







 本文详细介绍了Linux内核的主要功能,包括内存管理、进程管理、设备驱动和文件系统。通过uname命令展示了获取内核信息的方法,并探讨了Linux系统启动过程中的运行级别。此外,文章还讨论了系统调优工具,如vmstat、top和free,以及如何通过/proc目录获取内核信息。最后,文章提供了系统故障排查和性能优化的案例,包括CPU负载、内存使用和磁盘I/O的分析。
本文详细介绍了Linux内核的主要功能,包括内存管理、进程管理、设备驱动和文件系统。通过uname命令展示了获取内核信息的方法,并探讨了Linux系统启动过程中的运行级别。此外,文章还讨论了系统调优工具,如vmstat、top和free,以及如何通过/proc目录获取内核信息。最后,文章提供了系统故障排查和性能优化的案例,包括CPU负载、内存使用和磁盘I/O的分析。
Linux系统内核:内核是操作系统的核心,有很多基本功能,负责管理系统的进程
内存设备驱动程序 文件和网络系统,决定着系统的性能和稳定性
Linux内核相关介绍:
内存管理(Linux采用虚拟内存)
进程管理(进程调度)
设备驱动程序
文件系统(虚拟文件系统vfs)
网络管理
内核组成部分:内核核心文件 内核对象 内核补充文件 文件系统
内核信息获取命令:uname
uname命令显示多个系统信息,包括Linux内核体系结构,名称版本和发行版。
hostnamectl实用程序是systemd的一部分,用于查询和更改系统主机名。 它还显示Linux发行版和内核版本:
Uname -n 显示节点名称 localhost.localdomain
Uname -r 显示内核版本号
Uname -a 显示所有信息
Uname -s 显示系统名称 Linux
Lsmod :可以显示模块名称 模块大小 被引用次数以及被谁引用
!!!内核空间和用户空间可以通过/proc虚拟文件系统进行通信
***/proc目录中包含一些目录和虚拟文件 这些虚拟文件可以向用户呈现内核信息
或者从用户空间向内核空间发送信息
通过查看/proc/version文件确认内核版本
/proc目录包含虚拟文件,其中包含有关系统内存,CPU内核,
已安装文件系统等的信息。有关正在运行的内核的信息存储在/proc/version虚拟文件中。
Linux系统启动过程:
内核空间与用户空间
内核态:当一个任务(进程)执行系统调用而陷入内核代码中执行时
用户态:用户执行自己的代码
用户态到内核态的条件: 系统调用 异常 外围设备的中断
系统运行级别:init进程 由内核启动的用户级进程
Linux七个运行级别:
0:系统停机状态 将0 设置为默认运行级别则不能正常启动
1:单用户工作状态 root权限(单用户修改密码)重启虚拟机 找到utf-8 之后添加一个 init=/bin/bash 并按CTRL+x 执行后进入如下提示符: mount-o remount.rw / 回车后 输入passwd 修改密码修改好之后,进入另一个界面 输入 touch /.autorelabe 更新信息系统信息 输入完后 最后执行exec/sbin/init 即可退出单用户模式 用于系统维护 禁止远程登陆
2:多用户状态 无NFS 网络文件系统表示层协议
