






1.Hadoop概述
什么是Hadoop?
- 是一个由 Apache 基金会所开发的分布式系统基础架构
- 主要解决海量数据的储存和海量数据的分析计算问题
- 广义上说,Hadoop 是一个更广泛的概念,Hadoop生态圈
Hadoop的优点
- 可扩展:不论是存储的可扩展还是计算的可扩展都是Hadoop的设计根本。
- 经济:框架可以运行在任何普通的PC上。
- 可靠:分布式文件系统的备份恢复机制以及MapReduce的任务监控保证了分布式处理的可靠性。
- 高效:分布式文件系统的高效数据交互实现以及MapReduce结合Local Data处理的模式,为高效处理海量的信息作了基础准备。
Hadoop的缺点
- 不适合低延时数据访问:毫秒级的存储数据
- 无法高效的对大量小文件进行存储:存储大量小文件的话,会占用NameNode 大量的内存来存储文件目录和块信息,NameNode的内存总是有限的;小文件的存储的寻址时间会超过读取时间,违反了HDFS的设计目标
- 不支持并发写入、文件随机修改:一个文件只能有一个写,不允许多个线程同时写;仅支持数据追加,不支持文件的随机修改
Hadoop的核心设计(两大核心设计)
- 1.X
HDFS分布式存储(NameNode:文件管理,DataNode:文件存储,Client:文件获取)
MapReduce分布式处理(Map:任务的分解,Reduce:结果的汇总)
- 2.X
HDFS分布式存储(数据存储)
Yarn(资源调度)
(MapReduce(计算框架))
常见框架
HDFS,MapReduce,HIVE,Sqoop,HBase
大数据不仅仅是“大”
至少PB级
比大更重要的是数据的复杂性
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LgjiiR2o-1653031923258)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1652162762405.png)]
大数据的4V特征
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6UDP0L5B-1653031923259)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1652162839342.png)]
Variety,海量数据有不同格式,第一种是结构化,我们常见的数据,还有半结据化网页数据,还有非结构化视频音频数据。而且这些数据化他们处理方式是比较大的。很多不同形式(文本、图像、视频、机器数据),无模式或者模式不明显,不连贯的语法或句义
Volume,量比较大,我们有一些用户化每秒就要进入很多数据,很多客户内部都有几批数据,还有下面淘宝都是几PB数据,所以PB化将是比较常态的情况。非结构化数据的超大规模和增长,占总数据量的80~90%,比结构化数据增长快10倍到50倍,是传统数据仓库的10倍到50倍
