







 本文详细介绍了Java 8的Stream API,包括其操作周期、使用方法如排序、过滤、映射、计数、去重等,并通过实例展示了如何在实际编程中运用,如Lambda表达式的使用,以及串行流与并行流的选择与性能比较。
本文详细介绍了Java 8的Stream API,包括其操作周期、使用方法如排序、过滤、映射、计数、去重等,并通过实例展示了如何在实际编程中运用,如Lambda表达式的使用,以及串行流与并行流的选择与性能比较。
stream
什么是Stream流
Stream 是JDK1.8 中处理集合的关键抽象概念,Lambda 和 Stream 是JDK1.8新增的函数式编程最有亮点的特性了,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。使用Stream API 对集合数据进行操作,就类似于使用SQL执行的数据库查询。Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。
Stream :非常方便精简的形式遍历集合,实现过滤、排序等。
Stream的操作周期
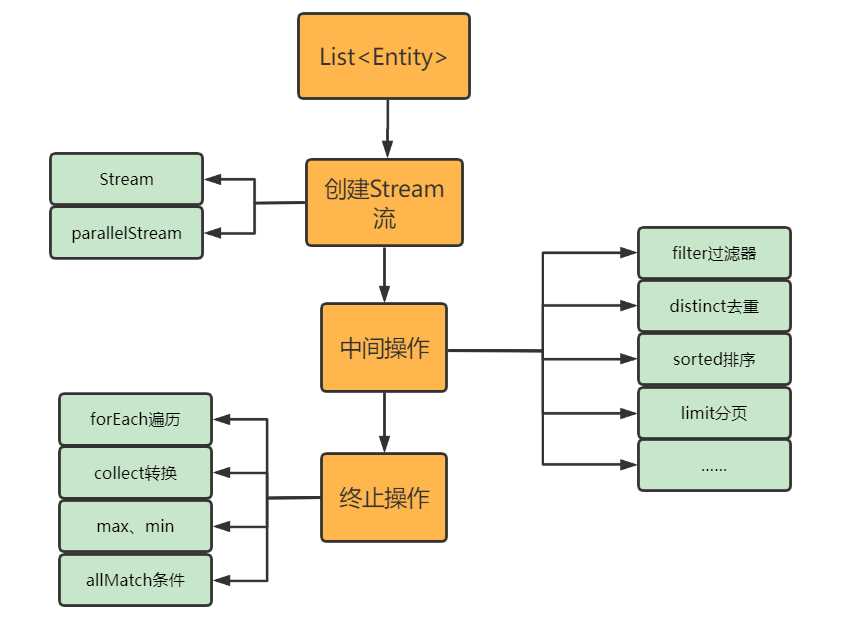
我把Stream的使用周期分为这4步:
首先,Stream是对集合进行操作的,因此要先有集合对象,通过集合对象的stream()或parallelStream()将集合转为流,然后可以对流进行处理,也就是中间操作,最终使用流并关闭流;在这个过程中,有时不需要中间操作。
先举个例子感受一下流的使用过程。
//创建一个集合对象
List<Integer> numbers = Arrays.asList(1, 45, 23, 66, 23);
//创建stream流,返回结果生成新的流,流中只包含满足筛选条件的数据
Stream<Integer> stream = numbers.stream();
//collect(Collectors.xx):把流收集起来,转换为List集合。
List<Integer> filteredNumbers = stream.filter(e -> e > 10).collect(Collectors.toList());
System.out.println(filteredNumbers); //[45, 23, 66, 23]
流的使用
我们在实用过程中更多的是使用lambda的形式,文中提供了匿名内部类的完整代码是为了让很少接触lambda的人更好地理解代码。
要注意,每个流只能使用一次。流在进行最终操作后就关闭了,不可再使用。
准备实体类代码
/**
* @Author: Forward Seen
* @CreateTime: 2022/06/14 20:19
* @Description: 实体类Book
* 构造函数
* 重写equals()和hashCode()、toString()
*/
public class Book {
private String name;
private double price;
public Book(String name, double price) {
this.name = name;
this.price = price;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Book book = (Book) o;
return Double.compare(book.price, price) == 0 &&
Objects.equals(name, book.name);
}
@Override
public int hashCode() {
return Objects.hash(name, price);
}
}
/**
* @Author: Forward Seen
* @CreateTime: 2022/06/14 20:26
* @Description: Student 实体类
* 添加构造函数
* 添加getter、setter方法
* 重写hashCode()和equals()、toString()
* 实现Comparable接口
*/
public class Student implements Comparable<Student> {
private int id;
private String name;
private int age;
public Student(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public int getId() {
return id;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public int compareTo(Student o) {
return this.name.compareTo(o.getName());
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Student student = (Student) o;
return id == student.id &&
age == student.age &&
Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name);
}
}
sorted排序
stream的sorted排序操作
- 创建集合用例
List<Integer> list = Arrays.asList(3, 4, 6, 2, 45, 32, 565, 34, 5, 2);
- 默认升序排序
list.stream().sorted().forEach(e -> System.out.print(e + " "));

