






1 原理
1.1 GMP调度模型的设计思想
1.1.1 传统多线程的问题
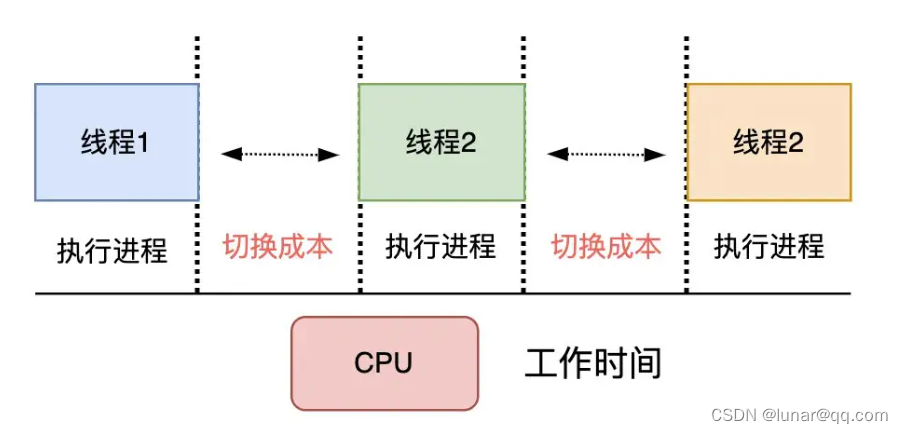
在现代的操作系统中,为了提高并发处理任务的能力,一个CPU核上通常会运行多个线程,多个线程的创建、切换使用、销毁开销通常较大:
(1)一个线程的大小通常达到4M,因为需要分配内存来存放用户栈和内核栈的数据
(2)一个线程执行系统调用(发生IO时间如网络请求或者读写请求)不占用CPU时,需要及时让出CPU,交给其他线程执行,这是会发生线程之间的切换
(3)线程在CPU上进行切换时,需要保持当前线程的上下文,将待执行的线程的上下文恢复到寄存器中,还需要向操作系统内核申请资源
在高并发的情况下,大量线程的创建、使用、切换、销毁会占用大量的内存,并浪费较多的CPU时间在非工作任务的执行上,导致程序并发处理事务的能力降低
1.2 GO早期的GM模型
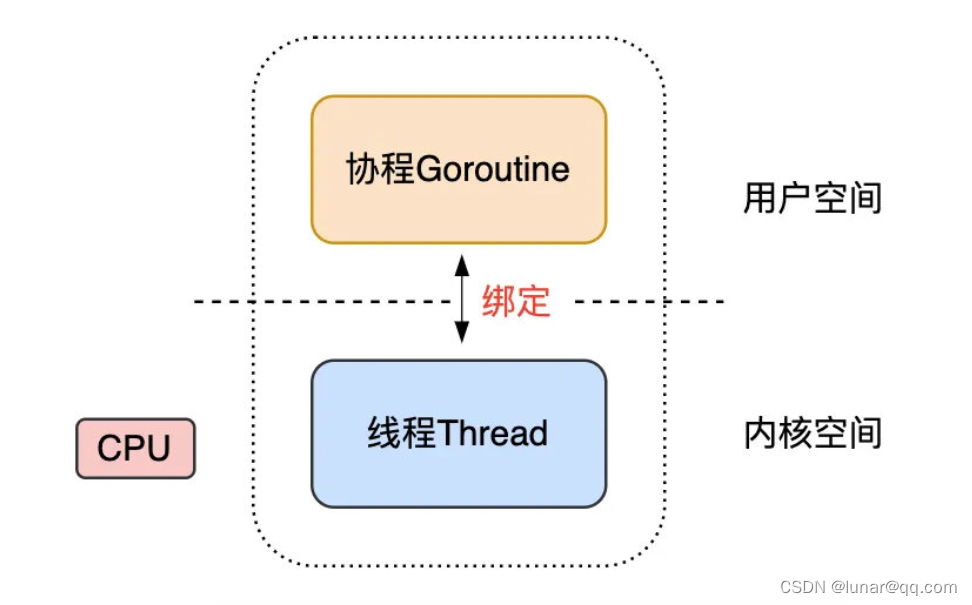
为了解决传统内核级的线程的创建、切换、销毁开销较大的问题,Go将线程分为了内核级线程M,轻量级的用户态的协程Goroutine。(简单点来说就是没什么问题是加一层逻辑处理不了,如果有就再加一层,既然内核的线程开销大,那我就自己在内核级的线程之上创建一个更轻量的线程)。到这里,Go的调度器的三个核心概念就出现了两个:
M:Machine,代表了内核级线程OS Thread,CPU调度的基本单元
G:Goroutine,被Go优化过的协程,是一个用户态、轻量级的协程,一个G代表了对一段需要被执行Go程序的封装。每个Goroutine都有自己独立地栈存放自己程序的运行状态,分配的栈大小为2KB,可以按需扩容。
在早期,Go将传统线程拆分成为了M和G之后,为了充分利用轻量级的G的低内存占用、低切换开销 的优点,会在当前一个M上绑定多个G,某个正在运行中G执行完成后,Go调度器会将该G切换走,将其他可以运行的G放入M上执行,这时一个Go程序中只有一个M线程
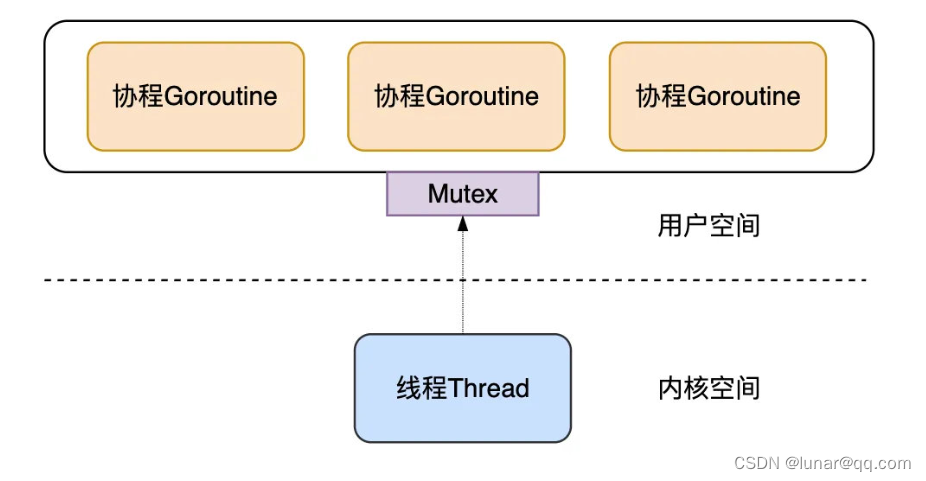
这个方案的优点是用户态的G可以快速切换,不会陷入内核态,缺点是无法充分利用CPU,并且如果G阻塞,会导致跟G绑定的M阻塞,其他G也用不了M去执行自己的程序了。
为了解决这些问题,Go后面又上线了多线程调度器,如下:
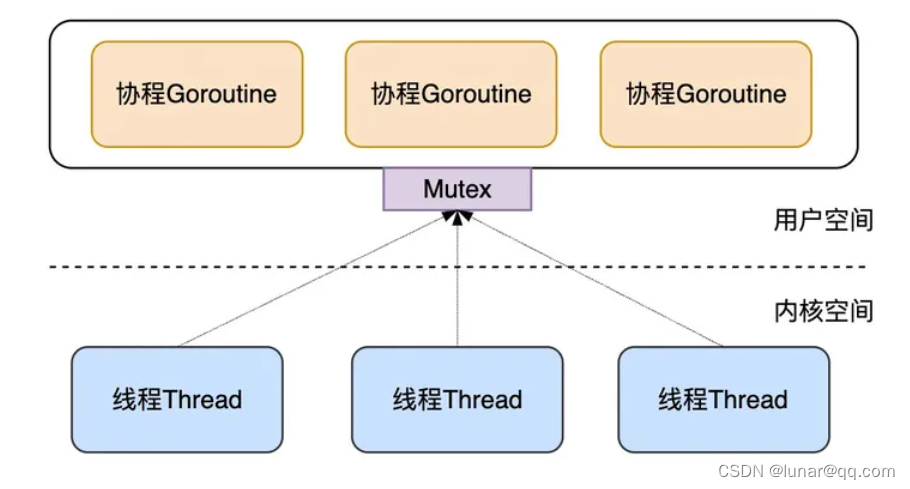
每个Go程序都有多个M线程对应的多个G,但是每次取、还G的时候都需要进行加锁操作,这样会导致锁竞争导致性能下降。
1.1.3 当前的GMP模型
为了解决上面的问题,Go在上面M,G的基础上,引入了P处理器。
P:Process的缩写,代表一个虚拟的处理器,它维护了一个局部可运行的G队列,可以通过CAS的方式无锁访问,除了自己,别人也有可能从自己这里偷G(简单的提一下,这里说的无锁主要理解为轻量的加锁,个人觉得这个atomic原子化操作更像一把乐观锁,没有互斥锁锁的粒度范围大,具体取G流程下面会介绍。)工作线程M优先使用自己的runnext里面存放的G,没有才去本地环形队列找G,只有前面两个都找不到才会去全局队列中找G,这就大大减少了锁冲突,提高了大量G的并发性。每个G想要在M上运行,必须被分配一个P(sysmon除外,这个大哥不需要p就能直接在M上运行,后续介绍)
当前Go采用的GMP调度模型如下图所示。可运行的G是通过处理器P和线程M绑定起来的,M的执行是由操作系统调度器将M分配到CPU上实现的,Go运行时调度器负责调度G到M上执行,主要在用户态运行,跟操作系统调度器在内核态运行相对应。
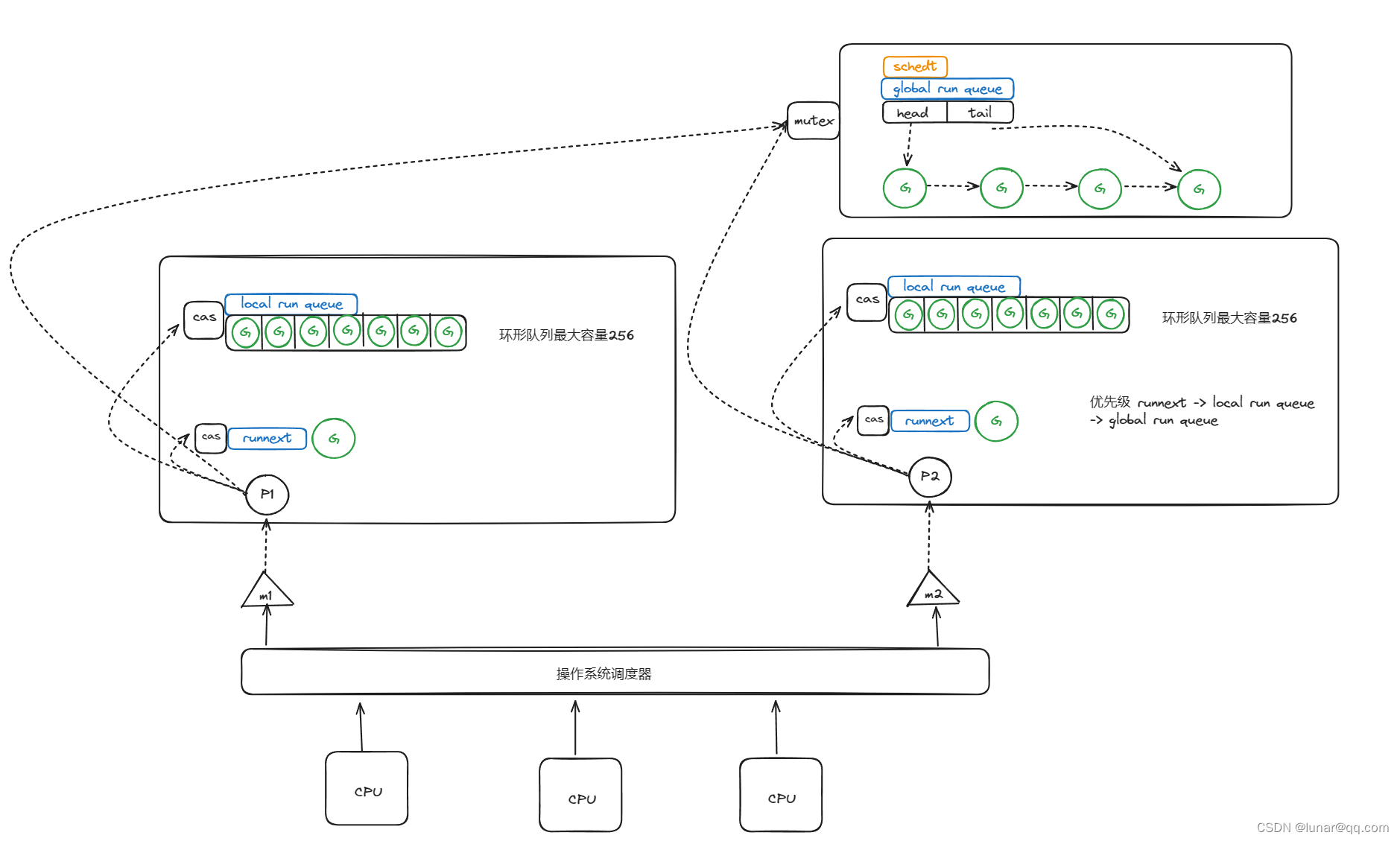
(这里的G为什么是放在P上而不是M上?这是因为当一个线程M阻塞(有可能是因为执行系统调用或者IO请求)的时候,可以将和它绑定的P和G转移到其他线程M上去执行,如果直接把可运行的G组成的本地队列绑定到M,这个时候万一M阻塞,它拥有的G就不能给其他M执行,后续介绍)
