






一、首先使用科大讯飞平台注册账号选择相应功能进行领取或购买

二、本文运用了语音转写和语音听写功能申请后获得讯飞开放平台提供的 apiKey。
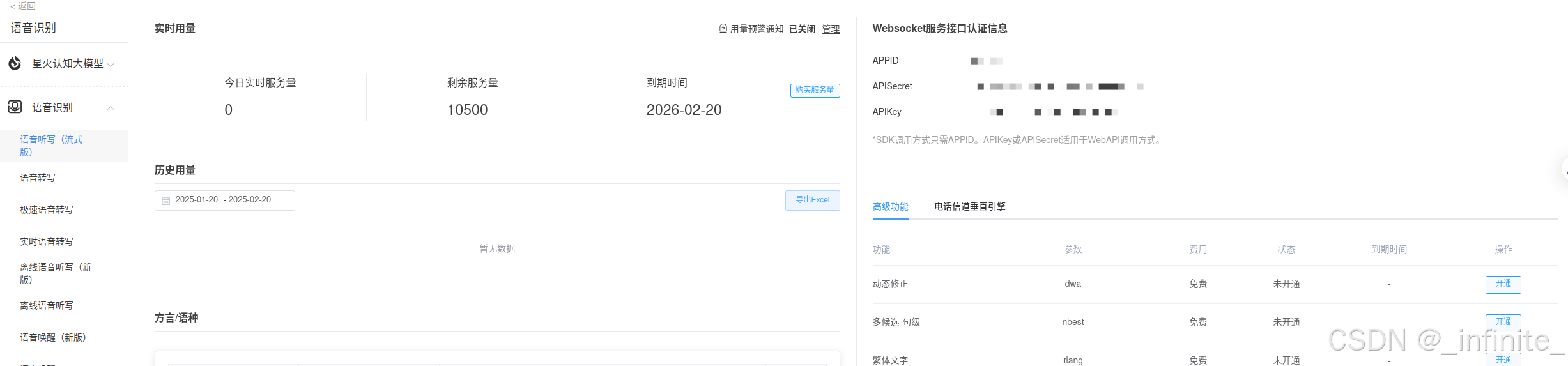
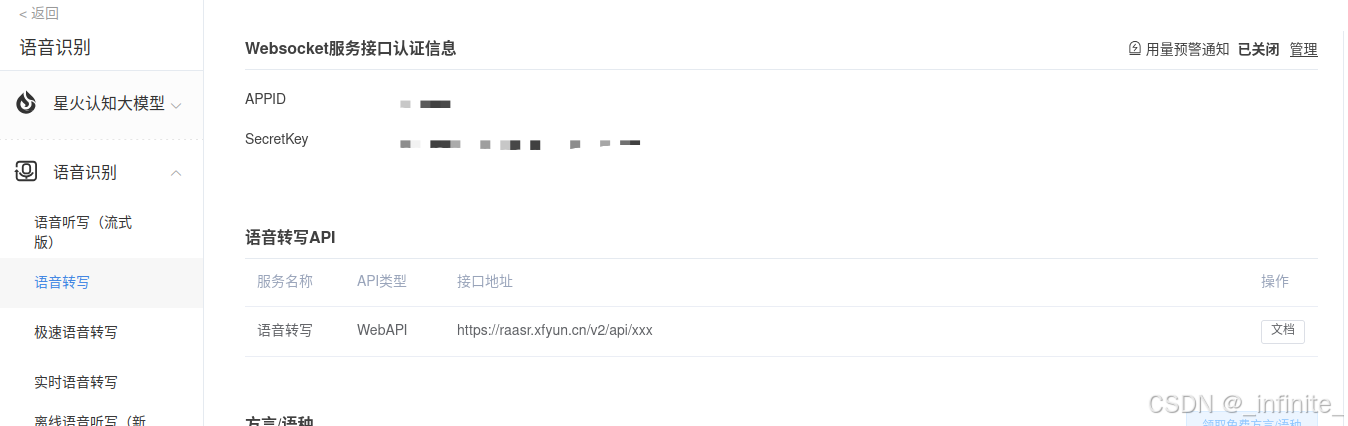
三、 示例代码
本文代码实现功能:
代码运行有三个模式:mode 0、mode 1、mode2
mode 0 对整段语音进行转文字操作,结果输出时间较长
mode 1 将语音划分为若干份,逐份进行转文字输出
mode 2 首先进行录音操作,然后再对音频使用mode 1方法转文字输出
# -*- coding: utf-8 -*-
import base64
import hashlib
import hmac
import json
import os
import time
import requests
import urllib
import websocket
import datetime
import hashlib
import base64
import hmac
import json
from urllib.parse import urlencode
import time
import ssl
from wsgiref.handlers import format_date_time
from datetime import datetime
from time import mktime
import _thread as thread
import pyaudio
import threading
import wave
import numpy as np
STATUS_FIRST_FRAME = 0 # 第一帧的标识
STATUS_CONTINUE_FRAME = 1 # 中间帧标识
STATUS_LAST_FRAME = 2 # 最后一帧的标识
lfasr_host = 'https://raasr.xfyun.cn/v2/api'
# 请求的接口名
api_upload = '/upload'
api_get_result = '/getResult'
##################################################
# 录音功能函数
#########
def audio_f2i(data, width=16):
"""将浮点数音频数据转换为整数音频数据。"""
data = np.array(data)
return np.int16(data * (2 ** (width - 1)))
def audio_i2f(data, width=16):
"""将整数音频数据转换为浮点数音频数据。"""
data = np.array(data)
return np.float32(data / (2 ** (width - 1)))
def save_wavfile(path, wave_data):
"""保存音频数据为wav文件。"""
with wave.open(path, 'wb') as wav_file:
wav_file.setnchannels(1)
wav_file.setsampwidth(2)
wav_file.setframerate(16000)
wav_file.writeframes(np.array(wave_data).tobytes())
print(f"Successfully saved wavfile: {path} ..")
# 获取麦克风设备列表
def list_devices():
p = pyaudio.PyAudio()
info = p.get_host_api_info_by_index(0)
numdevices = info.get('deviceCount')
