







C++11是C++的一次大更新,出现了很多实用的语法和特性,所以我们很有必要学习他的新东西
🍪统一列表初始化
C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自定义的类型,使用初始化列表时,可添加等号(=),也可不添加。
初始化列表是如何初始化对象的呢?答案是通过调用其构造函数。
以vector为例(其他容器都是一样的),看看底层实现
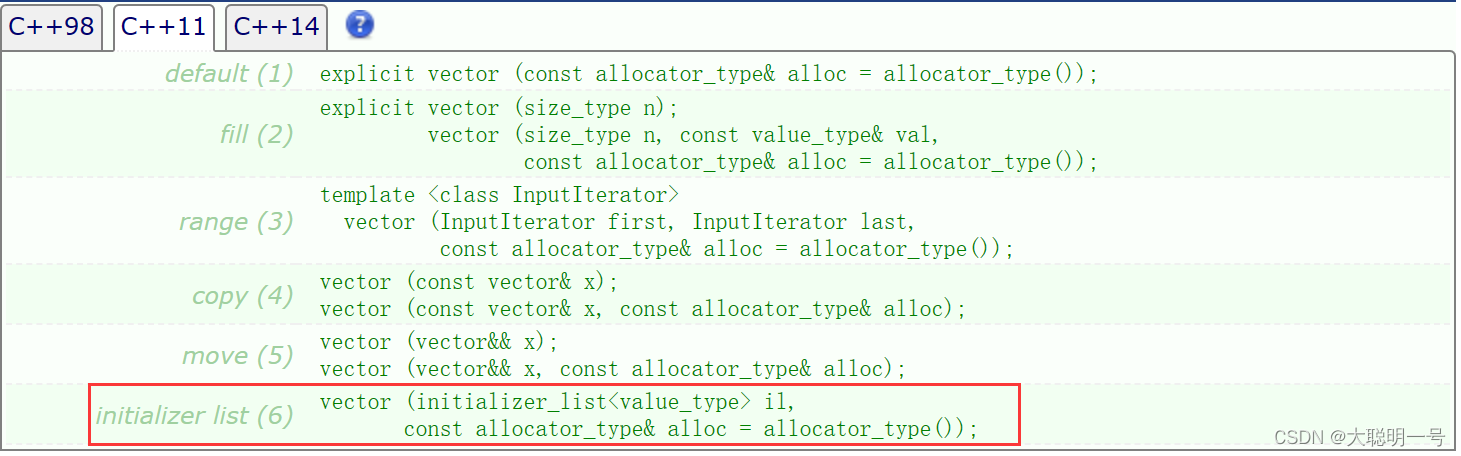
vector在C++11时,重载了一个新的构造函数,其中调用了initializer_List<T> il
- initializer_list 更多内容
是std里的一个类,只要调用{}来为容器对象初始化,都会调用先将这个类生成一个临时变量,然后在通过这个临时变量来构造出所目的对象。前提是容器里重载了initializer_list作为参数的构造函数。
🍪左值引用,右值引用
🥛概念和作用
了解左值引用,右值引用前,我们先了解左值和右值
左值和右值都是数据的表达式
- 左值:可以取地址+可以赋值
void test3()
{
// 以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;
// 以下几个是对上面左值的左值引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;
}
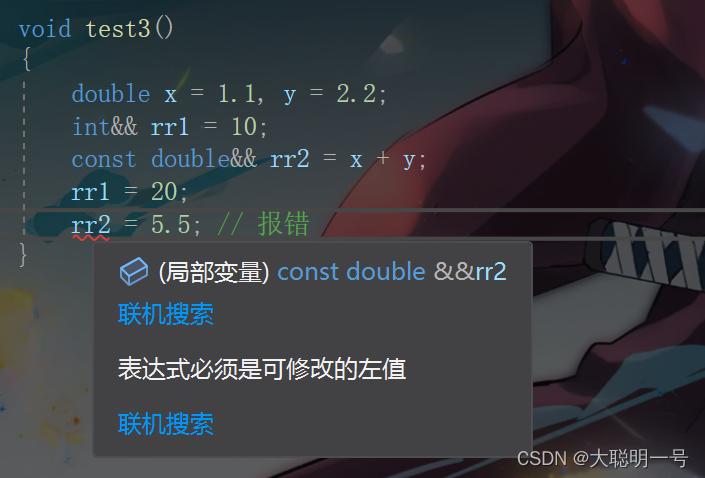
- 右值:右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,不可以取地址
void test3()
{
double x = 1.1, y = 2.2;
// 以下几个都是常见的右值
10;
x + y;
fmin(x, y);
// 以下几个都是对右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);
// 这里编译会报错:error C2106: “=”: 左操作数必须为左值
10 = 1;
x + y = 1;
fmin(x, y) = 1;
}
无论左值引用还是右值引用,都是给对象取别名
ps:右值是不可以取地址的,但是给取了别名后,会导致右值被存储到特定位置。且可以取到该位置的地址
- 总结
左值:
- 左值引用只能引用左值,不能引用右值。
- 但是const左值引用既可引用左值,也可引用右值
右值:
- 右值引用只能右值。
- 但是右值引用可以move以后的左值。