1.1.4 Go调度器的核心思想
1.尽可能复用线程M:主要是为了避免现成的创建和销毁
2.利用多核并行能力:限制同时运行(不包含阻塞)的M线程数为N,N等于CPU的核心数目,这里可以通过设置P处理器的个数为GOMAXPROCS来保证(也就是平常代码写的runtime.GOMAXPROCS(n),注意,这个还是少用,因为会STW也就是stopTheWorld停止一切工作)。不设置默认为CPU核数,因为M和P是绑定的,没有找到P的M会放入空闲M列表,没有找到M的P也会放入空闲列表
3.Work Stealing任务窃取机制:M优先执行其所绑定的P的runnext的G,没有就去P的本地环形队列找,再没有就去全局链表找,再没有就回去别的P里面去偷G来运行(主要是为了所谓的负载均衡,不让每个自旋的M闲着)
4.Hand Off移交机制:M阻塞,会将M绑定的P移交给别的M绑定,然后接着执行P存储的G
5.基于协作的抢占机制:每个真正运行的G,如果不被打断,将会一直被运行下去,这样太不公平(毕竟有些总喜欢占着茅坑不拉屎),为了公平,也就是防止新建的G一直P的本地队列不被调度导致饥饿问题,Go程序会保证每个G运行10ms就要让出M,交给其他G执行(sysmon负责监控,后续介绍)
6.基于信号的真抢占机制:尽管基于协作的抢占机制能够缓解长时间GC导致整个程序无法工作和大多数Goroutine饥饿问题,但是还是有部分情况下,Go调度器有无法被抢占的情况,例如,for循环或者垃圾回收长时间占用线程,为了解决这些问题,Go1.14引入了基于信号的抢占式调度机制,能够解决GC垃圾回收和栈扫描时存在的问题。(此机制后续不介绍,别问,问就是我没看懂,太菜了)
1.1.5 Go的调度流程(注意Go版本不一样情况可能也不一样,请注意版本哦,亲)
Go的调度流程的本质就是一个生产-消费流程
生产端:
情况一:runnext为空,local run queue为空,global run queue为空,此时M1正在运行G1,然后G1创建了一个G2
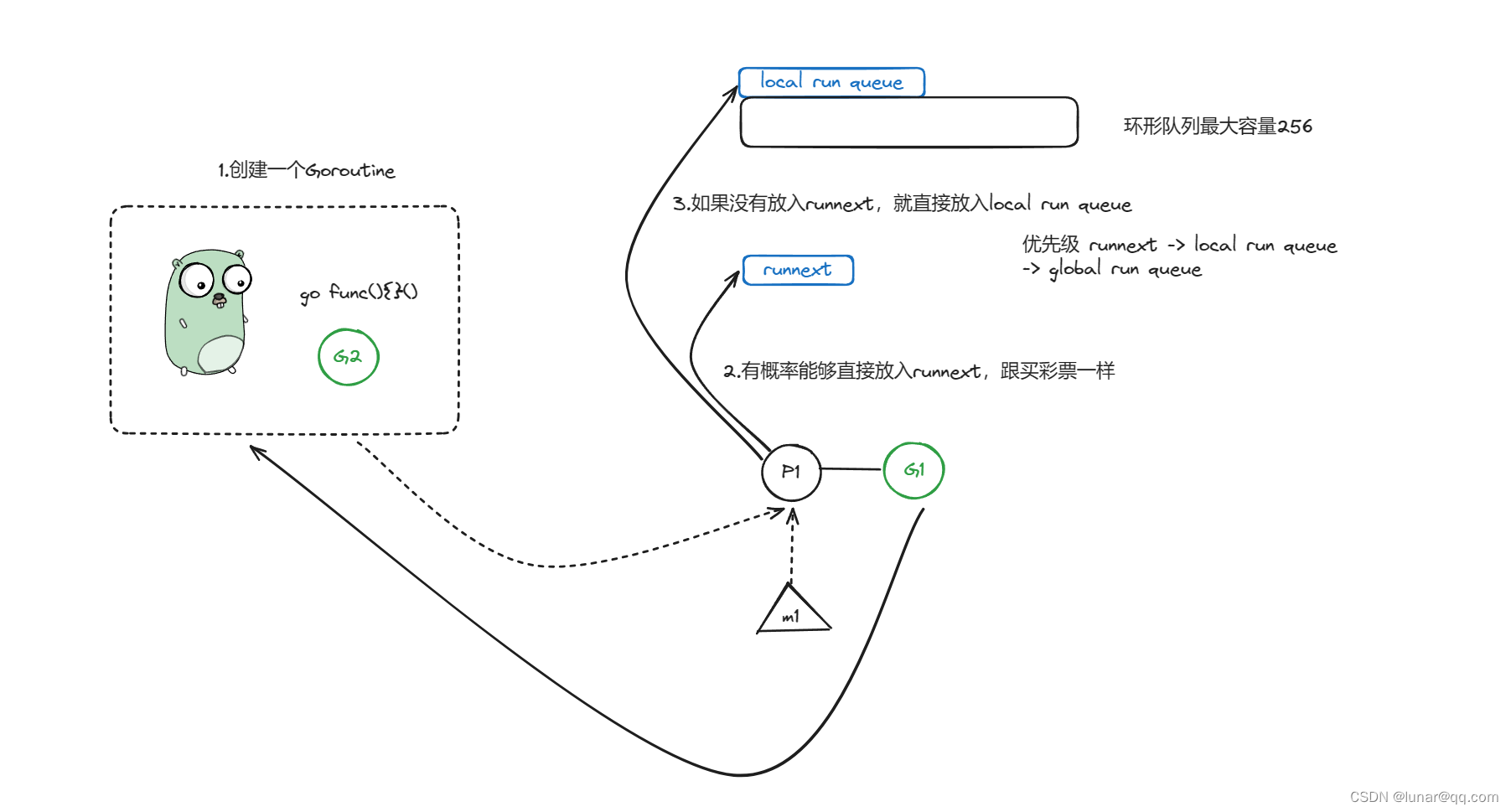
1.21.4这个版本新建的G不是一定先放入runnext,有的版本是,看你用的是啥版本,到时候看看源码就知道,就跟买彩票一样,有概率会被放入runnext,如果没有中奖,也就是没有放入runnext ,那就会直接进入local run queue
网上很多博客没有提这个runnext的哦,亲,不要有疑问,源码就是有,不信接着往下看源码
情况二:runnext满,local run queue满,global run queue可空可不空随便,反正是链表,此时M1正在运行G1,然后G1又创建了一个Gn
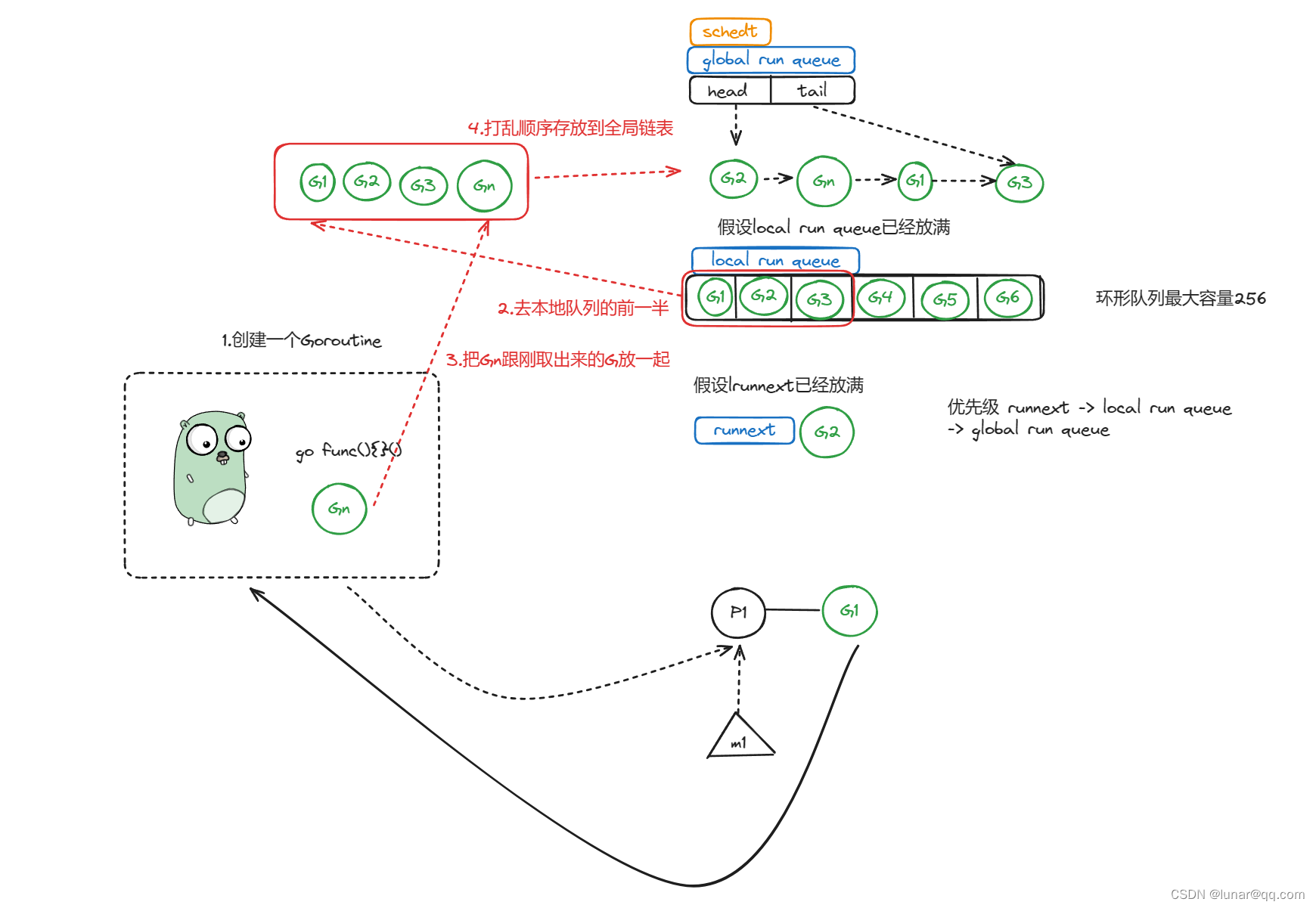
此时会先将本地队列的前一半先取出来放到数组batch中,然后把新建的Gn放到batch最后,然后打乱batch中的存放顺序,再按照batch的顺序存放到全局链表中
再次声明,每个版本可能情况不同,具体看源码哦,亲,不要纠结,网上博客一人说一个,你自己去看源码,那才是最正确的答案
消费端:
情况一:runnext不为空,local run queue不为空,global run queue随意(现在跟他没啥关系)
此时M1刚执行完G1,然后切换G0,开始寻找新的G来调度,优先从runnext,然后是local run queue,最后是global queue,先不要过分关注细节,后续源码展开,先了解大概
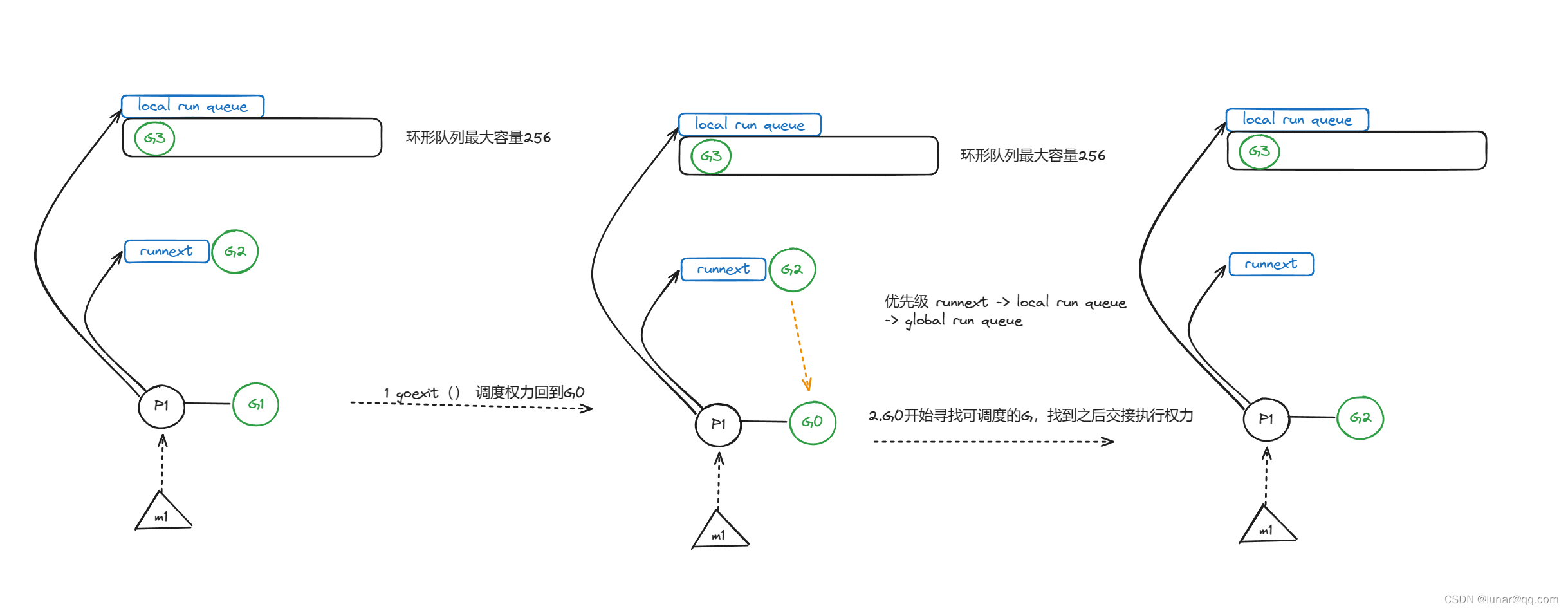
