






先导篇
1、打印:print("hello") 【括号内部的字符串用' '或者" "都正确,若是不加引号会被当做变量】
打印的进阶玩法
- 字符串连接:print("hello"+" world"+"!")
- 单双引号转移 若是内容本身就带有引号,则需要用单双引号转移的方法表达字符串的全部语义。
- 比如,print("He said"good!"")就会报错,因为第一个双引号与good之前的配对了,无法识别good!""所以,要想把该句子的语义完整的展现出来,就需要把内部的双引号换成单引号 或者外面大的双引号变为单引号
- 还有一种情况,若是字符串内部既有单引号也有双引号,比如"He said "Let's go !"",这种情况可以通过在字符串里面的引号前放一个反斜杠 \ 来表明后面的引号就是单纯的引号符号是内容的一部分 比如 "He said \"Let\'s go !\"" 这里的 \叫做转义符
- 换行 python中的一句代码不能随便换行。
- 若想换行打印 使用\n即可 就是print("Hello \n hi") 这个语句就可以实现换行输出。
- 使用多条print语句也可以实现换行的功能。
- 三个连在一起的单引号或者双引号包裹起来的内容比如【''' 123 ''' OR """""" 123 """""" 】这样包裹起来python 就会把新的一行当作换行的内容。

2、Pycharm中的venv文件是项目的虚拟环境文件,应该与代码是分开的。
3、Pycharm运行框中,第一行/Users/…这是Pycharm自动触发的运行指令;最后一行退出代码为0这是说明运行没有错误,若是非0则说明有错误。

4、变量:变量名之间不能有空格【my love】、不能用数字打头【1my_love】、也不能用引号包住【"my_love"】;变量名只能由字母、数字和下划线构成。
- 赋值操作 my_love = 111 赋值后可以通过变量名反复调用。
- python是从上往下运行的,所以要先定义变量,才能进行调用变量
- 变量名不要占用Python关键字,若是占用了,则该关键字不再具备原有的功能,而是拥有了变量名的作用。
- Userage≠userage 【大小写不同】
- 起变量名要易于理解,采用英文命名,最常用的是:
- 下划线命名法:字母全都小写;不同单词用下划线分割。
- 驼峰命名法:单词用首字母大写/小写分隔。
5、字符串:被双引号或者单引号包裹的,比如用户名,文字内容
- .title()会返回将一句话的每一个单词首字母大写
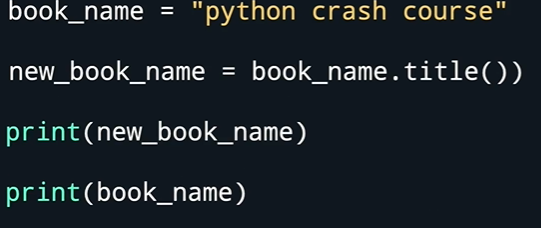
- .upper()将字母全转换为大写
- .lower()将字母全部转换为小写
- 有的时候还需要在字符串里添加变量名,对于c语言可以采用加号比如"姓名"+username+",性别"+sex的语句。对于Python采用更为优雅的格式化方法,即在字符串前加前缀f" 例如print(f"姓名{username},性别{sex})" 在此语句中花括号的内容会先被求值添加到字符串,当变量所赋的值也被更改,字符串的内容也会随之变化。
6、数:整型、浮点型
在Python中乘方符号为【**,比如2的三次方 就是2**3】
在Python中取整符号为【// 这个符号表示的是向下取整】
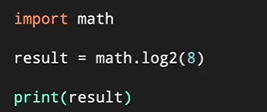
整数数的计算,常常用math运算库 导入方法 在开头 import math;当调用math库里面的函数时,使用方法为math.sin( );
7、注释:写一些代码解释 在Python中
- 单行注释使用# pycharm快捷键:添加和取消注释 ctrl+/
- 多行注释使用三引号包裹,之前也提到过,但是如果不赋值不打印。只是写三行注释,对于这个跨行字符串就没有任何执行效果