3:完全的多用户状态 有NFS 登陆后进入控制台命令行模式
4:未使用,保留级别
5:图形化模式 登陆后进入图形GUI模式
6:重启模式 将6设置为默认模式系统不能正常运行 会一直陷入重启开机重启的循环
运行级别的切换: init N 例如:init 0 系统会关机 init 6系统会重启
注意:该系统切换是临时的
runlevel 查看系统运行级别 一般都为 3 完全多用户状态
Init进程id为1 是初始化进程 ps -ef |grep init
永久修改: 修改默认运行级别: vim /etc/inittab 中的initdefault 的值
Systemctl get-default 查看 的是多用户级别
Init 0 切换运行级别命令
系统启动过程:
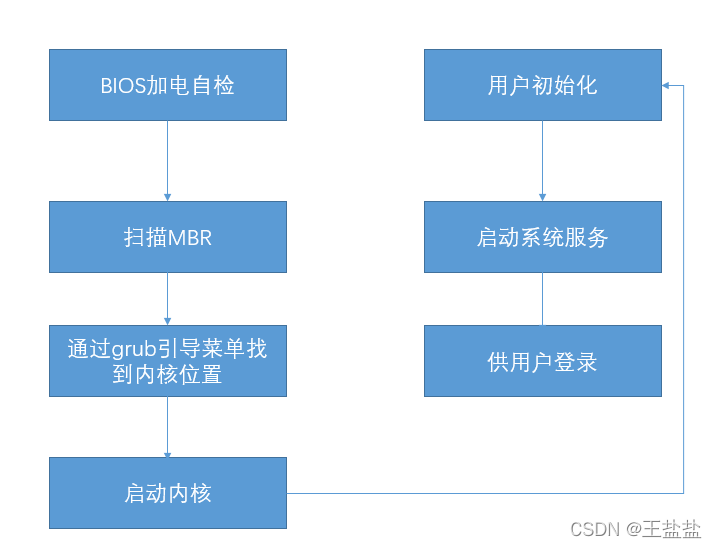
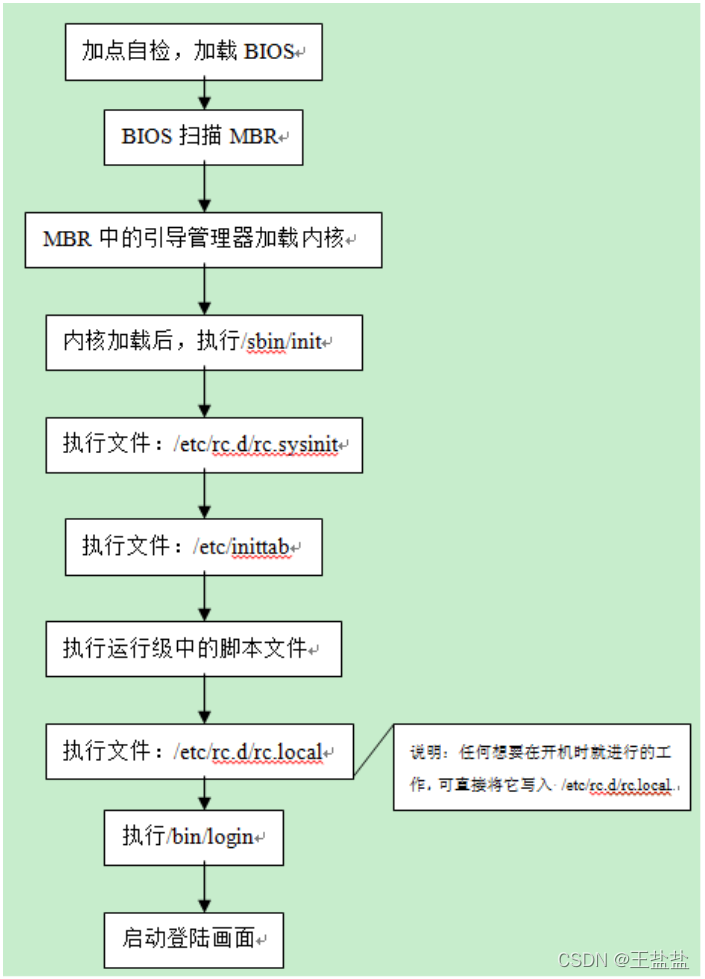
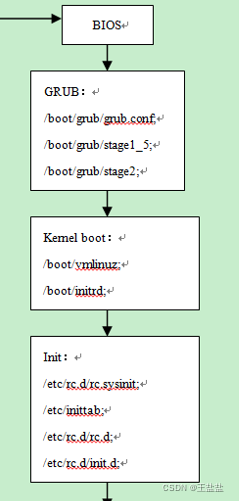
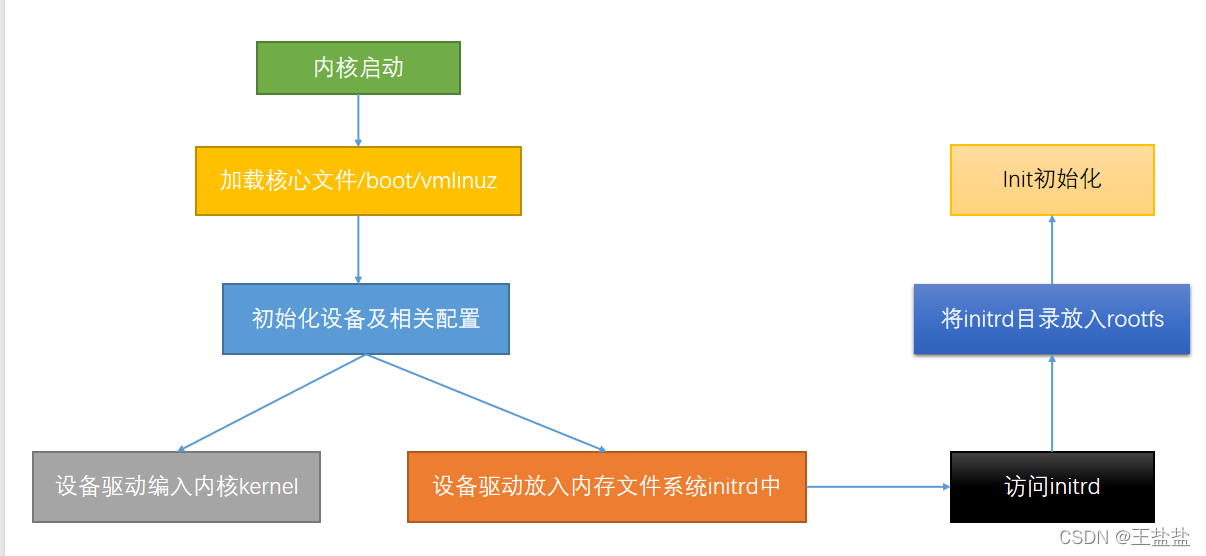
加载linux的核心就必须能识别linux的文件系统,核心文件一般会放在/boot/vmlinuz。
内核启动流程:
Linux系统调优:
常见系统性能问题:
web网页响应慢 SQL操作慢 CPU负载高 内存负载高
影响性能的因素:
1)CPU(cpu的速度与性能很大一部分决定了系统整体的性能,是否使用SMP)
2)内存(物理内存不够时会使用交换内存,使用swap会带来磁盘I0和cpu的开销)
3)硬盘(存储系统)
a.Raid技术使用(RAID0, RAID1, RAID5, RAID0+1)
b.小文件读写瓶颈是磁盘的寻址(tps),大文件读写的性能瓶颈是带宽
c.Linux可以利用空闲内存作文件系统访问的cache,因此系统内存越大存储系统的性能也越好
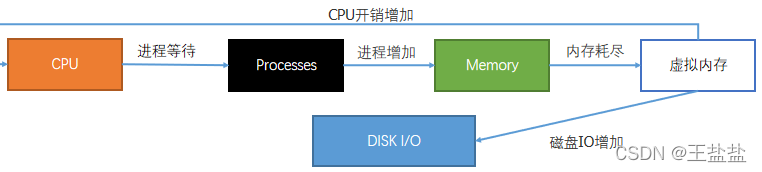
一般情况下系统良好运行的时候恰恰各项资源达到了一个平衡体,任何一项资源的过渡使用都会造成平衡体系破坏,从而造成系统负载极高或者响应迟缓。比如CPU过度使用会造成大量进程等待CPU资源,系统响应变慢,等待会造成进程数增加,进程增加又会造成内存使用增加,内存耗尽又会造成虚拟内存使用,使用虚拟内存又会造成磁盘IO增加和CPU开销增加
性能分析的步骤:
1) 对资源的使用状况进行长期的监控和数据采集(nagios、cacti)
2)使用常见的性能分析工具(vmstat、top、free、iostat等)
3)经验积累
a.应用程序设计的缺陷和数据库查询的滥用最有可能导致性能问题
b.性能瓶颈可能是因为程序差/内存不足/磁盘瓶颈,但最终表现出的结果就是CPU耗尽,系统负载极高,响应迟缓,甚至暂时失去响应
c.物理内存不够时会使用交换内存,使用swap会带来磁盘I0和cpu的开销
d.可能造成cpu瓶颈的问题:频繁执Perl,php,java程序生成动态web;数据库查询
大量的where子句、order by/group by排序……
e.可能造成内存瓶颈问题:高并发用户访问、系统进程多,java内存泄露……
