







一、执行顺序的核心逻辑
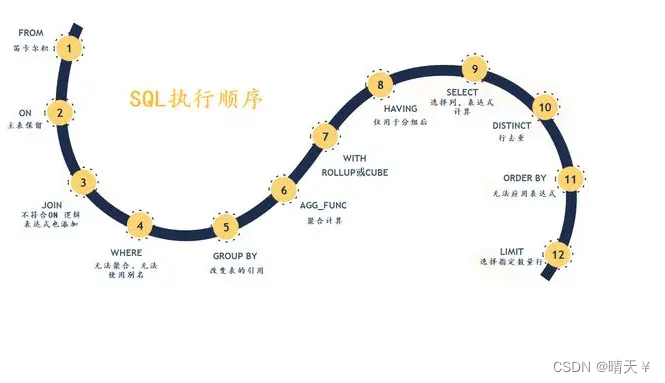
1.FROM & JOIN
作用:确定数据源和表连接方式(笛卡尔积 → 连接条件过滤 → 外部行补充)。
示例:
FROM employees e
JOIN departments d ON e.department_id = d.department_id
首先生成所有可能的行组合(笛卡尔积),再通过ON条件过滤有效连接行。
若使用LEFT JOIN,保留主表中未匹配的行作为外部行。
2.WHERE
作用:筛选满足条件的行,无法使用聚合函数(如SUM)。
示例:
WHERE e.salary > 5000 -- 仅保留工资大于5000的记录
3.GROUP BY
作用:按指定列分组,为后续聚合计算做准备。
示例:
GROUP BY d.department_name -- 按部门名称分组
4.HAVING
作用:过滤分组后的结果,支持聚合函数(如COUNT)。
示例:
HAVING COUNT(e.employee_id) > 10 -- 筛选员工数超过10的部门
5.SELECT
作用:选择最终输出的列,包括计算字段和别名定义。
注意:SELECT中定义的别名在后续步骤(如ORDER BY)可用,但不能在WHERE或GROUP BY中使用。
示例:
SELECT d.department_name, COUNT(e.employee_id) AS employee_count
6.DISTINCT
作用:去除重复行,生成唯一结果集。
示例:
SELECT DISTINCT job_title -- 返回唯一的职位名称
7.ORDER BY
作用:按指定列排序结果集,支持别名和聚合字段(如employee_count)。
示例:
ORDER BY employee_count DESC -- 按员工数量降序排列
8.LIMIT/OFFSET
作用:限制返回的行数或分页。
示例:
LIMIT 10 OFFSET 20 -- 返回第21~30条记录
二、示例
SELECT d.department_name, COUNT(e.employee_id) AS emp_count
FROM employees e
JOIN departments d ON e.department_id = d.department_id
WHERE e.salary > 5000
GROUP BY d.department_name
HAVING emp_count > 10
ORDER BY emp_count DESC
LIMIT 5;执行步骤:
- FROM + JOIN → 连接员工表和部门表。
- WHERE → 过滤工资>5000的员工。
- GROUP BY → 按部门分组。
- HAVING → 筛选员工数>10的部门。
- SELECT → 选择部门名称和员工数。
- ORDER BY → 按员工数降序排序。
- LIMIT → 返回前5条记录。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









