






开源历程
2023年6月7日,浦语系列发布首个千亿参数大模型,正式拉开了其大规模中文语言模型发展的序幕。同年7月6日,InterLM-7B模型开源,成为首个支持免费商用的模型,并率先推出完整的全链条开源工具体系,极大地降低了开发者的使用门槛。随后,9月20日,InterLM-20B模型正式开源,开源工具体系也迎来了全面升级,进一步提升了开发效率和模型应用范围。进入2024年,1月7日,InterLM2模型开源,其性能在同量级开源模型中脱颖而出,展现了强劲的竞争力。到了7月4日,InterLM2.5正式开源,其中 InterLM2.5-20B-chat 模型表现尤为突出,与当时业界领先的 GPT-4(20240409)模型在多项评测中旗鼓相当,充分展示了浦语系列在大模型领域的持续创新。


开源工具箱链路
标准化的开源工具链与算法库,全面覆盖了从模型预训练、数据处理、分布式训练到模型评测与部署的全链条流程。其功能模块高度集成且灵活,可支持多种任务需求,例如大规模语料的清洗与标注、预训练参数优化、模型微调、性能调优以及多场景的应用评测。同时,这套工具链还提供丰富的可扩展接口和详细的文档,方便开发者快速上手和深度定制,极大地提升了模型开发的效率与可用性,为科研和工业界的各类大模型项目提供了有力支持。
优秀的数据集:万卷-CC
与其他开源英文 CC 数据集相比,WanJuan2.0 (WanJuan-CC) 展现了显著的优势,尤其在安全性和实用性方面表现突出:
- WanJuan2.0 是基于 CommonCrawl 提取的 1T Tokens 高质量英文网络文本数据集,而其他开源 CC 数据集通常在语料清洗与筛选上不够精细,可能含有更多的低质量或潜在有害内容。
- 在使用 Perspective API 对语料在攻击性语言、偏见、冒犯性等维度进行评估时,WanJuan2.0 的表现显著优于同类数据集,体现了更高的安全性,为模型在实际应用中的可信度提供了保障。
2.验证集困惑度 (PPL) 对比:
- WanJuan2.0 在四个验证集上的困惑度均表现出竞争力,尤其是在 tiny-stories 等对语言流畅性要求更高的数据集上,其 PPL 显著低于其他数据集。这表明基于 WanJuan2.0 训练的模型生成文本更为自然流畅。
- 相较而言,其他数据集在语言生成任务中可能面临更高的困惑度,导致生成内容流畅性和一致性较弱。
3.下游任务表现对比:
- 在六个下游任务的评估中,基于 WanJuan2.0 训练的模型准确率明显高于使用其他 CC 数据集训练的模型。特别是在语言理解和文本补全任务中,WanJuan2.0 显著提升了模型的实用性和通用能力。
- 其他 CC 数据集由于数据质量的限制,在下游任务的泛化能力上相对逊色。
4.模型性能对比实验:
- 使用 1B 参数模型分别训练 WanJuan2.0 和其他 CC 数据集,并采用验证集的困惑度 (PPL) 和下游任务的准确率作为评估指标。结果表明,基于 WanJuan2.0 训练的模型在英文文本补全和通用语言任务中性能更优。
