









 本文整理了MySQL面试中常见的问题,包括基本概念(如char和varchar、索引的使用和优缺点)、数据库主键和外键、各种SQL聚合函数、内连接、左连接和右连接,以及数据库设计原则。此外,还探讨了索引的类型和数据结构,如B+树和Hash索引的区别。最后,提到了数据库事务和存储引擎的相关知识。
本文整理了MySQL面试中常见的问题,包括基本概念(如char和varchar、索引的使用和优缺点)、数据库主键和外键、各种SQL聚合函数、内连接、左连接和右连接,以及数据库设计原则。此外,还探讨了索引的类型和数据结构,如B+树和Hash索引的区别。最后,提到了数据库事务和存储引擎的相关知识。
Java初级面试题整理
目录
mysql部分
基本概念
char和varchar
区别
-
char 是一种固定长度的字符串类型,
-
varchar 是一种可变长度的字符串类型;
适用场景:
-
char一般用来存储长度固定字段,如:手机号,身份证号等
-
varchar一般用来存储不固定长度的字段:如:用户名,昵称等
drop、delete与truncate
相同点:
-
truncate和不带where子句的delete、以及drop都会删除表内的数据。
区别:
-
drop、truncate都是DDL语句(数据库定义语言),执行后会自动提交,操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。
-
delete 是DML语句(数据库操作语言),这个操作会放到rollback segement 中,事务提交之后才生效;支持事务回滚,如果有相应的 trigger,执行的时候将被触发。
-
delete不重置自动增长列的计数值
-
truncate重置自动增长列的计数值
删除速度/效率:
一般来说删除效率: drop> truncate> delete
-
truncate在功能上与不带 where子句的 delete语句相同:二者均删除表中的全部行。但truncate比 delete速度快,且使用的系统和事务日志资源少。
-
delete语句每次删除一行,并在事务日志中为所删除的每行 记录一项。
-
truncate通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
-
truncate删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。
使用范围:
delete:想删除部分数据行用 delete,注意应带上where条件子句. 回滚段要足够大;
drop:想删除整个表,当然用 drop;
truncate:想保留表字段、索引等而将所有数据删除,如果和事务无关,用truncate即可。如果和事务有关,或者想触发trigger,还是用delete。如果是整理表内部的碎片,可以用truncate跟上reuse stroage,再重新导入/插入数据。
不能对以下表使用 TRUNCATE TABLE:
-
对于有foreign key约束引用的表,不能使用truncate,而应使用不带 where子句的 delete语句。(您可以截断具有引用自身的外键的表。)
-
TRUNCATE TABLE 不能激活触发器,因为该操作不记录各个行删除。
-
TRUNCATE TABLE 不能用于参与了索引视图的表。
关于数据库主键和外键
主键:
-
唯一标识一条记录的字段或字段的组合称为主键。
-
主键不能重复,不允许为空
-
作用:定义主键来强制不允许空值的指定列中输入值的唯一性。任何表都应该有且仅有唯一的主键,在数据库中为表定义主键,可将该表与其它表相关联,从而减少冗余数据。
外键:
-
通过设置外键和其他表建立关联关系(一对一,一对多,多对多),用来维护表之间数据一致性
-
外键是关联从表的主键,可以重复, 允许为空值
-
作用:FOREIGN KEY 约束并不仅仅只可以与另一表的 PRIMARY KEY 约束相链接,它还可以定义为引用另一表的 UNIQUE 约束。FOREIGN KEY 约束不允许空值,但是,如果任何组合 FOREIGN KEY 约束的列包含空值,则将跳过 FOREIGN KEY 约束的校验。
mysql支持的约束
六种约束:
-
NOT NULL:非空约束,用于保证该字段的值不能为空;比如姓名、学号等
-
DEFAULT:默认约束,用于保证该字段有默认值;比如性别
-
PRIMARY KEY:主键约束,用于保证该字段的值具有唯一性,并且非空;比如学号、员工编号等
-
UNIQUE:唯一约束,用于保证该字段的值具有唯一性,可以为空;比如座位号
-
CHECK:检查约束【mysql中不支持】;比如年龄、性别
-
FOREIGN KEY:外键约束,用于限制两个表的关系,用于保证该字段的值必须来自于主表的关联列的值,在从表添加外键约束,用于引用主表中某列的值;比如学生表的专业编号,员工表的部门编号,员工表的工种编号
添加约束的时机:
-
创建表时
-
修改表时
约束的添加分类:
-
列级约束:六大约束语法上都支持,但外键约束没有效果
-