番外篇:数据类型
整数int、字符串str、浮点数float、布尔类型bool、空值类型NoneType、列表list、字典dict、元组tuple
str字符串
- 可以对字符串使用len("Hello")表示获得字符串的长度;在字符的长度计算中无论是字符还是数字还是空格都是占用一个长度【PS.如果是转义符就是\n 这种情况 完整的转义符才占用一个字符】
- 在字符串里放置方括号在方括号里放入索引,就能提取出该索引位置的字符。例如"Hello"[1] 就会提取出'e'字符。
- 使用str(int) 就可以把里面的int类型手动转换为str类型
bool布尔类型
只有两种值真True 、假False。必须是大写开头
NoneType空值类型
- 这种类型下只有一种值None ,None不是空字符串、不是0、不是False,表示的是完全没有值。如果你定义了一个变量但是还不知道变量的值,就可以定义为None 比如my_WiFi=None。 必须是大写开头
list列表
- 由于定义过多的类型要重复多次定义过于复杂,所以采用列表。一对空的列表用一对方括号表示,如shopping_list = [ ];若是列表包含多个数据,则使用方括号包裹,用逗号进行分割。如shopping_list = ["键盘","鼠标"];
- 若是想要往定义完的列表里加入东西,需要用对应的方法.append(),比如shopping_list.append("显示器")。shopping_list.insert(0,"笔记本") 说明在0号位置插入笔记本;append()是加入到结尾的意思就不用加索引【方法和函数差不多,都是来负责某个特定功能的。不同的是方法一般为对象.方法名(…);函数一般为函数名(对象)】
- 列表与字符串、整型、浮点数、布尔类型有个最大的区别就是列表是可变的。所以用.append()的时候不能再对shopping_list重新进行赋值,因为原来的列表已经被改变了
- 若是想删除列表里的某个元素,使用.remove()方法,比如:shopping_list.remove("显示器")。
- Python 的列表与其他语言不同的是,你可以放入很多类型的元素,列表和字符串一样可以使用len函数,返回的是列表有多少元素,也可以通过索引获得某个位置的元素,比如print(shopping_list[0])
dict字典
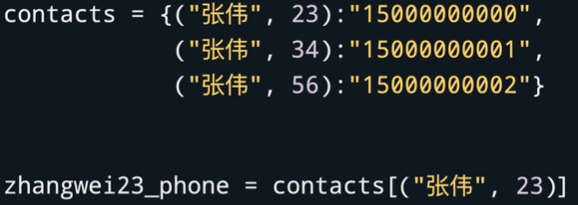
- 字典用于储存 "键:值"="key : value" 键是用来查找值的。空的字典用花括号表示,如contacts={ };要往字典里放入多个键值队就用花括号进行包住,如contacts={"小明":"13700000000","小刘":"13800000001"}。键和值之间用引号表示对应,键值对之间用逗号分隔。若是像获取某个键的值,在字典名后面跟方括号里面放入键,如contacts["小刘"]。这里注意键的类型必须是不可变的,也就是说,列表作为可变数据类型就不能作为键,而字符串、整数、浮点数、布尔类型等不可变数据类型就可以作为键。
- 字典和列表一样都是可变的数据类型,所有可以添加和删除键值对;可以使用contacts["美女A"]="15600000002"的方式添加,即在"[]"中添加键,在后面赋值所对应的值。如此一来字典就加入一个键值对。同样修改就是对"[]"中原有的键进行重新赋值,如contacts["美女A"]="15900000006"。在获得了一值的同时,也是去了一个值
- 若是想知道字典中,是否有一个键存在。"键 in 字典"会返回一个布尔值,告诉你该键是否在字典中,存在则返回true,不存在则返回false;
- 要想删除一个键值对,可以使用del,如del contacts["美女A"]。如此就可以把键和对应的值从字典里删除。若是键本身不存在,则会报错。
- 若是想知道字典里有多少键值对,任然可以使用len()函数,如len(contacts);
tuple元组
若是出现需要列表作为键时,应该这么办?使用元组,元组里面可以放多个元素,和列表之间的区别是,列表用的是方括号,元组用的是圆括号。
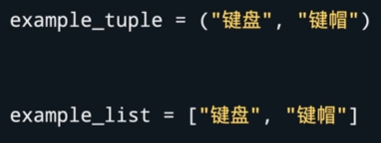
由于元组不可变,添加、删除操作均不可以操作。虽然不灵活,但是可以用元组作为字典的键,实现想用列表作为键而无法使用的情况。
数据类型非常重要,他决定了你能在该类型的对象身上运用哪些函数,函数是负责执行某个功能的,只有给了合适的输入才能给出正常的输出;当你不确定某个对象类型的时候可以使用Type,它可以反应你想要知道的数据类型

8、遍历
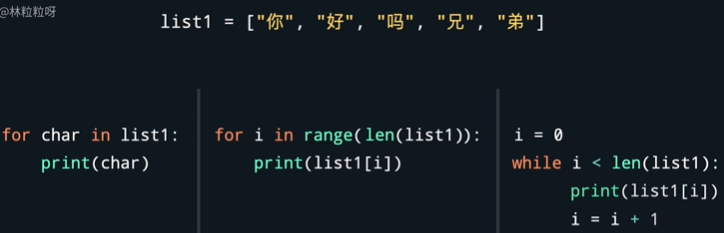
- 使用for循环进行迭代,迭代的对象可以是列表、字典、字符串。
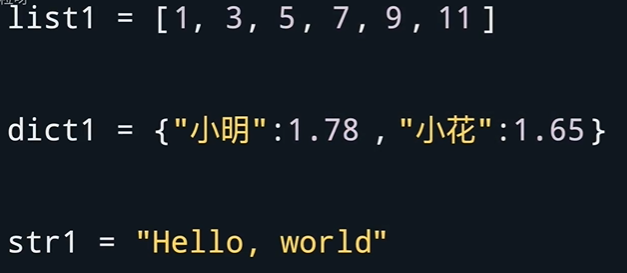
- for 变量名 in 可迭代对象 :
#对每个变量做一些事情
#所有带缩进的都会被视为for循环里的语句,对每个元素都会执行一遍
- 若是想要在循环外面进行输出语句,应该将前面的空格删除,
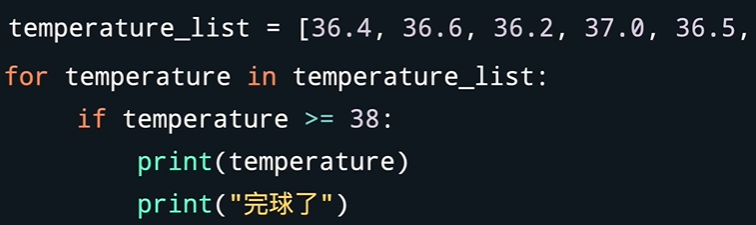
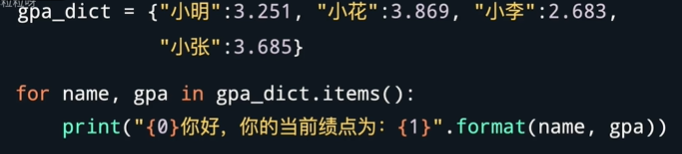
- 遍历字典,键值对有以下方法:
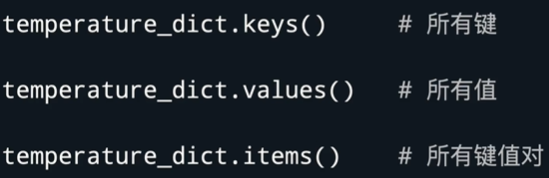
遍历字典使用dict.items()时 for后面要跟两个变量,因为字典赋值要把键和值赋值给两个变量,如 for key,value in dict.item():
当然对应着还有另一种写法,利用元组作为中介,但是这种写法要注意,要提取里面的键值对还是需要单独设置key 和 value 变量 分别将元组的两个值进行赋予如for tuple in dict.items(): key1=tuple[0] value1=tuple[1]
9、创建数值列表
- range(5,10)用来表示整数数列,括号里面第一个值表示起始值,最后一个数字表示结束值【PS.结束值不在序列的范围之内】
例:比如 for I in range(5,10) #这句话里是说i依次被赋值为 5 6 7 8 9 但不会为10
- range(5,10,2)还可以包含第三个参数表示步长,即每次跨几个数字,不指明的时候默认为1。
例:要打印1-9之间所有的奇数 就可以用: for num in range(1,10,2): print(num)
number = [1,22,3,4,55] sum(number)函数可以算列表里所有数的和.
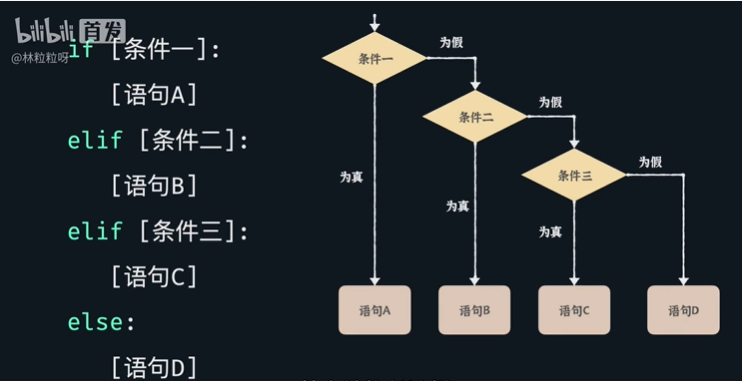
10、条件判断
- 条件语句:if语句结束要加":",下面所有缩进的语句都被看作if 条件为真时要执行的内容。在条件为真时,执行if;条件为假时,执行else;