- stream的降序排序
Comparator.reverseOrder()能够逆序一个已经排序的流
list.stream().sorted(Comparator.reverseOrder()).forEach(e -> System.out.print(e + " "));

自定义的排序(创建一个学生类Student,实现Comparable接口,重写equals和hashcode方法)
- 创建集合用例
ArrayList<Student> students = new ArrayList<>();
students.add(new Student(1, "Bob", 12));
students.add(new Student(2, "Linda", 22));
students.add(new Student(3, "Black", 8));
- 根据名称自然排序,这个根据什么排序取决于equals和hashCode方法
students.stream().sorted().forEach(System.out::println);

- 根据名称反转自然排序
students.stream().sorted(Comparator.reverseOrder()).forEach(System.out::println);

返回对象以类属性排序
- 按照年龄大小升序排序(匿名内部类)
students.stream().sorted(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
//如果你想要降序,只需要将o1,o2的位置换一下
return o1.getAge()-o2.getAge();
}
}).forEach(new Consumer<Student>() {
@Override
public void accept(Student student) {
System.out.println(student);
}
});

- 改用lambda表达式
students.stream().sorted((o1, o2) -> o1.getAge()-o2.getAge()).forEach(student -> System.out.println(student));
- 还可以使用比较器
students.stream().sorted(Comparator.comparing(student -> student.getAge())).forEach(student -> System.out.println(student));
//还可以简写
students.stream().sorted(Comparator.comparing(Student::getAge)).forEach(System.out::println);
- 使用比较器对年龄属性先升序、结果再降序
students.stream().sorted(Comparator.comparing(Student::getAge).reversed()).forEach(System.out::println);
max、min
-
Optional
Optional 类是⼀个可以为null的容器对象,它也是Java8的新特性之一。如果值存在则isPresent()方法会返回true,调⽤get()方法会返回该对象。
Optional 是个容器:它可以保存类型T的值,或者仅仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测。
Optional 类的引入很好的解决空指针异常。 -
max可以按条件返回流中最大的元素并以Optional容器存储
ArrayList<Student> list = new ArrayList<>();
list.add(new Student(1, "Bob", 12));
list.add(new Student(2, "Linda", 22));
list.add(new Student(3, "Black", 8));
Optional<Student> maxAgeStudent = list.stream().max(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getAge() - o2.getAge();
}
});
Student student = maxAgeStudent.get();
System.out.println(student); //Student{id=2, name='Linda', age=22}
- 使用lambda表达式
Optional<Student> maxAgeStudent = list.stream().max((o1, o2) -> o1.getAge() - o2.getAge());
- 还可以简写
Optional<Student> maxAgeStudent = list.stream().max(Comparator.comparingInt(Student::getAge));
- min的用法与max一样,它是返回最小的元素的Optional
filter过滤
- stream的filter过滤操作
Stream<String> stream = Stream.of("小明", "小红", "小王", "小李", "红红", "花花");
stream.filter(name -> {
//只保留以“小”开头的元素,返回的是boolean类型,若元素为true则保留
return name.startsWith("小");
}).forEach(name -> {
System.out.print(name + " ");
});