Velocity,因为数据化会存在时效性,需要快速处理,并得到结果出来。比如说,一些电商数据,今天的信息不处理没有结果化,将会影响到今天捕获很多商业决策。立竿见影而非事后见效
Value:大量的不相关信息,不经过处理则价值较低,属于价值密度底的数据海量数据分析非常复杂,使得过去靠单纯基于关系数据库BI已经不是太适合了。所以,可能需要新的创新。
2.linux的常用命令及作用
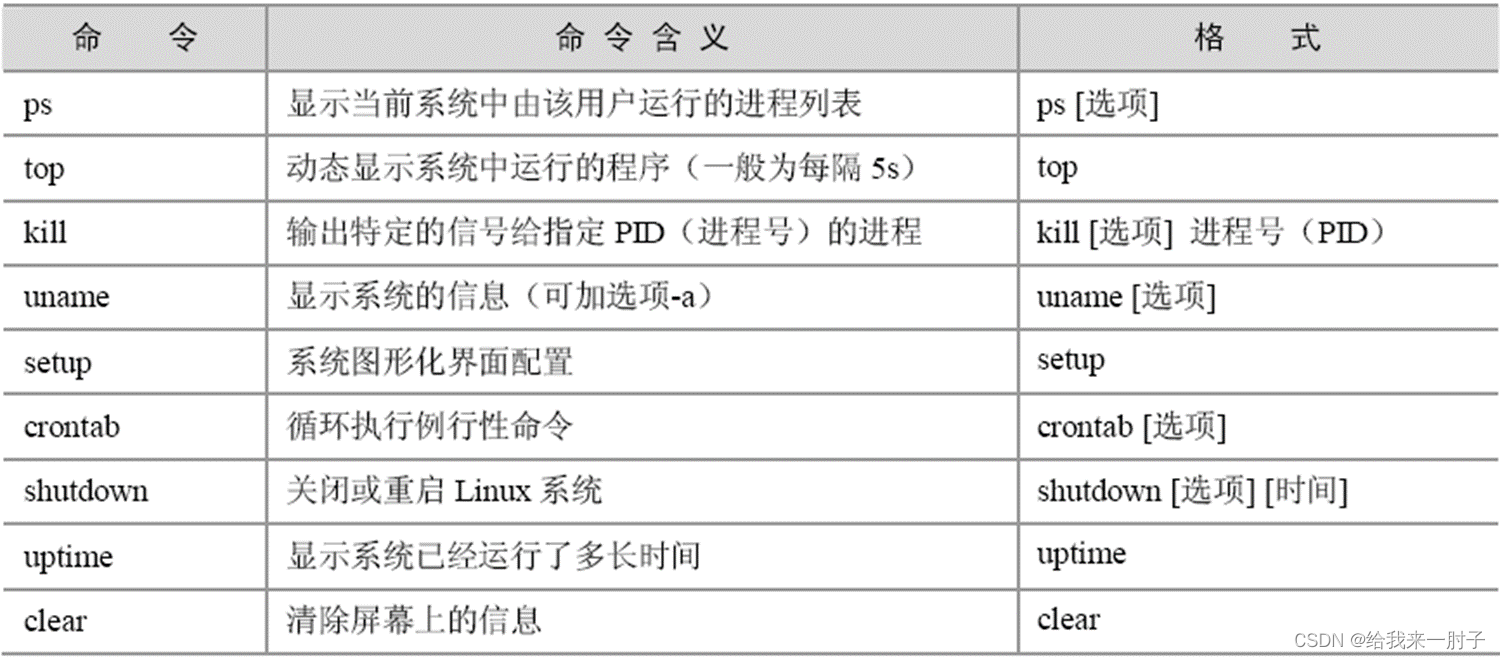
-
cd(切换路径)
- 格式:cd [路径](其中的路径为要改变的工作目录,可为相对路径或绝对路径)
- 可使用“cd –”可以回到前次工作目录。“./”代表当前目录,“…/”代表上级目录。
-
ls(列出目录内容)
- 格式:ls [选项] [文件](其中文件选项为指定查看指定文件的相关内容,若未指定文件,默认查看当前目录下的所有文件。)

- 格式:ls [选项] [文件](其中文件选项为指定查看指定文件的相关内容,若未指定文件,默认查看当前目录下的所有文件。)
-
mkdir(创建目录)
- 格式:mkdir [选项] 路径

-
cat(连接并显示指定文件的有关信息)
- 格式:cat[选项]文件 1 文件 2…(其中的文件 1、文件 2 为要显示的多个文件。)
- 常见参数

-
cp,mv,rv
(1)作用
① cp:将给出的文件或目录复制到另一文件或目录中。
② mv:为文件或目录改名或将文件由一个目录移入另一个目录中。 ③ rm:删除一个目录中的一个或多个文件或目录。(2)格式 ① cp:cp [选项] 源文件或目录 目标文件或目录。 ② mv:mv [选项] 源文件或目录 目标文件或目录。 ③ rm:rm [选项] 文件或目录。(3)常见参数
cp:

mv:

rm:

-
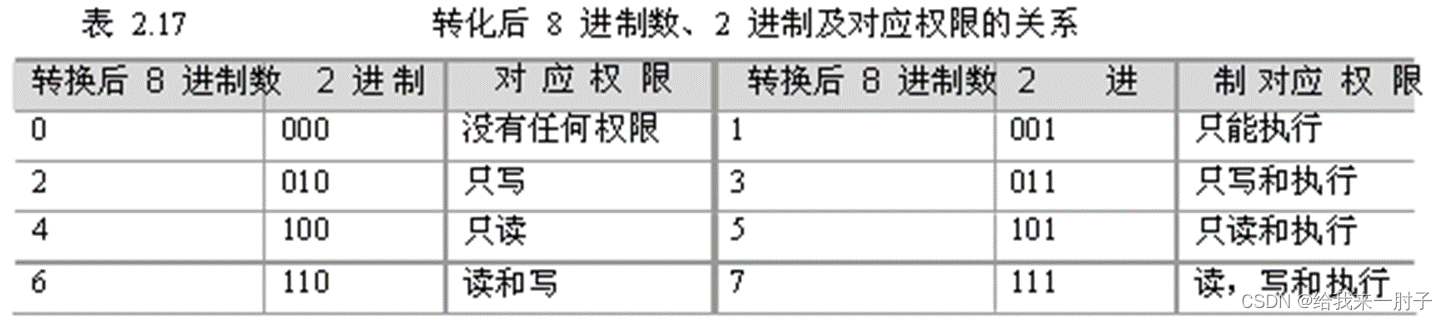
chmod(改变文件访问权限)
-
格式
chmod 可使用符号标记进行更改和八进制数指定更改两种方式,因此它的格式也有两种不同的形式。
① 符号标记:chmod [选项]…符号权限[符号权限]…文件(其中的符号权限可以指定为多个,也就是说,可以指定多个用户级别的权限,但它们中间要用逗号分开表示,若没有显示指出则表示不作更改。)
② 八进制数:chmod [选项] …八进制权限 文件…(其中的八进制权限是指要更改后的文件权限。)
-
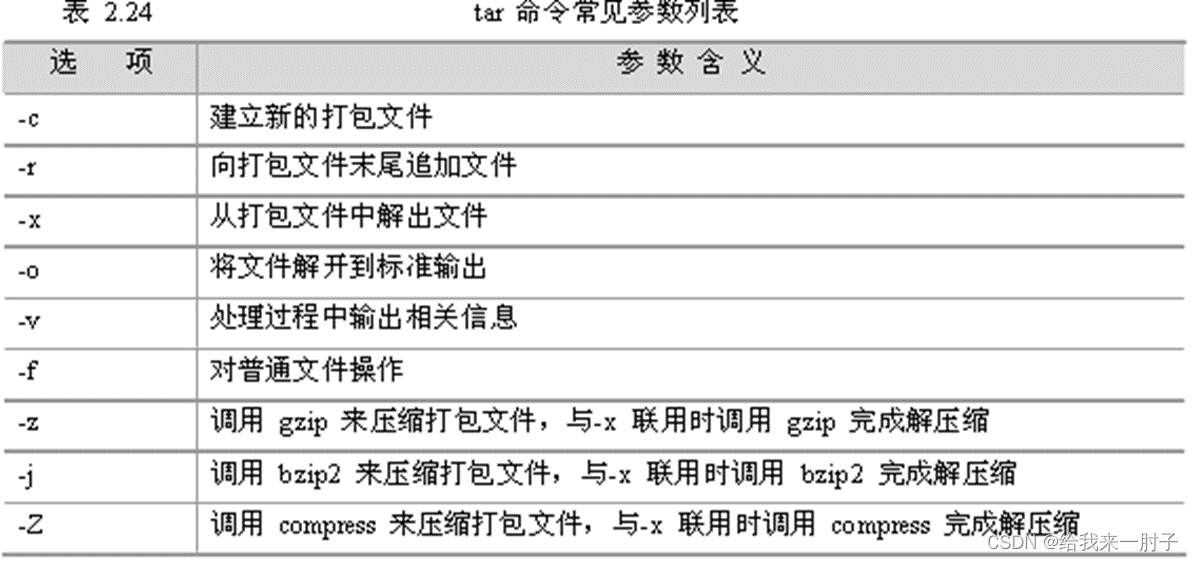
-
tar(对文件目录进行打包或解压)
- 格式:tar [选项] 文件 [路径]
- eg:

3.分布式文件系统HDFS
-
HDFS概述
-
HDFS的定义、特点、数据块大小
定义:是个文件系统,用于存储文件,通过目录树来定位文件。
特点:
-
优点:
- 高容错性----副本机制
- 适合处理大数据
