







实战保险花销预测:从数据探索到模型优化
在数据分析和机器学习领域,预测保险花销是一个经典的回归问题。本文将详细介绍如何通过 Python 和机器学习算法,从数据探索到模型优化,逐步实现保险花销的预测。我们将使用一个公开的保险数据集,通过特征工程、模型选择和评估,最终构建一个准确的预测模型。
数据集简介
本次使用的保险数据集包含以下字段:
-
age:被保险人的年龄 -
sex:被保险人的性别(male/female) -
bmi:体质指数(Body Mass Index) -
children:子女数量 -
smoker:是否吸烟(yes/no) -
region:居住地区(northwest, southeast, northeast, southwest) -
charges:保险花销(目标变量)
以下是数据集的前几行示例:
| age | sex | bmi | children | smoker | region | charges |
|---|---|---|---|---|---|---|
| 19 | female | 27.900 | 0 | yes | southwest | 16884.92400 |
| 18 | male | 33.770 | 1 | no | southeast | 1725.55230 |
| 28 | male | 33.000 | 3 | no | southeast | 4449.46200 |
| 33 | male | 22.705 | 0 | no | northwest | 21984.47061 |
| 32 | male | 28.880 | 0 | no | northwest | 3866.85520 |
数据探索性分析(EDA)
在进行模型训练之前,我们需要对数据进行初步探索,了解各特征与目标变量之间的关系。
目标变量分布
首先,我们绘制 charges 的直方图,观察其分布情况:
Python复制
import matplotlib.pyplot as plt
plt.hist(data['charges'], bins=20)
plt.title('Distribution of Charges')
plt.xlabel('Charges')
plt.ylabel('Frequency')
plt.show()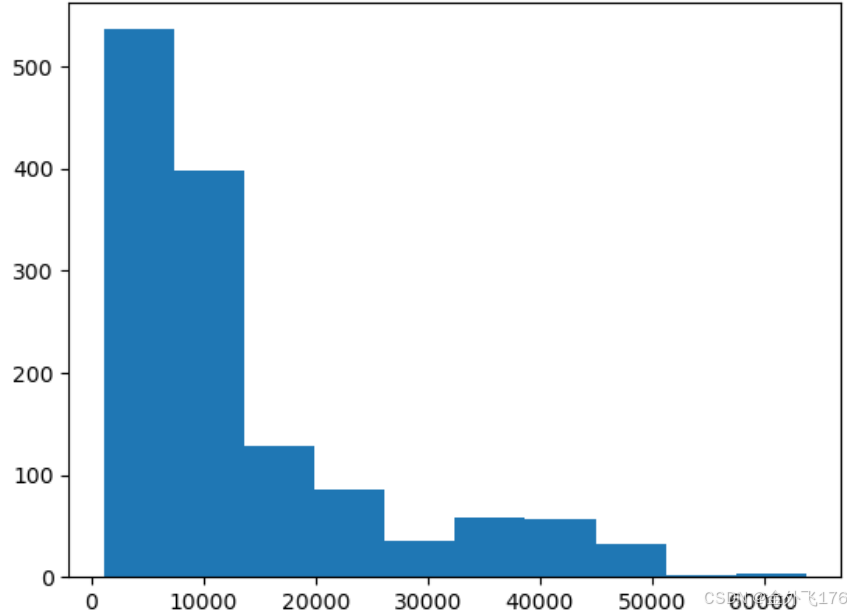
从图中可以看出,charges 的分布明显右偏。为了使数据更接近正态分布,我们对其进行对数变换:
Python复制
plt.hist(np.log(data['charges']), bins=20)
plt.title('Log-transformed Distribution of Charges')
plt.xlabel('Log(Charges)')
plt.ylabel('Frequency')
plt.show()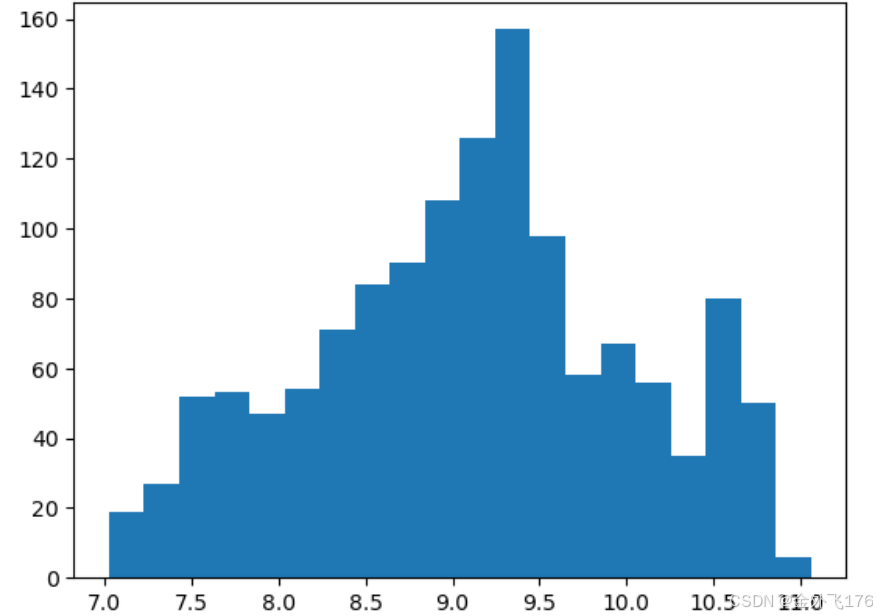
对数变换后的数据分布更加均匀,这有助于后续的回归分析。
特征与目标变量的关系
接下来,我们通过核密度图(KDE)分析不同特征对保险花销的影响。
性别与保险花销
Python复制
import seaborn as sns
sns.kdeplot(data.loc[data.sex == 'male', 'charges'], fill=True, label='male')
sns.kdeplot(data.loc[data.sex == 'female', 'charges'], fill=True, label='female')
plt.legend()
plt.title('Charges by Gender')
plt.xlabel('Charges')
plt.ylabel('Density')
plt.show()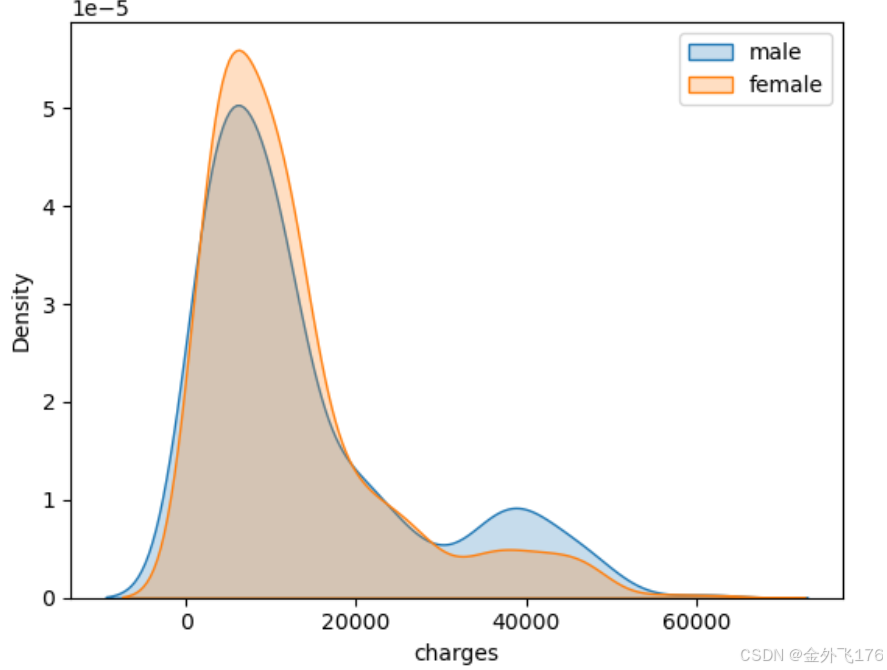