表级约束:除了非空、默认,其他的都支持
了解更多请点击:约束的使用
5种SQL常用聚合函数
常用的聚合函数有:COUNT(),SUM(),AVG(),MIN(),MAX()。
-
COUNT( ),其作用主要是返回每个组的行数,也会返回有NULL值的列,可用于数字和字符列。
-
SUM( ),主要用于返回表达式中所有的总和,忽略NULL值,仅用于数字列。
-
AVG( ),返回表达式所有的平均值,仅用于数字列并且自动忽略NULL值。
-
MIN( ),返回表达式中的最小值,忽略NULL值,可用于数字、字符和日期时间列。
-
MAX( ),返回表达式中的最大值,忽略NULL值,可用于数字、字符和日期时间列。
-
聚合函数不能在where条件语句之后直接使用
了解更多请点击: MySQL中常用的聚合函数
-
SQL中内连接、左连接、右连接
内连接 (inner )join:是从结果表中删除与其他被连接表中没有匹配行的所有行
左(外)连接 left (outer) join:以左表作为基准进行查询,左表数据都显示,连接条件成立右表数据显示,条件不成立显示null
右(外)连接 right (outer) join:以右表作为基准进行查询,右表数据都显示,连接条件成立左表数据显示,条件不成立显示null
了解更多请点击:sql左连接、右连接和内连接
数据库设计
三大范式
第一范式(1NF):字段(或属性)是不可分割的最小单元,即不会有重复的列,体现原子性
第二范式(2NF):在满足第一范式前提下,存在一个候选码,非主属性全部依赖该候选码,即存在主键,体现唯一性,专业术语则是消除部分函数依赖
第三范式(3NF):满足 第二范式前提下,非主属性必须互不依赖,消除传递依赖
除了三大范式外,还有BC范式和第四范式,但其规范过于严苛,在生产中往往使用不到。 范式是符合某一种级别的关系模式的集合。构造数据库必须遵循一定的规则。在关系数据库中,这种规则就是范式。
范式:范式化的表减少了数据冗余,数据表更新操作快、占用存储空间少。 缺点:查询时通常需要多表关联查询,更难进行索引优化
反范式:反范式的过程就是通过冗余数据来提高查询性能,可以减少表关联和更好进行索引优化 缺点:存在大量冗余数据,并且数据的维护成本更高
所以在平时工作中,我们通常是将范式和反范式相互结合使用。
索引
索引就像指向表行的指针,是一种允许查询操作快速确定哪些行符合WHERE子句中的条件,并检索到这些行的其他列值的数据结构;
索引主要有普通索引、唯一索引、主键索引、外键索引、全文索引、复合索引几种;
在大数据量的查询中,合理使用索引的优点非常明显,不仅能大幅提高匹配where条件的检索效率,还能用于排序和分组操作的加速。 但是索引如果使用不当也有比较大的坏处:比如索引必定会增加存储资源的消耗;同时也增大了插入、更新和删除操作的维护成本,因为每个增删改操作后相应列的索引都必须被更新。
加分回答 只要创建了索引,就一定会走索引吗?
不一定。 比如,在使用组合索引的时候,如果没有遵从“最左前缀”的原则进行搜索,则索引是不起作用的。 举例,假设在id、name、age字段上已经成功建立了一个名为MultiIdx的组合索引。索引行中按id、name、age的顺序存放,索引可以搜索id、(id,name)、(id, name, age)字段组合。如果列不构成索引最左面的前缀,那么MySQL不能使用局部索引,如(age)或者(name,age)组合则不能使用该索引查询。
1、索引的几种类型或分类?
1)从物理结构上可以分为聚集索引和非聚集索引两类:
-
聚簇索引的索引键值的逻辑顺序与表中相应行物理顺序一致,即每张表只能有一个聚簇索引,也就是我们常说的主键索引;
-
非聚簇索引的逻辑顺序则与数据行的物理顺序不一致。
2)从应用上可以划分为一下几类:
普通索引:MySQL 中的基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了提高查询效率。通过 ALTER TABLE table_name ADD INDEX index_name (column) 创建;
唯一索引:索引列中的值必须是唯一的,但是允许为空值。通过 ALTER TABLE table_name ADD UNIQUE index_name (column) 创建;
主键索引:特殊的唯一索引,也成聚簇索引,不允许有空值,并由数据库帮我们自动创建;
组合索引:组合表中多个字段创建的索引,遵守最左前缀匹配规则;
全文索引:只有在 MyISAM 引擎上才能使用,同时只支持 CHAR、VARCHAR、TEXT 类型字段上使用。
2、索引的优缺点?
先来说说优点:创建索引可以大大提高系统的性能。
通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
缺点:
创建和维护索引需要耗费时间,这种时间随着数据量的增加而增加,这样就降低了数据的维护速度。
索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间。如果要建立聚簇索引,那么需要的空间就会更大。
3、索引设计原则?