f.可能造成磁盘IO瓶颈问题:生成cache文件,数据库频繁更新,或者查询大表……
4)网络带宽。
系统调优工具:
1.Vmstat:

Procs: r 运行和等待CPU时间片的进程数
b 表示等待资源的进程数
memory: swpd 切换到内存交换区的内存数量
free 表示当前空闲的物理内存数量
buffer:缓冲区的内存数量 一般对块设备的读写才需要缓冲
cache 文件系统的缓存cached
swap:si 磁盘调入内存
so 内存调入磁盘
一般情况下为0
io:bi 表示从块设备读入的数据总量
bo: 表示写入到块设备的数据总量
System: in 表示在某一时间间隔中观察到的每秒设备中断数
cs 表示每秒产生的上下文切换次数
CPU: us 用户进程消耗CPU的时间百分比
sy 内核进程消耗CPU的时间百分比
id CPU在空闲状态的时间百分比
wa io等待所占CPU时间百分比
st 虚拟机占用时间百分比
2.top:
一、top前5行统计信息
第1行:top - 05:43:27 up 4:52, 2 users, load average: 0.58, 0.41, 0.30
第1行是任务队列信息,其参数如下:
| 内容 | 含义 |
| 05:43:27 | 表示当前时间 |
| up 4:52 | 系统运行时间 格式为时:分 |
| 2 users | 当前登录用户数 |
| load average: 0.58, 0.41, 0.30 | 系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。 |
load average: 如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第2行:Tasks: 159 total, 1 running, 158 sleeping, 0 stopped, 0 zombie
第3行:%Cpu(s): 37.0 us, 3.7 sy, 0.0 ni, 59.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
第2、3行为进程和CPU的信息
当有多个CPU时,这些内容可能会超过两行,其参数如下:
| 内容 | 含义 |
| 159 total | 进程总数 |
| 1 running | 正在运行的进程数 |
| 158 sleeping | 睡眠的进程数 |
| 0 stopped | 停止的进程数 |
| 0 zombie | 僵尸进程数 |
| 37.0 us | 用户空间占用CPU百分比 |
| 3.7 sy | 内核空间占用CPU百分比 |
| 0.0 ni | 用户进程空间内改变过优先级的进程占用CPU百分比 |
| 59.3 id | 空闲CPU百分比 |
| 0.0 wa | 等待输入输出的CPU时间百分比 |
| 0.0 hi | 硬中断(Hardware IRQ)占用CPU的百分比 |
| 0.0 si | 软中断(Software Interrupts)占用CPU的百分比 |
| 0.0 st |
第4行:KiB Mem: 1530752 total, 1481968 used, 48784 free, 70988 buffers
