







主从和哨兵可以解决高并发读、高可用读的问题。但是依然有两个问题没有解决:
1、海量数据存储问题
2、高并发写的问题
解决方案:使用Redis分片集群。利用插槽机制实现动态扩容,利用集群多个master实现高并发写。
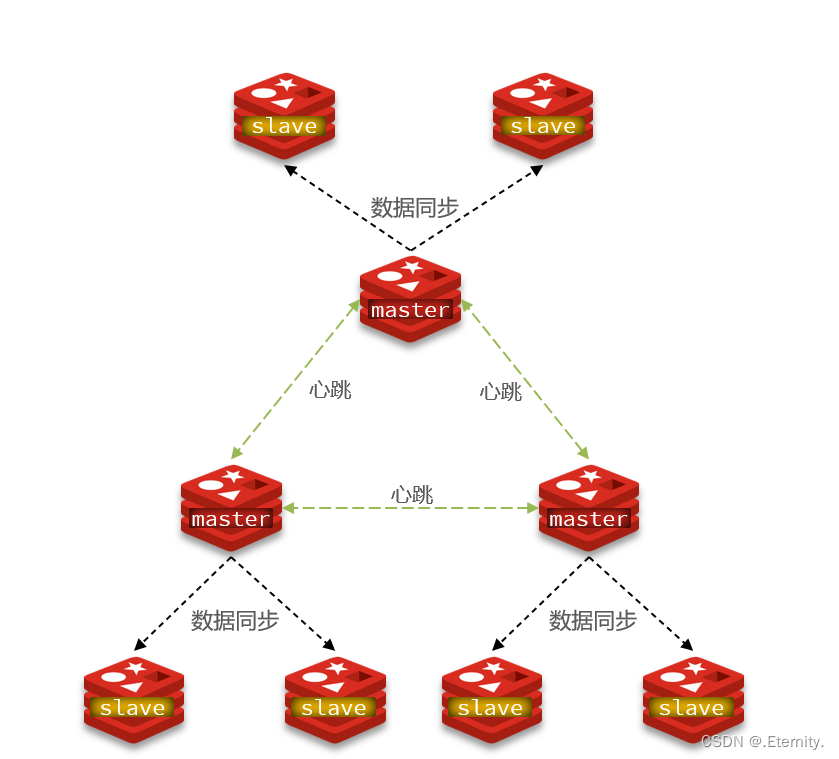
Redis分片集群cluter 特征:
- 集群中有多个master,每个master保存不同数据
- 每个master都可以有多个slave节点
- master之间通过心跳机制发送ping命令监测彼此健康状态
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点
散列插槽
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上,查看集群信息时就能看到:
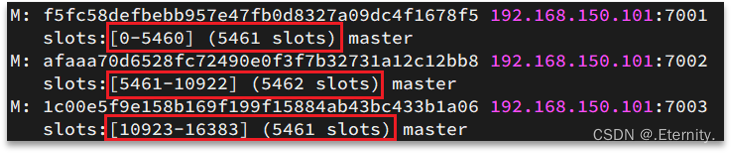
注意:数据key不是与节点绑定,而是与插槽绑定。但是数据存储到对应mater节点,而非插槽。
key中包含"{}",且“{}”中至少包含1个字符,“{}”中的部分是有效部分
key中不包含“{}”,整个key都是有效部分
例如:key是num,那么num是有效部分,如果是{it}num,则it是有效部分。
Redis如何判断某个key应该在哪个实例(哪个master)?
- 将16384个插槽分配到不同的实例(master)
- 根据key的有效部分计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在实例(master)即可
- 将数据存储到实例(master)中,而非插槽
如何将同一类数据固定的保存在同一个Redis实例?
这一类数据使用相同的有效部分,例如key都以{typeId}为前缀

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