🥛使用场景
- 左值引用
优点:做参数和做返回值都可以提高效率。
缺点:但是当函数返回对象是一个局部变量,出了函数作用域就不存在了,就不能使用左值引用返回,只能传值返回。就势必会调用一次拷贝构造函数。

- 右值引用
优点:作为使用移动构造的形参,将临时变量的内容剪切过来,这样可以提高效率。
这里介绍一下移动拷贝和移动赋值。(以自己造的string为例)
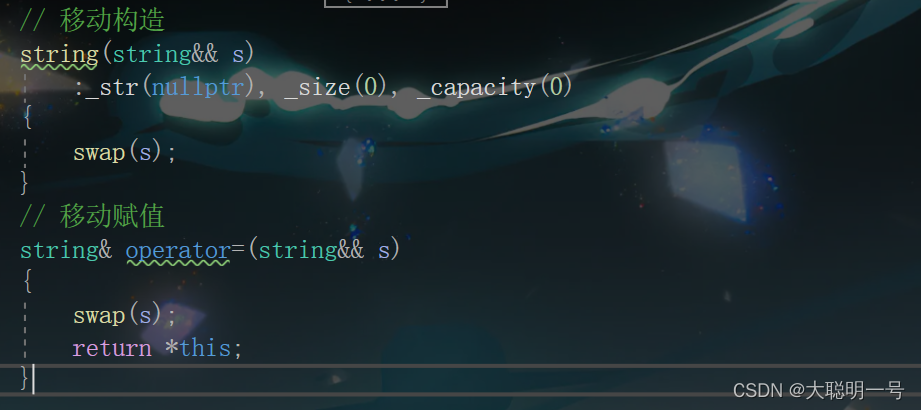
可以看到,移动构造和赋值都是进行内容的转移。这里和库里实现的效果一致。

s1的内容被s3窃取了。
移动构造和赋值一般都是把快要被释放掉资源的临时变量的资源进行转移,从而减少开销。上图演示的例子是错误示范。
🍪完美转发
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }
template<typename T>
void PerfectForward(T&& t)
{
//Fun(t);
//Fun(std::forward<T>(t)); // 完美转发
}
int test3()
{
PerfectForward(10); // 右值
int a;
PerfectForward(a); // 左值
PerfectForward(std::move(a)); // 右值
const int b = 8;
PerfectForward(b); // const 左值
PerfectForward(std::move(b)); // const 右值
return 0;
}

模板中的&&不代表右值引用,而是万能引用,其既能接收左值又能接收右值。
模板的万能引用只是提供了能够接收同时接收左值引用和右值引用的能力,
但是引用类型的唯一作用就是限制了接收的类型,后续使用中都退化成了左值,
我们希望能够在传递过程中保持它的左值或者右值的属性, 就需要用“完美转发”
std::forward 完美转发在传参的过程中保留对象原生类型属性,从而调用不同的函数,减少开销,提高性能。
🍪可变参数模板
template<class ...args>
void show(args...) // 显示args的参数列表个数
{
cout << sizeof...(args) << " ";
}
void print() {}
template<class T ,class ...args>
void print(T head, args ...rest)
{
cout << head << " ";
print(rest...);
}
void test3()
{
print(1, 2, 3.2, "x");
show(1, "2", 'x', 6);
}
可变参数通过函数递归来进行打印数据,由于这是编译时进行的,所以必须得重载个空函数来表示递归结束。
🍪lambda表达式
🥛用法
我们使用仿函数一般都是实行一些简单的内部控制,所以我们实现的仿函数一般功能都不会很复杂,而对细节的把控需求就会导致我们有时需要多个仿函数来实现。这样无疑就会定义很多仿函数,导致操作繁琐。
所以C++11推出了lambda表达式,其定义如下:
[捕捉列表](参数列表)mutable->返回值{函数体}
- 捕捉列表:默认是捕捉在同一生命周期的内的变量
[var] 按值捕捉
[&var] 引用捕捉
[=] 按值捕捉同一作用域里的所有变量
[&] 引用捕捉同一作用域里的所有变量
[this] 值传递方式捕捉当前的this指针
- 参数列表:传入的形式参数,和普通的函数列表一致,如果不需要参数,则()可以一起省略
- mutable:lambda函数是一个const函数的,mutable可以取消其常量属性。使用mutable时,参数列表不可以省略(即使参数为空)
- 返回值:即函数返回值
- 函数体:实现函数功能的区域
int main()
{
// 最简单的lambda表达式, 该lambda表达式没有任何意义
[]{};
// 省略参数列表和返回值类型,返回值类型由编译器推导为int
int a = 3, b = 4;
[=]{return a + 3; };
// 省略了返回值类型,无返回值类型
auto fun1 = [&](int c){b = a + c; };
fun1(10)
cout<<a<<" "<<b<<endl;
// 各部分都很完善的lambda函数
auto fun2 = [=, &b](int c)->int{return b += a+ c; };
cout<<fun2(10)<<endl;
// 复制捕捉x
int x = 10;
auto add_x = [x](int a) mutable { x *= 2; return a + x; };
cout << add_x(10) << endl;
return 0;
}
注意事项:
- 捕捉列表中的捕捉对象以逗号分隔
- 不可以重复捕捉
- lambda表达式之间不能相互赋值
🥛底层实现