嵌套条件语句:就是在条件语句中再放条件语句。
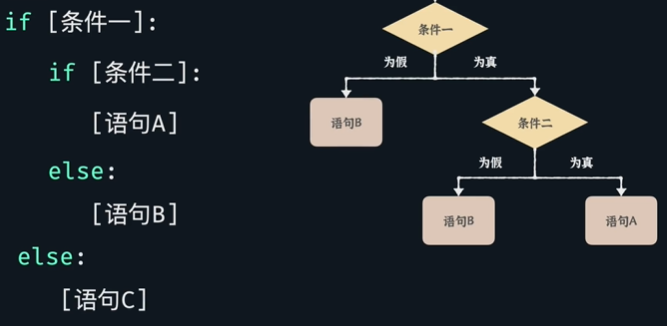
多条件判断语句:这种结构使用了elif 比嵌套条件语句要清晰的多
番外篇:逻辑运算
- Python的逻辑运算只有三个 and or not 【即与 或 非】
and 只有所有都是true才会返回true
or 只要有一个是true 就会返回true
not 是给true 就返回false 给false 就返回true
逻辑运算符可以混用,但是要注意优先级:not > and > or
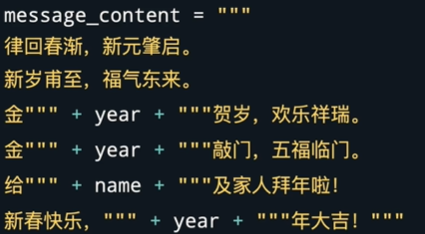
格式化字符串
下面这种情况,把好好的文字写的稀碎
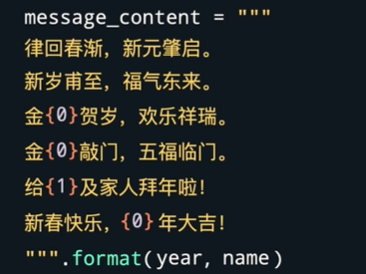
故,Python提供了两种方式更加优雅的格式化字符串的方法,如format方法,花括号表示会被替换的位置,里面的数字表示会用format里面的第几个参数进行替换。
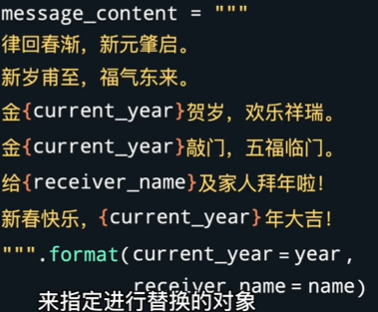
用format不仅仅可以使用关键字来标注要替换的对象,而不是使用位置。在这种情况下,第一个和第二个的位置就无所谓了,只要锁定format里面的关键字即可比如
数字也可以对字符串进行格式化,加入有个字典,使用format方法的时候无需手动将数字转换为字符串,如
还可以使用:.2f的方法来指定浮点数在格式化时,保证几位小数,比如上述.2f就是保留两位小数,如:【这里使用下面的字符串前加前缀f"的形式也能做到】

![]()
除了上面的format方法还可以使用f-字符串,在字符串前加前缀"f",花括号里面的值会被直接求值,添加到字符串内,如:

11、函数input()
- input( )可以从用户那里获取输入,比如input("can you speak English?"),Python就会输出这句话,并且等待用户的输入,比如用户可以输入 yes 点击回车表示输入结束。Python会继续运行之后的代码。但是这样我们并不能知道用户输入了什么。其实input()函数会把输入的内容进行返回,使用应该使用一个变量去获取input函数返回的值,如:language = input("can you speak english?")。如此一来变量language就被赋值了,就可以使用这个变量进行其他的操作
- input( )一律返回的是字符串,就算你返回的是数字,其也会当作字符串来看待 即,上述中language为字符串类型。所以你直接拿user_age去做数学运算,Python会报错。使用int("666")就能把其转换为整数,比如int(user_age);但是前提是内部的元素确实能被转换为数字。str( )可以强转为字符串等等。
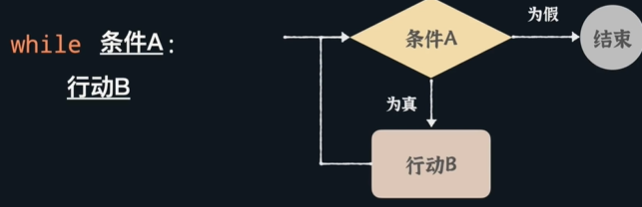
12、while循环
- 当条件何时结束未知的情况下,while循环要比for循环更适合使用;
- 除此以外,while循环和for循环可以相互转换,在即可以使用for循环也可以使用while循环的情况下,for循环会更加简单直观,所需行数更少。而且while也比for更加"危险",比如对于while循环,若是少写了结束判断的内容,就会无限循环下去。
- 总之,for循环在有明确的循环对象的情况或有确定的循环次数的情况下更为方便,while相比之下更加的通用,特别是不知道需要循环多少次的时候
13、定义函数
- 帮助我们远离复读机行为,需要定义函数,使用def来定义,如:

PS.定义函数的时候,里面的代码都不会执行,只有调用的时候才能执行函数定义里面的代码。
- 可以通过参数来使函数更具有通用性,如:

作用域:我们在函数里面定义的变量都是局部变量,出了函数之外定义的变量都是全局变量。使用return可以返回我们想要返回的内容。当你没写return语句时,函数默认存在return None
14、面向对象
- 区分面向对象和面向过程:
- 面向过程,就是负责完成某个具体任务的代码,基本可以理解为函数 ,面向过程编程的核心,就是把要是实现的事情拆分成一个个的步骤依次完成。在随着代码长度和逻辑规模的增加,面向过程的编程的代码清晰度会降低。
- 面向对象,以对象为核心,编程的第一步并不会考虑是具体的操作,而是模拟真实世界,先考虑各个对象有什么性质、能做什么事情,例每个ATM机器都有自己的性质,包括编号、银行、支行可以提取出这些性质,定义一个ATM类,然后用类创建对象。

- 类和对象之间的关系是类是创建对象的模板,对象是类的实例。面向对象除了把参数百年少了以外,还使用对象把相关属性绑定在了一起,利于让程序逻辑更加清晰,可以利用atm.编号 输出001 可以让人清楚的知道性质所属的对象是什么。
- 除了属性以外,另一个可以和对象绑定的是方法,正如真实世界里,对象拥有不同的属性,并且能做不同的事情。属性对应的就是对象拥有的性质,而方法就对应了对象能做的事情。
- 所谓方法,就是被定义在类里面的函数;所谓方法,就是被定义在类里面的变量。定义好类以后,就可以通过类来创建变量,让各个对象去执行这些方法。面向对象编程将事务先分解到对象身上,描述各个对象的作用。然后才是他们之间的交互。
- 对象不仅仅可以把所有相关属性和方法绑在一起,结合方法和属性还够更优雅地处理复杂逻辑
- 封装:就是写class类的人把内部的细节隐藏起来,使用类的人只通过外部接口访问和使用【接口:大致理解为提供使用的方法】。
- 继承:面向对象编程允许创建有层次的类,就像儿子继承爸爸一样。类也可以有子类和父类来表示从属关系,如:小学生和大学生都是学生,都应该有学号、年级等属性,都可以定义去学校这个方法。这两个类的共同之处会导致出现重复代码。如此一来就可以创建一个叫学生的父类,让小学生和大学生继承这个类。如此一来父类的属性和方法都会被小学生和大学生继承。不需要反复重新定义。同样都属于人类。
- 多态:同样的接口,因为对象具体类的不同而有不同的表现,如:小学生和大学生都需要写作业,但是内容的难度肯定不同。所以这个写作业的方法就不能直接定义在父类里面。而是分别要定义在子类里。否则大学生和小学生就是用的同一个方法。但是对于这俩孩子的家长,不用管具体写的是高难度还是低难度作业,都可以一视同仁直接调用写作业方法。由于写作业的所属类不同会分别去调用不同的写作业方法。【这里如果不用类,就需要用if先去判断孩子是大学生还是小学生,然后手动调用不同的写作业函数。多态就是让你无需判断,统一调用同一名称的方法。但是并不代表面向对象就一定优于面向过程,选择哪个具体问题具体分析】
- 创建类
- 关键字class 类的名字: 【Python在定义类名的时候不采用下划线命名法而是使用Passcal(帕斯卡)命名法,它要求在变量名和函数名称由两个或两个以上单词连接时,每个单词的首字母都要大写,以提高代码的可读性。其实就是大写驼峰命名法】
- 类有一个特殊的方法叫构造函数,主要作用是定义实例对象的属性,必须要被定义为def __init__(): init前后必须有两个下划线。
- 定义对象创建属性:
括号内可以放任意数量的参数,但是第一个参数永远是被占用的,得用于表示对象自身。约定成俗叫self,它可以帮助将属性的值绑定到实例对象上,例:def __init__(self):虽然__init__(self)当中有self参数,但是创建一个对象的时候,self不需要我们手动传入,如people1 = student()。调用对应类的方法时,__init__(self)会自动运行,里面的内容就会进行赋值,加入self.name=“小孩”。那么name属性就会被赋值为小孩。要获取对象的属性。使用.name就能获取name属性对应的值,如people1.name会返回这个people1对象所绑定的name属性的值。但是我们的类是一个模板,而且不是所有的name都叫"小孩"。所以,应该给__init__更加灵活的属性赋值,比如从参数获取name的值。如

