







Kubernetes 作为云原生领域的中流砥柱,能够高效地管理大规模容器化应用。这得益于其设计精妙的核心组件,这些组件相互协作,支撑着整个 Kubernetes 集群的稳定运行。本篇文章将详细剖析 Kubernetes 的核心组件,包括 Master 节点和 Node 节点上的关键组件。
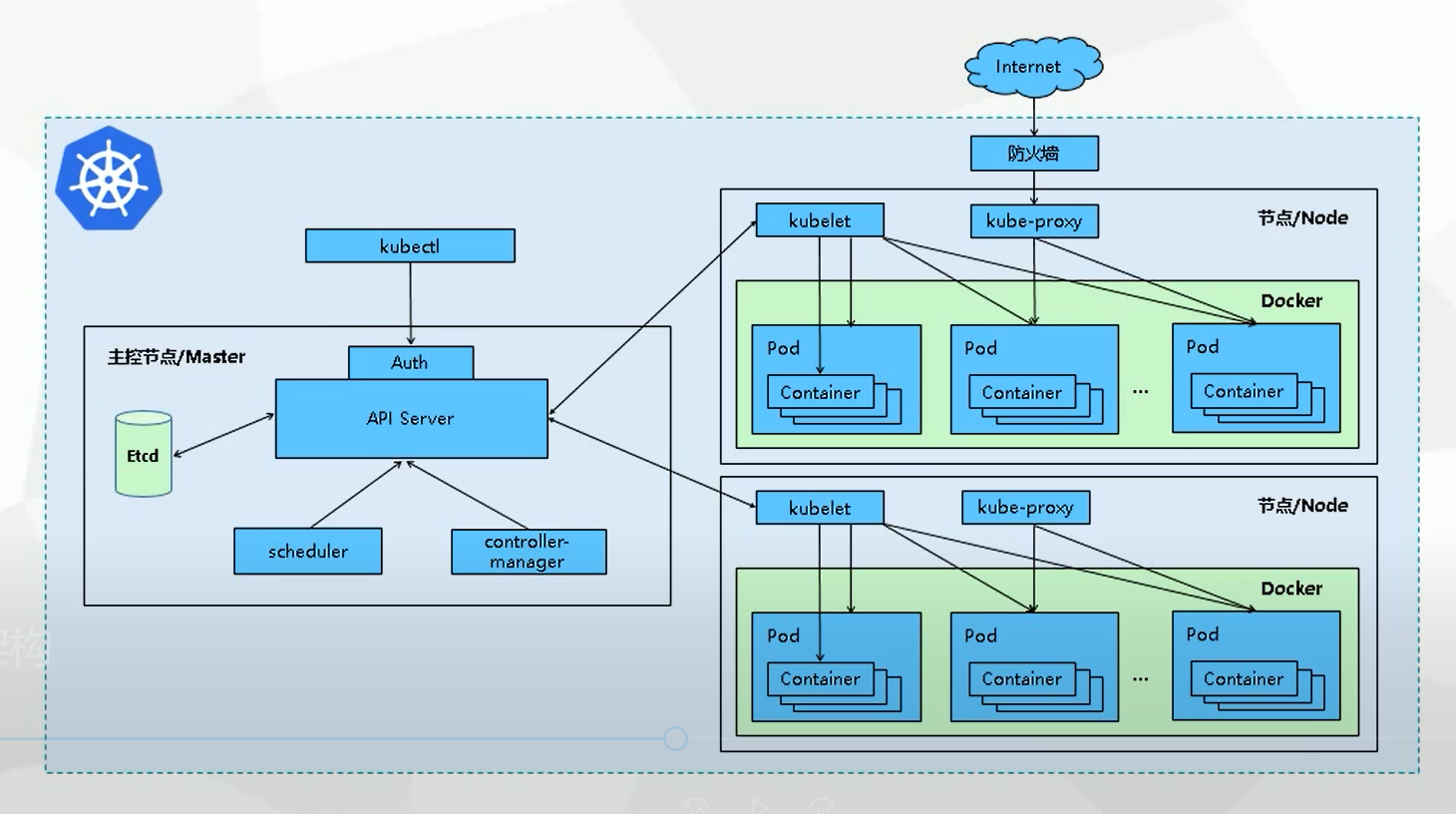
一、Master 节点组件
Master 节点是 Kubernetes 集群的控制中枢,负责管理和调度整个集群的资源,其包含多个核心组件,每个组件都承担着独特且重要的职责。
1. kube-apiserver
kube-apiserver 是 Kubernetes 集群的入口,提供了 RESTful API 接口,用于接收和处理来自客户端(如 kubectl 命令行工具、Kubernetes Dashboard、其他自动化工具等)的请求。它是集群中所有资源操作的唯一入口,任何对集群资源(如 Pod、Service、Deployment 等)的创建、读取、更新和删除操作,都需要通过 kube-apiserver 来完成。
架构与工作原理:
kube-apiserver 采用了基于 HTTP/HTTPS 协议的 RESTful 架构,通过认证、授权、准入控制等机制,确保只有合法的请求才能访问集群资源。它还支持多种认证方式,如 TLS 证书认证、Bearer Token 认证等,以保障集群的安全性。在处理请求时,kube-apiserver 会与 etcd 进行交互,获取或存储集群的配置信息和状态数据。
代码示例:
以使用 kubectl 创建一个 Namespace 为例,执行以下命令:
kubectl create namespace example - namespace该命令会向 kube-apiserver 发送一个 HTTP POST 请求,请求体中包含 Namespace 的定义信息。kube-apiserver 接收到请求后,会对请求进行验证和处理,然后将 Namespace 的定义信息存储到 etcd 中。
2. etcd
etcd 是一个高可用的键值存储系统,用于存储 Kubernetes 集群的配置信息和状态数据。它采用 Raft 一致性算法,保证数据在多个节点之间的一致性和可靠性。etcd 存储的信息包括集群中所有资源对象的定义、节点状态、事件记录等,这些信息对于 Kubernetes 集群的正常运行至关重要。
架构与工作原理:
etcd 集群通常由多个节点组成,通过 Raft 协议进行数据同步和选举。每个节点都保存了完整的集群数据副本,当某个节点出现故障时,其他节点可以继续提供服务,保证集群的可用性。kube-apiserver 通过 etcd 的 API 接口来读写数据,实现对集群资源的管理。
数据结构示例:
在 etcd 中,数据以键值对的形式存储。例如,一个 Pod 的定义信息可能存储在如下键值对中:
Key: /registry/pods/default/my - pod
Value: {
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"name": "my - pod",
"namespace": "default"
},
"spec": {
"containers": [
{
"name": "my - container",
"image": "nginx:1.14.2"
