







前言
融合模型的设计原理类似于集成学习,集成学习是将几个弱学习器集成得到强学习器,这里的弱学习器不是指准确率低的分类模型,而是子模型之间的多样性差异。在特征提取的过程中,两个深度学习模型的多样性差异指的就是模型在 结构、样本、超参数、特征提取等方面的不同而带来的随机性差异。子模型的多样性差异越大,融合后的模型在同样的数据条件下可以获得的表述信息就越多, 可判断类别的选择信息面就越广,泛化能力就越强[33~35]。模型融合是一种简单、 粗暴且高效率的方法,在 kaggle、天池等深度学习的国际比赛中可以看到,排名靠前的模型往往都是多模型的集成结果,这种方法逐渐变成了深度学习比赛中的 “大杀器”。在整个网络中,模型融合工作是由特征融合单元来完成的,特征融合单元将深度学习模型 1 和深度学习模型 2 学习到的特征信息的输出进行融合, 将两个不同模型提取到的不同特征进行结合,也就是将两个模型的学习思想融合 在一起,用以提高网络性能,达到分类效果最优值。
模型结构
我用ResNet和Xception为例,用keras实现一个模型融合的分类网络
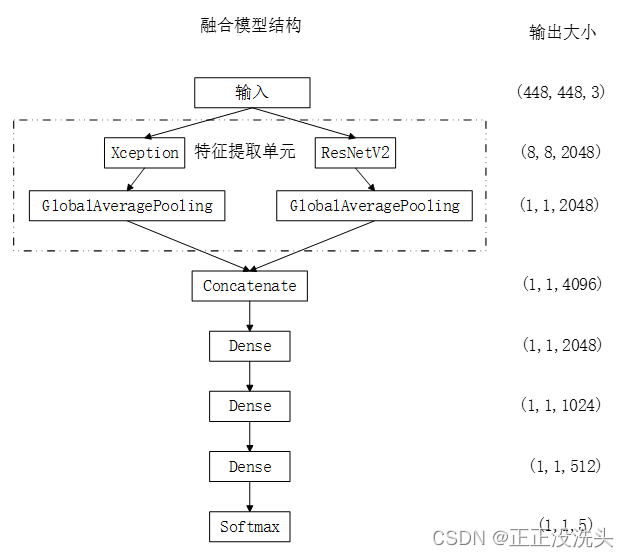
整体模型如图所示,图片分别输入到两个预训练模型上去,之后经过平均池化和特征融合进行常规全连接操作。
代码实现
def Model_Fusion(IMG_SHAPE=(448, 448, 3), class_num=5):
ResNet101V2_model = tf.keras.applications.ResNet101V2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
ResNet101V2_model.trainable = False
model_left = tf.keras.Sequential([
experimental.preprocessing.Rescaling(1. / 127.5, offset=-1),
ResNet101V2_model,
GlobalAveragePooling2D(),
])
Xception_model = tf.keras.applications.Xception(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
Xception_model.trainable = False
model_right = tf.keras.Sequential([
experimental.preprocessing.Rescaling(1. / 127.5, offset=-1),
Xception_model,
GlobalAveragePooling2D(),
])
inputs = Input(shape=IMG_SHAPE)
ResNet101V2 = model_left(inputs)
Xception = model_right(inputs)
# model concat
concatenated = concatenate([ResNet101V2, Xception])
x = Dense(2048, activation='relu')(concatenated)
x = Dense(1024, activation='relu')(x)
x = Dense(512, activation='relu')(x)
final_output = Dense(class_num, activation='softmax')(x)
model = Model(inputs=inputs, outputs=final_output)
model.summary()
# 模型训练的优化器为adam优化器,模型的损失函数为交叉熵损失函数
model.compile(optimizer=tf.keras.optimizers.Adam(
learning_rate=0.001,
beta_1=0.9,
beta_2=0.999,
epsilon=None,
decay=0.0,
amsgrad=False),
loss='categorical_crossentropy', metrics=['accuracy'])
return model
















 5213
5213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









