






一、为什么要使用集合?
使用传统数组作为存储的容器时会存在以下问题:
1、长度固定的此情况下不能存储更多的数据
2、不能根据数据的情况实时改变
所以引入了集合的概念
二、集合的体系
集合的体系自上而下分为:Cllection/Map;
Cllection下有:List、Set。
Map下有:HashMap;
而List又分为:ArrayList、LinkedList;
Set又分为:HashSet、TreeSet、LinkedHashSet;
三、单列集合
Cllection(List/Set)
List可以使得有重复的元素存在,因为底层的数据结构是数组,这样的结构也就决定了它的特点:通过索引查询快,但是一旦删减元素的话,就得改变索引的值以及元素的位置,效率不高,也有引入LinkedList,底层是链表,可以快速增删,但是查询效率不高,每次都需要从表头开始查询。
Set集合内不可以有重复的元素存在,这一特性源于哈希值,即调用hashCode()产生哈希值,找到哈希表对应的索引,先判断索引是否对的上,不是的话寻找下个,否则判断该索引下是否有数据,没有直接放到里面,有的话进行数据重复的判断;数据没有重复,将数据加到哈希表中,有重复则不进行操作,直到所有的数据被操作完成。
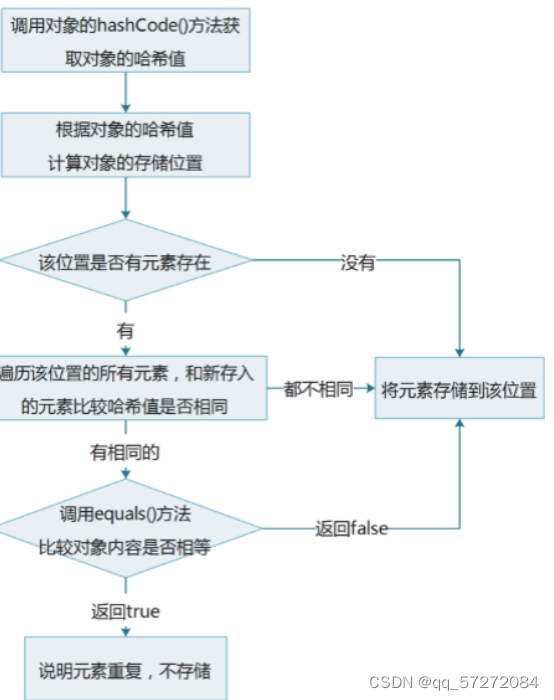
这就是通过哈希表使得Set集合内重复元素没有的原因。
另外,Set集合包含有HashSet、LinkedHashSet、TreeSet。第一个不保证顺序,第二个可以使得存储和取出的顺序一致,第三个可以使用无参构造器Comparable进行自然排序,也可以使用带参构造器Compareactor。
四、双列集合
Map目前就学到HashMap,因此在这里只讨论有关于HashMap的特点;
首先,Map的特点是引入了泛型键值,即是<k,v>前者是键,后者是值,键不允许有重复,但值不一定(可能是对象时)。
在这里提到HashMap和HashSet的区别:在键一致的情况下,会将后面的值覆盖原来的键对应的值,但是HashSet不会。

引入阈值:
阈值=默认负载因子*容量
当默认负载因子取0.75时,比较合理,能够使得哈希冲突尽量减小空间利用开销也也减少。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