情况二:runnext为空,local run queue为空,global run queue为空,此时M1刚执行完G1,切换G0开始寻找下一个可运行的G,因为runnext为空,local run queue为空,global run queue也为空,G0只能走下下策,随机找个P偷它的G用。具体的偷细节看源码。下面简单描述一下
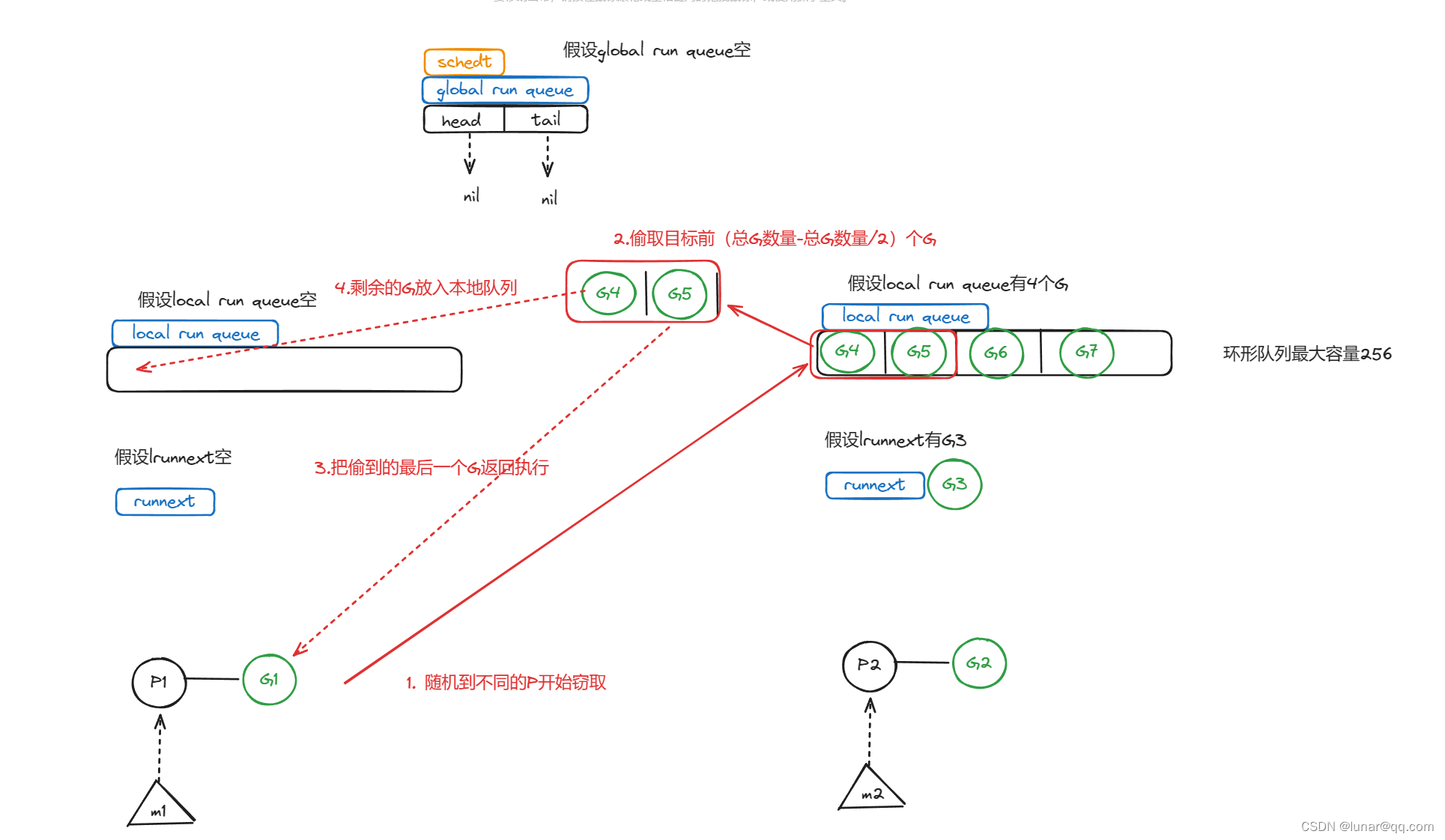
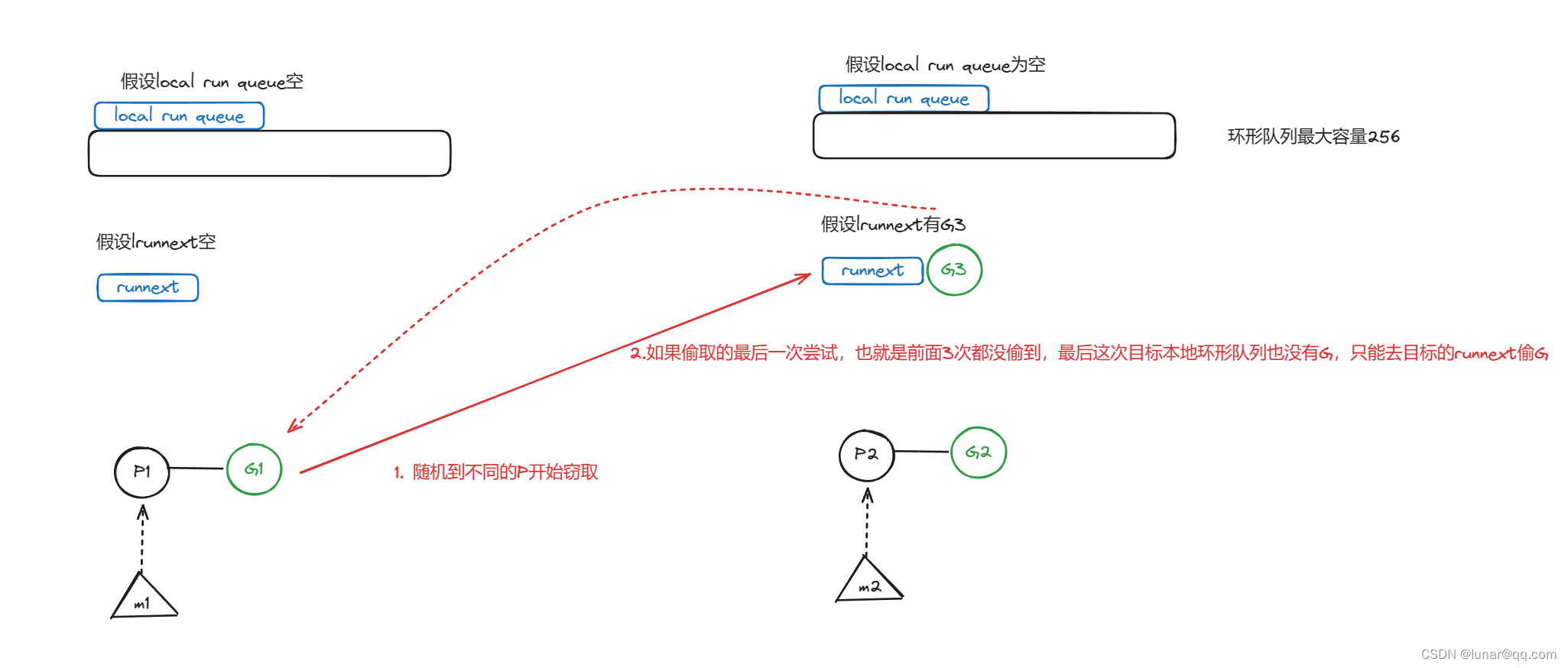
假设被偷的是P1,小偷是P0的G0,一共有四次容错,优先偷P1本地队列的G,当然,G0身为小偷,必然要给人家留点G,所以会留一半G给P1,所以偷取的数量就是P1本地队列的G总数量-P1本地队列的G总数量/2.如果非常不幸,前面三次随机都没偷到,那么最后一次随机找P偷取的时候,就会不管不顾了,如果目标本地队列没有G,连runnext里面的G也要偷,不然自己就要饿死了,这是兜底的下下策。最后返回的是最后偷到的那个G。
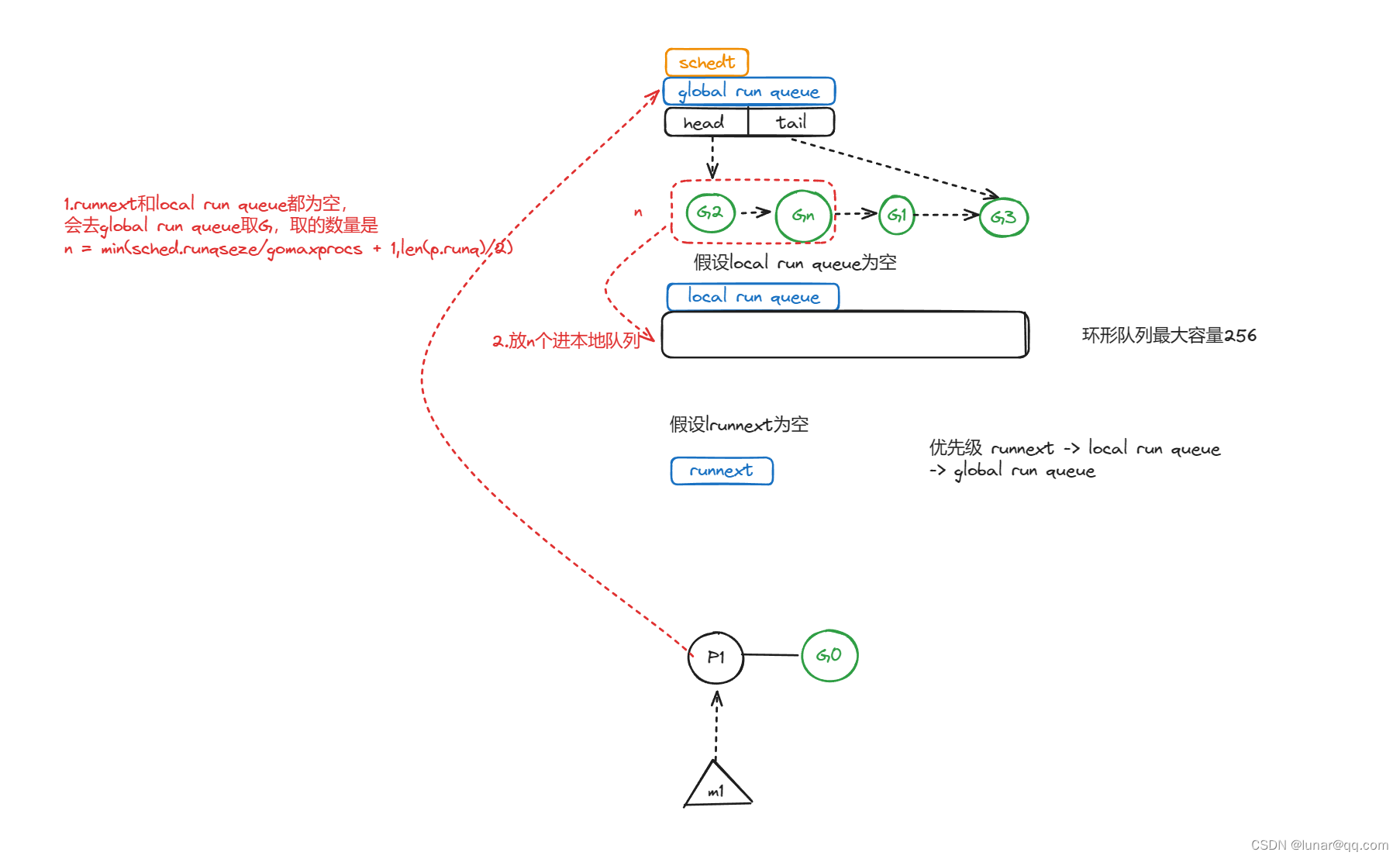
情况三:runnext为空,local run queue为空,global run queue不为空,此时M1刚执行完G1,切换G0开始寻找下一个可运行的G,此时会去global run queue找G,取的数量是min(sched.runqseze/gomaxprocs + 1,len(p.runq)/2),也就是取两个值中最小的一个。最后放到本地队列。 (去全局队列取G时,主要是要注意不能一次拿太多,毕竟别的P可能也要用,所以这里取最小值,最少都会拿一个,除非没有)
约定:
在创建G时,运行的G会尝试唤醒其他空闲的P和M组合去执行。
借用刘冰丹老师的绘制图。假定G2唤醒M2,M2绑定了P2,并运行G0,但P2本地队列没有G,M2此时为自旋线程(没有可运行的G,不断寻找G)
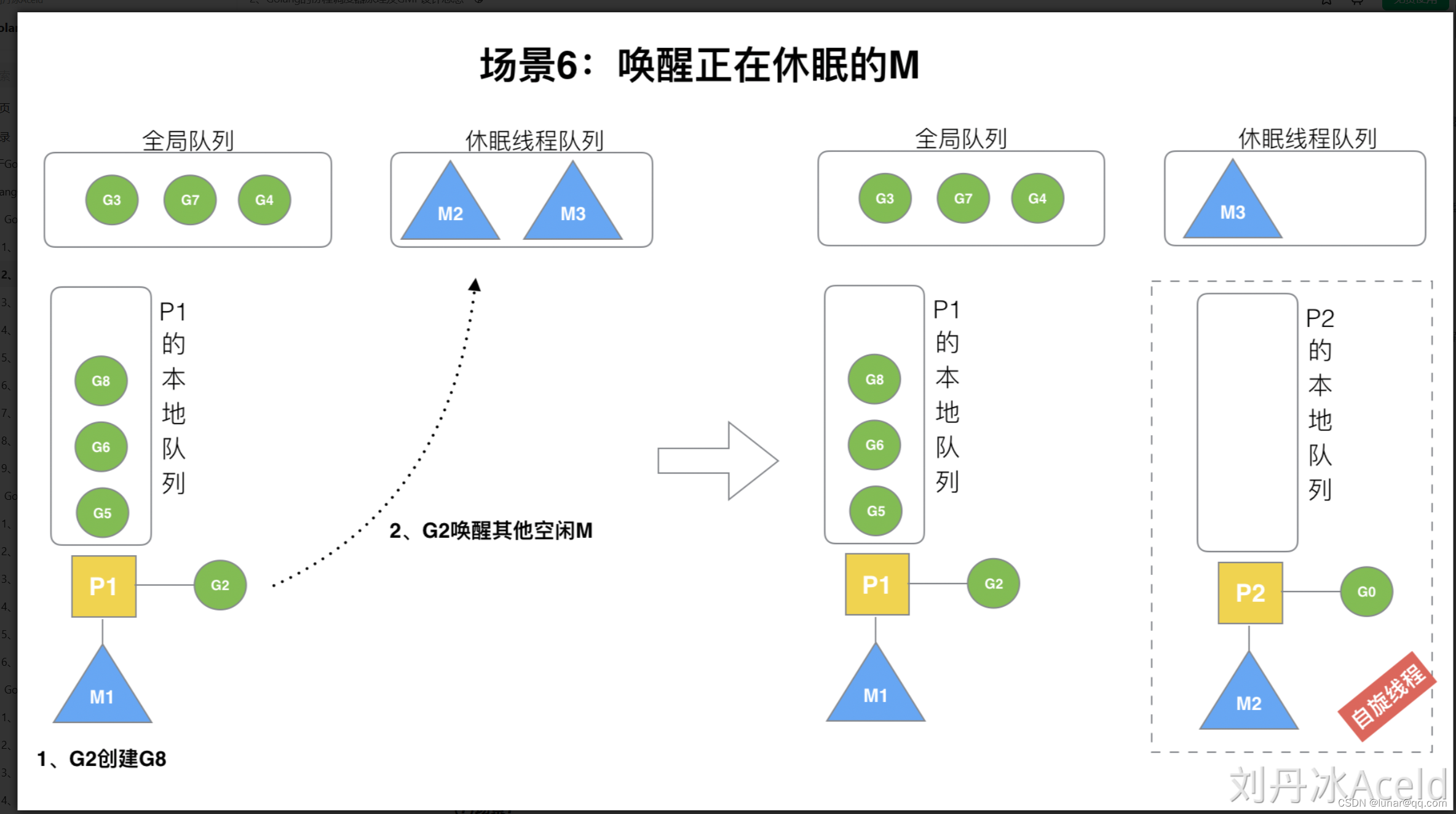
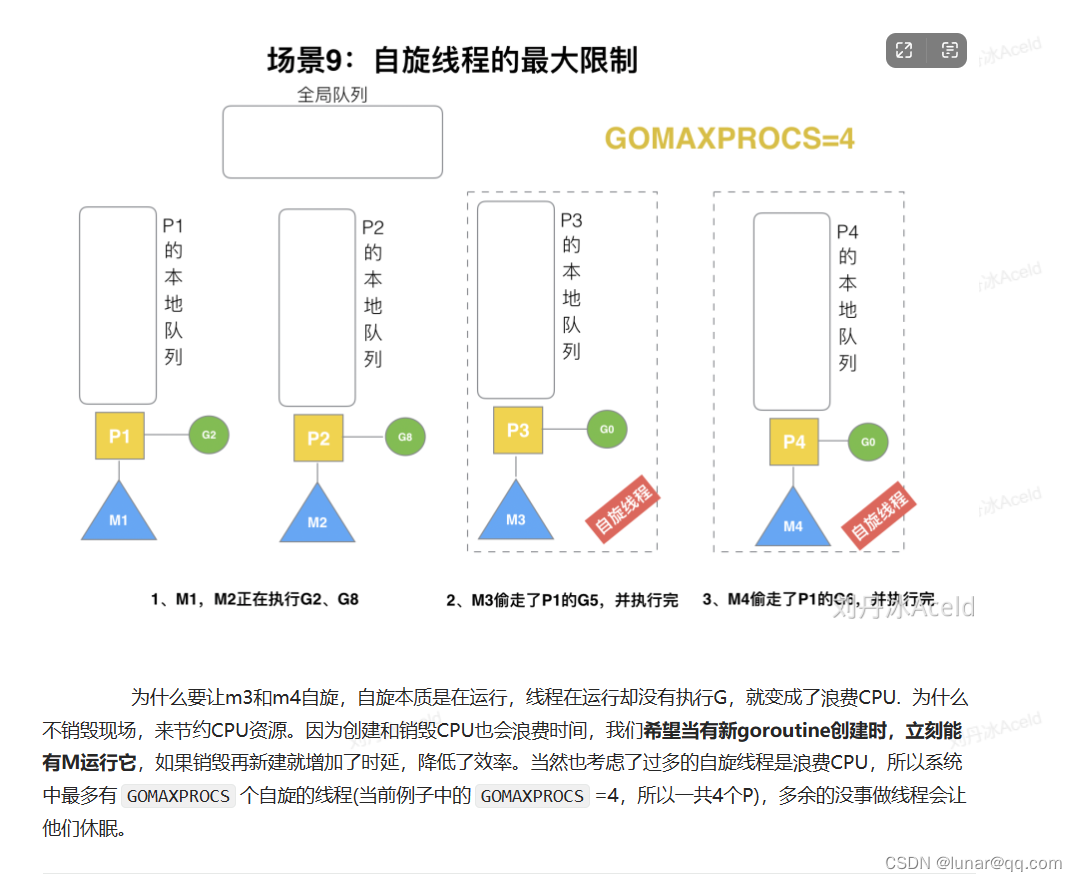
自旋线程补充:
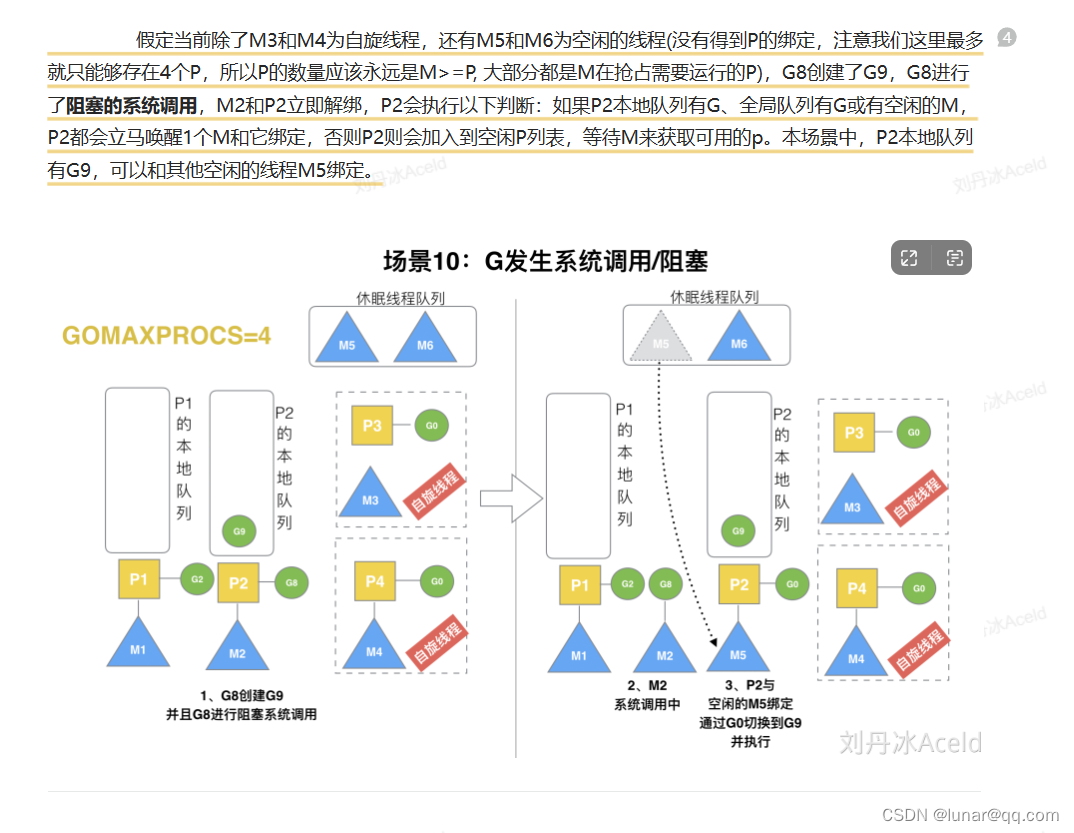
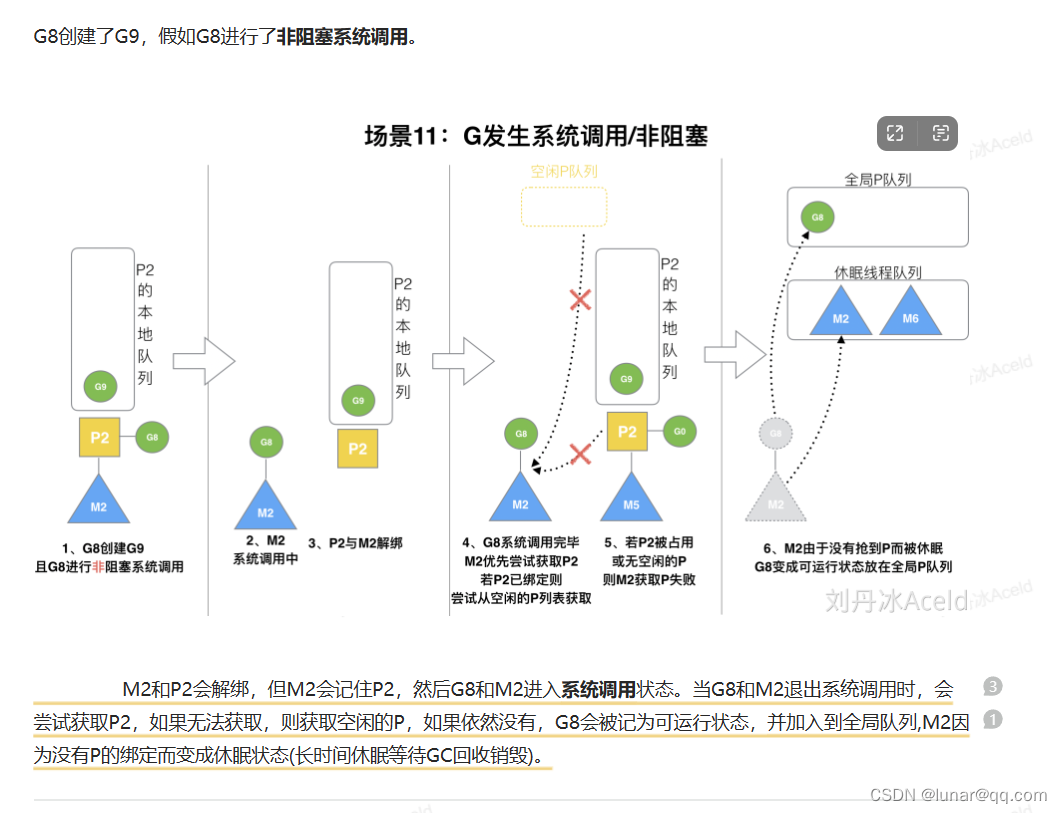
G发生系统调用:
2 源码走读
2.1 重要数据结构
2.1.1 M
M是OS线程的实体。下面是一些重要的字段:
- 持有用于执行调度器的g0
- 持有用于处理信号的gsignal
- 持有线程本地存储tls
- 持有当前正在运行的curg
- 持有运行Goroutine时需要的本地资源P
- 表示自身的自旋和非自旋状态spining
- 管理在它身上执行的cgo调用
- 将自己与其他的M进行串联
- 持有当前线程上进行内存分配的本地缓存mcache
- M的状态有以下:
- 1.自旋(spining) :M正在从运行队列获取G,这时候M会拥有一个P
- 2.执行go代码中:M正在执行go代码,这时候M会有一个P
- 3.执行原生代码中:M正在执行原生代码(sysmon)或者阻塞的syscall,这是M不拥有P
- 4.休眠中:M发现无待运行的G时会进入休眠,并添加到空闲的M链表中,这是M不拥有P
// src/runtime/runtime2.go
type m struct {
g0 *g // 用于执行调度指令的 Goroutine
gsignal *g // 处理 signal 的 g
tls [6]uintptr // 线程本地存储
curg *g // 当前运行的用户 Goroutine
p puintptr // 执行 go 代码时持有的 p (如果没有执行则为 nil)
spinning bool // m 当前没有运行 work 且正处于寻找 work 的活跃状态
cgoCallers *cgoCallers // cgo 调用崩溃的 cgo 回溯
alllink *m // 在 allm 上
mcache *mcache
...