- 可构建在廉价的机器上
-
缺点:
- 不适合低时延的数据访问;
- 无法高效的对大量小文件进行存储;
- 不支持并发写入、文件随机修改:一个文件只能有一个写,不允许多个线程同时写入;只支持数据追加,不支持文件的随机修改
数据块大小:默认大小在Hadoop.2x版本中是128M,老版本中是64M(HDFS块大小的设置主要取决与磁盘的传输效率,可以通过配置参数([hdfs-site.xml]文件中的dfs.blocksize)来设置)
-
-
NameNode的定义和作用
定义:是整个文件系统的管理节点
作用:
- 管理HDFS的名称空间
- 配置副本策略
- 管理数据块的映射信息
- 处理客户端的读写请求
-
DataNode的定义和作用
定义:是一个在HDFS实例中单独机器上运行的软件节点。
作用: 实际存储数据、执行数据块的读写并汇报存储信息给NameNode。
-
SecondaryNameNode的定义和作用
定义:
作用:
- 辅助NameNode
- 紧急情况下可辅助恢复NameNode。
-
HDFS的架构
•主从结构( HDFS是Master和Slave的主从结构。 )
–主节点,只有一个: namenode
–从节点,有很多个: datanodes
–
•namenode负责:
–接收用户操作请求
–维护文件系统的目录结构
–管理文件与block之间关系,block与datanode之间关系
•
•datanode负责:
–存储文件
–文件被分成block存储在磁盘上
–为保证数据安全,文件会有多个副本
-
HDFS的体系结构图
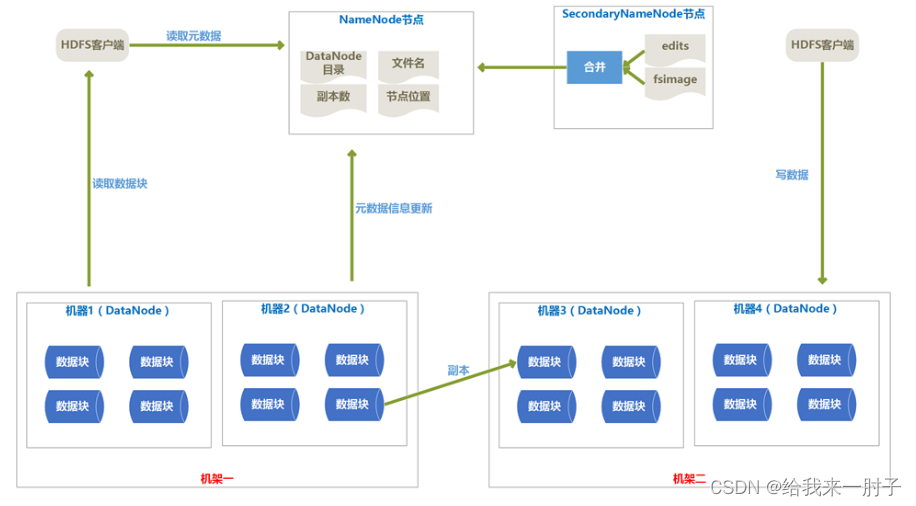
-
HDFS的体系介绍
1.HDFS由Client、NameNode、DataNode、SecondaryNameNode组成。
2.Client提供了文件系统的调用接口。
3.NameNode由fs image(HDFS元数据镜像文件)和edit log(HDFS文件改动日志)组成,NameNode在内存中保存着每个文件和数据块的引用关系。NameNode中的引用关系不存在硬盘中而是内存里,每次都是HDFS启动时重新构造出来的。
4.SecondaryNameNode的任务有两个:
1.定期合并fsimage和editlog,并传输给NameNode。
2.在NameNode出现问题时辅助NameNode恢复。
3.但不提供热备功能(容易误解)
5.一般是一个机器上安装一个DataNode,一个DataNode上又分为很多很多数据块(block)。数据块是HDFS中最小的寻址单位,一般一个块的大小为128M,不像单机的文件系统,少于一个块大小的文件不会占用一整块的空间。
6.设置块比较大的原因是减少寻址开销,但是块设置的也不能过大,因为一个Map任务处理一个块的数据,如果块设置的太大,Map任务处理的数据量就会过大,会导致效率并不高。
7.DataNode会通过心跳定时(默认3秒)向NameNode发送所存储的文件块信息。
