










 本文深入解析C++ STL中的各种容器,如vector、deque、list、set、map等,讨论它们的特性和应用场景,重点讲解了顺序存储结构和关联存储结构的区别,以及如何高效使用这些容器进行数据处理和算法配合。
本文深入解析C++ STL中的各种容器,如vector、deque、list、set、map等,讨论它们的特性和应用场景,重点讲解了顺序存储结构和关联存储结构的区别,以及如何高效使用这些容器进行数据处理和算法配合。
参考连接:史上最全的各种C++ STL容器全解析 - Seaway-Fu - 博客园 (cnblogs.com)
C++中的容器类包括“顺序存储结构”和“关联存储结构”,前者包括vector,list,deque等;后者包括set,map,multiset,multimap等。 若需要存储的元素数在编译器间就可以确定,可以使用数组来存储,否则,就需要用到容器类了。
容器类是一种对特定代码重用问题的良好解决方案;容器可以自行扩展,一般在解决问题时,我们常常不知道我们需要存储多少对象,容器的优势就在这里,它不需要你预先告诉他要存储多少对象,它可以为你申请内存或释放内存,并且用最优的算法来执行命令。c++中处理容器提供多种数据结构,这些数据结构可以与标准算法一起很好的工作,为软件开发提供了良好的支持。
标准容器:
| 顺序性容器 | |
| vector | 从后面快速插入与删除,直接访问任何元素 |
| deque | 从前面或后面快速的插入与删除,直接访问任何元素 |
| list | 双链表,从任何地方快速插入与删除 |
| 关联容器 | |
| set | 快速查找,不允许重复值 |
| multiset | 快速查找,允许重复值 |
| map | 一对多映射,基于关键字快速查找,不允许重复值 |
| multimap | 一对多映射,基于关键字快速查找,允许重复值 |
set, multiset, map, multimap 是一种非线性的树结构,具体的说采用的是一种比较高效的特殊的平衡检索二叉树—— 红黑树结构。(至于什么是红黑树,我也不太理解,只能理解到它是一种二叉树结构)
| 容器适配器 | |
| stack | 后进先出 |
| queue | 先进先出 |
| priority_queue | 最高优先级元素总是第一个出列 |
vector容器:
是一个线性顺序结构,相当于数组,其大小会自动扩展,我们可以将其看作动态数组。创建一个vector之后他会自动在内存中分配一块连续的内存空间进行数据存储,初始的空间大小可以预先指定也可以由vector默认指定,这个大小即capacity()函数的返回值。当存储超过分配的空间时,vector会重新分配一块内存块,其分配时工作如下:
vector会申请一块更大的内存块
将原来的数据拷贝到新的内存块中
再销毁原内存块中的对象(调用析构函数)
最后将原来的内存空间释放掉。
容器类型<变量类型> 名称
#include<vector>
vector<int> vec;
vector<char> vec;
vector<pair<int,int> > vec;
vector<node> vec;
struct node{...};
容器的使用方法:
vec.begin(),vec.end() 返回vector的首、尾迭代器
vec.front(),vec.back() 返回vector的首、尾元素
vec.push_back() 从vector末尾加入一个元素
vec.pop_back() 从vector末尾删除一个元素
vec.size() 返回vector当前的长度(大小)
vec.empty() 返回vector是否为空,1为空,0不为空
vec.clear() 清空vector
for(vector<Person*>::iterator it=v.begin();it!=v.end();it++) //使用迭代器遍历该容器
{
cout<<"姓名: "<<(**it).m_Name<<"年龄: "<<(**it).m_Age<<endl;
}
//通过迭代器来访问容器的数据
vector<int>::iterator itBegin = v.begin();
vector<int>::iterator itEnd = v.end();deque容器:
双端队列,双端进出,处于双端队列中的元素既可以从队首进/出队,也可从队尾进/出队。deque比quque更优秀的一个性质是它支持随机访问,即可以像数组下标一样取出其中一个元素。如q[1],用处可以应用到SPFA算法的SLF优化
q.begin(),q.end() 返回deque的首、尾迭代器
q.front(),q.back() 返回deque的首、尾元素
q.push_back() 从队尾入队一个元素
q.push_front() 从对头入队一个元素
q.pop_back() 从队尾出队一个元素
q.pop_front() 从对头出队一个元素
q.clear() 清空队列list:
list是一个链表,其中任何一个元素可以是不连续的,但他都有两个指向上一个元素和下一个的指针,所以他对插入、删除元素性能是最好的,而查询性能非常差;适合大量地插入和删除操作而不关心随机存取的需求。
set:
set容器的功用就是维护一个集合,其中的元素满足互异性。可以将其理解为一个数组,这个数组的元素是两两不同的。如这个set容器包含了一个元素i,无论我们后续添加多个i,这个set容器中还是只有一个元素i,不会出现一堆i的情况。set是有序的(升序排序),setset容器自动有序和快速添加、删除的性质是由其内部实现:红黑树(平衡树的一种)。
声明一个set容器
#include<set>
set<int> s;
set<char> s;
set<pair<int,int> > s;
set<node> s;
struct node{...};
s.empty()
s.size()
s.clear()
s.begin()
s.end()
s.insert(k) 向集合加入元素k
s.erase(k) 删除集合中的元素k
s.find(k) 返回集合中指向元素k的迭代器,不存在这个元素就返回s.end()
s.lower_bound(),s.upper_bound() 其中lower_bound返回集合中第一个大于等于关键字的元素。upper_bound返回集合中第一个严格大于关键字的元素。multiset:
有序多重集合,其很多性质和set一样,multiset与set容器不同的地方就是:set的元素互不相同,multiset元素可以允许相同。
if中的条件语句表示定义了一个指向一个a元素迭代器,如果这个迭代器不等于s.end(),就说明这个元素的确存在,就可以直接删除这个迭代器指向的元素了。
if((it=s.find(a))!=s.end())
s.erase(it);
s.count(k); 函数返回集合中元素k的个数map:
map是“映射容器”,其存储的两个变量构成了一个键值到元素的映射关系。我们可以根据键值快速找到这个映射出的数据。
声明map容器,建立一个从一个整型变量到一个字符型变量的映射
#include<map>
map<int,char> mp;
插入操作:
1、类似于数组类型,可以把键值作为数组下标对map进行直接赋值
mp[1]='a';
2、使用insert()函数进行插入:
mp.insert(map<int,char>::value_type(5,'d'));
删除操作:mp.erase('b');
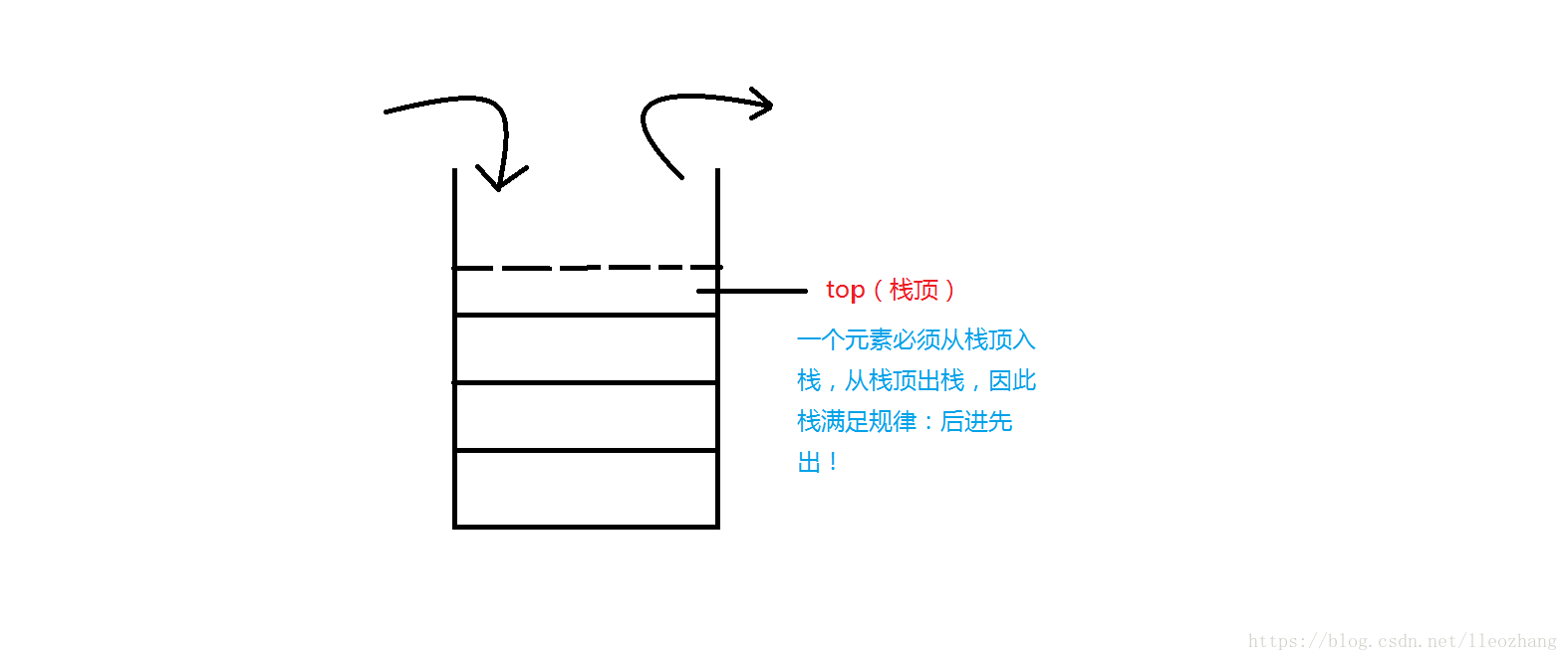
查找操作:mp.find(1) 查找键值为1的元素stack:
#include<stack>
stack<int> st;
stack<char> st;
stack<pair<int,int> > st;
stack<node> st;
struct node{...};
st.top() 返回栈顶元素
st.push() 从stack栈顶加入一个元素
st.size() 返回stack当前元素的长度
st.pop 从stack栈顶弹出一个元素
st.empty() 返回stack是否为空,1为空,0不为空queue:
我们可以在脑中想象买票时人们站的排队队列。我们发现,在一个队列中,只可以从队首离开,从队尾进来,即一个先进先出的数据结构。
用法于stack相同。
priority_queue:
声明方式:
#include<queue>
priority_queue<int> q;
priority_queue<string> q;
priority_queue<pair<int,int> > q;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