}
]
}
}3. kube-controller-manager
kube-controller-manager 负责管理集群中的各种控制器,这些控制器通过不断地监测集群的实际状态与期望状态之间的差异,来自动调整集群状态,确保集群始终处于用户定义的期望状态。常见的控制器包括副本控制器(Replication Controller)、副本集控制器(ReplicaSet Controller)、Deployment 控制器、StatefulSet 控制器、DaemonSet 控制器等。
架构与工作原理:
kube-controller-manager 由多个独立的控制器组成,每个控制器都运行在一个单独的线程中。这些控制器通过监听 kube-apiserver 的资源变化事件,获取集群的最新状态,并根据预设的规则进行相应的处理。例如,副本控制器会确保指定类型的 Pod 数量始终保持在用户定义的副本数。
代码示例:
以 Deployment 控制器为例,创建一个 Deployment 定义文件my - deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my - deployment
spec:
replicas: 3
selector:
matchLabels:
app: my - app
template:
metadata:
labels:
app: my - app
spec:
containers:
- name: my - container
image: nginx:1.14.2
ports:
- containerPort: 80执行kubectl apply -f my - deployment.yaml后,Deployment 控制器会监测到新的 Deployment 定义,然后创建并管理 3 个副本的 Pod。
4. kube-scheduler
kube-scheduler 负责将新创建的 Pod 调度到合适的 Node 节点上运行。它会根据一系列的调度策略和算法,综合考虑节点的资源状况(如 CPU、内存、磁盘等)、节点的负载情况、Pod 的资源需求以及其他约束条件(如节点亲和性、反亲和性等),选择一个最优的节点来运行 Pod。
架构与工作原理:
kube-scheduler 通过与 kube-apiserver 进行交互,获取集群中所有 Node 节点的信息和待调度的 Pod 列表。然后,它会根据预设的调度策略对每个 Pod 进行评估,为其选择最合适的 Node 节点。一旦选择完成,kube-scheduler 会将调度结果通知给 kube-apiserver,kube-apiserver 再将 Pod 分配到相应的节点上。
调度策略示例:
例如,可以通过节点亲和性来指定 Pod 只能运行在特定标签的节点上。在 Pod 的定义文件中添加如下内容:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- worker上述配置表示该 Pod 只能调度到具有role=worker标签的节点上。
二、Node 节点组件
Node 节点是 Kubernetes 集群中运行 Pod 的工作节点,每个 Node 节点上都运行着多个核心组件,负责管理和运行容器化应用。
1. kubelet
kubelet 是 Node 节点上的核心组件,负责与 Master 节点进行通信,管理本节点上的 Pod。它会根据 Master 节点的指令,启动、停止和监控 Pod 的运行状态,并定期向 Master 节点汇报节点的状态信息。