8.HDFS的副本存放规则:默认的副本系数是3,一个副本存在本地机架的本机器上,第二个副本存储在本地机架的其他机器上,第三个副本存在其他机架的一个节点上。这样减少了写操作的网络数据传输,提高了写操作的效率;另一方面,机架的错误率远比节点的错误率低,所以不影响数据的可靠性。
-
-
HDFS的Shell操作
注释 命令 启动集群命令 start-dfs.sh
start-yarn.sh帮助 -help hadoop fs -help 显示目录信息 -ls
递归查看 -lsrhadoop fs -ls / 在HDFS上创建目录(递归创建)-mkdir -p /path hadoop fs -mkdir -p /… 本地剪切粘贴(移动)到hdfs hadoop fs -moveFromLocal 源文件path 追加文件到已存在的文件末尾 hadoop fs -appendToFile 源文件 目标文件 显示文件内容 hadoop fs -cat 文件 修改权限 hadoop fs -chmod 777 /log.txt 从本地文件系统中拷贝到HDFS
-copyFromLocal 等同于-puthadoop fs -copyFromLocal(put) 本地文件 HDFS 路径 从HDFS的路径拷贝到另一个路径 hadoop fs -cp 原路径文件 拷贝路径文件 从HDFS拷贝到本地
copyToLocal 等同于 -gethadoop fs -copyToLocal(get) HDFS文件 本地路径 在HDFS中移动文件 -mv hadoop fs -mv 文件 目标路径 合并下载多个文件
如HDFS/logs目录下有多个log文件hadoop fs -getmerge/log/*./merge.txt 显示文件的末尾 hadoop fs -tail /hadoop1/abc.log 删除文件或是文件夹 -rm
删除空目录 -rmdirhadoop fs -rm 文件(文件夹)
hadoop fs -rmdir 空目录统计文件夹的大小信息 -du hadoop fs -du 文件夹 设置HDFS中副本数量 hadoop fs -setrep 8 /pf/spa.txt
----副本数量设置为8,这里副本数为最大值 -
JAVA接口
-
HDFS的Java访问接口–FileSystem
•写文件 create
•读取文件 open
•删除文件 delete
•创建目录 mkdirs
•删除文件或目录 delete
•列出目录的内容 listStatus
•显示文件系统的目录和文件的元数据信息 getFileStatus
-
n-1.简答题
hadoop概述
什么是Hadoop:
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。( HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。 MapReduce是一个计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。)
