







一、python的安装
二、python编辑器的安装
在这里我使用的是VS code 1.62.3
三、pywin32库的安装
在CMD里面使用pip install pywin32进行安装
四、全部代码
import os, win32com.client, gc
# Word
def word2Pdf(filePath, words):
# 如果没有文件则提示后直接退出
if(len(words)<1):
print ("\n【无 Word 文件】\n")
return
# 开始转换
print ("\n【开始 Word -> PDF 转换】")
try:
print ("打开 Word 进程...")
word = win32com.client.Dispatch("Word.Application")
word.Visible = 0
word.DisplayAlerts = False
doc = None
for i in range(len(words)):
print(i)
fileName = words[i] # 文件名称
fromFile = os.path.join(filePath, fileName) # 文件地址
toFileName = changeSufix2Pdf(fileName) # 生成的文件名称
toFile = toFileJoin(filePath,toFileName) # 生成的文件地址
print ("转换:"+fileName+"文件中...")
# 某文件出错不影响其他文件打印
try:
doc = word.Documents.Open(fromFile)
doc.SaveAs(toFile,17) # 生成的所有 PDF 都会在 PDF 文件夹中
print ("转换到:"+toFileName+"完成")
except Exception as e:
print(e)
# 关闭 Word 进程
print ("所有 Word 文件已打印完毕")
print ("结束 Word 进程...\n")
doc.Close()
doc = None
word.Quit()
word = None
except Exception as e:
print(e)
finally:
gc.collect()
# Excel
def excel2Pdf(filePath, excels):
# 如果没有文件则提示后直接退出
if(len(excels)<1):
print ("\n【无 Excel 文件】\n")
return
# 开始转换
print ("\n【开始 Excel -> PDF 转换】")
try:
print ("打开 Excel 进程中...")
excel = win32com.client.Dispatch("Excel.Application")
excel.Visible = 0
excel.DisplayAlerts = False
wb = None
ws = None
for i in range(len(excels)):
print(i)
fileName = excels[i] # 文件名称
fromFile = os.path.join(filePath, fileName) # 文件地址
print ("转换:"+fileName+"文件中...")
# 某文件出错不影响其他文件打印
try:
wb = excel.Workbooks.Open(fromFile)
for j in range(wb.Worksheets.Count): # 工作表数量,一个工作簿可能有多张工作表
toFileName = addWorksheetsOrder(fileName, j+1) # 生成的文件名称
toFile = toFileJoin(filePath,toFileName) # 生成的文件地址
ws = wb.Worksheets(j+1) # 若为[0]则打包后会提示越界
ws.ExportAsFixedFormat(0,toFile) # 每一张都需要打印
print ("转换至:"+toFileName+"文件完成")
except Exception as e:
print(e)
# 关闭 Excel 进程
print ("所有 Excel 文件已打印完毕")
print ("结束 Excel 进程中...\n")
ws = None
wb.Close()
wb = None
excel.Quit()
excel = None
except Exception as e:
print(e)
finally:
gc.collect()
# PPT
def ppt2Pdf(filePath, ppts):
# 如果没有文件则提示后直接退出
if(len(ppts)<1):
print ("\n【无 PPT 文件】\n")
return
# 开始转换
print ("\n【开始 PPT -> PDF 转换】")
try:
print ("打开 PowerPoint 进程中...")
powerpoint = win32com.client.Dispatch("PowerPoint.Application")
ppt = None
# 某文件出错不影响其他文件打印
for i in range(len(ppts)):
print(i)
fileName = ppts[i] # 文件名称
fromFile = os.path.join(filePath, fileName) # 文件地址
toFileName = changeSufix2Pdf(fileName) # 生成的文件名称
toFile = toFileJoin(filePath,toFileName) # 生成的文件地址
print ("转换:"+fileName+"文件中...")
