







 文章讲述了如何处理一个涉及共模攻击的加密问题,使用gmpy2库进行大数运算,解密后发现结果是Base64编码,进一步揭示了Base64隐写术的应用。作者通过编写Python脚本,首先解决共模攻击中的数学问题,然后解析出隐藏的信息,最终成功获取到Flag。
文章讲述了如何处理一个涉及共模攻击的加密问题,使用gmpy2库进行大数运算,解密后发现结果是Base64编码,进一步揭示了Base64隐写术的应用。作者通过编写Python脚本,首先解决共模攻击中的数学问题,然后解析出隐藏的信息,最终成功获取到Flag。
题目
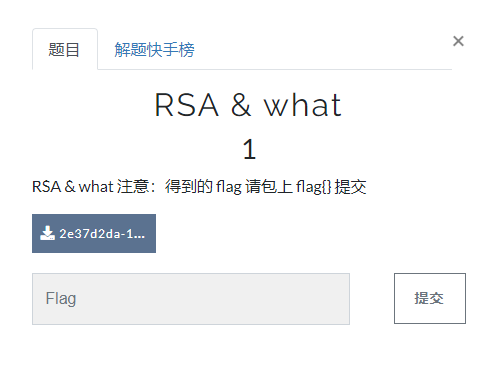
附件

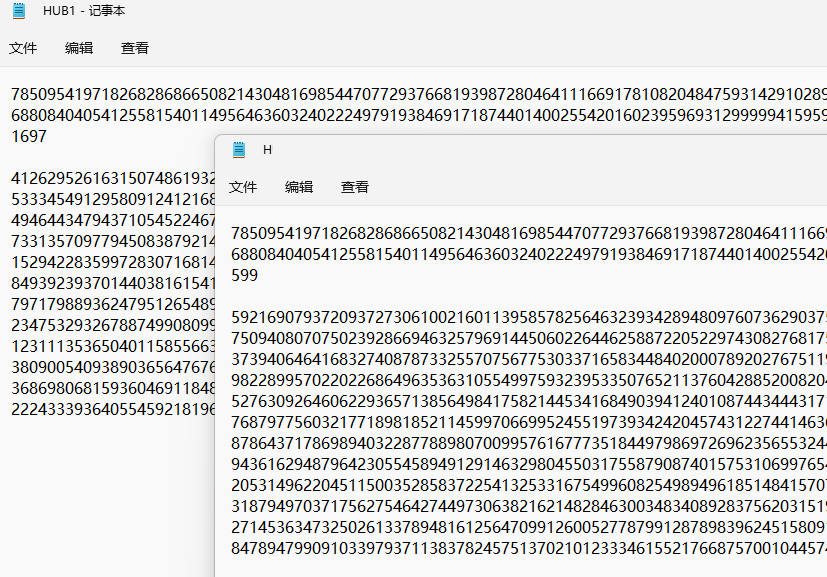
这里给了相同的N,所以无疑是共模攻击,每个文件有多个c,因为之前遇到的也就只有c1,c2,这次多来几个还有点不会了,其实每个相对应组成c1,c2,最后的结果拼接一下就行了,我脚本能力较差,所以就分开跑了六祖c1,c2
import gmpy2 as gp
def egcd(a, b):
if a == 0:
return (b, 0, 1)
else:
g, y, x = egcd(b % a, a)
return (g, x - (b // a) * y, y)
n =
c1 =
c2 =
e1 = 1697
e2 = 599
print(gp.gcd(c1,c2))
s = egcd(e1, e2)
s1 = s[1]
s2 = s[2]
if s1<0:
s1 = - s1
c1 = gp.invert(c1, n)
elif s2<0:
s2 = - s2
c2 = gp.invert(c2, n)
m = pow(c1,s1,n)*pow(c2,s2,n) % n
print(m)
print(hex(m)[2:])
print(bytes.fromhex(hex(m)[2:]))
##十进制转ASCII码
'''
m=str(m)
flag=""
i=0
while i < len(m):
if m[i]=='1':
c=chr(int(m[i:i+3]))
i+=3
else:
c=chr(int(m[i:i+2]))
i+=2
flag+=c
print(flag)
'''但是,当我跑出第一组结果时我就愣住了

这个看似base64,又不太像,最后看了大佬wp才知道,原来这是base64隐写,那就直接上脚本
from Crypto.Util.number import *
import base64
c = b''
def get_base64_diff_value(s1, s2):
base64chars = b'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
res = 0
for i in range(len(s2)):
if s1[i] != s2[i]:
return abs(base64chars.index(s1[i]) - base64chars.index(s2[i]))
return res
def solve_stego():
line=b''
bin_str=''
for i in c:
k=long_to_bytes(i)
if k==b'\n':
steg_line = line
norm_line = base64.b64encode(base64.b64decode(line))
diff = get_base64_diff_value(steg_line, norm_line)
#print(diff)
pads_num = steg_line.count(b'=')
if diff:
bin_str += bin(diff)[2:].zfill(pads_num * 2)
else:
bin_str += '0' * pads_num * 2
print(goflag(bin_str))
line=b''
continue
line+=k
def goflag(bin_str):
res_str = ''
for i in range(0, len(bin_str), 8):
res_str += chr(int(bin_str[i:i + 8], 2))
return res_str
if __name__ == '__main__':
solve_stego()结果如下:
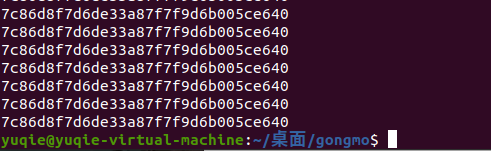
成功拿到flag!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











