_UI_PORT=4043
3、配置文件配置文件$SPARK_HOME/conf/workers
cd spark-3.1.1-bin-hadoop2.7/conf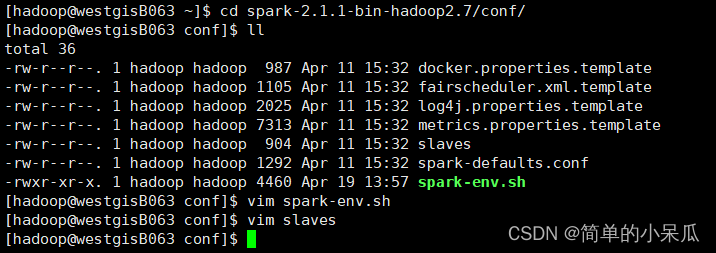
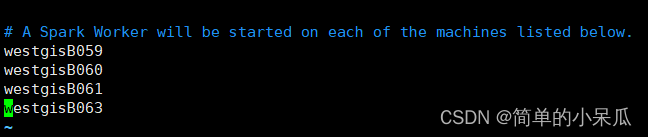
vim slaves去掉最后面的localhost,在文件末尾增加所有从节点的机器名
westgisB059
westgisB060
westgisB061
westgisB063
4、配置文件远程拷贝
spark-2.1.1-bin-hadoop2.7拷贝到每个节点(以62节点为例)
scp -r spark-2.1.1-bin-hadoop2.7 hadoop@10.103.105.62:/home/hadoop其余操作和spark-3.1.1-bin-hadoop2.7类似

















 3887
3887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