devices = []
for i in range(numdevices):
if p.get_device_info_by_host_api_device_index(0, i).get('maxInputChannels') > 0:
devices.append(p.get_device_info_by_host_api_device_index(0, i))
p.terminate()
print("Available recording devices:")
devices_dict = {}
for i, device in enumerate(devices):
print(f"{i}: {device['name']}")
devices_dict[device['name']] = i
return devices, devices_dict
def init_device():
devices, devices_dict = list_devices()
device_id = int(input("请选择设备:"))
print("选择设备:",devices[device_id])
device = devices[device_id] # Select the first available device, modify as needed
return device
class Recorder(threading.Thread):
def __init__(self,
format=pyaudio.paInt16,
channels=1,
sample_rate=16000,
frames_per_buffer=1024,
device = None):
super().__init__()
self.daemon = True
self._stop_event = threading.Event()
self.device = device
self.init_stream(format=format,
channels=channels,
sample_rate=sample_rate,
frames_per_buffer=frames_per_buffer)
self.waveform = []
def run(self):
self.waveform = []
chunk_size = 1024
while not self._stop_event.is_set():
data = self.stream.read(chunk_size)
data = np.frombuffer(data,dtype='int16')
self.waveform.extend(data)
self.deinit_stream()
def init_stream(self,
format=pyaudio.paInt16,
channels=1,
sample_rate=16000,
frames_per_buffer=1024):
self.p = pyaudio.PyAudio()
self.stream = self.p.open(
format=format,
channels=channels,
rate=sample_rate,
input=True,
input_device_index=self.device['index'],
frames_per_buffer=frames_per_buffer
)
print("Initialized the stream reader successfully.")
def deinit_stream(self):
self.stream.stop_stream()
self.stream.close()
self.p.terminate()
print("Deinitialized the stream reader successfully.")