从图中可以看出,男性和女性的保险花销分布差异不大。
地区与保险花销
Python复制
sns.kdeplot(data.loc[data.region == 'northwest', 'charges'], fill=True, label='northwest')
sns.kdeplot(data.loc[data.region == 'southwest', 'charges'], fill=True, label='southwest')
sns.kdeplot(data.loc[data.region == 'northeast', 'charges'], fill=True, label='northeast')
sns.kdeplot(data.loc[data.region == 'southeast', 'charges'], fill=True, label='southeast')
plt.legend()
plt.title('Charges by Region')
plt.xlabel('Charges')
plt.ylabel('Density')
plt.show()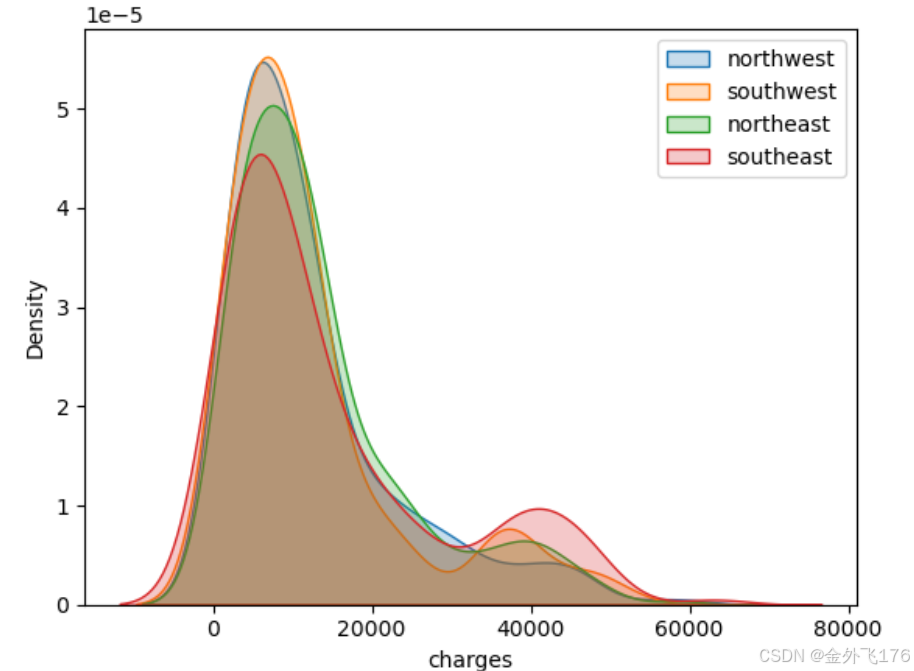
不同地区的保险花销分布也较为接近,说明地区对保险花销的影响较小。
吸烟状态与保险花销
Python复制
sns.kdeplot(data.loc[data.smoker == 'yes', 'charges'], fill=True, label='smoker yes')
sns.kdeplot(data.loc[data.smoker == 'no', 'charges'], fill=True, label='smoker no')
plt.legend()
plt.title('Charges by Smoking Status')
plt.xlabel('Charges')
plt.ylabel('Density')
plt.show()
从图中可以看出,吸烟者的保险花销明显高于非吸烟者,这表明吸烟状态是一个重要的影响因素。
特征工程
在机器学习中,特征工程是提高模型性能的关键步骤。我们将对数据进行清理和转换,以提取更有用的特征。
去除不重要特征
通过 EDA 分析,我们发现 region 和 sex 对保险花销的影响较小,因此可以将其从数据集中移除:
Python复制
data = data.drop(['region', 'sex'], axis=1)二值化处理
我们将 bmi 和 children 进行二值化处理,以简化模型:
Python复制
def greater(df, bmi, num_child):
df['bmi'] = 'over' if df['bmi'] >= bmi else 'under'
df['children'] = 'no' if df['children'] == num_child else 'yes'
return df
data = data.apply(greater, axis=1, args=(30, 0))这样,bmi 被分为“超过 30”和“不超过 30”,children 被分为“有”和“无”。
独热编码
由于 bmi 和 children 是分类变量,我们需要对其进行独热编码(One-Hot Encoding):
Python复制
data = pd.get_dummies(data)独热编码后的数据如下所示:
| age | charges | bmi_over | bmi_under | children_no | children_yes | smoker_no | smoker_yes |
|---|---|---|---|---|---|---|---|
| 19 | 16884.92 | False | True | True | False | False | True |
