







多项式升维:解决欠拟合问题的利器
在机器学习中,线性回归模型虽然简单高效,但在处理非线性数据时往往力不从心。为了提升模型的拟合能力,多项式升维成为一种重要的数据预处理技术。本文将通过一个具体的例子,详细介绍如何使用scikit-learn库实现多项式升维,并对比不同阶数多项式回归的效果。
一、多项式升维的原理
1.1 什么是多项式升维?
多项式升维是一种通过增加特征的高次项来提升模型拟合能力的技术。例如,对于一个一元线性回归模型 y=θ0+θ1x,如果数据呈现非线性关系,我们可以将特征 x 升维为多项式特征 x,x2,x3,…,xn,从而将模型转换为多项式回归模型:
y=θ0+θ1x+θ2x2+⋯+θnxn
1.2 为什么需要多项式升维?
多项式升维可以将原本非线性的数据转换为线性可分的数据,从而让线性回归模型能够更好地拟合复杂的数据关系。然而,需要注意的是,多项式阶数越高,模型的复杂度也会越高,可能导致过拟合。
二、多项式升维的实现
2.1 数据准备
我们首先生成一些模拟数据,这些数据呈现明显的非线性关系:
Python复制
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 生成模拟数据
np.random.seed(12)
m = 100
x = 6 * np.random.rand(m, 1) - 3 # 数据范围 -3 到 3
y = 2 + x + 0.5 * x**2 + np.random.randn(m, 1) # 真实关系为 y = 2 + x + 0.5x^2 + 噪声
# 划分训练集和测试集
x_train = x[:80]
y_train = y[:80]
x_test = x[80:]
y_test = y[80:]2.2 使用PolynomialFeatures进行多项式升维
scikit-learn提供了PolynomialFeatures类,可以方便地将特征升维为多项式特征:
Python复制
# 定义不同阶数的多项式
degrees = [1, 2, 10]
# 创建字典,用于绘图
d = {1: 'g-', 2: 'r+', 10: 'y*'}
# 遍历不同阶数的多项式
for i in degrees:
poly_features = PolynomialFeatures(degree=i, include_bias=True) # include_bias=True 包括截距项
x_poly_train = poly_features.fit_transform(x_train) # 训练集多项式升维
x_poly_test = poly_features.transform(x_test) # 测试集多项式升维
# 打印升维后的特征
print(f"阶数为 {i} 时,训练集第一个样本的特征:")
print(x_poly_train[0])
print(f"升维前特征维度:{x_train.shape[1]},升维后特征维度:{x_poly_train.shape[1]}\n")
# 训练线性回归模型
linear_reg = LinearRegression(fit_intercept=False) # fit_intercept=False,因为已经包括了截距项
linear_reg.fit(x_poly_train, y_train)
# 预测训练集和测试集
y_train_predict = linear_reg.predict(x_poly_train)
y_test_predict = linear_reg.predict(x_poly_test)
# 计算MSE
train_mse = mean_squared_error(y_train, y_train_predict)
test_mse = mean_squared_error(y_test, y_test_predict)
print(f"阶数为 {i} 时,训练集MSE:{train_mse:.4f},测试集MSE:{test_mse:.4f}\n")
# 绘制拟合结果
plt.plot(x_train, y_train_predict, d[i], label=f"Degree {i}")2.3 可视化结果
我们将不同阶数的多项式回归结果可视化,以便直观比较它们的拟合效果:
Python复制
# 绘制原始数据点
plt.plot(x, y, 'b.', label="原始数据")
# 设置图例和标题
plt.xlabel("x")
plt.ylabel("y")
plt.title("多项式回归拟合效果")
plt.legend()
plt.show()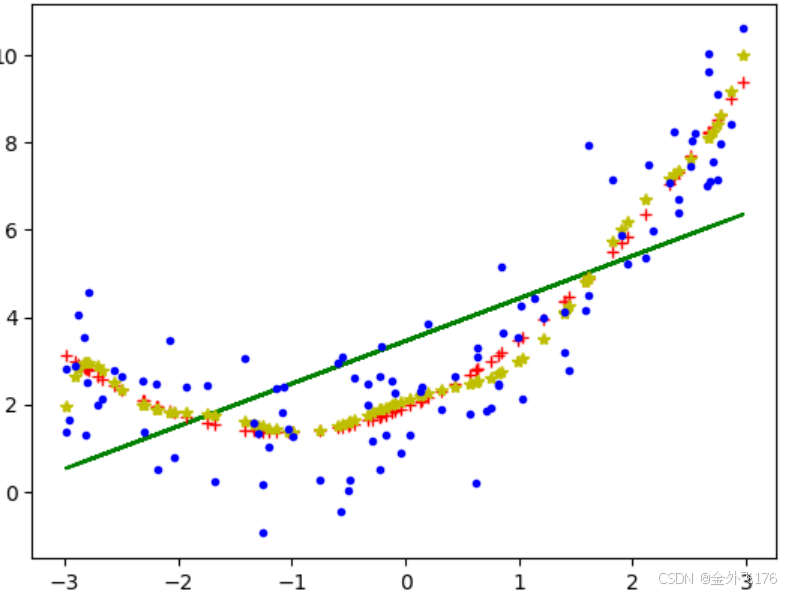
三、结果分析
3.1 不同阶数的拟合效果
通过运行上述代码,我们可以得到以下结果:
-
阶数为1时:训练集MSE较大,测试集MSE也较大,模型欠拟合。
-
阶数为2时:训练集MSE较小,测试集MSE也较小,模型拟合适度。
-
阶数为10时:训练集MSE非常小,但测试集MSE较大,模型过拟合。
3.2 选择合适的阶数
从实验结果可以看出,多项式的阶数对模型的拟合效果有显著影响。选择合适的阶数是关键:
-
欠拟合:模型复杂度不足,无法捕捉数据的真实关系。
-
过拟合:模型复杂度过高,虽然在训练集上表现很好,但在测试集上表现较差。
在实际应用中,可以通过交叉验证等方法选择最优的多项式阶数。
四、总结
本文通过一个具体的例子,详细介绍了多项式升维的原理和实现方法。多项式升维是一种强大的数据预处理技术,可以显著提升线性回归模型的拟合能力。然而,需要注意的是,多项式阶数的选择至关重要,过高或过低的阶数都可能导致模型性能不佳。
希望本文对你理解多项式升维及其在Python中的实现有所帮助!如果你有任何问题或建议,欢迎在评论区留言。
代码详细注释:https://gitee.com/jinwaifei/artificial-intelligence-project/tree/master/%E5%8D%87%E7%BB%B4
如果你对这篇博客有任何修改意见,或者希望我补充更多内容,请随时告诉我!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