}2.1.2 P
// src/runtime/runtime2.go
type p struct {
status uint32 // p 的状态 pidle/prunning/...
schedtick uint32 // 每次执行调度器调度 +1
syscalltick uint32 // 每次执行系统调用 +1
m muintptr // 关联的 m
mcache *mcache // 用于 P 所在的线程 M 的内存分配的 mcache
deferpool []*_defer // 本地 P 队列的 defer 结构体池
// 可运行的 Goroutine 队列,可无锁访问
runqhead uint32
runqtail uint32
runq [256]guintptr
// 线程下一个需要执行的 G
runnext guintptr
// 空闲的 G 队列,G 状态 status 为 _Gdead,可重新初始化使用
gFree struct {
gList
n int32
}
......
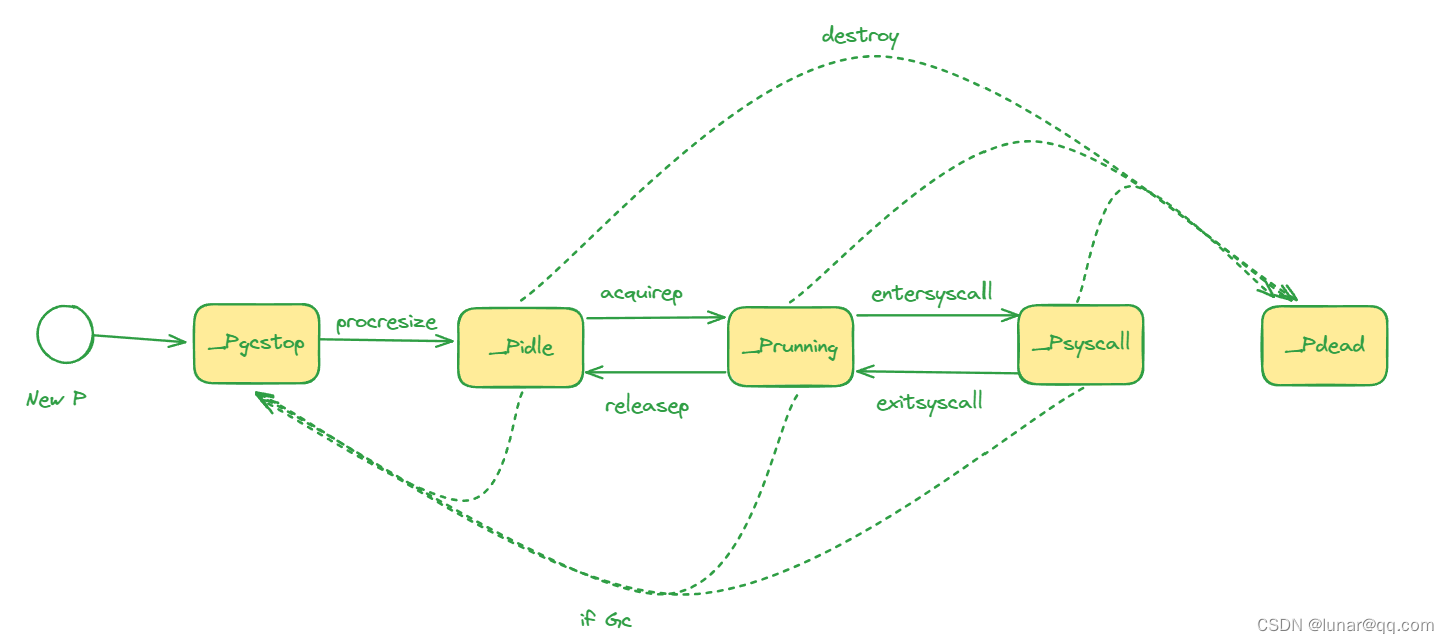
}最重要的数据结构是status表示P不同的状态,runqhead、runqtail、runq三个字段表示处理器持有的运行队列,是一个长度为256的环形队列,其中存储着待执行的G列表,runnext中是线程下一个要执行的G;gFree存储P本地状态为_Gdead的空闲的G,可重新初始化使用。
P结构体中的状态status字段会是以下5种中的一种:
_Pidle:P没有运行用户代码或者调度器 ,被空闲队列或者改变其状态的结构持有,运行队列为空
_Prunning:被线程M持有,并且正在执行用户代码或者调度器
_Psyscall:没有执行用户代码,当前线程陷入系统调用
_Pgcstop:被线程M持有,当前处理器由于垃圾回收被停止
_Pdead:当前P已经不被使用
下面是P状态切换调用的函数以及不同状态之间的转换
2.1.2 sysmon监控和抢占P
在程序启动的时候,会创建一个新的线程m,同时创建一个协程g,这个g不需要绑定p,直接与m绑定,也就是所谓的sysmon协程
func main() {
...
if GOARCH != "wasm" { // no threads on wasm yet, so no sysmon
// For runtime_syscall_doAllThreadsSyscall, we
// register sysmon is not ready for the world to be
// stopped.
atomic.Store(&sched.sysmonStarting, 1)
systemstack(func() {
newm(sysmon, nil, -1)
})
}
...
}sysmon就是监控协程,抢占retake()的逻辑如下:
const forcePreemptNS = 10 * 1000 * 1000 // 10ms
func retake(now int64) uint32 {
n := 0
lock(&allpLock)
for i := 0; i < len(allp); i++ {
pp := allp[i]
if pp == nil {
continue
}
pd := &pp.sysmontick
s := pp.status
sysretake := false
if s == _Prunning || s == _Psyscall {
// Preempt G if it's running for too long.
t := int64(pp.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
// 如果p距离上次调度已经过去了10ms
// 将p当前执行的goroutine(curg)标记为可以抢占状态
preemptone(pp)
sysretake = true
}
}
if s == _Psyscall {
// 超过了1个监控tick(20us)
t := int64(pp.syscalltick)
if !sysretake && int64(pd.syscalltick) != t {
pd.syscalltick = uint32(t)
pd.syscallwhen = now
continue
}
if runqempty(pp) && sched.nmspinning.Load()+sched.npidle.Load() > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
unlock(&allpLock)
incidlelocked(-1)
if atomic.Cas(&pp.status, s, _Pidle) {
if traceEnabled() {
traceGoSysBlock(pp)
traceProcStop(pp)
}
n++
pp.syscalltick++
handoffp(pp)
}
incidlelocked(1)
lock(&allpLock)
}
}
unlock(&allpLock)
return uint32(n)
}
当p在_Prunning或者_Psyscall状态下,以下情况P可能会被抢占:
1.如果距离上次调度已经过去了10ms(pd.schedwhen+forcePreemptNS <= now),也就是某一个G已经执行了10ms
2.如果系统调用超过了一个sysmon tick(20us)
3.系统调用的情况下,p中的本地队列如果还有多余的goroutine,也就是(runqempty(p)不为空)。这个时候抢占是为了让本地队列的其他G有机会执行
4.如果atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 ,说明外面有空闲的p和自旋的m,压根没必要抢占当前的p
如果是情况1,会调用preemptone(),将p当前执行的goroutine(curg)标记为可以抢占的状态:
// 设置p的当前运行goroutine(curg)标记为可抢占
func preemptone(pp *p) bool {
mp := pp.m.ptr()
if mp == nil || mp == getg().m {
return false
}
gp := mp.curg
if gp == nil || gp == mp.g0 {
return false
}
gp.preempt = true
// Every call in a goroutine checks for stack overflow by
// comparing the current stack pointer to gp->stackguard0.
// Setting gp->stackguard0 to StackPreempt folds
// preemption into the normal stack overflow check.
gp.stackguard0 = stackPreempt
// Request an async preemption of this P.
if preemptMSupported && debug.asyncpreemptoff == 0 {
pp.preempt = true
preemptM(mp)
}
return true
}从gp.stackguard0 = stackPreempt上面的注释可以得知,协程调用前都会检查时候会栈溢出,将gp.stackguard0设置为stackguard0,就会让协程进入到检查栈溢出的逻辑中。
检查函数是个汇编函数morestack_noctxt(),函数执行流程:morestack_noctxt() -> morestack() -> newstack()
// src/runtime/stack.go
func newstack() {
...
preempt := atomic.Loaduintptr(&gp.stackguard0) == stackPreempt
...
if preempt {
gopreempt_m(gp)
}
...
}最终回到上面的执行逻辑,而gopreempt_m(),会调用goschedImpl(),这就很熟悉了,goschedImpl就是我们主动让出协程的调用函数。
其他情况:主要就是进入handoffp()函数,只要满足以下条件,就会启动一个m(startm())来接管p:
条件一:p的本地队列或者全局队列不为空
条件二:处理gc
条件三:此时全局没有自旋的m也没有空闲的p,然后尝试启动一个自旋线程
...
接管后,最终就会调用releasem(mp),该方法也执行g.stackguard0=stackPreempt,那么就跟preemptone()执行逻辑一样。
如果上面条件不满足,就通过pidleput()将p放入空闲队列。
func handoffp(pp *p) {
if !runqempty(pp) || sched.runqsize != 0 {
startm(pp, false, false)
return
}
if (traceEnabled() || traceShuttingDown()) && traceReaderAvailable() != nil {
startm(pp, false, false)
return
}
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) {
startm(pp, false, false)
return
}
if sched.nmspinning.Load()+sched.npidle.Load() == 0 && sched.nmspinning.CompareAndSwap(0, 1) { // TODO: fast atomic
sched.needspinning.Store(0)
startm(pp, true, false)
return
}
lock(&sched.lock)
if sched.gcwaiting.Load() {
pp.status = _Pgcstop
sched.stopwait--
if sched.stopwait == 0 {
notewakeup(&sched.stopnote)
}
unlock(&sched.lock)
return
}
if pp.runSafePointFn != 0 && atomic.Cas(&pp.runSafePointFn, 1, 0) {
sched.safePointFn(pp)
sched.safePointWait--
if sched.safePointWait == 0 {
notewakeup(&sched.safePointNote)
}
}
if sched.runqsize != 0 {
unlock(&sched.lock)
startm(pp, false, false)
return
}
if sched.npidle.Load() == gomaxprocs-1 && sched.lastpoll.Load() != 0 {
unlock(&sched.lock)
startm(pp, false, false)
return
}
when := nobarrierWakeTime(pp)
pidleput(pp, 0)
unlock(&sched.lock)
if when != 0 {
wakeNetPoller(when)
}
}
2.1.3 G
// src/runtime/runtime2.go
type g struct {
stack stack // 描述了当前 Goroutine 的栈内存范围 [stack.lo, stack.hi)
stackguard0 uintptr // 用于调度器抢占式调度
_panic *_panic // 最内侧的 panic 结构体
_defer *_defer // 最内侧的 defer 延迟函数结构体
m *m // 当前 G 占用的线程,可能为空
sched gobuf // 存储 G 的调度相关的数据
atomicstatus uint32 // G 的状态
goid int64 // G 的 ID
waitreason waitReason //当状态status==Gwaiting时等待的原因
preempt bool // 抢占信号
preemptStop bool // 抢占时将状态修改成 `_Gpreempted`
preemptShrink bool // 在同步安全点收缩栈
lockedm muintptr //G 被锁定只能在这个 m 上运行
waiting *sudog // 这个 g 当前正在阻塞的 sudog 结构体
......
}- stack:描述了当前Goroutine的栈内存范围[stack.lo,stack.hi]
- stackguard0:可以用于调度器抢占式调度;preempt,preemptStop,preempShrink跟抢占相关
- defer和panic:分别记录这个G最内侧的panic和_defer结构体
- m:记录当前G占用线程M,可能为空
- atmicstatus:表示G的状态
- sched:存储G的调度相关的数据
- goid:表示G的ID,对开发者不可见
需要展开描述的是sched字段的runtime.gobuf结构体:
type gobuf struct {
sp uintptr // 栈指针
pc uintptr // 程序计数器,记录G要执行的下一条指令位置
g guintptr // 持有 runtime.gobuf 的 G
ret uintptr // 系统调用的返回值
......
}这些字段会在调度器将当前G切换离开M和调度进入M执行程序时用到,栈指针sp和程序计数器pc用来存放或恢复寄存器中的值,改变程序执行的指令。
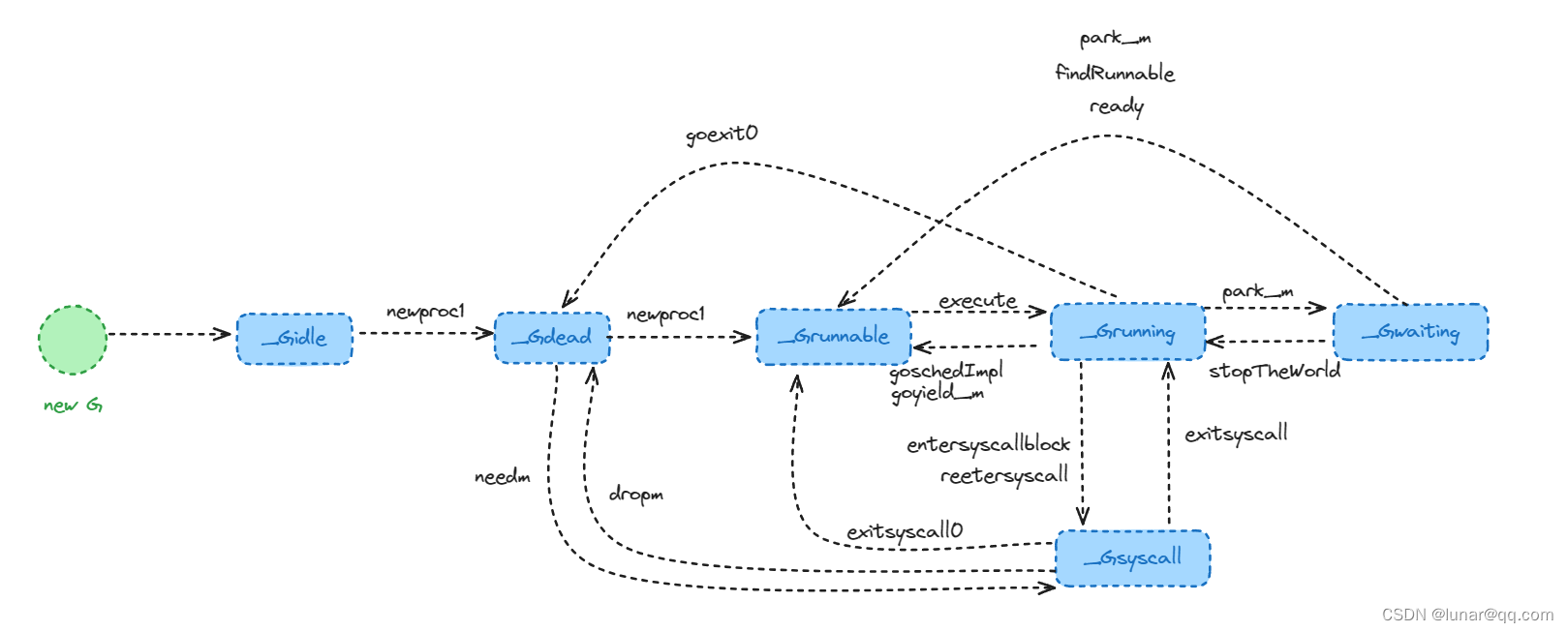
结构体runtime.g的atomicstatus字段存储了当前G的状态,如下:
const (
// _Gidle 表示 G 刚刚被分配并且还没有被初始化
_Gidle = iota // 0
// _Grunnable 表示 G 没有执行代码,没有栈的所有权,存储在运行队列中
_Grunnable // 1
// _Grunning 可以执行代码,拥有栈的所有权,被赋予了内核线程 M 和处理器 P
_Grunning // 2
// _Gsyscall 正在执行系统调用,拥有栈的所有权,没有执行用户代码,被赋予了内核线程 M 但是不在运行队列上
_Gsyscall // 3
// _Gwaiting 由于运行时而被阻塞,没有执行用户代码并且不在运行队列上,但是可能存在于 Channel 的等待队列上
_Gwaiting // 4
// _Gdead 没有被使用,没有执行代码,可能有分配的栈
_Gdead // 6
// _Gcopystack 栈正在被拷贝,没有执行代码,不在运行队列上
_Gcopystack // 8
// _Gpreempted 由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒
_Gpreempted // 9
// _Gscan GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在
_Gscan = 0x1000
......
