







 本文介绍如何使用Hadoop在一组文本文件中统计每个单词的出现次数。具体步骤包括准备数据格式、创建并上传文件到HDFS,接着定义Mapper和Reducer进行单词计数。
本文介绍如何使用Hadoop在一组文本文件中统计每个单词的出现次数。具体步骤包括准备数据格式、创建并上传文件到HDFS,接着定义Mapper和Reducer进行单词计数。
需求:在一堆给定的文本文件中统计输出每一个单词出现的总次数
Step1.数据格式准备
1.创建一个新的文件
cd /export/serves
vim wordcount.txt
2.向其中放入以下内容并保存
hello,world,hadoop
hive,sqoop,flume,hello
kitty,tom,jerry,world
hadoop
3.上传到HDFS
hdfs dfs -mkdir /wordcount/
hdfs dfs -put wordcount.txt /wordcount/
Step2.Mapper

Step3.Reducer

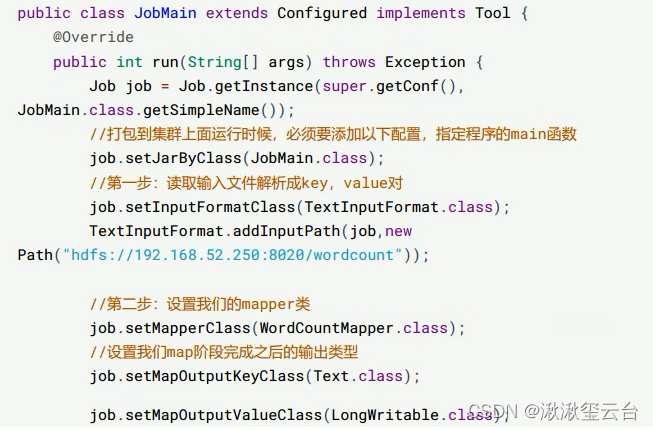
Step4.定义主类,描述Job并提交Job

















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