- 过滤对象
ArrayList<Book> books = new ArrayList<>();
books.add(new Book("Java面向对象程序设计", 40.00));
books.add(new Book("Java核心技术I", 89.00));
books.add(new Book("Java核心技术II", 89.00));
books.add(new Book("数据结构与算法(Java语言描述)", 120.00));
books.add(new Book("MySQL实战", 100.00));
books.add(new Book("深入理解Java虚拟机", 110.00));
books.add(new Book("操作系统", 56.00));
books.stream().filter(new Predicate<Book>() {
@Override
public boolean test(Book book) {
return book.getName().contains("Java") && book.getPrice() <= 100;
}
}).forEach(new Consumer<Book>() {
@Override
public void accept(Book book) {
System.out.println(book);
}
});

- 使用lambda简写
books.stream().filter(book -> book.getName().contains("Java") && book.getPrice() <= 100)
.forEach(book -> System.out.println(book));
count统计
count可以返回流中元素的个数
long number = books.stream().count();
System.out.println(number);
distinct去重
distinct可以对流中的元素进行去重,去重的原理依赖的是元素的hashCode()和equals()。
- String、包装类这些类型的都已经重写过hashCode()和equals()
List<String> list = Arrays.asList("AA", "BB", "CC", "BB", "AA", "CC");
//Collectors.joining("xx"):可以指定字符串连接时的分隔符,前缀和后缀字符串,来连接stream流中的元素
String collect = list.stream().distinct().collect(Collectors.joining(","));
System.out.println(collect);

- distinct对自定义对象去重
需要实现hashcode()和equals()方法,这里使用图书类Book
ArrayList<Book> books = new ArrayList<>();
books.add(new Book("Java Core Technology", 199.0));
books.add(new Book("Java Core Technology", 199.0));
books.add(new Book("Thinking in java", 250.0));
books.add(new Book("Thinking in java", 250.0));
books.add(new Book("Java Core Technology 2", 199.0));
books.stream().distinct().forEach(book -> System.out.println(book));

limit&skip
- limit可以对流中元素进行截取,参数为截取的个数,超过这个范围会过滤掉
Stream<String> stream = Stream.of("小明", "小红", "小王", "小李", "红红", "花花");
stream.limit(3).forEach(name -> System.out.print(name + " "));

- skip可以跳过元素,使用skip方法跳过前4个元素
stream.skip(4).forEach(name -> System.out.print(name + " "));

- limit和skip可以一起用,但是skip在前面
你可以将这个组合理解为“掐头去尾”
stream.skip(2).limit(3).forEach(name -> System.out.print(name + " "));