)其中主要的六种状态是:
Gidle:G被创建但还未完全被初始化
Grunnable:当前G为可运行的,正在等待被运行
Grunning:当前的G正在运行
Gsyscall:当前G正在被系统调用
Gwaiting:当前G正在因某个原因而等待
Gdead:当前G完成了运行
下面是G状态变化图:
2.1.3.1 主动让出
有时候我们会主动调用runtime.Gosched()让出Goroutine的cpu,比如自旋锁的实现,如果我们发现锁被占用,就直接让出cpu:
type spinLock uint32
func (sl *spinLock) Lock() {
for !atomic.CompareAndSwapUint32((*uint32)(sl), 0, 1) {
runtime.Gosched()
}
}
func (sl *spinLock) Unlock() {
atomic.StoreUint32((*uint32)(sl), 0)
}
func NewSpinLock() sync.Locker {
var lock spinLock
return &lock
}
// src/runtime/proc.go
func goschedImpl(gp *g) {
status := readgstatus(gp)
if status&^_Gscan != _Grunning {
dumpgstatus(gp)
throw("bad g status")
}
casgstatus(gp, _Grunning, _Grunnable)
dropg()
lock(&sched.lock)
globrunqput(gp)
unlock(&sched.lock)
schedule()
}逻辑如下:
1.将Goroutine的状态从_Grunning变成_Grunnable
2.通过dropg()将m和Goroutine解绑
3.把Goroutine放入全局队列
4.开启新一轮调度
2.1.3.2 被动等待
这是比较常见的,比如网络I/O、chan阻塞、定时器等都会进入这里
// src/runtime/proc.go
func park_m(gp *g) {
_g_ := getg()
if trace.enabled {
traceGoPark(_g_.m.waittraceev, _g_.m.waittraceskip)
}
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
if fn := _g_.m.waitunlockf; fn != nil {
ok := fn(gp, _g_.m.waitlock)
_g_.m.waitunlockf = nil
_g_.m.waitlock = nil
if !ok {
if trace.enabled {
traceGoUnpark(gp, 2)
}
casgstatus(gp, _Gwaiting, _Grunnable)
execute(gp, true) // Schedule it back, never returns.
}
}
schedule()
}
func dropg() {
gp := getg()
setMNoWB(&gp.m.curg.m, nil)
setGNoWB(&gp.m.curg, nil)
}2.1.3.3 等待被唤醒
运行时通过goready()唤醒等待的goroutine
func goready(gp *g, traceskip int) {
systemstack(func() {
ready(gp, traceskip, true)
})
}
func ready(gp *g, traceskip int, next bool) {
if traceEnabled() {
traceGoUnpark(gp, traceskip)
}
status := readgstatus(gp)
// Mark runnable.
mp := acquirem() // disable preemption because it can be holding p in a local var
if status&^_Gscan != _Gwaiting {
dumpgstatus(gp)
throw("bad g->status in ready")
}
// status is Gwaiting or Gscanwaiting, make Grunnable and put on runq
// 修改g的状态
casgstatus(gp, _Gwaiting, _Grunnable)
// 放入p的本地队列,有概率放入runnext
runqput(mp.p.ptr(), gp, next)
wakep()
releasem(mp)
}
主要逻辑:
修改g的状态_Gwaiting->_Grunnable
放入 p的本地队列,有概率放入runnext
2.1.3.4 退出系统调用
系统调用前,运行时会调用reentersyscall().它会完成Goroutine进入系统调用前的准备工作:
func reentersyscall(pc, sp uintptr) {
gp := getg()
gp.m.locks++
gp.stackguard0 = stackPreempt
gp.throwsplit = true
// Leave SP around for GC and traceback.
// 保存当前PC和栈指针SP中的内容
save(pc, sp)
gp.syscallsp = sp
gp.syscallpc = pc
// 修改g的状态为Gsyscall
casgstatus(gp, _Grunning, _Gsyscall)
if staticLockRanking {
save(pc, sp)
}
if gp.syscallsp < gp.stack.lo || gp.stack.hi < gp.syscallsp {
systemstack(func() {
print("entersyscall inconsistent ", hex(gp.syscallsp), " [", hex(gp.stack.lo), ",", hex(gp.stack.hi), "]\n")
throw("entersyscall")
})
}
if traceEnabled() {
systemstack(traceGoSysCall)
save(pc, sp)
}
if sched.sysmonwait.Load() {
systemstack(entersyscall_sysmon)
save(pc, sp)
}
if gp.m.p.ptr().runSafePointFn != 0 {
// runSafePointFn may stack split if run on this stack
systemstack(runSafePointFn)
save(pc, sp)
}
// 解除m和p之间的绑定
gp.m.syscalltick = gp.m.p.ptr().syscalltick
pp := gp.m.p.ptr()
pp.m = 0
// 把p放到oldp中,等系统调用结束后,m优先到oldp找p
gp.m.oldp.set(pp)
gp.m.p = 0
atomic.Store(&pp.status, _Psyscall)
if sched.gcwaiting.Load() {
systemstack(entersyscall_gcwait)
save(pc, sp)
}
gp.m.locks--
}1.保存当前PC和栈指针SP中的内容
2.修改g的状态为_Gsyscall;修改p的状态为_Psyscall
3.解除p与m之间的绑定
4.将p放入oldp中(后面结束系统调用使用)
当系统调用结束之后,会调用退出系统调用的函数,将g重新执行
func exitsyscall() {
gp := getg()
gp.m.locks++ // see comment in entersyscall
if getcallersp() > gp.syscallsp {
throw("exitsyscall: syscall frame is no longer valid")
}
gp.waitsince = 0
// 到oldp找进入系统调用时m绑定的p
oldp := gp.m.oldp.ptr()
gp.m.oldp = 0
// 快路径,也就是原来进入系统调用时存放的p现在空闲,m可以直接绑定oldp
if exitsyscallfast(oldp) {
if goroutineProfile.active {
systemstack(func() {
tryRecordGoroutineProfileWB(gp)
})
}
if traceEnabled() {
if oldp != gp.m.p.ptr() || gp.m.syscalltick != gp.m.p.ptr().syscalltick {
systemstack(traceGoStart)
}
}
gp.m.p.ptr().syscalltick++
casgstatus(gp, _Gsyscall, _Grunning)
gp.syscallsp = 0
gp.m.locks--
if gp.preempt {
gp.stackguard0 = stackPreempt
} else {
gp.stackguard0 = gp.stack.lo + stackGuard
}
gp.throwsplit = false
if sched.disable.user && !schedEnabled(gp) {
Gosched()
}
return
}
if traceEnabled() {
for oldp != nil && oldp.syscalltick == gp.m.syscalltick {
osyield()
}
gp.trace.sysExitTime = traceClockNow()
}
gp.m.locks--
// Call the scheduler.
// 慢路经就进入exitsyscall0
mcall(exitsyscall0)
gp.syscallsp = 0
gp.m.p.ptr().syscalltick++
gp.throwsplit = false
}这里有一个快路径和一个慢路径
快路径就是exitsyscallfast(),直接把上面保存的oldp跟当前g的m绑定:
func exitsyscallfast(oldp *p) bool {
gp := getg()
if sched.stopwait == freezeStopWait {
return false
}
if oldp != nil && oldp.status == _Psyscall && atomic.Cas(&oldp.status, _Psyscall, _Pidle) {
wirep(oldp)
exitsyscallfast_reacquired()
return true
}
if sched.pidle != 0 {
var ok bool
systemstack(func() {
ok = exitsyscallfast_pidle()
if ok && traceEnabled() {
if oldp != nil {
for oldp.syscalltick == gp.m.syscalltick {
osyield()
}
}
traceGoSysExit()
}
})
if ok {
return true
}
}
return false
}
func wirep(pp *p) {
gp := getg()
if gp.m.p != 0 {
throw("wirep: already in go")
}
if pp.m != 0 || pp.status != _Pidle {
id := int64(0)
if pp.m != 0 {
id = pp.m.ptr().id
}
print("wirep: p->m=", pp.m, "(", id, ") p->status=", pp.status, "\n")
throw("wirep: invalid p state")
}
// 将p和m相互绑定
gp.m.p.set(pp)
pp.m.set(gp.m)
// 设置p的状态为pRunning
pp.status = _Prunning
}
慢路径就是调用exitsyscall0(),把m和g解绑,将g状态变成_Grunnable,看看有没有空闲的P,有就绑定到M然后执行g,没有就把g放到全局链表
func exitsyscall0(gp *g) {
casgstatus(gp, _Gsyscall, _Grunnable)
// 解绑M和G
dropg()
lock(&sched.lock)
var pp *p
if schedEnabled(gp) {
pp, _ = pidleget(0)
}
var locked bool
if pp == nil {
// 如果没有空闲的p,就把G放入全局队列allg
globrunqput(gp)
locked = gp.lockedm != 0
} else if sched.sysmonwait.Load() {
sched.sysmonwait.Store(false)
notewakeup(&sched.sysmonnote)
}
unlock(&sched.lock)
if pp != nil {
// 如果有空闲的p,就绑定p和m,然后执行g
acquirep(pp)
execute(gp, false) // Never returns.
}
if locked {
stoplockedm()
execute(gp, false) // Never returns.
}
stopm()
schedule() // Never returns.
}
func dropg() {
gp := getg()
setMNoWB(&gp.m.curg.m, nil)
setGNoWB(&gp.m.curg, nil)
}
2.1.4 schedt
调度器的schedt结构体存储了全局的G队列,空闲M列表和P列表:
// src/runtime/runtime2.go
type schedt struct {
lock mutex // schedt的锁
midle muintptr // 空闲的M列表
nmidle int32 // 空闲的M列表的数量
nmidlelocked int32 // 被锁定正在工作的M数
mnext int64 // 下一个被创建的 M 的 ID
maxmcount int32 // 能拥有的最大数量的 M
pidle puintptr // 空闲的 P 链表
npidle uint32 // 空闲 P 数量
nmspinning uint32 // 处于自旋状态的 M 的数量
// 全局可执行的 G 列表
runq gQueue
runqsize int32 // 全局可执行 G 列表的大小
// 全局 _Gdead 状态的空闲 G 列表
gFree struct {
lock mutex
stack gList // Gs with stacks
noStack gList // Gs without stacks
n int32
}
// sudog结构的集中存储
sudoglock mutex
sudogcache *sudog
// 有效的 defer 结构池
deferlock mutex
deferpool *_defer
......
}还有一些全局变量
// src/runtime/runtime2.go
var (
allm *m // 所有的 M
gomaxprocs int32 // P 的个数,默认为 ncpu 核数
ncpu int32
......
sched schedt // schedt 全局结构体
newprocs int32
allpLock mutex // 全局 P 队列的锁
allp []*p // 全局 P 队列,个数为 gomaxprocs
......
}2.2 程序启动流程
从简单的hello world程序开始追寻,借助dlv来进行调试,在linux下进行。
package main
import "fmt"
func main() {
fmt.Println("hello world")
}先构建
go build main.go
dlv exec ./main然后按照下面步骤执行
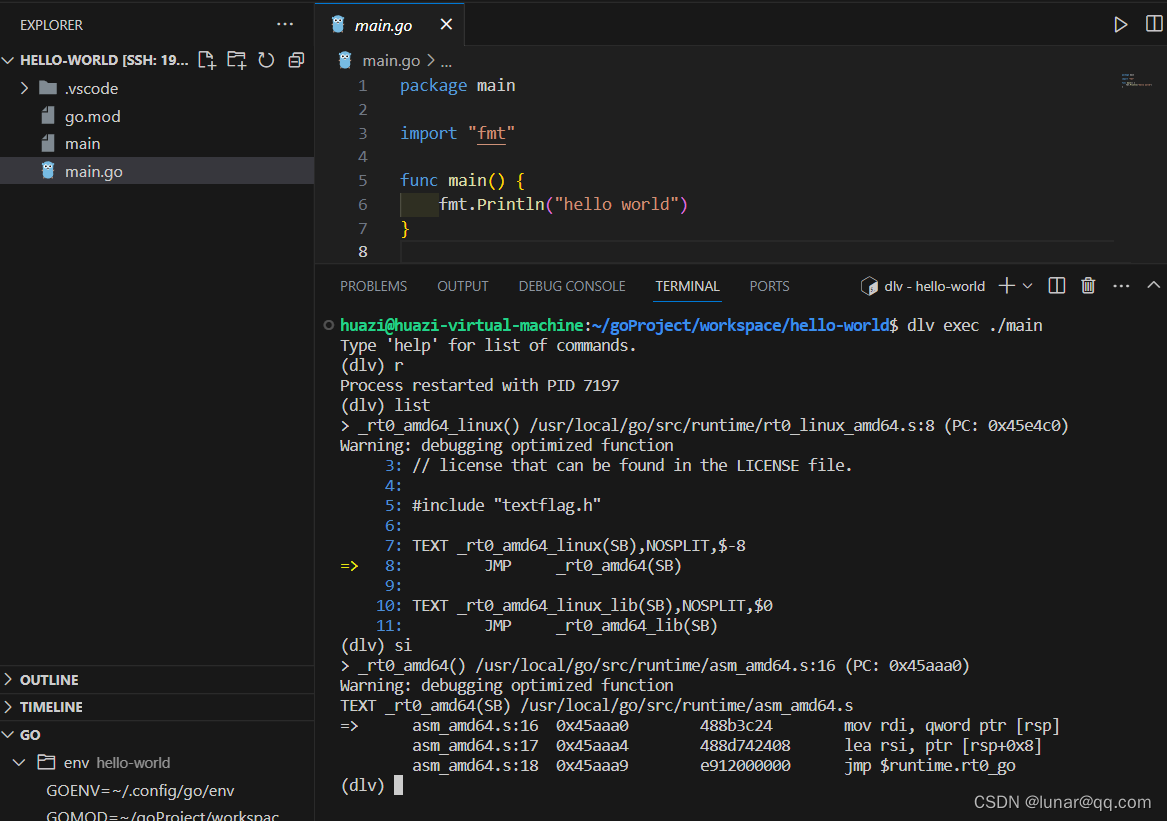
由上可知linux amd64系统的启动函数是在asm_amd64.s的runtime.rt0_go函数中。当然,不同的平台有不同的程序入口,有兴趣的可以自行了解。(我看不懂汇编,下面是别人博客的注解)
TEXT runtime·rt0_go(SB),NOSPLIT|TOPFRAME,$0
......
// 初始化g0
MOVD $runtime·g0(SB), g
......
// 初始化 m0
MOVD $runtime·m0(SB), R0
// 绑定 g0 和 m0
MOVD g, m_g0(R0)
MOVD R0, g_m(g)
......
BL runtime·schedinit(SB) // 调度器初始化
// 创建一个新的 goroutine 来启动程序
MOVD $runtime·mainPC(SB), R0 // main函数入口
.......
BL runtime·newproc(SB) // 负责根据主函数即 main 的入口地址创建可被运行时调度的执行单元goroutine
.......
// 开始启动调度器的调度循环
BL runtime·mstart(SB)
......