try:
ppt = powerpoint.Presentations.Open(fromFile,WithWindow=False)
if ppt.Slides.Count>0:
ppt.SaveAs(toFile, 32) # 如果为空则会跳出提示框(暂时没有找到消除办法)
print ("转换至:"+toFileName+"文件完成")
else:
print("(错误,发生意外:此文件为空,跳过此文件)")
except Exception as e:
print(e)
# 关闭 PPT 进程
print ("所有 PPT 文件已打印完毕")
print ("结束 PowerPoint 进程中...\n")
ppt.Close()
ppt = None
powerpoint.Quit()
powerpoint = None
except Exception as e:
print(e)
finally:
gc.collect()
# 修改后缀名
def changeSufix2Pdf(file):
return file[:file.rfind('.')]+".pdf"
# 添加工作簿序号
def addWorksheetsOrder(file, i):
return file[:file.rfind('.')]+"_工作表"+str(i)+".pdf"
# 转换地址
def toFileJoin(filePath,file):
return os.path.join(filePath,'pdf',file[:file.rfind('.')]+".pdf")
# 开始程序
print ("====================程序开始====================")
print ("【程序功能】将目标路径下内所有的 ppt、excel、word 均生成一份对应的 PDF 文件,存在新生成的 pdf 文件夹中(需已经安装office,不包括子文件夹)")
print ("注意:若某 PPT 和 Excel 文件为空,则会出错跳过此文件。若转换 PPT 时间过长,请查看是否有报错窗口等待确认,暂时无法彻底解决 PPT 的窗口问题(为空错误已解决)。在关闭进程过程中,时间可能会较长,十秒左右,请耐心等待。")
filePath = input ("输入目标路径:(若为当前路径:"+os.getcwd()+",请直接回车)\n")
# 目标路径,若没有输入路径则为当前路径
if(filePath==""):
filePath = os.getcwd()
# 将目标文件夹所有文件归类,转换时只打开一个进程
words = []
ppts = []
excels = []
for fn in os.listdir(filePath):
if fn.endswith(('.doc', 'docx')):
words.append(fn)
if fn.endswith(('.ppt', 'pptx')):
ppts.append(fn)
if fn.endswith(('.xls', 'xlsx')):