第5行:KiB Swap: 3905532 total, 267544 used, 3637988 free. 617312 cached Mem
第4、5行为内存信息
其参数如下:
| 内容 | 含义 |
| KiB Mem: 1530752 total | 物理内存总量 |
| 1481968 used | 使用的物理内存总量 |
| 48784 free | 空闲内存总量 |
| 70988 buffers(buff/cache) | 用作内核缓存的内存量 |
| KiB Swap: 3905532 total | 交换区总量 |
| 267544 used | 使用的交换区总量 |
| 3637988 free | 空闲交换区总量 |
| 617312 cached Mem | 缓冲的交换区总量。 |
| 3156100 avail Mem | 代表可用于进程下一次分配的物理内存数量 |
上述最后提到的缓冲的交换区总量,这里解释一下,所谓缓冲的交换区总量,即内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,该数值即为这些内容已存在于内存中的交换区的大小。相应的内存再次被换出时可不必再对交换区写入。
计算可用内存数有一个近似的公式:
第四行的free + 第四行的buffers + 第五行的cached
二、进程信息
| 列名 | 含义 |
| PID | 进程id |
| PPID | 父进程id |
| RUSER | Real user name |
| UID | 进程所有者的用户id |
| USER | 进程所有者的用户名 |
| GROUP | 进程所有者的组名 |
| TTY | 启动进程的终端名。不是从终端启动的进程则显示为 ? |
| PR | 优先级 |
| NI | nice值。负值表示高优先级,正值表示低优先级 |
| P | 最后使用的CPU,仅在多CPU环境下有意义 |
| %CPU | 上次更新到现在的CPU时间占用百分比 |
| TIME | 进程使用的CPU时间总计,单位秒 |
| TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| %MEM | 进程使用的物理内存百分比 |
| VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| SWAP | 进程使用的虚拟内存中,被换出的大小,单位kb |
| RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| CODE | 可执行代码占用的物理内存大小,单位kb |
| DATA | 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
| SHR | 共享内存大小,单位kb |
| nFLT | 页面错误次数 |
| nDRT | 最后一次写入到现在,被修改过的页面数。 |
| S | 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 |
