



 文章介绍了OSD叠加原理,通过在内存中处理rgn并叠加到视频帧上来实现显示。在实践中遇到颜色显示不正确的问题,最终发现是由于rgn显示颜色有限制。解决方案是采用rga叠加,通过rga模块对视频进行处理后再编码。文章还涉及了代码规范,如自旋锁的使用和RGB转YUV的函数实现。
文章介绍了OSD叠加原理,通过在内存中处理rgn并叠加到视频帧上来实现显示。在实践中遇到颜色显示不正确的问题,最终发现是由于rgn显示颜色有限制。解决方案是采用rga叠加,通过rga模块对视频进行处理后再编码。文章还涉及了代码规范,如自旋锁的使用和RGB转YUV的函数实现。
OSD叠加RGN图片
1、OSD叠加原理
讲一下我的理解:
字面意思上看就是两个东西叠加到一起嘛,如下图,regbit程序比notepad++靠前,就可以理
解为regbit叠加到了notepad++上,导致regbit界面盖住了notepad++的内容,这就是叠加,
当notepad++放大或缩小时,regbit的大小和位置是不受影响的
如下图,红框是个bmp文件,叠加到了视频帧上(这里的叠加其实是修改了这块的帧内容,不是上述的“叠加”)。当放大倍数是1时,正常显示,当放大倍数为1.1和2时,这个色标就随着视频放大跑到显示区域外部了,但是真正的OSD叠加却不受影响。如下图。这就是叠加到视频帧上的坏处。

为了让色标在放大时还能在原位置显示,就要用OSD叠加了
2、OSD叠加处理
代码中的处理跟上面讲的原理有点区别
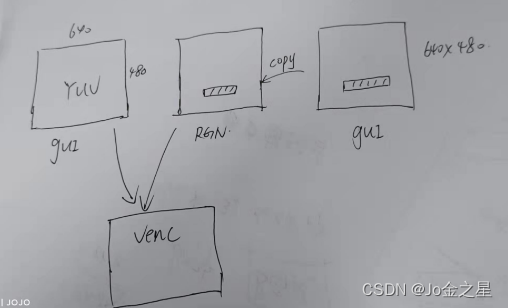
先分配一块rgn内存,先在右边的gui中画出要显示东西(没画的部分是透明的),然后拷贝到分配的rgn中,再把rgn和视频的YUV通过venc编码,最终显示。参考上图的test显示
3、代码中的细节(供自己食用)
3.1、分配rgn
- 设置位置,起始位置xy坐标和宽高wh,这里设置x=192,y=400,w=256,h=20,宽高根据bmp图片大小来的
- 设置通道,叠加到哪个视频通道上
- 设置序号idx,idx越大,位置越靠前,也就是它挡别人
i = vench*RGN_SEG_SIZE+RGN_IDX_IR_UPDATE;
fill_rgnpara(&rgnpara[i], vench, RGN_IDX_IR_UPDATE, &rect);
3.2、读bmp并复制到rgn的buf
- bmp图片是24bpp,而屏幕显示用了ARGB格式32bpp
ARGB中的A代表透明度,0x00透明度100%,0xFF透明度0%,要显示颜色肯定要透明度0啦,所以每三个字节后加个0xFF
U8 *rgb_new;
rgb = (U8*)malloc(256*20*3);
rgb_new = (U8*)malloc(256*20*4);
for(int q=0; q<256*20; q++){
rgb_new[4*q + 0] = rgb[3*q + 0];
rgb_new[4*q + 1] = rgb[3*q + 1];
rgb_new[4*q + 2] = rgb[3*q + 2];
rgb_new[4*q + 3] = 0xFF;
}
for(int p=0; p<20; p++){
memcpy(rgn.buf + 640*(400+p)*4+192*4, rgb_new + p*256*4, 256*4);
}
3.3、显示结果
想的挺好,显示不对,设置成C9 AE FF,就是下图的粉色,结果出来是个褐色。
期初我以为是加0xFF时出错了,倒腾过来倒腾过去。然后把我加0xFF的数组和rgn.buf都保存下来看。
原始数据C9 AE FF,加了FFC9 AE FF FF,rgn.buf中C9 AE FF FF,这特么没毛病啦,一点都没错。显示仍然不行。
然后想是不是ARGB中RGB顺序不是这种,是BGR之类的,试了之后还是不行
最后试了纯色,哎!可以.