-
选择唯一性索引:唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。
-
为常作为查询条件的字段建立索引:如果某个字段经常用来做查询条件,那么该字段的查询速度会影响整个表的查询速度。因此,为这样的字段建立索引,可以提高整个表的查询速度。
-
为经常需要排序、分组和联合操作的字段建立索引:经常需要 ORDER BY、GROUP BY、DISTINCT 和 UNION 等操作的字段,排序操作会浪费很多时间。如果为其建立索引,可以有效地避免排序操作。
-
限制索引的数目:每个索引都需要占⽤用磁盘空间,索引越多,需要的磁盘空间就越大,修改表时,对索引的重构和更新很麻烦。
-
小表不建议索引(如数量级在百万以内):由于数据较小,查询花费的时间可能比遍历索引的时间还要短,索引可能不会产生优化效果。
-
尽量使用数据量少的索引:如果索引的值很长,那么查询的速度会受到影响。此时尽量使用前缀索引。
-
删除不再使用或者很少使用的索引。
4、索引的数据结构?
索引的数据结构和具体存储引擎的实现有关,MySQL 中常用的是 Hash 和 B+ 树索引。
Hash 索引底层就是 Hash 表,进行查询时调用 Hash 函数获取到相应的键值(对应地址),然后回表查询获得实际数据.
B+ 树索引底层实现原理是多路平衡查找树,对于每一次的查询都是从根节点出发,查询到叶子节点方可以获得所查键值,最后查询判断是否需要回表查询.
5、Hash 和 B+ 树索引的区别?
Hash:
-
Hash 进行等值查询更快,但无法进行范围查询。因为经过 Hash 函数建立索引之后,索引的顺序与原顺序无法保持一致,故不能支持范围查询。同理,也不支持使用索引进行排序。
-
Hash 不支持模糊查询以及多列组合(复合)索引的最左前缀匹配,因为 Hash 函数的值不可预测,如 AA 和 AB 的算出的值没有相关性。
-
Hash 任何时候都避免不了回表查询数据.
-
虽然在等值上查询效率高,但性能不稳定,因为当某个键值存在大量重复时,产生 Hash 碰撞,此时查询效率反而可能降低。
B+ Tree:
-
B+ 树本质是一棵查找树,自然支持范围查询和排序。
-
在符合某些条件(聚簇索引、覆盖索引等)时候可以只通过索引完成查询,不需要回表。
-
查询效率比较稳定,因为每次查询都是从根节点到叶子节点,且为树的高度。
6、为何使用 B+ 树而非二叉查找树做索引?
我们知道二叉树的查找效率为 O(logn),当树过高时,查找效率会下降。另外由于我们的索引文件并不小,所以是存储在磁盘上的。
文件系统需要从磁盘读取数据时,一般以页为单位进行读取,假设一个页内的数据过少,那么操作系统就需要读取更多的页,涉及磁盘随机 I/O 访问的次数就更多。将数据从磁盘读入内存涉及随机 I/O 的访问,是数据库里面成本最高的操作之一。
因而这种树高会随数据量增多急剧增加,每次更新数据又需要通过左旋和右旋维护平衡的二叉树,不太适合用于存储在磁盘上的索引文件。
7、为何使用 B+ 树而非 B 树做索引?
在此之前,先来了解一下 B+ 树和 B 树的区别:
B 树非叶子结点和叶子结点都存储数据,因此查询数据时,时间复杂度最好为 O(1),最坏为 O(log n)。而 B+ 树只在叶子结点存储数据,非叶子结点存储关键字,且不同非叶子结点的关键字可能重复,因此查询数据时,时间复杂度固定为 O(log n)。
B+ 树叶子结点之间用链表相互连接,因而只需扫描叶子结点的链表就可以完成一次遍历操作,B 树只能通过中序遍历。
为什么 B+ 树比 B 树更适合应用于数据库索引?
B+ 树减少了 IO 次数。 由于索引文件很大因此索引文件存储在磁盘上,B+ 树的非叶子结点只存关键字不存数据,因而单个页可以存储更多的关键字,即一次性读入内存的需要查找的关键字也就越多,磁盘的随机 I/O 读取次数相对就减少了。
B+ 树查询效率更稳定 由于数据只存在在叶子结点上,所以查找效率固定为 O(log n),所以 B+ 树的查询效率相比B树更加稳定。
8、什么是最左匹配原则?
顾名思义,最左优先,以最左边为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
如建立 (a,b,c,d) 索引,查询条件 b = 2 是匹配不到索引的,但是如果查询条件是 a = 1 and b = 2 或 a=1 又或 b = 2 and a = 1 就可以,因为优化器会自动调整 a,b 的顺序。
再比如 a = 1 and b = 2 and c > 3 and d = 4,其中 d 是用不到索引的,因为 c 是一个范围查询,它之后的字段会停止匹配。
最左匹配的原理
上图可以看出 a 是有顺序的(1、1、2、2、3、3),而 b 的值是没有顺序的(1、2、1、4、1、2)。所以 b = 2 这种查询条件无法利用索引。
同时我们还可以发现在 a 值相等的情况下(a = 1),b 又是顺序排列的,所以最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。
9、什么是覆盖索引?