reduce计算
ArrayList<Student> students = new ArrayList<>();
students.add(new Student(1, "小明", 18));
students.add(new Student(2, "小李", 19));
students.add(new Student(3, "小王", 18));
students.add(new Student(4, "小红", 19));
students.add(new Student(5, "小刘", 20));
Optional<Student> sum = students.stream().reduce(new BinaryOperator<Student>() {
@Override
public Student apply(Student student, Student student2) {
return new Student(0, "sum", student.getAge() + student2.getAge());
}
});
System.out.println(sum); //Optional[Student{id=0, name='sum', age=94}]
改用lambda表达式
Optional<Student> sum = students.stream()
.reduce((student, student2) -> new Student(0, "sum", student.getAge() + student2.getAge()));
map映射处理
映射(map)
映射可以将一个流的元素按照一定的映射规则映射到另一个流中。
它接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
每个元素都会被映射过去,映射的新元素和被映射的元素形成一一对应的关系。
- 通过map返回一组对象中的某个属性
ArrayList<Book> books = new ArrayList<>();
books.add(new Book("Java面向对象程序设计", 40.00));
books.add(new Book("Java核心技术I", 89.00));
books.add(new Book("Java核心技术II", 89.00));
books.add(new Book("数据结构与算法(Java语言描述)", 120.00));
books.add(new Book("深入理解Java虚拟机", 110.00));
books.stream().map(new Function<Book, String>() {
@Override
public String apply(Book book) {
String name = book.getName();
return name;
}
}).forEach(bookName -> System.out.print(bookName + " "));
- 改用lambda表达式
books.stream().map(book -> book.getName()).forEach(bookName -> System.out.print(bookName + " "));
- mapToInt()
接收一个函数作为参数,该函数会被应用到每个元素上并将其映射成一个新的元素,返回新的流,这个流是数值流,是IntStream类型。
这种流的元素都是原始数据类型,比如:int double long
在这个例子中,是将每一个元素用Integer.parseInt(num)方法转成数值,这时就是一个新的流,IntStream,然后这里加了个过滤操作,过滤条件是能被3整除的筛选出来。
List<String> list = Arrays.asList("3", "6", "8", "14", "15");
IntStream intStream = list.stream().mapToInt(num -> Integer.parseInt(num)).filter(num -> num % 3 == 0);
intStream.forEach(System.out::println); //3 6 15
match查询式比较
准备一个对象集合
ArrayList<Student> students = new ArrayList<>();
students.add(new Student(1, "Bob", 12));
students.add(new Student(2, "Linda", 22));
students.add(new Student(3, "Black", 8));
- anyMatch
anyMatch每一个对象都比较,只要有一个符合 test方法的条件,就返回true,否则false
例:查看是否存在name为“Linda”的学生
boolean isExist = students.stream().anyMatch(new Predicate<Student>() {
@Override
public boolean test(Student student) {
return "Linda".equals(student.getName());
}
});
System.out.println(isExist); // true
- 改用lambda表达式
boolean isExist = students.stream().anyMatch(student -> "Linda".equals(student.getName()));
- allMatch
allMatch每一个对象都比较,必须所有都符合test方法的条件,才返回true,否则false
boolean isExist = students.stream().allMatch(student -> student.getAge() < 35);// true
collect收集
collect:收集
它可以说是内容最繁多、功能最丰富的部分了。从字面上去理解,就是把一个流收集起来,最终可以收集成一个值,也可以收集成一个新的集合。
collect主要依赖java.util.stream.Collectors类内置的静态方法
归集(toList/toSet/toMap)
因为流不存储数据,那么在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。
toList、toSet、toMap比较常用,另外还有toCollection、toConcurrentMap等复杂一些的用法
- 准备一个List案例
ArrayList<Book> books = new ArrayList<>();
books.add(new Book("Java",35.00));
books.add(new Book("JavaWeb",40.00));
books.add(new Book("SQL",30.00));
books.add(new Book("Java",35.00));
books.add(new Book("数据结构",35.00));
books.add(new Book("Java",35.00));
- collect将流收集成List集合
List<Book> collectedBooks = books.stream().limit(4).collect(Collectors.toList());

- list集合转换成set集合(需要重写hashCode和equals方法)
Set<Book> bookSet = books.stream().collect(Collectors.toSet());
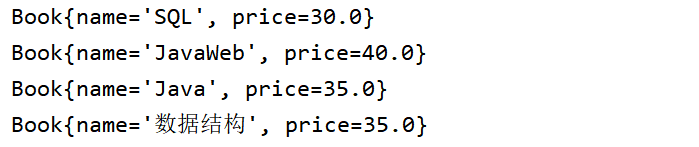
- list集合转成map
要注意,Map的key是唯一的,因此我这里拿name作为key的话需要先去重。
Map<String, Book> bookMap =
books.stream().distinct().collect(Collectors.toMap(new Function<Book, String>() {
@Override
public String apply(Book book) {
// 以name为key
return book.getName();
}
}, new Function<Book, Book>() {
@Override
public Book apply(Book book) {
// book为value
return book;
}
}));
bookMap.forEach(new BiConsumer<String, Book>() {
@Override
public void accept(String s, Book book) {
System.out.println(s + ":" + book);
}
});