def stop(self):
self._stop_event.set()
#########
##################################################
# 语音转写
#########
class RequestApi(object):
def __init__(self, appid, secret_key, upload_file_path):
self.appid = appid
self.secret_key = secret_key
self.upload_file_path = upload_file_path
self.ts = str(int(time.time()))
self.signa = self.get_signa()
def get_signa(self):
appid = self.appid
secret_key = self.secret_key
m2 = hashlib.md5()
m2.update((appid + self.ts).encode('utf-8'))
md5 = m2.hexdigest()
md5 = bytes(md5, encoding='utf-8')
# 以secret_key为key, 上面的md5为msg, 使用hashlib.sha1加密结果为signa
signa = hmac.new(secret_key.encode('utf-8'), md5, hashlib.sha1).digest()
signa = base64.b64encode(signa)
signa = str(signa, 'utf-8')
return signa
def upload(self):
# print("上传部分:")
upload_file_path = self.upload_file_path
file_len = os.path.getsize(upload_file_path)
file_name = os.path.basename(upload_file_path)
param_dict = {}
param_dict['appId'] = self.appid
param_dict['signa'] = self.signa
param_dict['ts'] = self.ts
param_dict["fileSize"] = file_len
param_dict["fileName"] = file_name
param_dict["duration"] = "200"
# print("upload参数:", param_dict)
data = open(upload_file_path, 'rb').read(file_len)
response = requests.post(url =lfasr_host + api_upload+"?"+urllib.parse.urlencode(param_dict),
headers = {"Content-type":"application/json"},data=data)
# print("upload_url:",response.request.url)
result = json.loads(response.text)
# print("upload resp:", result)
return result
def get_result(self):
uploadresp = self.upload()
orderId = uploadresp['content']['orderId']
param_dict = {}
param_dict['appId'] = self.appid
param_dict['signa'] = self.signa
param_dict['ts'] = self.ts
param_dict['orderId'] = orderId
param_dict['resultType'] = "transfer,predict"
# print("")
# print("查询部分:")
# print("get result参数:", param_dict)
status = 3
# 建议使用回调的方式查询结果,查询接口有请求频率限制
while status == 3:
response = requests.post(url=lfasr_host + api_get_result + "?" + urllib.parse.urlencode(param_dict),
headers={"Content-type": "application/json"})
# print("get_result_url:",response.request.url)
result = json.loads(response.text)
# print(result)
status = result['content']['orderInfo']['status']
# print("status=",status)
if status == 4:
break
time.sleep(5)
# print("get_result resp:",result)
return result
#########
##################################################
# 语音听写
#########
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret, AudioFile):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.AudioFile = AudioFile
# 公共参数(common)
self.CommonArgs = {"app_id": self.APPID}
# 业务参数(business),更多个性化参数可在官网查看
self.BusinessArgs = {"domain": "iat", "language": "zh_cn", "accent": "mandarin", "vinfo":1,"vad_eos":10000}
# 生成url
def create_url(self):
url = 'wss://ws-api.xfyun.cn/v2/iat'
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + "ws-api.xfyun.cn" + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + "/v2/iat " + "HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (
self.APIKey, "hmac-sha256", "host date request-line", signature_sha)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": "ws-api.xfyun.cn"
}
# 拼接鉴权参数,生成url
url = url + '?' + urlencode(v)
# print("date: ",date)
# print("v: ",v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
# print('websocket url :', url)
return url
# 收到websocket消息的处理
def on_message(ws, message):
try:
code = json.loads(message)["code"]
sid = json.loads(message)["sid"]
if code != 0:
errMsg = json.loads(message)["message"]
print("sid:%s call error:%s code is:%s" % (sid, errMsg, code))
else:
data = json.loads(message)["data"]["result"]["ws"]
# print(json.loads(message))
result = ""
for i in data:
for w in i["cw"]:
result += w["w"]