定义对象拥有的方法:
- 方法很简单,与创建普通的函数差不多。只有两个区别:①要写在class里面;②和__init__(self)一样,第一个参数要被占用,用来表示对象自身,约定俗成为self。方法中设置self是为了去获取或修改和对象绑定的属性。字符串乘上数字表示字符串重复多少次,如print("喵"*self.age),这样就实现了方法调用结果根据属性的不同而改变。
- 调用类方法,要使用对象.方法名( ),括号内放上参数进行调用。这里构造方法一样,无需手动传入self。方法自然也可以接收更多参数。
- 继承
- 写法:class 类名(父类名字): 若是子类没有写对应的方法,则会调用父类的方法。若是子类自己有对应的方法,优先调用子类的方法。即,优先看所属的类有没有该方法,若无则往上找父类的同名方法用。
- 对于__init__(self)方法,若是有独属于子类的属性,创建一个新的__init__(self) 就会优先调用子类的构造函数,而不是调用父类的构造函数了。为了解决这个问题,在子类的__init__(self)方法之下,写一个super()方法,如:super().__init__(self);super()会返回当前类的父类。这样就会调用父类的构造函数,在super()后面再写,独树于子类的属性。
- 在实例化、调用属性、调用方法的时候与之前没有任何区别。
- 什么时候用继承?若是有子是父 则可以写成class 子类名字(父类名字)。
- 导入类与Python标准库
- 内置函数数量有限,可以去Python标准库里的其他模块,模块就是一个Python程序,引入模块后,里面的变量和函数都会为我所用。
- 引入模块和使用模块函数的方法:
- ①用import 模块名引入模块,如:import statistics ;使用模块内的函数:模块名.模块内的函数名( ),如:print(statistics.median(number_list));
- ②使用form….import….语句,即form 模块名 import 该模块中所需要使用的函数或变量【PS.多个之间使用 " ," 分开】 ,如 :form statistics import medin,mean。这样使用的好处是,使用模块内的函数的时候无需再带上模块名,如 print(median(number_list))
- ③使用form….import *语句,即form 模块名 import *,如:form statistics import *。*号代表将模块内所有内容都引入。这样使用的好处是,使用模块内的函数的时候无需再带上模块名,如 print(median(number_list))。
- 虽然这样做,在需要用到同一模块里多个内容时很方便,但不推荐使用。因为用 "*" 的时候*将模块内所有内容都引入,很可能包括一些你用不到的。假如用*导入了两个模块,它们里面都有一个名字为abc的函数,如此一来就会产生命名冲突。
- 如果使用第一种import的方法,需要在前面添加模块名的,不会出错
- 如果使用第二种import的方法,当然也可以选择在某个模块里你想要的方法,不会出错。
- 若是想要查看模块里的函数是怎么写的,在Pycharm可以按住ctrl+点击函数名。
- 有些时候Python的模块也不够用的时候,我们可以去引入第三方库的模块,第三方库的意思是非官方提供,而是其他程序员或机构提供的。引入第三方库的模块引入方法与前面相同,不同的是在引入之前需要先安装,即从互联网下载别人写好的模块。使用pip install命令。
- pypi.org这个网站可以对第三方库进行搜索。安装的话去终端输入pip install 库名
安装后,就可以使用import引入进来,再引入后,就可以使用这个模块里的函数了
15、文件
- 文件路径
- 计算机寻找有两种方法
- 绝对路径:就是从根目录出发的路径。
- ①对于unix系统绝对路径以 " / " 开头,路径之间的每个路径之间用 " / " 进行分割,最后以目标文件或目标目录结尾。
- ②对于windows系统绝对路径以分区名加" \ " 开头,如:c:\。路径之间的每个路径之间用 " \" 进行分割,最后以目标文件或目标目录结尾。
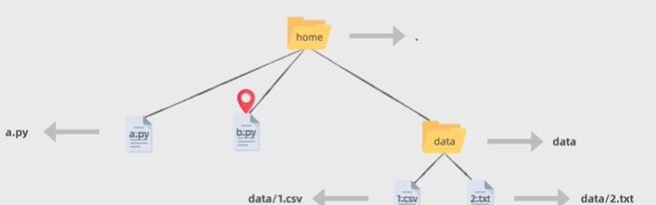
- 相对路径:从一个参考位置出发,表示从参考位置来看,其他文件处于什么路径。用相对路径时,我们使用 " . " 来表示参照文件当前所在的目录,用 " .. " 来表示更上一层的父目录。若是继续往前走就用 " ..\.. " 【用于Windows】或 " ../.. "【用于unix】 。若是往下走则用 " \ " 或者" / " 来分割路径。
- 绝对路径:就是从根目录出发的路径。
- 计算机寻找有两种方法
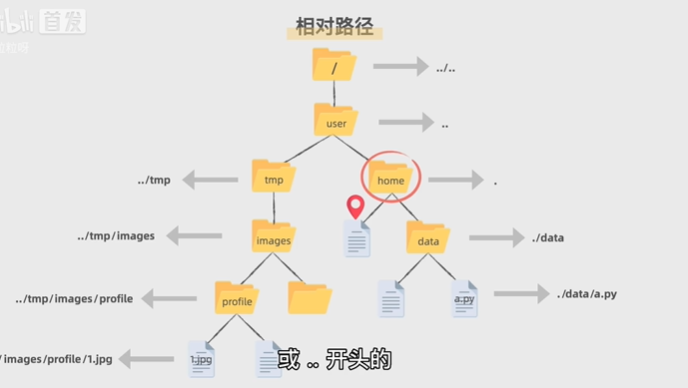
可以看出,相对路径都是以 " . " 或 " .. " 开头的,另外 " ./ "或 " .\ " 是可以被省略的。所以在同一目录下的文件想互相用相对路径找到彼此的话可以直接使用文件名。
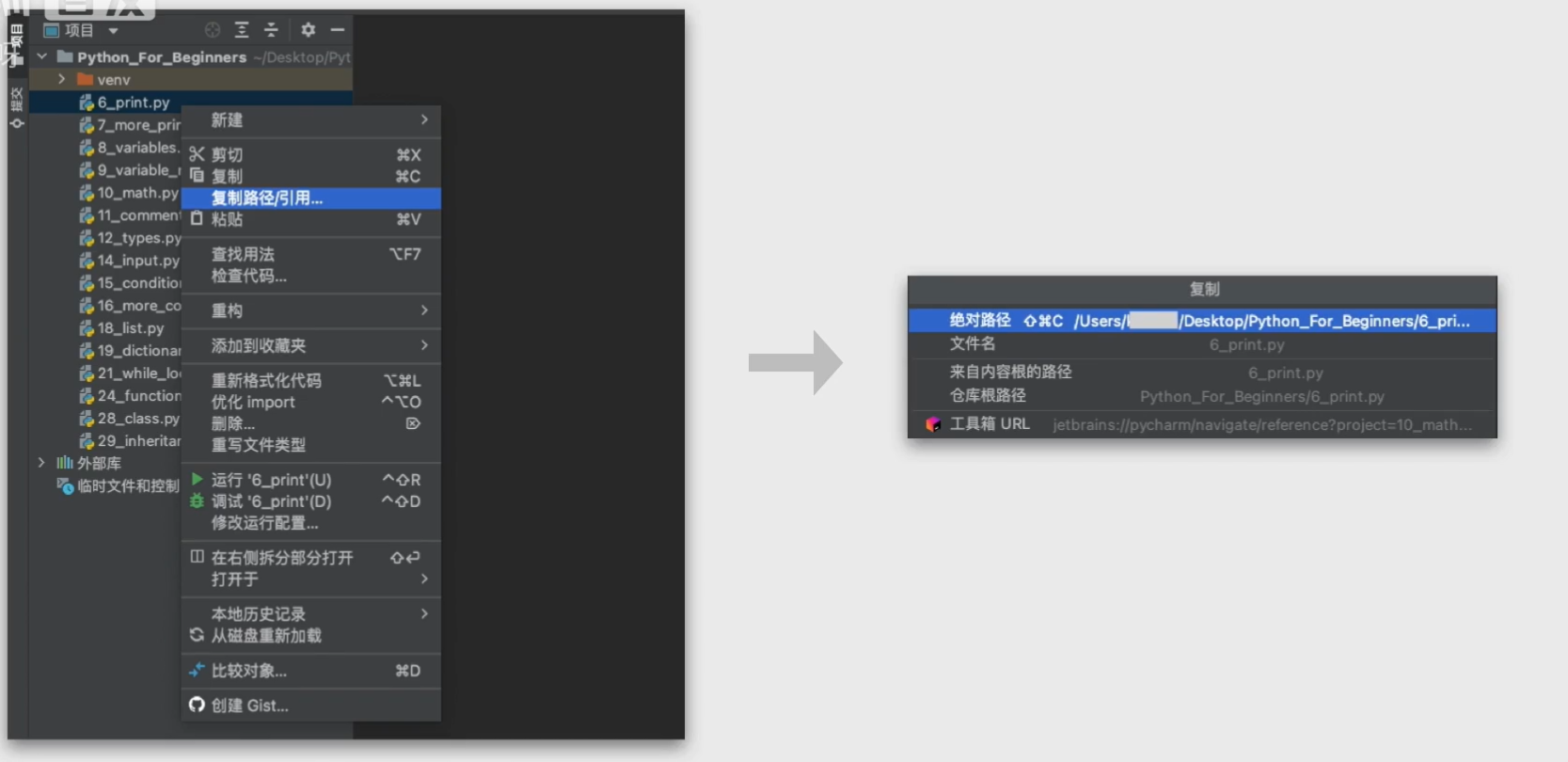
- 很多编辑器都可以实现复制文件的路径,在PyCharm,右键点击文件,选择"复制路径/引用",就可以获得那个文件的绝对路径,以及以最顶层项目目录为参考的相对路径。
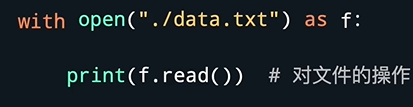
- 能用绝对路径和相对路径来定位文件的位置后,就可以使用代码对文件进行操作了。
- 读文件
- 用Python读文件第一步要打开目标文件,这里使用open()函数,括号内先放入文件路径,可以是绝对路径也可以是相对路径。括号内还要放入模式,模式是字符串包括"r(只读)"、"w(只写)"。当然这个参数也可以不写,不写默认为读取模式,如:open(".\data.txt","r")。在读取模式下,程序找不到你想找的文件名的话,会报一个FileNotFoundError的错误,提示文件不存在。open()函数还有一个参数叫encoding,表示编码方式,现在文件的一般编码方式都是"utf-8",如:open(".\data.txt","r",encoding="utf-8")。若是open()函数执行成功,会返回一个文件对象。我们可以后续对它进行读取或写入操作,如:file1 = open(".\data.txt","r",encoding="utf-8")。
- 针对读文件而言,文件对象有个read方法,调用后就会一次性读取文件里所有内容,并以字符串形式进行返回,如:file1.read();一般而言,我们用代码操作的文件格式都会是很简单且直接的方法。代码喜欢txt的纯文本,而不是word这种花哨的文本。另外,若是调用完read以后,再对同一文件调用一次read(),返回的结果为空。这是因为程序会记录该文件读到哪个位置了,用read()一次性就读到了结尾,第二次调用read()就没有内容了返回空字符串。
- 在文件特别大的情况下,最好不直接使用read()。若是不想一次性读完整个文件,就给read()传入一个数字,如:file1.read(10)。表示读多少字节,下一次调用read()的时候会接着上一个的末尾继续往下读。
- 除了read(),还可以使用file1.readline()方法,这个方法只会读文件的一行的内容。下一次调用就读下一行。它会根据换行符来判断本行的结尾。而且换行符也会被当作读到的内容的一部分。若是读到结尾,readline()会返回空字符串。表示后面就没有内容了。所以一般使用while循环,判断只要返回的不是空字符串,就继续阅读下一行。
- 还有一个方法file1.readlines(),该方法会读全部文件内容,并把每行作为列表元素进行返回。一般和for循环结合使用,如:

- 第二步,读完文件后,还要关闭文件。文件对象有一个close()的方法。调用后该文件对象就会释放系统资源,所以每次完成文件读写操作以后,都要关闭文件;有些时候,会忘记调用close方法。另一种方法是使用with关键字,在with后跟上open()函数的调用加as 文件对象,如此也不用单独再写file1.close()方法了
- 写文件
- 写文件与读文件有很多的相似之处,都是要打开文件,结束的时候关闭文件。区别在第二个传入"w"只写,使用"w"会把原本文件内容清空。而且当该文件不存在的情况,写文件不会像读文件那样报错,而是会自动创建一个所传入文件名的那个文件。任然可以传入encoding。
- 针对写文件,有个file1.write()方法。若是第一遍调用为file1.write("hello!"),之后再调用一次file1.write("Yo")。出现的结果为:hello!Yo。即write不会每次调用时默认帮你换行,所以若是想有换行效果,需要自己手动加入换行符号。
- 若是在写文件中,不想把原文件清空,就不能使用"w",而是使用"a"【附加模式】,所以若是针对原本就有文字的文件,用"a"作为模式参数打开,并且接着调用write,就会接着文档本身的末尾继续添加文本。另外"a"和"w"一样,若是不存在该文件名,则会创建一个文件。
- 注意:无论是"w"还是"a"都无法读取文件里原本的内容,若是硬要调用.read()。程序会报错为UnsupporteOperation即,不支持读操作
- 为了避免这些麻烦东西,直接在模式选择"r+",就又可以读又可以写,还是以追加的模式写了。
16、异常
程序在某一行报错后,后面的所有代码都不会被运行。所以,应该学会在程序运行之前预判,捕捉异常,从而处理错误情况。
异常类型
用长度之外的数字取索引,会产生IndexError,即索引错误。如:
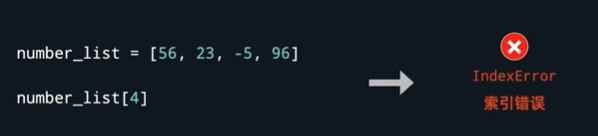
用数字除以0时,会产生ZeroDivisionError,即除零错误。如:

打开的文件不存在时,会产生FileNotFoundError,即找不到文件错误。如:

让两个字符串做乘法,会产生TypeError,即类型错误,如:

由于错误类型非常之多,无法全部概括。所以通过测试等方式,找出所有能处理的bug抓出来并且debug掉,若是错误无法从程序员避免。
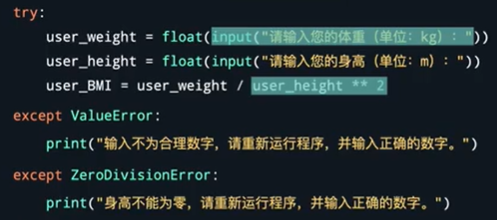
- 使用try…except语句捕捉异常。try:后面跟上缩进的代码块中放入你认为可能会产生报错的代码 在except后面跟上你想捕捉的错误名字以及冒号。然后在except下面缩进的代码块放入那类错误发生后,你想要执行的操作。另外,若是代码块中有多个想捕捉的侧屋名字。可以使用叠加except 错误名 :的模式,并且在下面缩进的代码块中放入该错误发生后,想执行的操作,如:
- 若是,你无法预知有什么错误类型的时候,可以直接写一个except :。无需写错误类型,这个语句会捕捉所有的错误类型,如

PS.对于try..except语句,是从上往下运行的,如果第一个except就捕捉到了对应错误。后面的except语句就都不会执行了。这个逻辑和if、elif的逻辑很像。即,只有第一个符合条件的分支会运行
在except后面还可以跟上两个语句:
else: 放入当try内语句块中没有产生任何错误的时候要执行的语句,如:
![]()
finally:放上无论错误发生与否,最终都会被执行的语句,finally很厉害的在于,无论是错误被某个except语句捕捉,还是没有任何错误产生,还是出现了你没捕捉到的错误。finally里面的代码最终都会被执行。
![]()
17、测试函数
- 测试的目的是帮我们确认程序的行为是否和我们预期相同,而且测试除了能帮助我们验证新代码是否正确以外,还能验证在改动老代码之后不该受影响的地方也仍然会按照预期执行,而不是牵一发而动全身。
- 使用assert进行测试,其后面可以跟上任何布尔表达式,即值为True或False的表达式。测试时,我们会在assert后面跟上我们认为应该为True的表达式,若assert后面的表达式最终求值出来的结果为True,则无事发生,继续运行后面的代码;但若是求解出的为False,就会产生"AssertionError",即断言错误,相当于在提醒运行程序的人,这里不符合预期。但是assert的缺点就是,一旦遇到断言错误代码就会终止,后面的代码也不会再运行了。我们并不知道后面的代码里哪里还有不符合预期的内容。故,一般会使用专门做测试的库,他们能一次性跑多个测试用例,并且能更直观的展现哪些测试用例通过了,哪些没有。
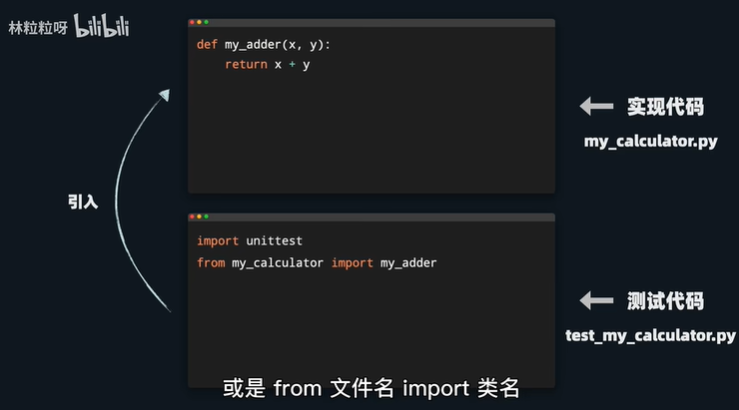
- unittest就是一个很常用的python单元测试库,【单元测试:即对软件中最小可测试单元进行验证,如:验证某函数某方面表现是否符合预期】unittest库是python自带的无需安装。但是记得使用import语句引入到测试程序中。一般而言,会把测试代码放到独立文件中,而不是和要测试的功能混合一起。更清晰的划分实现代码和测试代码,如:在实例代码文件my_calculator.py写了一个做加法的函数叫my_adder,可以对其写一些测试用例。为了要调用测试的功能还需要把要测试的函数或类也引入进来,若是测试文件和被测试文件位于同一文件夹下,引入的语法为from 被测试文件名 import 函数名或from 被测试文件名 import 类名。如:
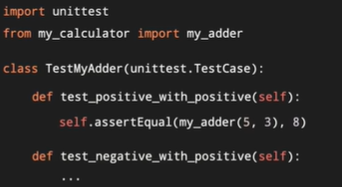
- 正式写测试,创建一个类,文件以test为开头,表示这是一个用于测试的类。如:test_my_calculator.py ,他要当unittest.TestCase的子类,如此就能使用那些继承自unittest.TestCase的各种测试功能。在这个类下面,可以定义不同的测试用例,每一个测试用例都是类下面的一个方法,命名必须以test_开头。这个命名很关键,因为unittest的库会自动搜寻test_开头的方法,并且只把test_开头的当作测试用例。写测试用例之前,要想清楚要测试的函数的预期都有哪些,可以使用assert方法,如:assert add(5,8) == 8。我们知道这个方法若是有错误会导致中断。所以我们使用来自unittest库里TestCase类的assertEqual方法,所以可以直接使用self调用父类方法,传入的第一个参数和第二个参数如果相等,显示测试通过。反之,显示不通过。但是程序也不会炸掉。如:self.assertEqual(add(5,8),8)
- 写好测试用例后在编辑器的终端输入python -m unittest表示运行unittest。这个库就会自动搜索所有继承了unittest库里TestCase类的子类,运行它们所有以test_开头的方法,然后展示测试结果,会告诉你共运行了几个测试,上面的点点,每个点都代表一个测试的通过。
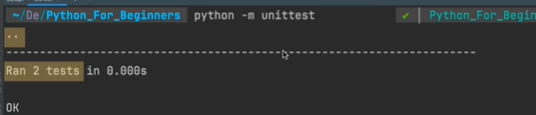
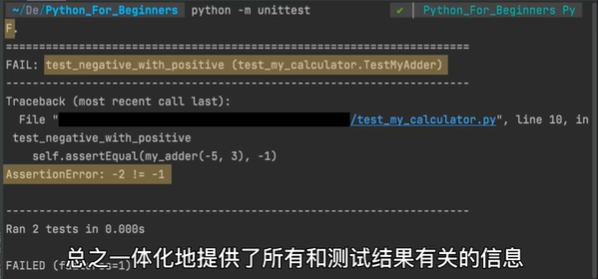
若是有一个测试没有通过,则那个对应的点就会变成F,unittest还会详细告诉你,是哪个文件的哪个方法造成了测试失败以及为什么失败。总之,一体化地提供了所有和测试结果有关的信息。
- unittest.TestCase类常见的测试方法