Hadoop的特点:
优点:
可扩展:不论是存储的可扩展还是计算的可扩展都是Hadoop的设计根本。
经济:框架可以运行在任何普通的PC上。
可靠:分布式文件系统的备份恢复机制以及MapReduce的任务监控保证了分布式处理的可靠性。
高效:分布式文件系统的高效数据交互实现以及MapReduce结合Local Data处理的模式,为高效处理海量的信息作了基础准备。
缺点:
不适合低延时数据访问
无法高效的对大量小文件进行存储
不支持并发写入、文件随机修改
HDFS
hdfs的定义、特点、数据块大小:
定义:是个文件系统,用于存储文件,通过目录树来定位文件。
特点:
优点:高容错性、适合处理大数据、
缺点:不适合低时延的数据访问;
无法高效的对大量小文件进行存储;
不支持并发写入、文件随机修改
数据块大小:默认大小在Hadoop.2x版本中是128M,老版本中是64M
nameNode、dataNode、secondaryNode的定义和作用:见3.分布式文件系统hdfs
Yarn组件
Yarn是另一种分布式的资源管理系统,是从MRv1(MapReduce Version1.0)中抽取公共模块(主要是和hdfs交互的内容),并进行优化后形成的,yarn不仅支持mr这一种数据处理框架,还支持如spark,storm等数据处理框架。
MapReduce on Yarn (了解即可)
ResourceManager (整个集群仅一个,负责集群资源的统一管理和调度)
处理客户端请求
启动/监控ApplicationMaster
监控NodeManager
资源分配与调度
NodeManager(整个集群有多个,负责单节点资源管理和使用)
单个节点上的资源管理
处理来自ResourceManager的命令
处理来自ApplicationMaster的命令
ApplicationMaster(每个应用程序都有一个,负责应用程序的管理)
数据切分
为应用程序申请资源,并分配给内部任务
任务监控与容错
Container(对运行环境的抽象)
描述一系列信息:
- 任务运行资源(节点、内存、CPU)
- 任务启动命令
- 任务运行环境
HBase
什么是HBase:
HBase是Apache的顶级开源项目
Hbase是bigtable的开源山寨版本。是建立的hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。
它是典型的nosql数据库,仅能通过主键**(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)**。主要用来存储非结构化和半结构化的松散数据。
列存储的优缺点:
行式存储 列式存储 优点 Ø 数据被保存在一起 Ø INSERT/UPDATE容易 Ø 查询时只有涉及到的列会被读取 Ø 投影(projection)很高效 Ø 任何列都能作为索引 缺点 Ø 选择(Selection)时即使只涉及某几列,所有数据也都会被读取 Ø 选择完成时,被选择的列要重新组装 Ø INSERT/UPDATE比较麻烦 HBase Shell 命令
名称 命令表达式 eg 释义 创建表 create ‘表名称’, ‘列族名称1’,‘列族名称2’,‘列族名称N’ create’users’,‘address’,‘info’ 表users,有两个列族address,info 添加记录 put ‘表名称’, ‘行键’, ‘列名称:’, ‘值’ 查看记录 get ‘表名称’, ‘行键’ get ‘users’,‘xiaoming’
get ‘users’,‘xiaoming’,‘info’
get ‘users’,‘xiaoming’,‘inf
o:age’取得一个id的所有数据
获取一个id,一个列族的所有数据
获取一个id,一个列族中一个列的所有数据查看表中的记录总数 count ‘表名称’ 删除记录 delete ‘表名’ ,‘行键’ , ‘列名称’ 删除一张表 先要屏蔽该表,才能对该表进行删除,第一步 disable ‘表名称’ 第二步 drop ‘表名称’ 查看所有记录 scan “表名称” 查看某个表某个列中所有数据 scan “表名称” , {COLUMNS=>‘列族名称:列名称’} 更新记录 就是重写一遍进行覆盖 NoSQL
- 概念: 泛指非关系型的数据库 ,NoSQL仅仅是一个概念,泛指非关系型的数据库,区别于关系数据库,它们不保证关系数据的ACID特性。
- (了解即可)NoSQL有如下优点:易扩展,NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。无形之间也在架构的层面上带来了可扩展的能力。大数据量,高性能,NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。
n. 编程题
map函数:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NSWFLiBw-1653031923265)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1652928442691.png)]](https://i-blog.csdnimg.cn/blog_migrate/7cc31ec6477b159f150b2a8356645136.png)
reduce函数:

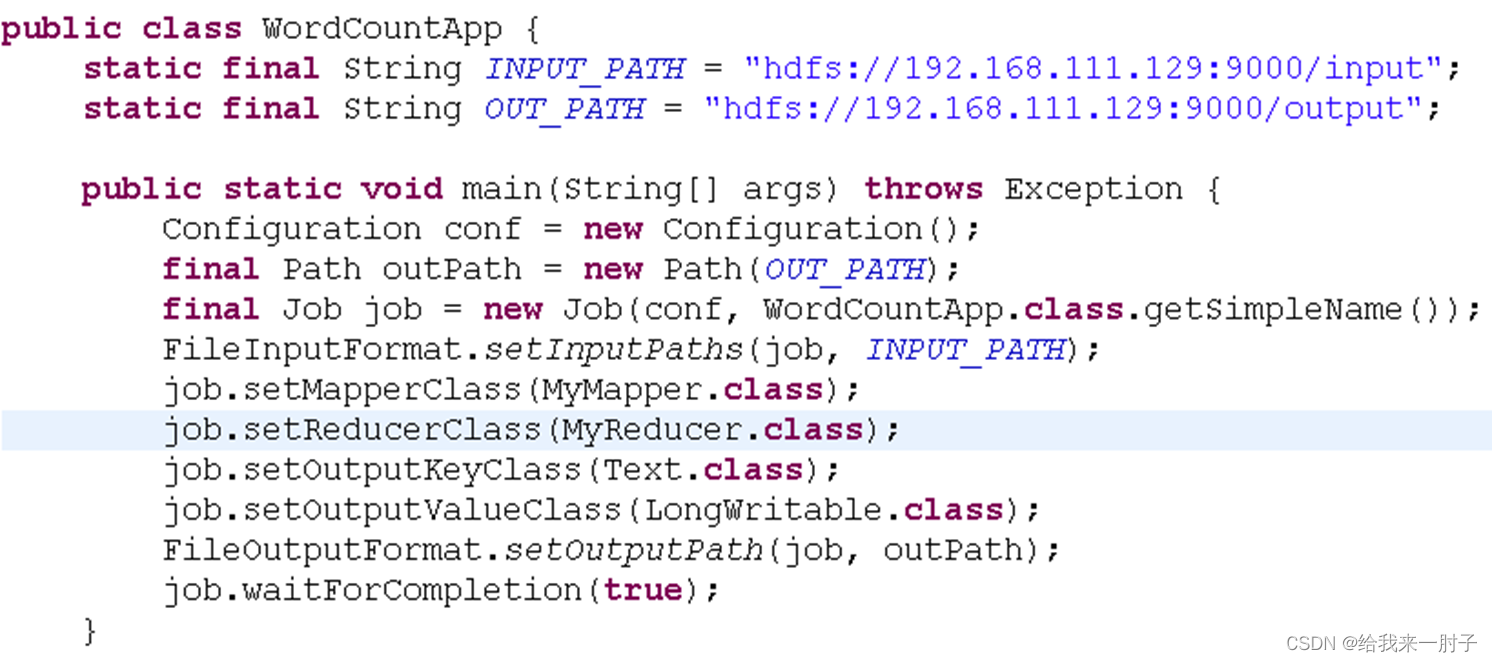
main函数:

















 380
380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