DATA runtime·mainPC+0(SB)/8,$runtime·main<ABIInternal>(SB) // main函数入口地址
GLOBL runtime·mainPC(SB),RODATA,$8Go程序的真正启动函数runtime.rt0_go主要做了如下几件事:
(1)初始化g0和m0,并将两者相互绑定,m0是程序启动后的初始线程,g0是m0的系统栈代表的G结构体,负责普通G在M上的调度切换;
(2)schedinit:进行各种运行时组件的初始化工作,这就包括调度器与内存分配器、回收器的初始化,这个函数主要关注mcommoninit()和Procresize()这两个函数是如何初始化M的allm和P的allp;
(3)newproc:负责根据主函数即main的入口地址创建可被运行时调度的执行单元(也就是创建G),这个函数主要关心创建一个新G干了啥
(4)mstart:开始启动调度器的调度循环
Go程序启动后的调度器主要逻辑如下:
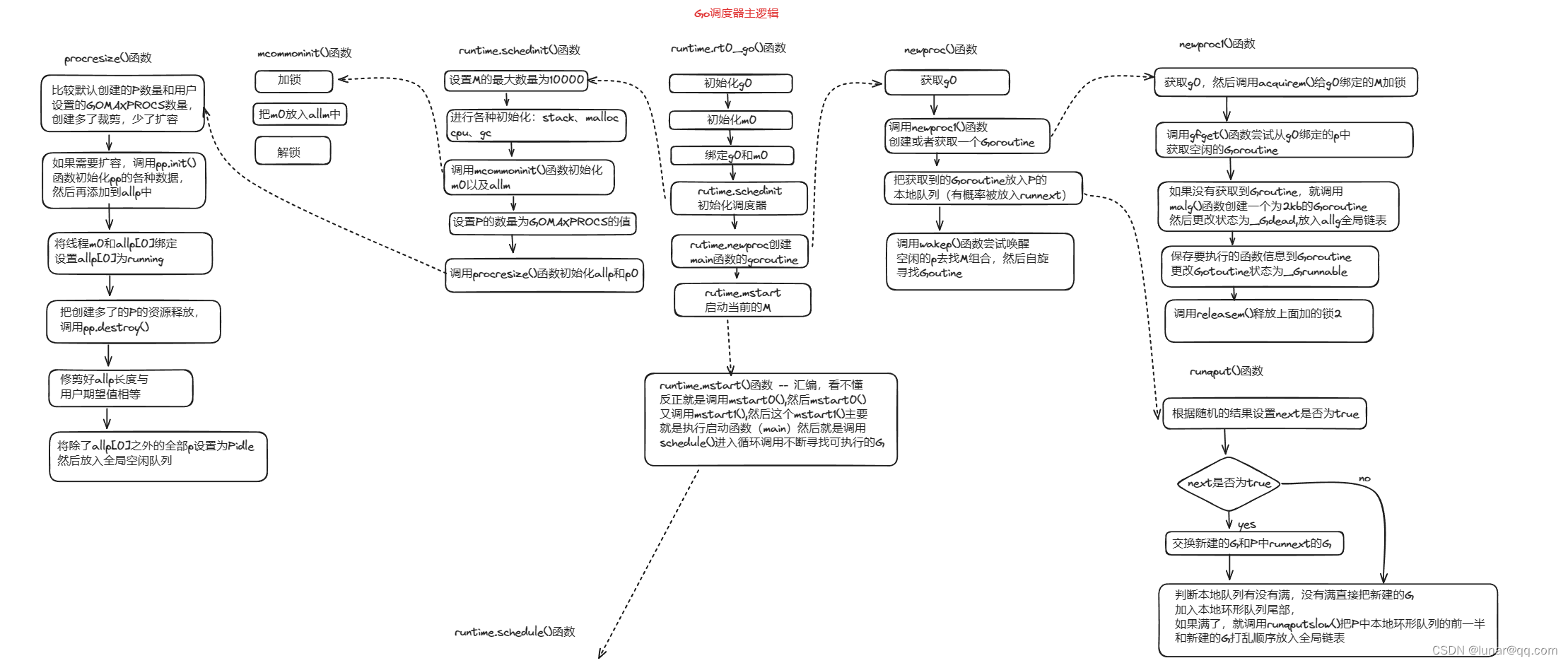
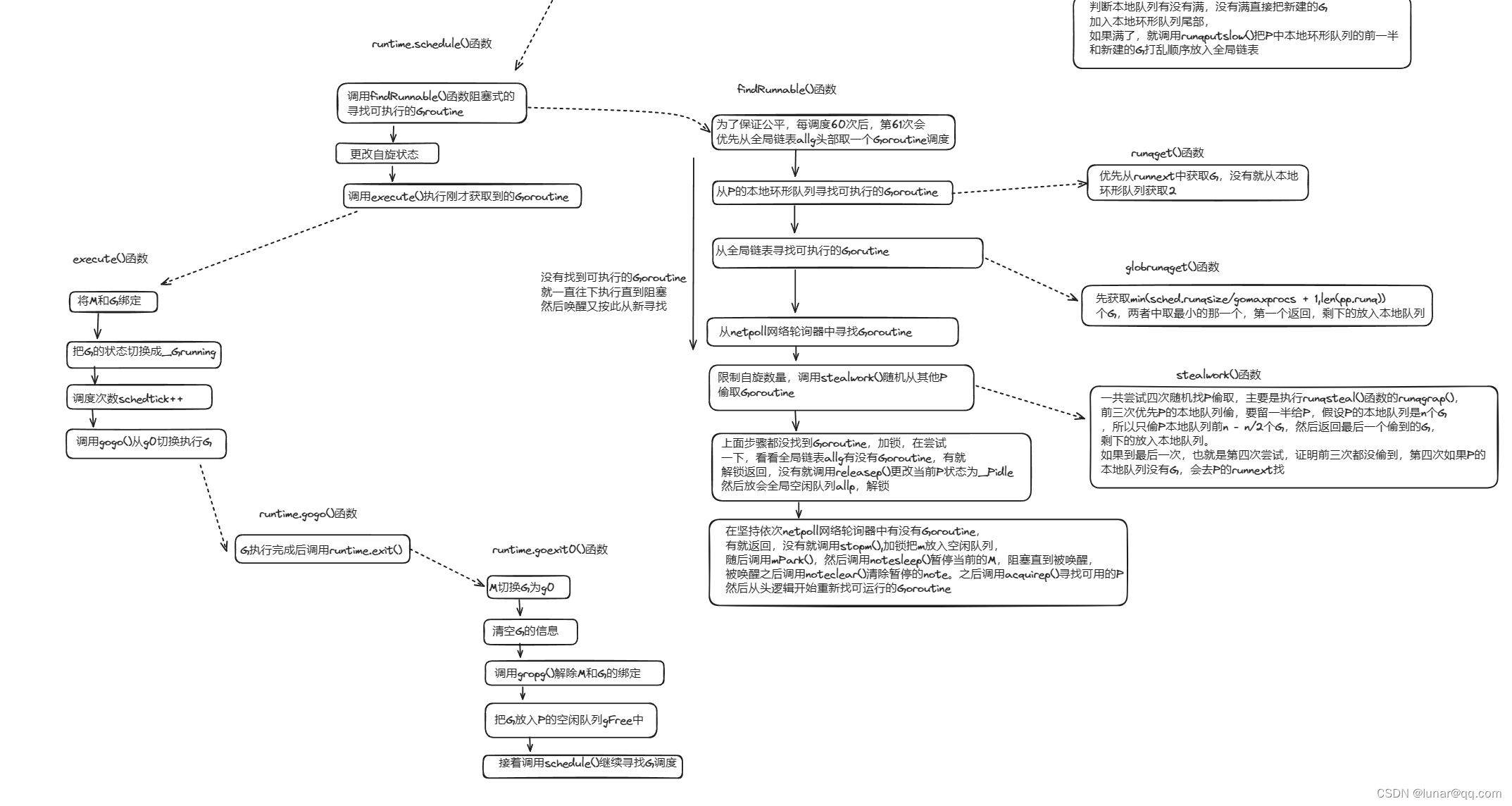
主要分两部分来走读源码:调度器的启动和调度循环
2.2.1 调度器的启动
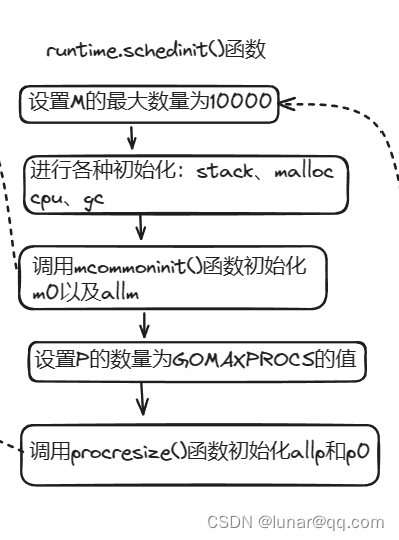
调度器启动函数在 src/runtime/proc.go包的schedinit()函数:
// 调度器初始化
func schedinit() {
...
gp := getg()
if raceenabled {
gp.racectx, raceprocctx0 = raceinit()
}
// 设置机器线程数M最大为10000
sched.maxmcount = 10000
// The world starts stopped.
worldStopped()
moduledataverify()
// 栈、内存分配器相关初始化
stackinit()
mallocinit()
...
// 初始化当前系统线程M0,添加到全局链表allm
mcommoninit(gp.m, -1)
...
// GC初始化
gcinit()
...
lock(&sched.lock)
sched.lastpoll.Store(nanotime())
// 设置p的值为GOMAXPROCS个数
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
// procresize()调整p列表,将p0和m0绑定
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
...
}schedinit()函数会设置M最大数量为10000,实际中不会达到;会分别调用stackinit()、mallocinit() 、mcommoninit()、gcinit()等执行goroutine栈初始化、进行内存分配器初始化、进行系统线程M0初始化、进行GC垃圾回收器的初始化;接着,将P个数设置为GOMAXPROCS的值,即程序能够同时运行的最大处理器数,最后会调用runtime.procresize()函数初始化P列表。
mcommoninit()函数主要负责对M0和M资源池(allm)进行一个初步的初始化,并将其添加到schedt全局结构体中,这里访问全局schedt会加锁:
// 主要负责对M0进行一个初步的初始化,并将其添加到schedt全局结构体中
func mcommoninit(mp *m, id int64) {
gp := getg()
...
lock(&sched.lock)
if id >= 0 {
mp.id = id
} else {
mp.id = mReserveID()
}
...
// Add to allm so garbage collector doesn't free g->m
// when it is just in a register or thread-local storage.
// 添加m到全局链表allm中
mp.alllink = allm
// NumCgoCall() iterates over allm w/o schedlock,
// so we need to publish it safely.
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
...
}2.2.1.1创建P的过程
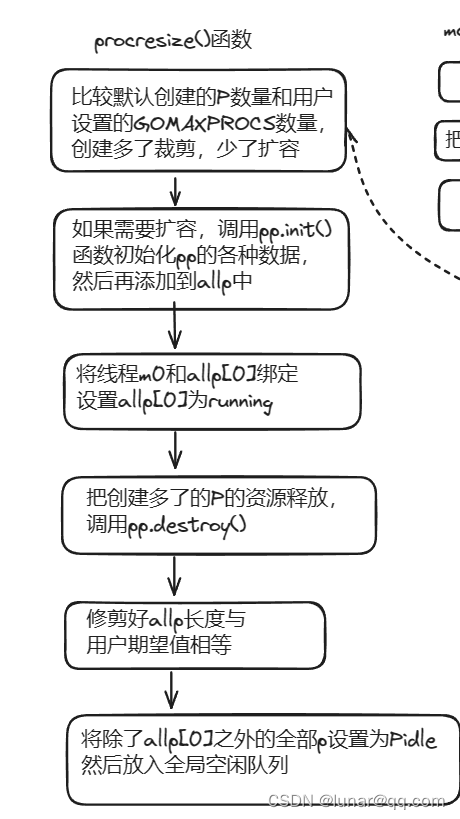
runtime.procresize()函数主要就是初始化P资源池(allp),根据用户期望值调整allp的大小。逻辑如下:
func procresize(nprocs int32) *p {
...
// 获取先前的p的个数
old := gomaxprocs
...
// 根据runtime.MAXGOPROCS调整p的数量,因为runtime.MAXGOPROCS用户可以自行定义,nprocs就是用户期待的allp的大小
if nprocs > int32(len(allp)) {
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
// 不需要扩容
allp = allp[:nprocs]
} else {
// 扩容全局p数量
nallp := make([]*p, nprocs)
// Copy everything up to allp's cap so we
// never lose old allocated Ps.
copy(nallp, allp[:cap(allp)])
allp = nallp
}
...
unlock(&allpLock)
}
// initialize new P's
// 初始化新的p -- 上面扩容新建的还未初始化
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
// 初始化p的各种数据
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}
gp := getg()
// p不为空,并且id小于nprocs,那么可以继续使用当前p
if gp.m.p != 0 && gp.m.p.ptr().id < nprocs {
// continue to use the current P
gp.m.p.ptr().status = _Prunning
gp.m.p.ptr().mcache.prepareForSweep()
} else {
...
gp.m.p = 0
pp := allp[0]
pp.m = 0
pp.status = _Pidle
// P0绑定到当前的M0
acquirep(pp)
...
}
...
// 从未使用的p释放资源
for i := nprocs; i < old; i++ {
pp := allp[i]
pp.destroy()
}
// 释放完p重置allp长度
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
idlepMask = idlepMask[:maskWords]
timerpMask = timerpMask[:maskWords]
unlock(&allpLock)
}
// 将没有本地任务的p放到空闲链表中
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
pp := allp[i]
// 忽略当前正在使用的p
if gp.m.p.ptr() == pp {
continue
}
// 设置状态为idle
pp.status = _Pidle
if runqempty(pp) {
// p的任务列表为空,放入空闲队列中
pidleput(pp, now)
} else {
// p的任务不为空,获取空闲M绑定到P上
pp.m.set(mget())
pp.link.set(runnablePs)
runnablePs = pp
}
}
stealOrder.reset(uint32(nprocs))
var int32p *int32 = &gomaxprocs // make compiler check that gomaxprocs is an int32
atomic.Store((*uint32)(unsafe.Pointer(int32p)), uint32(nprocs))
if old != nprocs {
// Notify the limiter that the amount of procs has changed.
gcCPULimiter.resetCapacity(now, nprocs)
}
// 返回包含本地队列的P链表
return runnablePs
} 
runtime.procresize()函数里面调用runtime.p.init初始化新建的P的过程如下:
// 初始化P
func (pp *p) init(id int32) {
// p的id就是它在allp中的索引
pp.id = id
// 新建时设置p状态为pgcstop
pp.status = _Pgcstop
pp.sudogcache = pp.sudogbuf[:0]
pp.deferpool = pp.deferpoolbuf[:0]
pp.wbBuf.reset()
// mcache初始化
if pp.mcache == nil {
if id == 0 {
if mcache0 == nil {
throw("missing mcache?")
}
// Use the bootstrap mcache0. Only one P will get
// mcache0: the one with ID 0.
pp.mcache = mcache0
} else {
pp.mcache = allocmcache()
}
}
if raceenabled && pp.raceprocctx == 0 {
if id == 0 {
pp.raceprocctx = raceprocctx0
raceprocctx0 = 0 // bootstrap
} else {
pp.raceprocctx = raceproccreate()
}
}
lockInit(&pp.timersLock, lockRankTimers)
// This P may get timers when it starts running. Set the mask here
// since the P may not go through pidleget (notably P 0 on startup).
timerpMask.set(id)
// Similarly, we may not go through pidleget before this P starts
// running if it is P 0 on startup.
idlepMask.clear(id)
}
这个mcache内存结构原来是在M上的,自从引入P之后,就将该结构体已到了P上,这样就不用每个M维护自己的内存分配mcache,由于P在有M可以执行时才会移动到其他M上去,空闲的M无需分配内存,这种灵活性使得整体现成的内存分配大大减少。
2.2.1.2 创建G的过程
回到2.2一开始程序启动函数runtime.rt0_go,执行完schedinit()之后,有个动作时调用runtime.newproc函数创建G,runtime.newproc入参是funcval结构体函数,代表go关键字后面调用的函数(也就是初始化过程中执行main函数的Goroutine):
// 创建g,并放入p的运行队列
func newproc(fn *funcval) {
gp := getg()
// 获取调用方PC寄存器值,即调用方程序要执行的下一条指令地址
pc := getcallerpc()
// 用g0系统栈创建Goroutine对象
// 传递的参数包括fn函数入口地址,gp(g0),调用方pc
systemstack(func() {
// 调用newproc1获取Goroutine结构
newg := newproc1(fn, gp, pc)
// 获取当前G的P
pp := getg().m.p.ptr()
// 将新的G放入P的本地运行队列
runqput(pp, newg, true)
if mainStarted {
// M启动时唤醒新的P执行G
wakep()
}
})
}逻辑流程如下图:
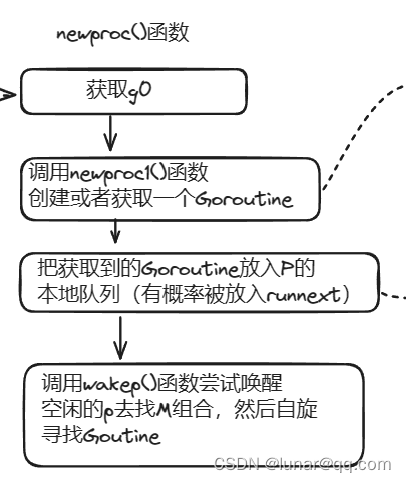
接着往下看runtime.newproc1()函数的逻辑,主要就是获取或者创建一个状态为_Grunnable的Goroutine:
// 创建一个运行fn函数的goroutine
func newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {
...
// 加锁,禁止这时G的M被抢占
mp := acquirem() // disable preemption because we hold M and P in local vars.
// 获取P
pp := mp.p.ptr()
// 从p的空闲队列gFree查找空闲G
newg := gfget(pp)
if newg == nil {
// 创建一个栈大小为2kb的G
newg = malg(stackMin)
// 更改状态为Gdead
casgstatus(newg, _Gidle, _Gdead)
// 将G加入全局allg列表中
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
...
totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // extra space in case of reads slightly beyond frame
totalSize = alignUp(totalSize, sys.StackAlign)
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
// 初始化G的信息
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.parentGoid = callergp.goid
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
if isSystemGoroutine(newg, false) {
sched.ngsys.Add(1)
} else {
// Only user goroutines inherit pprof labels.
if mp.curg != nil {
newg.labels = mp.curg.labels
}
if goroutineProfile.active {
newg.goroutineProfiled.Store(goroutineProfileSatisfied)
}
}
// Track initial transition?
newg.trackingSeq = uint8(fastrand())
if newg.trackingSeq%gTrackingPeriod == 0 {
newg.tracking = true
}
// 将G的状态CAS为 Gdead -> Grunnable
casgstatus(newg, _Gdead, _Grunnable)
gcController.addScannableStack(pp, int64(newg.stack.hi-newg.stack.lo))
...
newg.goid = pp.goidcache
pp.goidcache++
if raceenabled {
newg.racectx = racegostart(callerpc)
newg.raceignore = 0
if newg.labels != nil {
racereleasemergeg(newg, unsafe.Pointer(&labelSync))
}
}
if traceEnabled() {
traceGoCreate(newg, newg.startpc)
}
// 释放锁,对应上面的acquirem
releasem(mp)
return newg
}逻辑图如下:
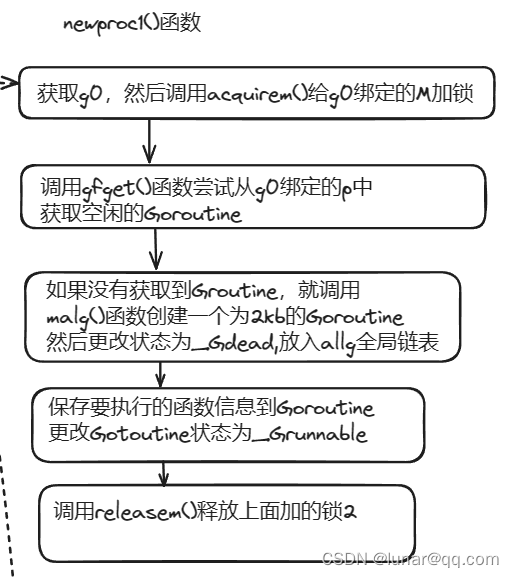
接着看newproc1()函数是怎么通过gfget()函数获取到已经存在的空闲的Goroutine的,主要就是先看当前P的本地空闲队列gFree有没有存放空闲G,没有就去全局空闲队列sched.gFree里面取32个G,本地和全局都没有就返回空,说明找不到空闲的G复用:
func gfget(pp *p) *g {
retry:
// 如果P的空闲列表gFree为空,sched的空闲列表gFree不为空
if pp.gFree.empty() && (!sched.gFree.stack.empty() || !sched.gFree.noStack.empty()) {
lock(&sched.gFree.lock)
// Move a batch of free Gs to the P.