本质上说assertTure可以代替这些所有方法,但是gen 推荐使用更具有针对性的方法。因为在测试的时候,针对性的测试方法会给出更详细的失败原因。有些时候,还可以通过额外方法进一步提高测试效率。
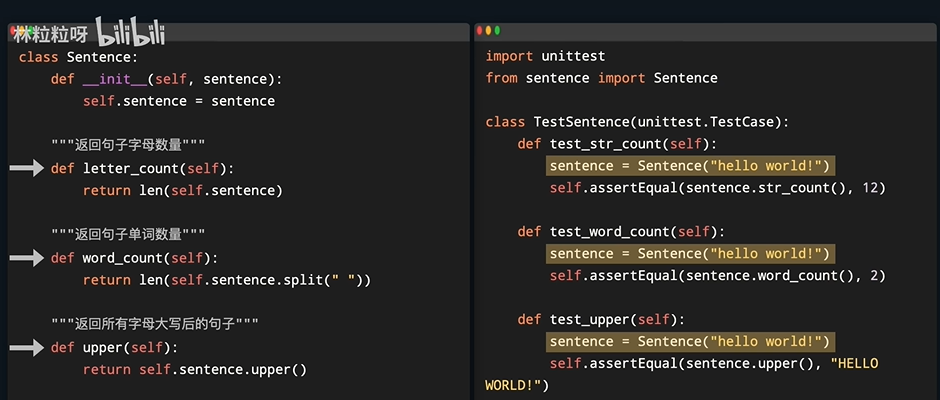
- 假如我们要测试一共类,为了调用各种类方法,需要创建实例对象,又因为不同的测试用例之间相互独立,测试不同方法的时候,我们要不停地创建新对象。
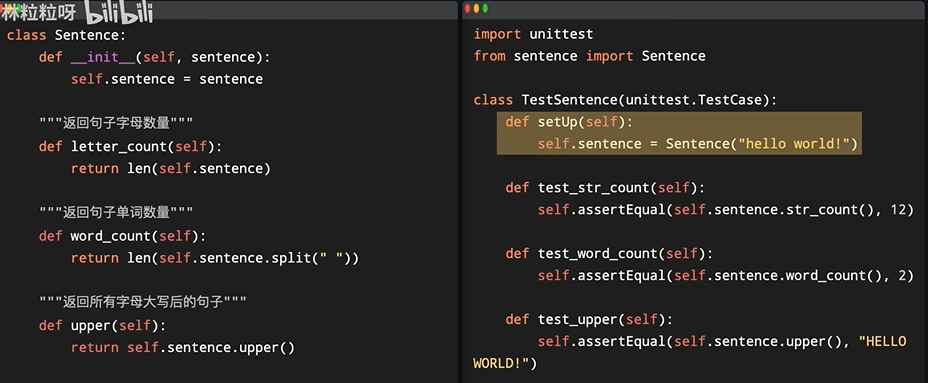
所以为了减少一些不必要的重复代码,利用TestCase类里的setUp方法,放置在运行各个测试方法,即test_开头的方法之前。setUp方法都会被先运行一次,如此一来就只需要在setUp方法里面把测试对象创建好作为当前测试类的一个属性。然后在各个方法里就通过这个属性获取那个已创建好的对象



















 3155
3155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