在 B+ 树的索引中,叶子节点可能存储了当前的键值,也可能存储了当前的键值以及整行的数据,这就是聚簇索引和非聚簇索引。 在 InnoDB 中,只有主键索引是聚簇索引,如果没有主键,则挑选一个唯一键建立聚簇索引。如果没有唯一键,则隐式的生成一个键来建立聚簇索引。
当查询使用聚簇索引时,在对应的叶子节点,可以获取到整行数据,因此不用再次进行回表查询。
10、什么是索引下推?
索引下推(Index condition pushdown) 简称 ICP,在 Mysql 5.6 版本上推出的一项用于优化查询的技术。
在不使用索引下推的情况下,在使用非主键索引进行查询时,存储引擎通过索引检索到数据,然后返回给 MySQL 服务器,服务器判断数据是否符合条件。
而有了索引下推之后,如果存在某些被索引列的判断条件时,MySQL 服务器将这一部分判断条件传递给存储引擎,然后由存储引擎通过判断索引是否符合 MySQL 服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给 MySQL 服务器。
索引条件下推优化可以减少存储引擎查询基础表的次数,也可以减少 MySQL 服务器从存储引擎接收数据的次数。
(索引下推在非主键索引上的优化,可以有效减少回表的次数,大大提升了查询的效率。)
Mysql性能优化:什么是索引下推? - 知乎 (zhihu.com)
———————————————— 版权声明:本文为优快云博主「程序猿周周」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:MySQL数据库面试题总结(2022最新版)_程序猿周周的博客-优快云博客_mysql数据库面试题
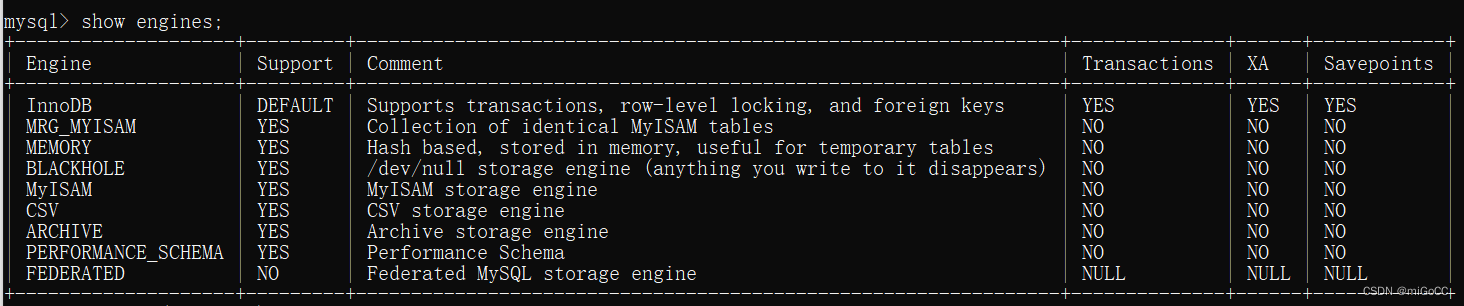
存储
查看数据库存储引擎命令:
mysql> SHOW ENGINES;
事务
数据库事务
事务:业务中的一组操作,要么全部成功,要么全部失败,是不可分割的工作单位。
java
基本概念
1.1 8大基本数据类型
1、Java 有哪些基本数据类型?
2、Java 有哪些数据类型?
3、类型有哪些转换方式?
4、什么是自动拆装箱?
5、什么是基本数据类型的缓冲池?
6、布尔类型占多少字节?
类
1、抽象类和接口的区别?
2、什么是内部类?
3、内部类有哪些优点?
4、Java 有哪四种引用类型?
5、类初始化顺序?
1.3 修饰符
1、Java 中常见的修饰符?
2、谈谈 final 关键字?
1.4 语法
1、Java 中有哪些取整方法?
2、Switch 支持哪些数据类型?
3、Switch 支持 String 的原理?
面向对象
1、面向对象的三大特性?
2、Java 是如何实现多态的?
3、重写和重载的区别?
4、什么是向前引用?
常用类库
3.1 基本包
1、java 和 javax 类库的区别?
3.2 Object
1、Object 有哪些公共方法?
2、equals 和 == 的区别?
3、equals 和 hashcode 的联系?
4、深拷贝和浅拷贝的区别?
3.3 String
1、String s=new String("x") 创建了几个对象?
2、说说 String 的 intern() 方法?
3、String、StringBuffer 和 StringBuilder 区别?
泛型
多线程
IO流
反射
未完待续。。。


















 1834
1834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