// 从sched的gFree列表中移动32个Goroutine到P的gFree中
for pp.gFree.n < 32 {
// Prefer Gs with stacks.
gp := sched.gFree.stack.pop()
if gp == nil {
gp = sched.gFree.noStack.pop()
if gp == nil {
break
}
}
sched.gFree.n--
pp.gFree.push(gp)
pp.gFree.n++
}
unlock(&sched.gFree.lock)
goto retry
}
gp := pp.gFree.pop()
if gp == nil {
return nil
}
pp.gFree.n--
if gp.stack.lo != 0 && gp.stack.hi-gp.stack.lo != uintptr(startingStackSize) {
systemstack(func() {
stackfree(gp.stack)
gp.stack.lo = 0
gp.stack.hi = 0
gp.stackguard0 = 0
})
}
if gp.stack.lo == 0 {
// Stack was deallocated in gfput or just above. Allocate a new one.
systemstack(func() {
gp.stack = stackalloc(startingStackSize)
})
gp.stackguard0 = gp.stack.lo + stackGuard
} else {
if raceenabled {
racemalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo)
}
if msanenabled {
msanmalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo)
}
if asanenabled {
asanunpoison(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo)
}
}
return gp
}在runtime.newproc1()函数中,如果不存在空闲的G,就是上面找不到空闲可复用的G,拿会通过runtime.malg()创建一个栈大小为2kb的Goroutine:
// 创建一个新的G结构体
func malg(stacksize int32) *g {
newg := new(g)
if stacksize >= 0 {
// 如果申请的堆栈大小大于0,会通过runtime.stackalloc分配2kb的栈空间
stacksize = round2(stackSystem + stacksize)
systemstack(func() {
newg.stack = stackalloc(uint32(stacksize))
})
newg.stackguard0 = newg.stack.lo + stackGuard
newg.stackguard1 = ^uintptr(0)
// Clear the bottom word of the stack. We record g
// there on gsignal stack during VDSO on ARM and ARM64.
*(*uintptr)(unsafe.Pointer(newg.stack.lo)) = 0
}
return newg
}接着往回看runtime.newproc()函数,执行完newproc1()之后,调用runtime.runqput()函数将G放入P本地队列或者全局队列(有概率会优先被放入runnext):
// 将G放入p的本地运行队列中
func runqput(pp *p, gp *g, next bool) {
// 保留一定的随机性,不将当前G设置成为P的下一个执行的任务
if randomizeScheduler && next && fastrandn(2) == 0 {
next = false
}
if next {
retryNext:
// 将G放入P的runnext变量中,作为下一个P执行的任务
oldnext := pp.runnext
if !pp.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
if oldnext == 0 {
return
}
// Kick the old runnext out to the regular run queue.
// 获取原来的runnext存储的G,放入P本地运行队列或者全局队列
gp = oldnext.ptr()
}
retry:
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with consumers
t := pp.runqtail
// 如果p的本地队列没有满,将G放入本地环形队列
if t-h < uint32(len(pp.runq)) {
pp.runq[t%uint32(len(pp.runq))].set(gp)
atomic.StoreRel(&pp.runqtail, t+1) // store-release, makes the item available for consumption
return
}
// 如果P的本地队列满了,就把G放入全局队列
if runqputslow(pp, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
goto retry
} 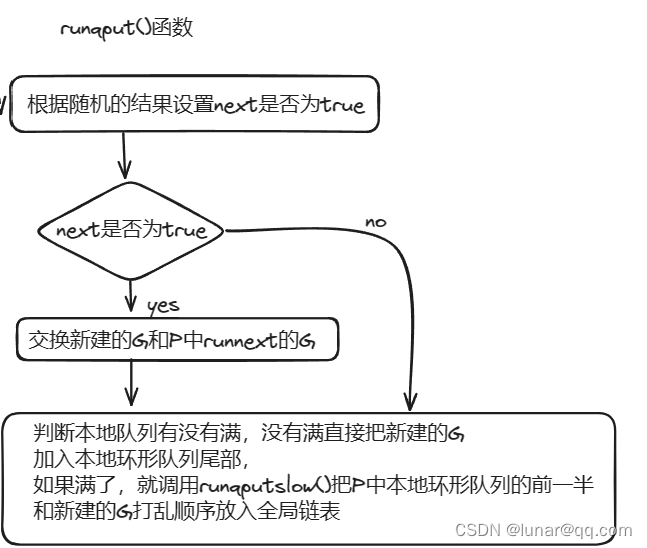
接着看如果本地队列满了,调用runqputslow()会发生什么:
// 将G和P本地队列的一部分放入全局队列
func runqputslow(pp *p, gp *g, h, t uint32) bool {
// 初始化一个本地队列长度一半 + 1的G列表batch
var batch [len(pp.runq)/2 + 1]*g
// First, grab a batch from local queue.
n := t - h
n = n / 2
if n != uint32(len(pp.runq)/2) {
throw("runqputslow: queue is not full")
}
// 将P的本地环形队列的前一半G放入batch
for i := uint32(0); i < n; i++ {
batch[i] = pp.runq[(h+i)%uint32(len(pp.runq))].ptr()
}
if !atomic.CasRel(&pp.runqhead, h, h+n) { // cas-release, commits consume
return false
}
// 把新建的G放入列表batch尾部
batch[n] = gp
// 打乱batch中存放G的顺序
if randomizeScheduler {
for i := uint32(1); i <= n; i++ {
j := fastrandn(i + 1)
batch[i], batch[j] = batch[j], batch[i]
}
}
// Link the goroutines.
// 将batch中的G连成一个链表
for i := uint32(0); i < n; i++ {
batch[i].schedlink.set(batch[i+1])
}
// 把batch列表设置成gQueue队列
var q gQueue
q.head.set(batch[0])
q.tail.set(batch[n])
// Now put the batch on global queue.
// 把gQueue队列放入全局队列
lock(&sched.lock)
globrunqputbatch(&q, int32(n+1))
unlock(&sched.lock)
return true
}主要就是当前p的本地环形队列的前一半和新建的G打乱顺序放入全局链表
最后,newproc()还剩最后一个wakep()函数,该函数就是1.1.5提到的,新建G时唤醒P去找M组合自旋,然后寻找可执行的Goroutine:
func wakep() {
...
mp := acquirem()
var pp *p
lock(&sched.lock)
pp, _ = pidlegetSpinning(0)
if pp == nil {
if sched.nmspinning.Add(-1) < 0 {
throw("wakep: negative nmspinning")
}
unlock(&sched.lock)
releasem(mp)
return
}
unlock(&sched.lock)
startm(pp, true, false)
releasem(mp)
}
func acquirem() *m {
gp := getg()
gp.m.locks++
return gp.m
}
func releasem(mp *m) {
gp := getg()
mp.locks--
if mp.locks == 0 && gp.preempt {
gp.stackguard0 = stackPreempt
}
}
func startm(pp *p, spinning, lockheld bool) {
mp := acquirem()
if !lockheld {
lock(&sched.lock)
}
if pp == nil {
if spinning {
throw("startm: P required for spinning=true")
}
pp, _ = pidleget(0)
if pp == nil {
if !lockheld {
unlock(&sched.lock)
}
releasem(mp)
return
}
}
nmp := mget()
if nmp == nil {
id := mReserveID()
unlock(&sched.lock)
var fn func()
if spinning {
fn = mspinning
}
newm(fn, pp, id)
if lockheld {
lock(&sched.lock)
}
releasem(mp)
return
}
if !lockheld {
unlock(&sched.lock)
}
...
nmp.spinning = spinning
nmp.nextp.set(pp)
notewakeup(&nmp.park)
releasem(mp)
}
2.2.1.3 小结
整个运行链条:mcommoninit -> procresize -> newproc
在调度器初始化过程中,首先通过mcommoninit对M的信号进行初始化。然后通过procresize创建与CPU核心数(或者用户指定的GOMAXPROCS)相同的P。最后通过newproc创建包含可以运行要执行函数的执行栈、运行现场的G,并将创建的G放入刚创建好的P的本地可执行队列(第一个入队的G,也就是要执行main函数的Goroutine)
调度器的设计还是挺牛逼,通过引入了一个P,巧妙的缓解了全局锁的调用频率,进一步压榨机器的性能。Goroutine本身也没有想象的那样花里胡哨,运行时只是将其作为一个需要运行的地址保存在了G中,同时对调用的参数进行了一份拷贝。重要的其实还是M,它才是执行代码的真身。
2.2.2 调度循环
所有的初始化过程上面都已经完成了,是时候启动运行时调度器了。我们已经知道,当所有工作准备完成的时候,最后一个开始执行引导调用就是runtime.mstart()函数。(这个runtime.mstart()时汇编写的,脑壳痛,我看不懂,但是它实际上是调用了mstart0())
TEXT runtime·rt0_go(SB),NOSPLIT,$0
(...)
CALL runtime·newproc(SB) // G 初始化
POPQ AX
POPQ AX
// 启动 M
CALL runtime·mstart(SB) // 开始执行
RET
DATA runtime·mainPC+0(SB)/8,$runtime·main(SB)
GLOBL runtime·mainPC(SB),RODATA,$8TEXT runtime·mstart(SB),NOSPLIT|TOPFRAME,$0
CALL runtime·mstart0(SB)
RET // not reached2.2.2.1 执行前的准备
runtime.mastart0()主要就是初始化G的栈边界,也就是在开始前要计算栈边界,确认栈边界的一些作用,然后才能执行mstart1().
func mstart0() {
gp := getg()
osStack := gp.stack.lo == 0
if osStack {
size := gp.stack.hi
if size == 0 {
size = 16384 * sys.StackGuardMultiplier
}
gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
gp.stack.lo = gp.stack.hi - size + 1024
}
// 初始化g0的参数
gp.stackguard0 = gp.stack.lo + stackGuard
// This is the g0, so we can also call go:systemstack
// functions, which check stackguard1.
gp.stackguard1 = gp.stackguard0
mstart1()
// Exit this thread.
if mStackIsSystemAllocated() {
osStack = true
}
mexit(osStack)
}再接着看mstart1()
func mstart1() {
gp := getg()
if gp != gp.m.g0 {
throw("bad runtime·mstart")
}
// 记录当前栈帧,便于其他调用复用,当进入schedule之后,再也不会回到mstart1
gp.sched.g = guintptr(unsafe.Pointer(gp))
gp.sched.pc = getcallerpc()
gp.sched.sp = getcallersp()
asminit()
minit()
// 设置信号handler;在minit之后,因为minit可以准备处理信号的线程
if gp.m == &m0 {
mstartm0()
}
// 执行启动函数
if fn := gp.m.mstartfn; fn != nil {
fn()
}
// 如果当前m并非m0(m0已经跟p0绑定),则要求绑定p
if gp.m != &m0 {
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
// 准备好后,开始调度循环,永不返回
schedule()
}2.2.2.2 核心调度
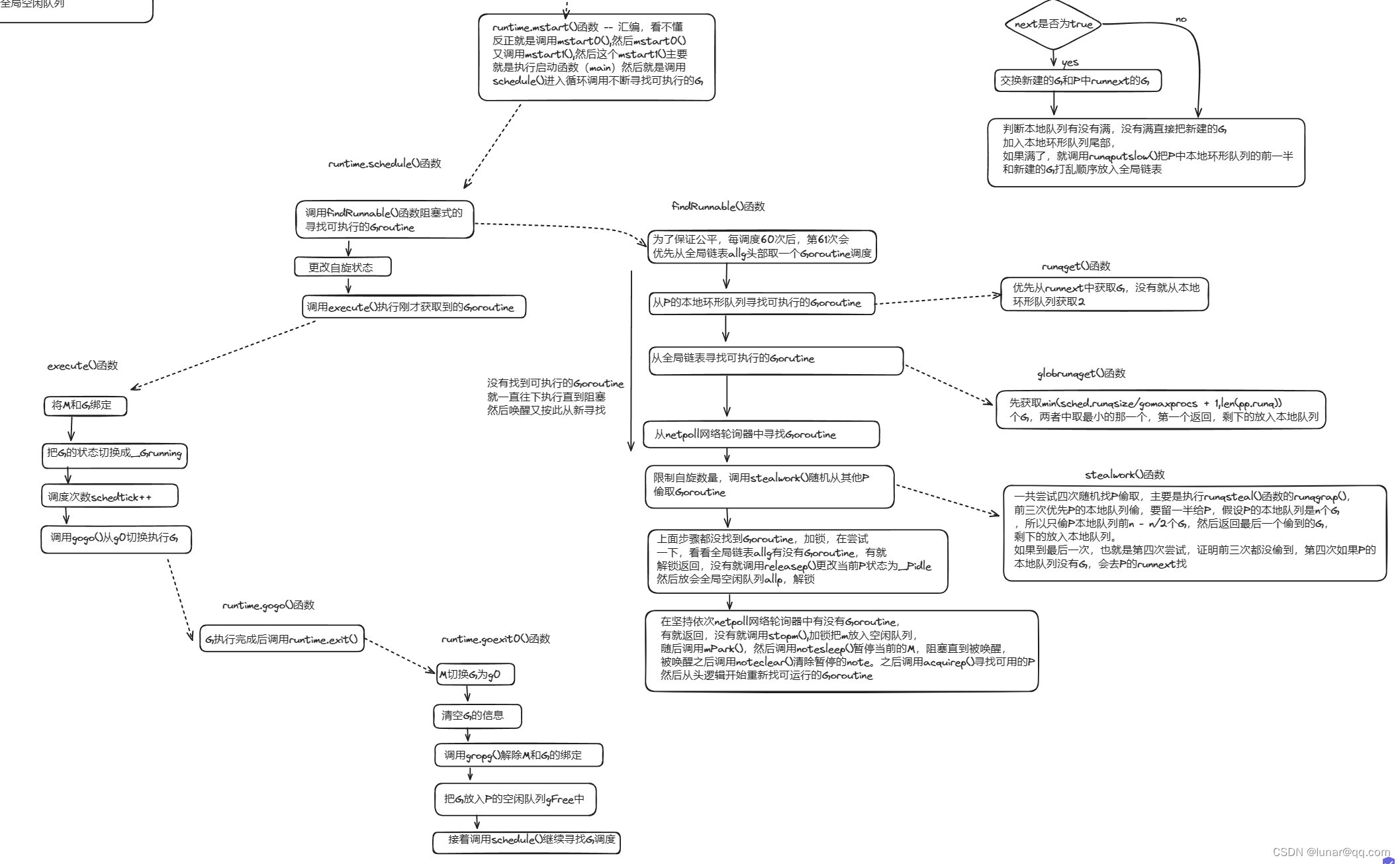
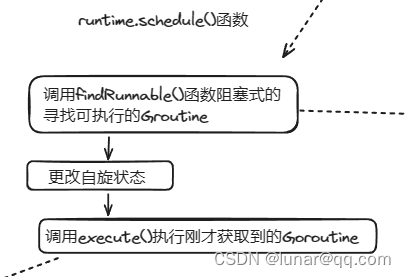
runtime.schedule()函数的逻辑是:
func schedule() {
mp := getg().m
if mp.locks != 0 {
throw("schedule: holding locks")
}
if mp.lockedg != 0 {
stoplockedm()
execute(mp.lockedg.ptr(), false) // Never returns.
}
if mp.incgo {
throw("schedule: in cgo")
}
top:
pp := mp.p.ptr()
pp.preempt = false
// 安全检查,如果G所在的M处于自旋状态,那么P的运行队列为空
if mp.spinning && (pp.runnext != 0 || pp.runqhead != pp.runqtail) {
throw("schedule: spinning with local work")
}
// 阻塞式查找可用的G
gp, inheritTime, tryWakeP := findRunnable() // blocks until work is available
if debug.dontfreezetheworld > 0 && freezing.Load() {
lock(&deadlock)
lock(&deadlock)
}
// M这个时候一定获取到了G,如果M是自旋状态,重置其状态到非自旋
if mp.spinning {
resetspinning()
}
if sched.disable.user && !schedEnabled(gp) {
lock(&sched.lock)
if schedEnabled(gp) {
unlock(&sched.lock)
} else {
sched.disable.runnable.pushBack(gp)
sched.disable.n++
unlock(&sched.lock)
goto top
}
}
if tryWakeP {
wakep()
}
if gp.lockedm != 0 {
startlockedm(gp)
goto top
}
// 执行G
execute(gp, inheritTime)
}
接着看这个funRunnable()函数:

func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
mp := getg().m
top:
pp := mp.p.ptr()
if sched.gcwaiting.Load() {
gcstopm()
goto top
}
if pp.runSafePointFn != 0 {
runSafePointFn()
}
now, pollUntil, _ := checkTimers(pp, 0)
if traceEnabled() || traceShuttingDown() {
gp := traceReader()
if gp != nil {
casgstatus(gp, _Gwaiting, _Grunnable)
traceGoUnpark(gp, 0)
return gp, false, true
}
}
// Try to schedule a GC worker.
