







数据标准化:从手动实现到使用 Scikit-Learn
在机器学习和数据分析中,数据预处理是一个至关重要的步骤,而数据标准化是其中的一种常用技术。本文将通过一个简单的例子,展示如何手动实现数据标准化,以及如何使用 Scikit-Learn 的 StandardScaler 来完成这一任务。我们将探讨这两种方法的实现细节、区别以及在实际应用中的注意事项。
1. 数据标准化简介
数据标准化(Z-score normalization)是一种常见的数据预处理方法,它通过将数据转换为均值为 0、标准差为 1 的分布,来消除不同特征之间的量纲差异和数值范围差异。标准化后的数据公式为:
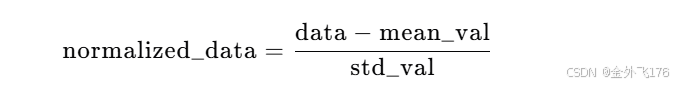
其中,mean_val 是数据的均值,std_val 是数据的标准差。
2. 手动实现数据标准化
假设我们有一个随机生成的数据集 x,我们可以通过以下步骤手动实现数据标准化:
Python复制
import numpy as np
# 生成随机数据
x = np.random.uniform(0, 4, (7, 5))
# 手动实现标准化函数
def standard_normalization(data):
mean_val = np.mean(data) # 计算均值
std_val = np.std(data) # 计算标准差
normalized_data = (data - mean_val) / std_val # 应用标准化公式
return normalized_data
# 对数据进行标准化
n_x = standard_normalization(x)在上述代码中,我们首先生成了一个 7 行 5 列的随机数组 x,数据范围在 0 到 4 之间。然后,我们定义了一个函数 standard_normalization,它计算整个数据集的均值和标准差,并对每个元素进行标准化处理。
3. 使用 Scikit-Learn 的 StandardScaler
虽然手动实现数据标准化可以帮助我们理解其背后的数学原理,但在实际应用中,我们通常会使用现成的库来完成这一任务。Scikit-Learn 提供了一个非常方便的工具 StandardScaler,它可以自动对数据进行标准化处理:
Python复制
from sklearn.preprocessing import StandardScaler
# 使用 StandardScaler
scalar = StandardScaler()
ns_x = scalar.fit_transform(x)StandardScaler 会自动按列(特征)计算均值和标准差,并对每一列进行标准化。这种方法更符合机器学习中对特征的标准化处理方式。
4. 打印结果并对比
为了验证手动实现和 StandardScaler 的结果是否一致,我们可以打印原始数据和标准化后的数据:
Python复制
print("原始数据:")
print(x)
print("\n手动标准化后的数据:")
print(n_x)
print("\n使用 StandardScaler 标准化后的数据:")
print(ns_x)从输出结果可以看出,手动标准化和 StandardScaler 的结果一致,但 StandardScaler 是按列标准化的。
5. 关键点和注意事项
5.1 标准化的作用
标准化可以将数据转换为均值为 0、标准差为 1 的分布,有助于提高模型的收敛速度和性能。在机器学习中,标准化通常是对每个特征(列)单独进行的。
5.2 手动实现与 StandardScaler 的区别
-
手动实现:基于整个数据集的全局均值和标准差进行标准化。
-
StandardScaler:按列(特征)计算均值和标准差,并对每一列进行标准化。
在实际应用中,推荐使用 StandardScaler,因为它更符合机器学习的处理方式。
5.3 数据集的划分
在机器学习中,数据集通常分为训练集和测试集。在测试阶段,应该使用训练集的均值和标准差对测试集进行标准化处理,而不是重新计算测试集的均值和标准差。这是因为测试集的均值和标准差在模型训练时是未知的。
6. 总结
本文通过一个简单的例子,展示了如何手动实现数据标准化,以及如何使用 Scikit-Learn 的 StandardScaler 来完成这一任务。我们探讨了这两种方法的实现细节、区别以及在实际应用中的注意事项。标准化是数据预处理中的一个重要步骤,有助于提高模型的性能和稳定性。在实际应用中,建议使用 StandardScaler 进行标准化处理,并注意在测试阶段使用训练集的均值和标准差。
希望本文对你有所帮助!如果你有任何问题或建议,欢迎在评论区留言。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