- 改用lambda表达式
Map<String, Book> bookMap =
books.stream().distinct().collect(Collectors.toMap(book -> book.getName(), book -> book));
bookMap.forEach((k, v) -> {
System.out.println(k + ":" + v);
});
range
range()表示生成数值的范围,可以用于IntStream(Int类型的流)和LongStream的静态方法
第一个参数为起始值,第二个参数为结束值,结果不包括结束值。
collect()就是把流收集起来,最终可以收集成一个值,也可以收集成一个新的集合
IntStream intStream = IntStream.range(1, 100).skip(85);
Stream<Integer> stream = intStream.boxed();
List<Integer> collect = stream.collect(Collectors.toList());
System.out.println("collect=" + collect);
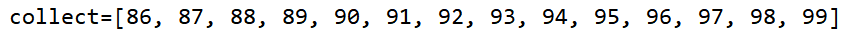
串行流与并行流
stream和parallelStream的简单区分:stream是顺序流,由主线程按顺序对流进行操作,而parallelStream是并行流,内部以多线程并行执行的方式对流进行操作,但前提是流中的数据处理没有顺序要求。
例如筛选集合中的奇数,两者的处理不同:
- 顺序流是流中所有一起筛选,直接拿到结果流;
- 而并行流是多个线程各自筛选各自部分的数据,最后将各个结果流合并,得到最终的结果流,
- 因为合并没有顺序,所以不能保证顺序一样。
- 如果流中的数量足够大,并行流可以加快速度。
- 除了直接创建并行流,还可以通过parallel()把顺序流转换成并行流。
流的创建
串行流的两种获取方式
- 集合转stream
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> stream = list.stream();
- Stream.of(Object…)
Stream<Integer> stream1 = Stream.of(6, 7, 8, 9, 0);
并行流的两种获取方式
- 集合转parallelStream
List<String> list1 = Arrays.asList("hello", "world", "java");
Stream<String> stream2 = list1.parallelStream();
- 串行流的parallel方法转并行流
Stream<Integer> stream3 = stream.parallel();
串行流与并行流的性能
//初始化一千万条数据
System.out.println("初始化测试数据。。。");
//iterate()方法:也可以获取流 无限流
List<UUID> data = Stream.iterate(UUID.randomUUID(),
t -> UUID.randomUUID()).limit(10000000).collect(Collectors.toList());
//开始测试串行流
long time1 = System.nanoTime();
data.stream().sorted().count();
long time2 = System.nanoTime();
//开始测试并行流
data.parallelStream().sorted().count();
long time3 = System.nanoTime();
System.out.println("测试完成,计算结果。。。");
//BiFunction是用来接收两个参数并返回结果的函数
//apply:将参数应用于执行
BiFunction<Long, Long, Long> workMillionTime = (start, end) -> TimeUnit.NANOSECONDS.toMillis(end - start);
long streamTime = workMillionTime.apply(time1, time2);
long parallelStreamTime = workMillionTime.apply(time2, time3);
System.out.println(String.format("串行流耗时:%d \n并行流耗时:%d", streamTime, parallelStreamTime));

stream的综合案例
List<Student> students = new ArrayList<>();
students.add(new Student(1,"小小怪",15));
students.add(new Student(2,"大大怪",25));
students.add(new Student(3,"小小怪",20));
students.add(new Student(4,"大大怪",31));
students.add(new Student(5,"小小怪",15));
students.add(new Student(6,"大大怪",40));
students.add(new Student(7,"大大怪",33));
students.add(new Student(8,"大大怪",20));
//...
//还有很多数据
- 对数据流的数据实现升序排列、且名称为 小小怪 ,获取前两位
students.stream()
.filter(e -> "小小怪".equals(e.getName()))
.sorted()
.limit(2)
.forEach(e -> System.out.println(e));
- 对数据流的数据实现按照年龄降序排列、且名称为 大大怪,获取后两位
students.stream()
.filter(e -> "大大怪".equals(e.getName()))
.sorted((o1, o2) -> o2.getAge() - o1.getAge())
.skip(2).limit(2)
.forEach(e -> System.out.println(e));


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