// 如果需要GC,不再进行调度
if gcBlackenEnabled != 0 {
gp, tnow := gcController.findRunnableGCWorker(pp, now)
if gp != nil {
return gp, false, true
}
now = tnow
}
// 每调度60次,在61次时就尝试从全局队列取一个G,保证公平性;不然一直处理p的本地队列导致全局队列的G饥饿
if pp.schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
// 从全局队列获取g
gp := globrunqget(pp, 1)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}
// Wake up the finalizer G.
if fingStatus.Load()&(fingWait|fingWake) == fingWait|fingWake {
if gp := wakefing(); gp != nil {
ready(gp, 0, true)
}
}
if *cgo_yield != nil {
asmcgocall(*cgo_yield, nil)
}
// local runq
// 从本地队列获取g
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}
// global runq
// 从全局队列获取一些(min(sched.runqsize/gomaxprocs + 1,len(pp.runq)))G
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}
// 从netpoll网络轮询器中尝试获取G,优先级比从其他p偷取G要高
if netpollinited() && netpollWaiters.Load() > 0 && sched.lastpoll.Load() != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
}
// 自旋M:从其他P中窃取任务G
// 限制自旋M数量到忙碌p数量的一半,避免一半p数量、并行机制很慢时的cpu消耗
if mp.spinning || 2*sched.nmspinning.Load() < gomaxprocs-sched.npidle.Load() {
if !mp.spinning {
mp.becomeSpinning()
}
// 从其他p或者timer中偷取G
gp, inheritTime, tnow, w, newWork := stealWork(now)
if gp != nil {
// Successfully stole.
return gp, inheritTime, false
}
if newWork {
// There may be new timer or GC work; restart to
// discover.
goto top
}
now = tnow
if w != 0 && (pollUntil == 0 || w < pollUntil) {
// Earlier timer to wait for.
pollUntil = w
}
}
// 没有任何work可做
// 如果我们在GC mark阶段,则可以安全的扫描并标记对象为黑色
// 然后便由work可做,运行idlle-time标记而非直接放弃当前的p
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) && gcController.addIdleMarkWorker() {
node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop())
if node != nil {
pp.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := node.gp.ptr()
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
gcController.removeIdleMarkWorker()
}
gp, otherReady := beforeIdle(now, pollUntil)
if gp != nil {
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
if otherReady {
goto top
}
// 放弃当前的p之前,对allp做一个快照
allpSnapshot := allp
idlepMaskSnapshot := idlepMask
timerpMaskSnapshot := timerpMask
// return P and block
// 准备归还p,对调度器加锁
lock(&sched.lock)
if sched.gcwaiting.Load() || pp.runSafePointFn != 0 {
// 进入了gc,回到顶部停止m
unlock(&sched.lock)
goto top
}
// 如果全局队列中又发现了任务
if sched.runqsize != 0 {
// 赶紧偷掉返回
gp := globrunqget(pp, 0)
unlock(&sched.lock)
return gp, false, false
}
if !mp.spinning && sched.needspinning.Load() == 1 {
// See "Delicate dance" comment below.
mp.becomeSpinning()
unlock(&sched.lock)
goto top
}
// 归还当前的p
if releasep() != pp {
throw("findrunnable: wrong p")
}
// 将p放入idle链表
now = pidleput(pp, now)
// 解锁,完成归还
unlock(&sched.lock)
// 这里要非常小心:线程从自旋到非自旋状态的转换,可能与新Goroutine的提交同时发生
wasSpinning := mp.spinning
if mp.spinning {
// M即将睡眠,状态不再是spinning
mp.spinning = false
if sched.nmspinning.Add(-1) < 0 {
throw("findrunnable: negative nmspinning")
}
// 再次检查所有p的runqueue是否有可执行的g
pp := checkRunqsNoP(allpSnapshot, idlepMaskSnapshot)
if pp != nil {
acquirep(pp)
mp.becomeSpinning()
goto top
}
// Check for idle-priority GC work again.
// 休眠时再次检查GC work
pp, gp := checkIdleGCNoP()
if pp != nil {
acquirep(pp)
mp.becomeSpinning()
// Run the idle worker.
pp.gcMarkWorkerMode = gcMarkWorkerIdleMode
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
pollUntil = checkTimersNoP(allpSnapshot, timerpMaskSnapshot, pollUntil)
}
// Poll network until next timer.
// 休眠前再次检测poll网络
if netpollinited() && (netpollWaiters.Load() > 0 || pollUntil != 0) && sched.lastpoll.Swap(0) != 0 {
sched.pollUntil.Store(pollUntil)
if mp.p != 0 {
throw("findrunnable: netpoll with p")
}
if mp.spinning {
throw("findrunnable: netpoll with spinning")
}
delay := int64(-1)
if pollUntil != 0 {
if now == 0 {
now = nanotime()
}
delay = pollUntil - now
if delay < 0 {
delay = 0
}
}
if faketime != 0 {
// When using fake time, just poll.
delay = 0
}
list := netpoll(delay) // block until new work is available
// Refresh now again, after potentially blocking.
now = nanotime()
sched.pollUntil.Store(0)
sched.lastpoll.Store(now)
if faketime != 0 && list.empty() {
// Using fake time and nothing is ready; stop M.
// When all M's stop, checkdead will call timejump.
stopm()
goto top
}
lock(&sched.lock)
pp, _ := pidleget(now)
unlock(&sched.lock)
if pp == nil {
injectglist(&list)
} else {
acquirep(pp)
if !list.empty() {
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
if wasSpinning {
mp.becomeSpinning()
}
goto top
}
} else if pollUntil != 0 && netpollinited() {
pollerPollUntil := sched.pollUntil.Load()
if pollerPollUntil == 0 || pollerPollUntil > pollUntil {
netpollBreak()
}
}
// 休眠当前M
stopm()
goto top
}这个runtime.findrunnable()函数有点长,主要工作如下:
(1)首先检查是否正在GC,如果是就休眠当前的M
(2)为了保证公平,当全局队列中有待执行的G时,通过schedtick对61取模,意思就是每61次调度时,会有一次从全局的运行队列中查找一个可执行的G,这样可以避免全局队列的G长时间无人调度出现饥饿。
(3)调用runtime.runqget()函数尝试从当前P的本地环形队列中获取_Grunnable的G,获取到就返回,没获取到就执行下面逻辑(下面展开)
(4)调用runtime.globalget()函数尝试从全局链表中获取G,获取到就返回,没获取到就执行下面逻辑
(5)从netpoll网络轮询器中尝试获取G,获取到就返回,没获取到就执行下面逻辑
(6)调用runtime.stealWork()函数尝试从别的P偷取G,获取到就返回,没获取到就执行下面逻辑(下面展开)
(7)检查此时是否是GC mark阶段,如果是,则直接返回mark阶段的G
(8)上面都没找到,准备放弃当前的P,对allp进行快照
(9)对调度器加锁,准备归还P
(10)再次检查全局队列有没有G,有就返回,解锁
(11)此时调度器被锁住,又找不到可执行的G,那就调用releasep()释放当前的p,把m和p解绑,然后把p的状态设置为_Pidle,最后调用pidleput()放回全局空闲列表,然后解锁
(12)因为上面M和P解绑了,所以要把M的状态从自旋切换成非自旋状态。并且减少nmspinning
(13)此时仍然需要重新检查所有的列表,如果在全局队列中发现了G,则直接返回
(14)接着在检查是否是GC mark阶段,如果是,则直接返回mark阶段的G
(15)最后还需要再检查一次netpoll,找到就返回,找不到就休眠当前的M
(16)基于note机制被唤醒之后,M会找空闲的P绑定,然后从新回到(1)接着找G
下面是对上某些函数的展开
2.2.2.2.1 runtime.runqget()从本地队列获取G
优先从runnext中获取,没有就从本地环形队列找
// 从p的本地队列中获取G
func runqget(pp *p) (gp *g, inheritTime bool) {
// If there's a runnext, it's the next G to run.
// 如果p有一个runnext,则它就是下一个要执行的g
next := pp.runnext
// 如果runnext不为空,而CAS失败,则它有可能被其他p偷取了,
// 因为其他p可以竞争机会到runnext为0,当前p只能只能设置该字段为非0(只有当前p能把g放到runnext,取的话自己和别的p都可以)
if next != 0 && pp.runnext.cas(next, 0) {
return next.ptr(), true
}
for {
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with other consumers
t := pp.runqtail
if t == h {
return nil, false
}
// 获取头部指针指向的G
gp := pp.runq[h%uint32(len(pp.runq))].ptr()
if atomic.CasRel(&pp.runqhead, h, h+1) { // cas-release, commits consume
return gp, false
}
}
}2.2.2.2.2 runtime.globrunqget()从全局队列获取G
先获取min(sched.runqsize/gomaxprocs + 1,len(pp.runq))个G,两者中取最小的那一个(如果全局队列不为空,最少都会获取一个,最多获取本地队列的一半,防止获取太多别的P获取不到),第一个返回,剩下的放入本地队列
// 从全局队列获取G
func globrunqget(pp *p, max int32) *g {
assertLockHeld(&sched.lock)
// 如果全局队列没有G直接返回
if sched.runqsize == 0 {
return nil
}
// 计算n,表示要从全局队列放入本地队列的G的个数
n := sched.runqsize/gomaxprocs + 1
if n > sched.runqsize {
n = sched.runqsize
}
// 不能超过指定要取的最大数量max
if max > 0 && n > max {
n = max
}
// 计算能不能用本地队列的一半容量存放下n个G,如果放不下就设置n为本地队列的一半
if n > int32(len(pp.runq))/2 {
n = int32(len(pp.runq)) / 2
}
sched.runqsize -= n
// 取全局队列的头部G返回
gp := sched.runq.pop()
n--
// 剩下的放进本地队列
for ; n > 0; n-- {
gp1 := sched.runq.pop()
runqput(pp, gp1, false)
}
return gp
}2.2.2.2.3 runtime.stealWork()随机从别的P偷取G
一共尝试四次随机找P偷取,主要是执行runqsteal()函数的runqgrap(),前三次优先P的本地队列偷,要留后一半给P,假设P的本地队列是n个G,所以只偷P本地队列前n - n/2个G,然后返回最后一个偷到的G(为啥返回的是偷到的最后一个G,个人感觉可能是因为第四次有可能是从runnext偷的G,执行的优先级比较高,纯个人看法),剩下的放入本地队列。如果到最后一次,也就是第四次尝试,证明前三次都没偷到,第四次如果P的本地队列没有G,会去P的runnext找
func stealWork(now int64) (gp *g, inheritTime bool, rnow, pollUntil int64, newWork bool) {
pp := getg().m.p.ptr()
ranTimer := false
const stealTries = 4
for i := 0; i < stealTries; i++ {
// 最后一次才开始去pp的runnext偷g
stealTimersOrRunNextG := i == stealTries-1
for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {
...
// Don't bother to attempt to steal if p2 is idle.
if !idlepMask.read(enum.position()) {
if gp := runqsteal(pp, p2, stealTimersOrRunNextG); gp != nil {
return gp, false, now, pollUntil, ranTimer
}
}
}
}
return nil, false, now, pollUntil, ranTimer
}
func runqsteal(pp, p2 *p, stealRunNextG bool) *g {
t := pp.runqtail
// 随机遍历p尝试偷取G
n := runqgrab(p2, &pp.runq, t, stealRunNextG)
if n == 0 {
return nil
}
n--
gp := pp.runq[(t+n)%uint32(len(pp.runq))].ptr()
if n == 0 {
// 如果只偷了一个,也就是最后一次尝试偷取,从目标的runnext偷到了G,直接返回
return gp
}
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with consumers
if t-h+n >= uint32(len(pp.runq)) {
throw("runqsteal: runq overflow")
}
atomic.StoreRel(&pp.runqtail, t+n) // store-release, makes the item available for consumption
// 返回最后一个偷盗的G
return gp
}
func runqgrab(pp *p, batch *[256]guintptr, batchHead uint32, stealRunNextG bool) uint32 {
for {
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with other consumers
t := atomic.LoadAcq(&pp.runqtail) // load-acquire, synchronize with the producer
n := t - h
// pp为偷取的目标,这里的n表示pp本地队列去掉一半还剩多少(要给pp留一半G)
n = n - n/2
if n == 0 {
// 如果pp的本地队列没有G,转头去偷pp的runnext
if stealRunNextG {
// Try to steal from pp.runnext.
if next := pp.runnext; next != 0 {
if pp.status == _Prunning {
if GOOS != "windows" && GOOS != "openbsd" && GOOS != "netbsd" {
usleep(3)
} else {
// On some platforms system timer granularity is
// 1-15ms, which is way too much for this
// optimization. So just yield.
osyield()
}
}
if !pp.runnext.cas(next, 0) {
continue
}
batch[batchHead%uint32(len(batch))] = next
return 1
}
}
return 0
}
if n > uint32(len(pp.runq)/2) { // read inconsistent h and t
continue
}
// 从pp的头部开始偷到n个到本地队列
for i := uint32(0); i < n; i++ {
g := pp.runq[(h+i)%uint32(len(pp.runq))]
batch[(batchHead+i)%uint32(len(batch))] = g
}
if atomic.CasRel(&pp.runqhead, h, h+n) { // cas-release, commits consume
return n
}
}
}2.2.2.2.4 M与P的绑定
func acquirep(pp *p) {
// Do the part that isn't allowed to have write barriers.
wirep(pp)
pp.mcache.prepareForSweep()
if traceEnabled() {
traceProcStart()
}
}
func wirep(pp *p) {
gp := getg()
if gp.m.p != 0 {
throw("wirep: already in go")
}
if pp.m != 0 || pp.status != _Pidle {
id := int64(0)
if pp.m != 0 {
id = pp.m.ptr().id
}
print("wirep: p->m=", pp.m, "(", id, ") p->status=", pp.status, "\n")
throw("wirep: invalid p state")
}
// 将p和m相互绑定
gp.m.p.set(pp)
pp.m.set(gp.m)
// 设置p的状态为pRunning
pp.status = _Prunning
}2.2.2.2.5 M的休眠与唤醒
func stopm() {
gp := getg()
...
lock(&sched.lock)
// 把M放回全局空闲队列
mput(gp.m)
unlock(&sched.lock)
// 再此阻塞直到被唤醒
mPark()
// 重新绑定p
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
// 把M放回全局空闲队列
func mput(mp *m) {
assertLockHeld(&sched.lock)
mp.schedlink = sched.midle
sched.midle.set(mp)
sched.nmidle++
checkdead()
}
func mPark() {
gp := getg()
// 暂停当前的M,在此处阻塞,直到被唤醒
notesleep(&gp.m.park)
// 清除暂停的note
noteclear(&gp.m.park)
}2.2.2.2.6 execute()
从上面的findrunnable()找到可执行的G之后,就会进入execute()
func execute(gp *g, inheritTime bool) {
mp := getg().m
if goroutineProfile.active {
tryRecordGoroutineProfile(gp, osyield)
}
// 将G绑定到当前的M上
mp.curg = gp
gp.m = mp
// 将g正是切换成Grunnable状态
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + stackGuard
if !inheritTime {
// 调度次数加1
mp.p.ptr().schedtick++
}
// Check whether the profiler needs to be turned on or off.
hz := sched.profilehz
if mp.profilehz != hz {
setThreadCPUProfiler(hz)
}
if traceEnabled() {
// GoSysExit has to happen when we have a P, but before GoStart.
// So we emit it here.
if gp.syscallsp != 0 {
traceGoSysExit()
}
traceGoStart()
}
// gogo完成从g0到gp真正的切换
gogo(&gp.sched)
}2.2.2.2.7 goexit0()
上面其实调用到了gogo()函数,但是是汇编写的,我不太熟悉,大概就是把g0切换成要执行的G,执行完成之后调用runtime.exit(),最后调用的runtime.goexit0(),把G切换回g0,然后清空G的信息,调用gdropg()解除M和G的绑定,然后把G放入当前P的空闲队列gFree中,接着调用schedule()开启新一轮调度循环。
func goexit1() {
if raceenabled {
racegoend()
}
if traceEnabled() {
traceGoEnd()
}
mcall(goexit0)
}
// goexit continuation on g0.
func goexit0(gp *g) {
mp := getg().m
pp := mp.p.ptr()
// 切换g的状态 Grunning -> Gdead
casgstatus(gp, _Grunning, _Gdead)
gcController.addScannableStack(pp, -int64(gp.stack.hi-gp.stack.lo))
if isSystemGoroutine(gp, false) {
sched.ngsys.Add(-1)
}
// 清理G
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
mp.lockedg = 0
gp.preemptStop = false
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = waitReasonZero
gp.param = nil
gp.labels = nil
gp.timer = nil
if gcBlackenEnabled != 0 && gp.gcAssistBytes > 0 {
assistWorkPerByte := gcController.assistWorkPerByte.Load()
scanCredit := int64(assistWorkPerByte * float64(gp.gcAssistBytes))
gcController.bgScanCredit.Add(scanCredit)
gp.gcAssistBytes = 0
}
// 解绑M和G
dropg()
if GOARCH == "wasm" { // no threads yet on wasm
// 把G放到pp的gFree空闲队列中
gfput(pp, gp)
// 再次调度
schedule() // never returns
}
if mp.lockedInt != 0 {
print("invalid m->lockedInt = ", mp.lockedInt, "\n")
throw("internal lockOSThread error")
}
gfput(pp, gp)
if locked {
if GOOS != "plan9" { // See golang.org/issue/22227.
gogo(&mp.g0.sched)
} else {
// Clear lockedExt on plan9 since we may end up re-using
// this thread.
mp.lockedExt = 0
}
}
schedule()
}3 引用
深入分析Go1.18 GMP调度器底层原理 - 知乎 (zhihu.com)
深入 golang -- GMP调度 - 知乎 (zhihu.com)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