通过反汇编我们可以初步观察到,其实lambda表达式在底层是调用了仿函数<lambda_1>::operator(),说到底还是对仿函数的封装。
实际在底层编译器对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的,即:如果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()
🍪包装器
function包装器,也叫作适配器。C++中的function本质是一个类模板,也是一个包装器
先说作用,包装器是对模板效率低下而做出的改进。
我们知道模板是针对不同类型的函数/类在编译的时候生成多种相对应的具体函数/类。在代码层面上看起来只有一份模板函数,而实际编译出来还是会有很多份代码。
如下列实例:
template<class F, class T>
T useF(F f, T x)
{
static int count = 0;
cout << "count:" << ++count << endl;
cout << "count:" << &count << endl;
return f(x);
}
double f(double i)
{
return i / 2;
}
struct Functor
{
double operator()(double d)
{
return d / 3;
}
};
int main()
{// 函数名
cout << useF(f, 11.11) << endl;
// 函数对象
cout << useF(Functor(), 11.11) << endl;
// lamber表达式
cout << useF([](double d)->double { return d / 4; }, 11.11) << endl;
return 0;
}

如图,生成了多份实例
为了优化这个问题,我们就要使用function了。
更改代码
int main()
{
// 函数名
function<double(double)> f1 = f;
cout << useF(f1, 2.0) << endl;
// 函数对象
function<double(double)> f2 = Functor();
cout << useF(f2, 3.0) << endl;
// lamber表达式
function<double(double)> f3 = [](double d)->double {return d / 4; };
cout << useF(f3, 4.0) << endl;
return 0;
}
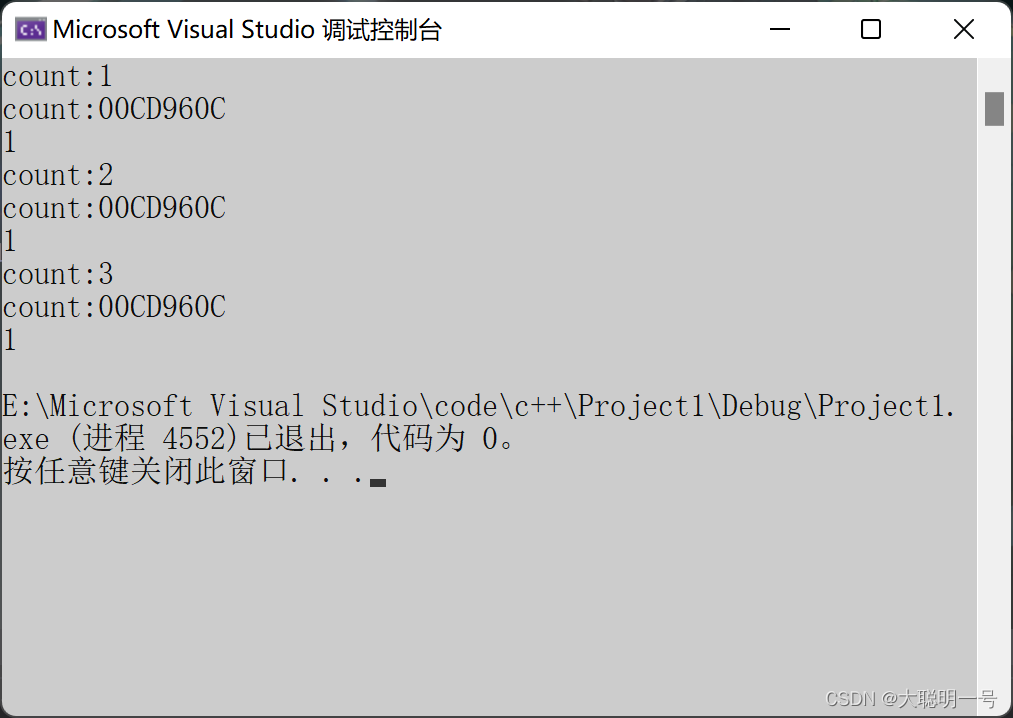
由此可观,function优化了模板的多重实例化。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