下图第2张,bmp颜色过渡多漂亮,叠加后两端不对,中间有竖线,过渡一点都不丝滑,但仍有正确的部分。你说气人不
最终确定了,是特么rgn显示不了那么多种颜色导致的,纯色的可以,有过渡的图片它显示竖条,这不就是相近颜色只能显示成一种的表现嘛。
显示字符是丝毫没问题的,毕竟字符串颜色单一不复杂


纯色

4、最终解决方案
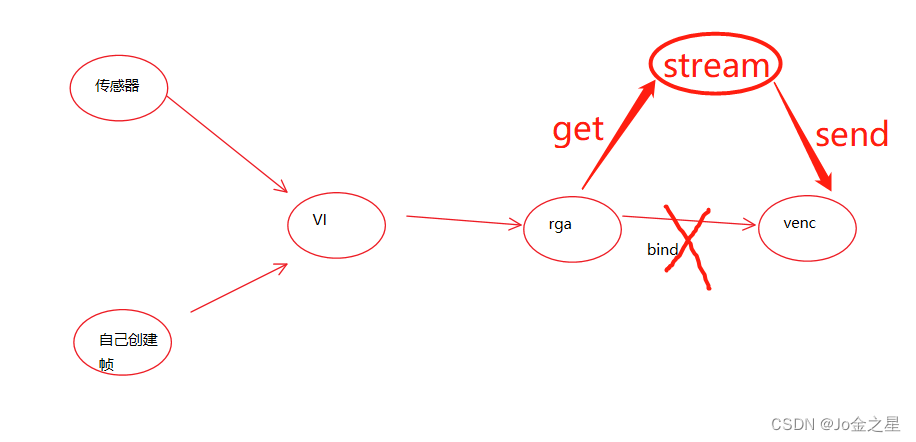
上边的操作是属于OSD叠加,没能成功。还有一种方法,rga叠加
rga是个视频处理模块,可以对视频裁剪,旋转等操作。
在网页上放大后,rga模块会对视频裁剪,但仍会输出640*480大小的视频。只是画面变糊了,就跟你放大图片一样。
本来rga模块是跟编码模块venc绑定在一起的,现在取消绑定,从rga中取帧,叠加,再发送到venc编码。大致就是下图这么回事
5、总结(自用)
- 自旋锁的使用
- 下面的用法,本来是不想用的,因为要一直获取锁,一直释放,但没有更好的办法。锁是必须的,因为修改放大倍数的函数里要改变rag的句柄,而下面获取帧也需要用到rga句柄,所以要加锁
- extern的使用
- 本来定义一个非static的全局变量,在另一个文件用关键字extern导入就行,但是项目中要把全局变量定义成static,那还怎么用?有办法,把该变量封装成函数然后把函数用extern导入到另一个文件里。
- 猜测这样做的原因:加static确实可以防止跟其他文件中的变量重名导致冲突,这样又可以被其他文件使用。
- rgb转YUV420sp和YUV422sp
- YUV422sp内存中是YYYYUVUV,Y:UV=1:1,YUV文件大小是W*H*2
- YUV422sp内存中是YYYYUV,Y:UV=2:1,YUV文件大小是W*H*3/2
- 还有就是YUV查看工具
7yuv,贼好用
定义并初始化
static pthread_mutex_t g_rgachn_mutex= PTHREAD_MUTEX_INITIALIZER;
static void* color_osd_venc_loop(void *arg)
{
D8XX *d8xx;
d8xx = (D8XX *)arg;
while(*d8xx->running){
pthread_mutex_lock(&g_rgachn_mutex);
get_rga_stream(get_hdl_rga(0), get_hdl_venc(0));
get_rga_stream(get_hdl_rga(2), get_hdl_venc(2));
pthread_mutex_unlock(&g_rgachn_mutex);
}
ss_printf(DBG_HISI, 3, "%s, !!! color_osd_venc_loop exit !!!\n", __FUNCTION__);
return NULL;
}
A文件中定义并封装
static pthread_mutex_t g_rgachn_mutex= PTHREAD_MUTEX_INITIALIZER;
void rgachn_mutex_lock(void)
{
pthread_mutex_lock(&g_rgachn_mutex);
}
void rgachn_mutex_unlock(void)
{
pthread_mutex_unlock(&g_rgachn_mutex);
}
B文件中导入,就能使用了
extern void rgachn_mutex_lock(void);
extern void rgachn_mutex_unlock(void);
int rgb2yuv(char* yuv, unsigned char* rgb, int w, int h, int type)
{
char *ptrY, *ptrU, *ptrV, *ptrRGB;
char y, u, v, r, g, b;
int i, j;
switch(type) {
case YUV422SP_NV16:
ptrY = yuv;
ptrU = yuv + w * h;
ptrV = yuv + w * h + 1;
for (j = 0; j < h; j++){
ptrRGB = rgb + w * j * 3;
for (i = 0; i < w; i++){
b = *(ptrRGB++);
g = *(ptrRGB++);
r = *(ptrRGB++);
y = RGB2Y(r, g, b);
u = RGB2U(r, g, b);
v = RGB2V(r, g, b);