| 18 | 1725.55 | True | False | False | True | True | False |
模型训练与评估
在完成特征工程后,我们将数据分为训练集和测试集,并对模型进行训练和评估。
数据分割与标准化
Python复制
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
x = data.drop('charges', axis=1)
y = data['charges']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
scaler = StandardScaler().fit(x_train)
x_train_scaled = scaler.transform(x_train)
x_test_scaled = scaler.transform(x_test)多项式特征
为了捕捉特征之间的非线性关系,我们对特征进行多项式升维:
Python复制
from sklearn.preprocessing import PolynomialFeatures
poly_features = PolynomialFeatures(degree=2, include_bias=False)
x_train_scaled = poly_features.fit_transform(x_train_scaled)
x_test_scaled = poly_features.transform(x_test_scaled)线性回归模型
我们首先使用线性回归模型进行训练:
Python复制
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
reg = LinearRegression()
reg.fit(x_train_scaled, np.log1p(y_train))
y_predict_linear = reg.predict(x_test_scaled)
log_rmse_train = np.sqrt(mean_squared_error(np.log1p(y_train), reg.predict(x_train_scaled)))
log_rmse_test = np.sqrt(mean_squared_error(np.log1p(y_test), y_predict_linear))
rmse_train = np.sqrt(mean_squared_error(y_train, np.exp(reg.predict(x_train_scaled))))
rmse_test = np.sqrt(mean_squared_error(y_test, np.exp(y_predict_linear)))
print(f"Log RMSE (Train): {log_rmse_train}")
print(f"Log RMSE (Test): {log_rmse_test}")
print(f"RMSE (Train): {rmse_train}")
print(f"RMSE (Test): {rmse_test}")评估结果如下:
-
Log RMSE (Train): 0.3604
-
Log RMSE (Test): 0.4246
-
RMSE (Train): 4285.55
-
RMSE (Test): 5374.22
岭回归模型
为了防止过拟合,我们尝试使用岭回归(Ridge Regression):
Python复制
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=0.4)
ridge.fit(x_train_scaled, np.log1p(y_train))
y_predict_ridge = ridge.predict(x_test_scaled)