- 相比之下,其他数据集在训练相同规模模型时,模型的性能往往存在较大差距,尤其是在语言生成相关任务上。
通过这些对比,可以看出,WanJuan2.0 凭借其高质量的语料清洗与筛选,在安全性、流畅性和下游任务表现上全面超越了其他开源英文 CC 数据集,成为更高效、更可靠的选择。
高效的预训练框架:InternEvo
InternEvo 是一个开源的高效轻量级训练框架,以其卓越的性能和简洁的设计脱颖而出,专为无需繁琐依赖的模型预训练任务而打造。通过一个统一的代码库,InternEvo 不仅支持在超大规模集群(如上千 GPU)上高效地执行预训练任务,还能够轻松适配单个 GPU 的微调需求,展现出极强的灵活性和适用性。
InternEvo 在性能优化上表现尤为突出:当在 1024 个 GPU 的大规模集群上运行时,其加速效率可达到接近 90%,远超同类框架的分布式效率。这一性能表现使其在高效利用硬件资源的同时,大幅缩短了模型训练时间,为开发者提供了强大的训练能力与极具竞争力的算力成本优势。
全能的微调工具:XTuner
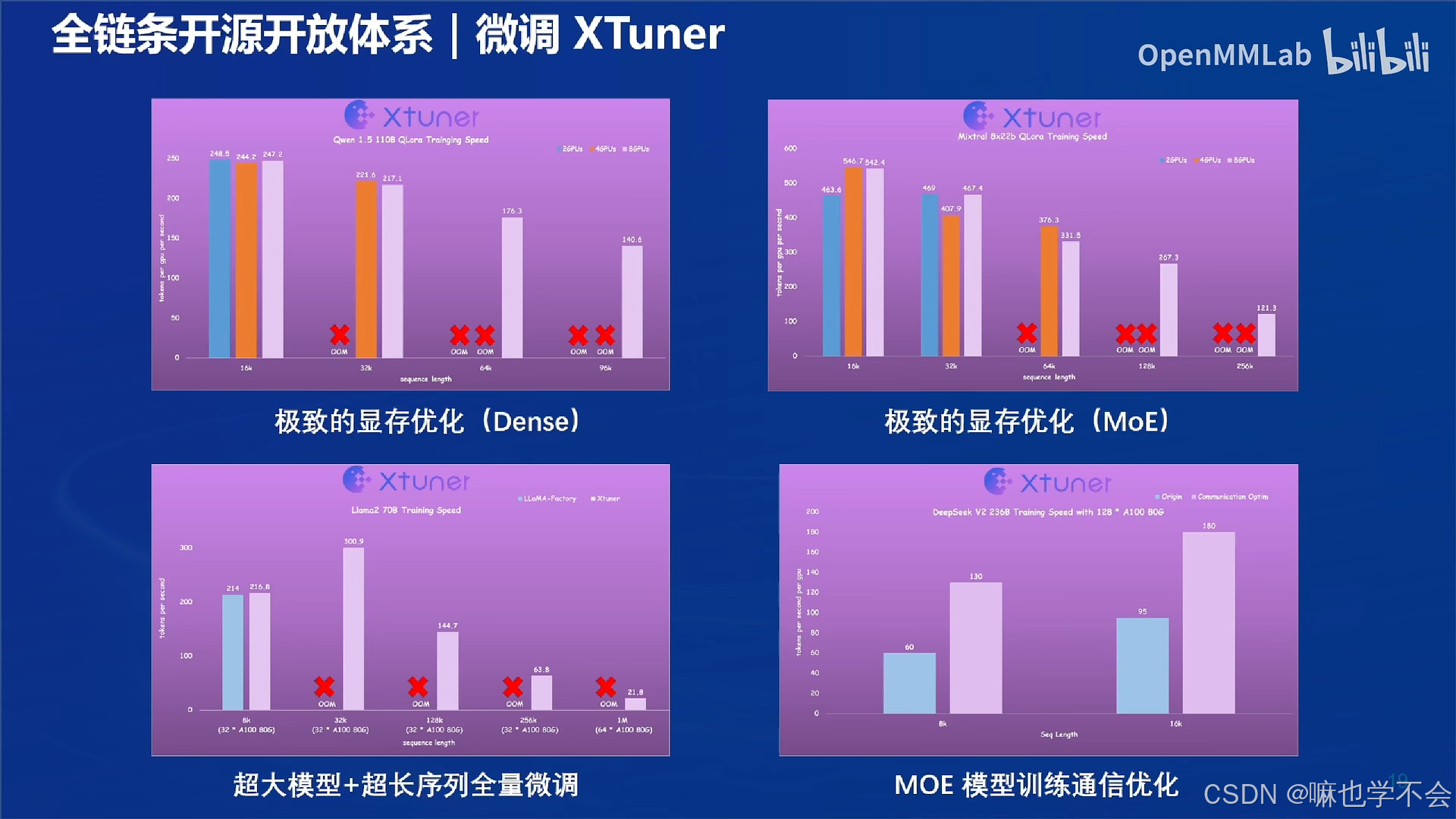
XTuner 提供丰富的功能模块,包括数据预处理、参数高效冻结与调整、任务特定优化(如 LoRA 和 QLoRA),以及可扩展的评估工具,覆盖从数据到模型全链条的微调流程。其简洁的接口和强大的性能,使其适用于研究实验、企业应用以及大规模生产环境中的大模型定制任务,是开发者提升工作效率与模型性能的理想选择。
便捷的服务:LMDeploy
LMDeploy 是由 MMDeploy 和 MMRazor 团队联合开发的一体化解决方案,专注于大语言模型(LLM)的轻量化、部署与服务。它通过高效推理、可靠量化、便捷服务和卓越兼容性,显著提升了 LLM 的性能和易用性:
1.高效推理:
- 实现了 Persistent Batch(连续批次处理)、Blocked K/V Cache、动态拆分与融合、张量并行等技术,推理性能达到 vLLM 的 1.8 倍。
2.可靠量化:
- 支持权重量化和 K/V 量化,4bit 模型推理效率是 FP16 模型的 2.4 倍,且量化模型的性能通过 OpenCompass 评测验证。
3.便捷服务:
- 提供请求分发功能,支持多模型在多机多卡环境下的推理服务。
4.有状态推理:
- 借助 K/V 缓存技术,在多轮对话中记忆历史上下文,避免重复计算,大幅提升长文本和多轮对话的效率。
5.卓越兼容性:
- 支持 K/V Cache 量化、AWQ(自动权重量化)以及自动前缀缓存功能的组合使用,适配多种场景。
公平的评估:OpenCompass
OpenCompass 是一款功能强大的评估平台,能够帮助社区更加便捷地对 NLP 模型的性能进行公平且全面的评估。它集成了丰富的基准数据集和标准化评测指标,覆盖多种 NLP 任务,包括文本分类、阅读理解、语言生成、翻译和问答等,确保评估结果的权威性和可比性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