*(ptrY++) = clip_value(y, 0, 255);
if (i % 2 == 1){
*(ptrU++) = clip_value(u, 0, 255);
ptrU++;
}else{
*(ptrV++) = clip_value(v, 0, 255);
ptrV++;
}
}
}
return 0;
case YUV420SP_NV12:
ptrY = yuv;
ptrU = yuv + w * h;
ptrV = yuv + w * h + 1;
for (j = 0; j < h; j++){
ptrRGB = rgb + w * j * 3;
for (i = 0; i < w; i++){
b = *(ptrRGB++);
g = *(ptrRGB++);
r = *(ptrRGB++);
y = RGB2Y(r, g, b);
u = RGB2U(r, g, b);
v = RGB2V(r, g, b);
*(ptrY++) = clip_value(y, 0, 255);
if (j%2==0 && i%2==0){
*(ptrV++) = clip_value(v, 0, 255);
*(ptrU++) = clip_value(u, 0, 255);
ptrV++;
ptrU++;
}
}
}
return 0;
default:
ss_printf(DBG_COMM, 3, "%s, No support YUV type\n", __FUNCTION__);
return -1;
}
return 0;
}
完整rgb转YUV代码(别的地方找的):
#include <stdio.h>
#include <stdlib.h>
//判断不前环境是大端还是小端
int checkCPU()
{
union w{
int a;
char b;
}c;
c.a = 1;
return (c.b == 1); //小端返回true,大端返回false
}
int RGB24_to_NV12()
{
int Width=256, Height=20; // 设置图片宽高
int i, j, k, cpu=checkCPU(); // 获取当前CPU是大端还是小端
unsigned char r, g, b;
//打开RGB24 源图 及 创建YUV420 I420图片文件
FILE *fp_s = fopen("XueNv.rgb", "rb+");
FILE *fp_d = fopen("XueNv_YUV420_I420.yuv", "wb+");
//分配内存并读取 rgb24 图片数据
unsigned char *b_s = (unsigned char *)malloc(sizeof(char)*Width*Height*3);
unsigned char *b_d_y = (unsigned char *)malloc(sizeof(char)*Width*Height), *p_y=b_d_y;
unsigned char *b_d_u = (unsigned char *)malloc(sizeof(char)*Width*Height/4), *p_u=b_d_u;
unsigned char *b_d_v = (unsigned char *)malloc(sizeof(char)*Width*Height/4), *p_v=b_d_v;
i = fread(b_s, 1, Width*Height*3, fp_s);
printf("read %d byte\n", i);
printf("CPU is %s mode\n", cpu==1?"little endian":"big endian");
// 开始数据转换
for(i = 0; i<Height; i++){
for(j = 0; j<Width; j++){
if(cpu){ // 小端时,数据存储为 RGB RGB RGB
r = b_s[3*(i*Width + j) + 0];
g = b_s[3*(i*Width + j) + 1];
b = b_s[3*(i*Width + j) + 2];
}else{ // 大端时,数据存储为 BGR BGR BGR
r = b_s[3*(i*Width + j) + 2];
g = b_s[3*(i*Width + j) + 1];
b = b_s[3*(i*Width + j) + 0];
}
*p_y++= (unsigned char)( ( 66 * r + 129 * g + 25 * b + 128) >> 8) + 16;