excels.append(fn)
# 调用方法
print ("====================开始转换====================")
# 新建 pdf 文件夹,所有生成的 PDF 文件都放在里面
folder = filePath + '\\pdf\\'
if not os.path.exists(folder):
os.makedirs(folder)
word2Pdf(filePath,words)
excel2Pdf(filePath,excels)
ppt2Pdf(filePath,ppts)
print ("====================转换结束====================")
print ("\n====================程序结束====================")
os.system("pause")
五、运行
将代码复制到python编辑器之后,运行,会弹出如下对话框
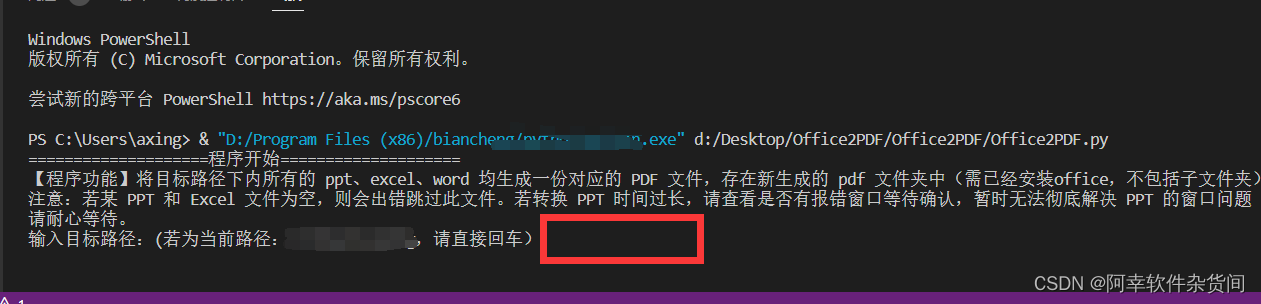
在我圈起来的地方输入需要转换的文件夹下的文件路径即可:D:\2(你自己根据实际情况来输入文件路径)
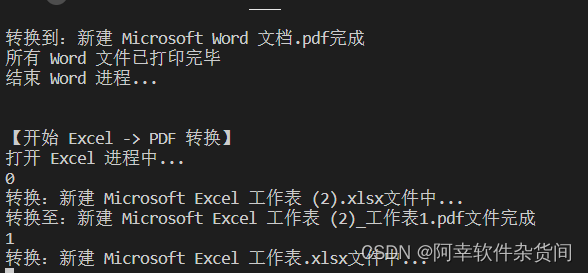
等待转换
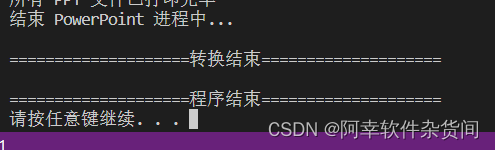
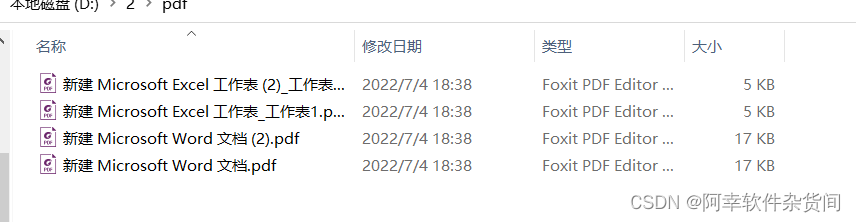
完成
六、将其打包为可执行的.exe文件
1、首先安装pyinstaller,使用安装命令:pip3 install pyinstaller,如下图所示。
2、然后将第五步的代码制作为.py文件,并且命名(我命名为:Office2PDF.py)
方法一:pyinstaller-F
我们来将这个.py的文件打包成一个exe,我们直接cmd切换到这个脚本的目录,执行命令:pyinstaller-F D:\Office2PDF.py,如下图所:
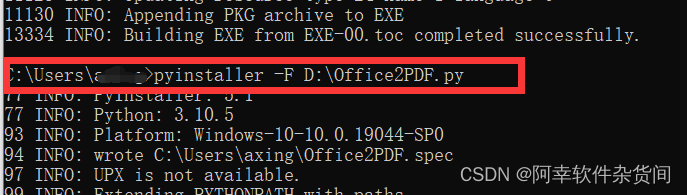
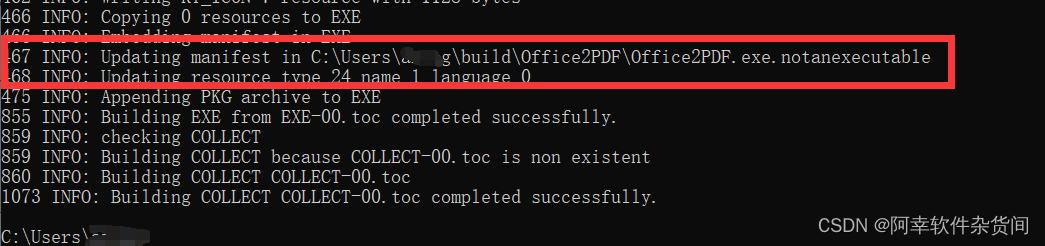
在这里介绍一下,D:\Office2PDF.py表示我要打包的文件路径,下面我圈起来的部分,表示打包为.exe路径


方法二:pyinstaller -D 打包
我们来将这个.py的文件打包成一个exe,我们直接cmd切换到这个脚本的目录,执行命令:pyinstaller -D D:\Office2PDF.py,如下图所:
在这里介绍一下,D:\Office2PDF.py表示我要打包的文件路径,下面我圈起来的部分,表示打包为.exe路径
七、程序获取
https://wws.lanzoul.com/ir6HZ07cwkah
密码的话,关注这个公众号,然后回复:提取码


















 619
619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