架构与工作原理:
kubelet 通过与 kube-apiserver 进行通信,获取分配到本节点的 Pod 列表。然后,它会根据 Pod 的定义,调用容器运行时接口(如 Docker、containerd 等)来创建和管理容器。kubelet 还会定期检查容器的健康状态,确保容器正常运行。
代码示例:
假设一个 Node 节点上运行着一个名为my - pod的 Pod,kubelet 可以通过以下命令查看 Pod 的状态:
kubectl describe pod my - pod -n default --kubeconfig /var/lib/kubelet/kubeconfig上述命令会获取my - pod的详细信息,包括容器状态、事件记录等。
2. kube-proxy
kube-proxy 负责实现 Service 的负载均衡和网络代理功能,将流量转发到后端的 Pod 上。它通过在每个 Node 节点上运行一个代理进程,维护节点上的网络规则,确保 Service 能够正常访问后端的 Pod。
架构与工作原理:
kube-proxy 有三种工作模式:userspace、iptables 和 ipvs。在 iptables 模式下,kube-proxy 会根据 Service 的定义,在 Node 节点上创建相应的 iptables 规则,将流量转发到后端的 Pod 上。在 ipvs 模式下,kube-proxy 会使用 Linux 内核的 IPVS 模块来实现更高效的负载均衡。
网络规则示例:
以 iptables 模式为例,当创建一个 Service 时,kube-proxy 会在 Node 节点上创建如下 iptables 规则:
-A KUBE - SERVICES -d 10.96.0.10/32 -p tcp -m comment --comment "default/kubernetes:https cluster IP" -m tcp --dport 443 -j KUBE - MASQ - CHAIN
-A KUBE - SERVICES -d 10.96.0.10/32 -p tcp -m comment --comment "default/kubernetes:https cluster IP" -m tcp --dport 443 -j KUBE - PORTALS - TCP上述规则将发往 Service Cluster IP 的流量进行转发。
三、组件间的协作
Kubernetes 的各个核心组件并非孤立存在,而是通过相互协作,共同完成集群的管理和调度任务。例如,当用户通过 kubectl 创建一个 Pod 时,请求首先会发送到 kube-apiserver,kube-apiserver 将 Pod 的定义信息存储到 etcd 中。然后,kube-scheduler 会从 etcd 中获取待调度的 Pod 列表,并选择一个合适的 Node 节点。最后,kubelet 在选定的 Node 节点上创建并运行 Pod。在整个过程中,kube-controller-manager 会不断监测集群的状态,确保 Pod 的数量和状态符合用户的期望。


















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