// 每 4 个Y,取一个U ,一个V。NV12就是先V后U,NV21的话就先U再V
if(j%2==0 && i%2==0){
*p_v++= (unsigned char)( ( -38 * r - 74 * g + 112 * b + 128) >> 8) + 128 ;
*p_u++= (unsigned char)( ( 112 * r - 94 * g - 18 * b + 128) >> 8) + 128 ;
}
}
}
printf("\n transition finally\n");
// 保存YUV图片
i = fwrite(b_d_y, 1, Width*Height, fp_d);
printf("write %d byte\n", i);
i = fwrite(b_d_u, 1, Width*Height/4, fp_d);
printf("write %d byte\n", i);
i = fwrite(b_d_v, 1, Width*Height/4, fp_d);
printf("write %d byte\n", i);
// 释放内存,关闭文件
free(b_s);
free(b_d_y);
free(b_d_u);
free(b_d_v);
fclose(fp_s);
fclose(fp_d);
}
int main(void)
{
RGB24_to_NV12();
printf("\n\n");
return 0;
}
6、代码规范(强烈推荐看一下)
代码写完了改格式都要大半天,改来改去,不是忘了这就是忘了那
- 空格问题
- 加空格可以使代码不那么拥挤,主要还是根据项目中的代码规范来
int a=1;--->int a = 1;
if(xxx){
xxx;
}
//代码块之间空行
function();
- 函数返回值判断
- 有些库函数,调用时需判断返回值,下面的,如果
do_rga_stream函数挂了,那它就没法释放锁,跟它竞争的线程就无法获得锁
- 有些库函数,调用时需判断返回值,下面的,如果
pthread_mutex_lock(&g_rgachn_mutex);
ret = do_rga_stream(tmp_rgachn, tmp_vencchn);
if(ret != 0){
pthread_mutex_unlock(&g_rgachn_mutex);
ss_printf(DBG_HISI, 3, "%s, do_rga_stream failed\n", __FUNCTION__);
return -1;
}
pthread_mutex_unlock(&g_rgachn_mutex);
- 数组越界判断
hdl_rgachn是用作rga通道句柄的,限制了12个,当传入参数不在该范围怎么办?所以要加判断,普通数组也一样,不判断越界了怎么办。
static int hdl_rgachn[12];
int get_hdl_rga(int chn)
{
if(chn >=0 && chn <= 11){
return hdl_rgachn[chn];
}else{
ss_printf(DBG_HISI, 3, "%s rag_chn = %d, chn < 0 or chn > 11, failed\n", chn);
return -1;
}
}
- 函数名称
- 项目中函数名尽量要贴切,简洁,符合代码功能,像rga帧的处理,我用的是
set_rga_stream,大佬觉得用rga_stream_proc比较好,proc就是process。我也觉得后者比较好。 - 创建的线程函数叫
rga_stream_venc_loop,想着这是rga帧的编码处理,就这样叫了。大佬说,这块代码只处理红外的rga,可以加前缀ir,这个函数内存已经有子函数分步处理rga帧了,如获取,编码,释放,就不用加vnec(编码)。于是变成了ir_rga_stream_loop
- 项目中函数名尽量要贴切,简洁,符合代码功能,像rga帧的处理,我用的是
给函数起个适当的名字函数名还是需要有点东西的,得抓住重点,一看函数名就能知道函数干了啥。关键结合项目中其他函数命名习惯。
- 代码封装
- 哪些需要封装,哪些不需要封装。
- 如果某个功能经常被使用,那封装一下
- 如果一个功能太长,占了几十行,那最好封装一下,哪怕它只被一两个函数调用

















 3893
3893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