log_rmse_train = np.sqrt(mean_squared_error(np.log1p(y_train), ridge.predict(x_train_scaled)))
log_rmse_test = np.sqrt(mean_squared_error(np.log1p(y_test), y_predict_ridge))
rmse_train = np.sqrt(mean_squared_error(y_train, np.exp(ridge.predict(x_train_scaled))))
rmse_test = np.sqrt(mean_squared_error(y_test, np.exp(y_predict_ridge)))
print(f"Log RMSE (Train): {log_rmse_train}")
print(f"Log RMSE (Test): {log_rmse_test}")
print(f"RMSE (Train): {rmse_train}")
print(f"RMSE (Test): {rmse_test}")评估结果如下:
-
Log RMSE (Train): 0.3604
-
Log RMSE (Test): 0.4245
-
RMSE (Train): 4285.56
-
RMSE (Test): 5374.61
梯度提升回归模型
最后,我们尝试使用梯度提升回归(Gradient Boosting Regressor):
Python复制
from sklearn.ensemble import GradientBoostingRegressor
booster = GradientBoostingRegressor()
booster.fit(x_train_scaled, np.log1p(y_train))
y_predict_boost = booster.predict(x_test_scaled)
log_rmse_train = np.sqrt(mean_squared_error(np.log1p(y_train), booster.predict(x_train_scaled)))
log_rmse_test = np.sqrt(mean_squared_error(np.log1p(y_test), y_predict_boost))
rmse_train = np.sqrt(mean_squared_error(y_train, np.exp(booster.predict(x_train_scaled))))
rmse_test = np.sqrt(mean_squared_error(y_test, np.exp(y_predict_boost)))
print(f"Log RMSE (Train): {log_rmse_train}")
print(f"Log RMSE (Test): {log_rmse_test}")
print(f"RMSE (Train): {rmse_train}")
print(f"RMSE (Test): {rmse_test}")评估结果如下:
-
Log RMSE (Train): 0.3428
-
Log RMSE (Test): 0.4245
-
RMSE (Train): 3942.97
-
RMSE (Test): 5244.94
结论
通过对比线性回归、岭回归和梯度提升回归的评估结果,我们发现:
-
梯度提升回归在训练集上的表现略优于其他模型,但测试集上的表现与线性回归和岭回归相近。
-
误差仍在 5000 左右,说明模型仍有改进空间。我们可以尝试更复杂的特征工程或选择更先进的算法来进一步提高预测精度。
在实际应用中,模型的选择和优化需要根据具体问题和数据进行调整。通过本文的介绍,相信你已经对如何进行保险花销预测有了更深入的了解。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