json_str = json.dumps(data, ensure_ascii=False)
data = json.loads(json_str)
result = ""
# 遍历数据列表
for item in data:
# 从每个子项中提取字符并添加到结果字符串中
result += item["cw"][0]["w"]
# 输出最终结果
with open('data.txt','a+',encoding='utf-8') as f:
f.write(result+'\n')
# print(result)
print("data:%s is:%s" % (n+1, result))
except Exception as e:
print("receive msg,but parse exception:", e)
# 收到websocket错误的处理
def on_error(ws, error):
print("### error:", error)
# 收到websocket关闭的处理
def on_close(ws,a,b):
print("### closed ###")
# 收到websocket连接建立的处理
def on_open(ws):
def run(*args):
frameSize = 8000 # 每一帧的音频大小
intervel = 0.04 # 发送音频间隔(单位:s)
status = STATUS_FIRST_FRAME # 音频的状态信息,标识音频是第一帧,还是中间帧、最后一帧
with open(wsParam.AudioFile, "rb") as fp:
while True:
buf = fp.read(frameSize)
# 文件结束
if not buf:
status = STATUS_LAST_FRAME
# 第一帧处理
# 发送第一帧音频,带business 参数
# appid 必须带上,只需第一帧发送
if status == STATUS_FIRST_FRAME:
d = {"common": wsParam.CommonArgs,
"business": wsParam.BusinessArgs,
"data": {"status": 0, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
d = json.dumps(d)
ws.send(d)
status = STATUS_CONTINUE_FRAME
# 中间帧处理
elif status == STATUS_CONTINUE_FRAME:
d = {"data": {"status": 1, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
ws.send(json.dumps(d))
# 最后一帧处理
elif status == STATUS_LAST_FRAME:
d = {"data": {"status": 2, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
ws.send(json.dumps(d))
time.sleep(1)
break
# 模拟音频采样间隔
time.sleep(intervel)
ws.close()
thread.start_new_thread(run, ())
#########
##################################################
# main函数
# mode = 0 语音转写
# mode = 1 实时语音转写 (小于30s)
# mode = 2 录音转写 (小于30s)
#########
if __name__ == '__main__':
# 导入库
import argparse
# 1. 定义命令行解析器对象
parser = argparse.ArgumentParser(description='Usage of argparse')
# 2. 添加命令行参数,可以简写,也可以写全称
parser.add_argument('-m','--mode', type=int, default="0")
# 3. 从命令行中结构化解析参数
args = parser.parse_args()
#通过args对象.参数名,获取命令行参数值
mode = args.mode
print(f"解析出的参数,mode:{mode}")
print("-------------------------------识别开始-------------------------------")
if mode == 0:
api = RequestApi(appid="xxxx",
secret_key="xxxx",
upload_file_path=r"audio/lfasr_涉政.wav")
result = api.get_result()
text = json.loads(result['content']['orderResult'])['lattice']
with open('music.txt','w',encoding='utf-8') as f:
for each in text:
txt = json.loads(each['json_1best'])['st']['rt']
for t in txt:
#print(t)
st = ''
for i in range(len(t['ws'])):
print(t['ws'][i]['cw'][0]['w'],end='')
st += t['ws'][i]['cw'][0]['w']
f.write(st+'\n')
print()
print("-------------------------------识别结束-------------------------------")
elif mode == 1:
n = 0
os.remove("data.txt")
time1 = datetime.now()
wsParam = Ws_Param(APPID='xxxx', APISecret='xxxx',
APIKey='xxxx',
AudioFile=r'audio/lfasr_涉政.wav')
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
ws.on_open = on_open
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
time2 = datetime.now()
print(time2-time1)
print("-------------------------------识别结束-------------------------------")
elif mode == 2:
os.remove("data.txt")
device = init_device()
recorder = Recorder(device=device)
input("按下任意键开始录音")
recorder.start()
input("按下任意键结束录音")
recorder.stop()
recorder.join()
save_wavfile('noise.wav',recorder.waveform)
time1 = datetime.now()
wsParam = Ws_Param(APPID='xxxx', APISecret='xxxx',
APIKey='xxxx',
AudioFile=r'noise.wav')
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
ws.on_open = on_open
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
time2 = datetime.now()
print(time2-time1)
print("-------------------------------识别结束-------------------------------")
#########
可用博主资源里的科大讯飞官方例程音频测试代码。

















 6124
6124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