| COMMAND | 命令名/命令行 |
| WCHAN | 若该进程在睡眠,则显示睡眠中的系统函数名 |
| Flags | 任务标志 |
3.free

4.iostat
网络参数调优: 比如:TIME_WAIT过高 DDOS攻击
系统参数调优:磁盘 文件 文件系统 内存等
Linux系统应用及企业案例分析:
1.系统故障修复
Linux再启动过程中 可能会出现故障 导致系统无法启动
我们可以应用单用户模式 grub命令进行操作 Linux救援模式解决问题
单用户模式:
1.root密码故障解决方案
2.硬盘扇区错乱解决方案
进入单用户模式:输入fsck -y /dev/sda5(发生错误的磁盘)
fsck 为文件系统修复命令 -y 为检测到错误要自动修复
修复完成后 重启
grub引导故障排除:
常见错误原因:grub配置文件选项设置错误 (先通过grub命令引导系统修复)
grub配置文件丢失 (Linux救援模式修复)
Linux救援模式:系统无法进入单用户模式 或者出现grub命令行
CPU管理优化:
CPU使用率低而负载高的原因:等待磁盘i/o完成的进程多,导致队列长度过大 但是CPU运行的进程却很少。
排查案例:
linux系统下的一个网站系统,用户反映,网站访问速度很慢,有时无法访问。
第一步要做的是检测网络,可以通过ping命令检查网站的域名解析是否正常,同时,ping服务器地址的延时是否过大等等
第二步,对linux系统的内存使用状况进行检查,因为网站响应速度慢,一般跟内存关联比较大,通过free、vmstat等命令判断内存资源是否紧缺
第三步,检查系统CPU的负载状况,可以通过sar、vmstat、top等命令的输出综合判断CPU是否存在过载问题
第四步,检查系统的磁盘I/O是否存在瓶颈,可以通过iostat、vmstat等命令检查磁盘的读写性能
如果磁盘读写也没有问题,linux系统自身的性能问题基本排除,最后要做的是检查程序本身是否存在问题。
SQL操作比较慢请问有哪些原因:
1.首先排查服务自身是否由于ORM框架导致的问题
2.再次排查网络是否通畅,是否存在丢包延迟等情况(网络相关命令)
3.确定业务服务正常无CPU 飙高或者FGC等情况
4.确定Mysql服务端是否已经满负荷运行
5.确定当时的场景是否存在高并发写入或者读
6.确定sql对应的表数据,sql本身是否存在导致慢的因素,比如数据量大,sql没有索
引,查全部数据等
CPU Load很高你怎么排查:
原因:
由于CPU是程序计算单元,因此涉及到的长时间高频率计算都有可能
定位方法及解决办法:
1、使用top命令查看是哪个PID进程消耗了CPU资源,其执行用户是否可疑
2、使用"lsof -p PID"命令来查询该PID开启了哪些进程
3、分析第二步中的可疑进程,比如有没有在执行一些奇怪的shell脚本,有没有开启特殊端口
4、使用"lsof -i :port"查看被开启的特殊端口在干啥子
5、经过上面的步骤后基本已经可以找出这些可疑程序和脚本了,只需要删除即可恢复


















 509
509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











