







 本文介绍了一个Python脚本,用于从xlsx文件读取图片URL,去除重复数据,然后通过线程池并发下载图片。关键步骤包括使用pandas处理数据,线程池提高下载效率,以及requests库获取图片二进制数据并保存到本地。主要难点在于线程池的使用和避免重复下载。
本文介绍了一个Python脚本,用于从xlsx文件读取图片URL,去除重复数据,然后通过线程池并发下载图片。关键步骤包括使用pandas处理数据,线程池提高下载效率,以及requests库获取图片二进制数据并保存到本地。主要难点在于线程池的使用和避免重复下载。
需求是这样的,有一份包含上万条存放图片地址数据的xlsx文件,对该文件地址中的图片进行保存到本地。
部分数据
先是通过pandas模块读取xlsx表格(表格需同python源文件同目录),指定工作簿,由于存在大量重复数据,所以通过 df.drop_duplicates(subset为指定列,keep为首个(first)或尾个(last)保留,inplace=False为删除所有重复项) 来指定删除某列的重复数据,将整理过的数据追加到空列表(imageUrlList)中,备用。
表格中,最下面这里是sheet_name。
![]()

!!! 难点 !!!

拿到所有的下载链接后,由于要使用线程池提高效率,所以将上文得到的列表(包含着图片地址链接)进行拆分,一分为多,把一个列表拆分为包含多个子列表的父列表(图片中的moreImageUrlList)
通过该方法拆分,方法来源于https://blog.youkuaiyun.com/weixin_45300868/article/details/102808109

将拆分后的子列表存在父列表中,然后调用线程池,创建多个线程,通过for遍历父列表,得到每一个子列表(子列表包含着一批一批的图片地址链接),然后通过ThreadPoolExecutor(本文简称t)的submit()的方法,来多线程执行任务。submit()的第一个参数是被执行函数的名,第二个参数是给被执行函数携带的参数,还有第三个参数,表示以关键字参数的形式为被执行函数传参(本文未涉及)。

被执行的函数
静候大功告成,作者由于时间关系,并没有将程序执行到底。
下面上源代码:
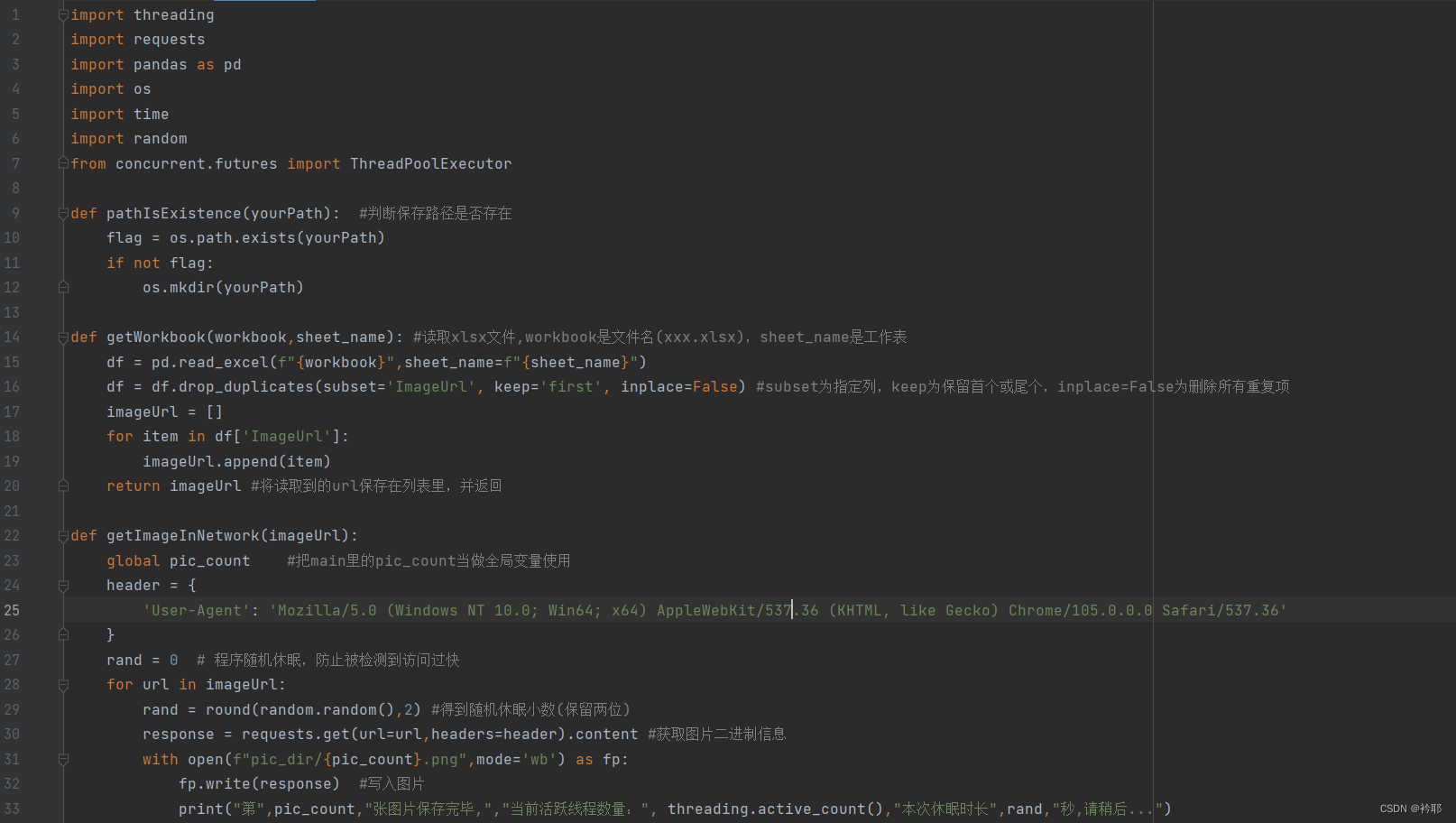
import threading
import requests
import pandas as pd
import os
import time
import random
from concurrent.futures import ThreadPoolExecutor
def pathIsExistence(yourPath): #判断保存路径是否存在
flag = os.path.exists(yourPath)
if not flag:
os.mkdir(yourPath)
def getWorkbook(workbook,sheet_name): #读取xlsx文件,workbook是文件名(xxx.xlsx),sheet_name是工作表
df = pd.read_excel(f"{workbook}",sheet_name=f"{sheet_name}")
df = df.drop_duplicates(subset='ImageUrl', keep='first', inplace=False) #subset为指定列,keep为保留首个或尾个,inplace=False为删除所有重复项
imageUrl = []
for item in df['ImageUrl']:
imageUrl.append(item)
return imageUrl #将读取到的url保存在列表里,并返回
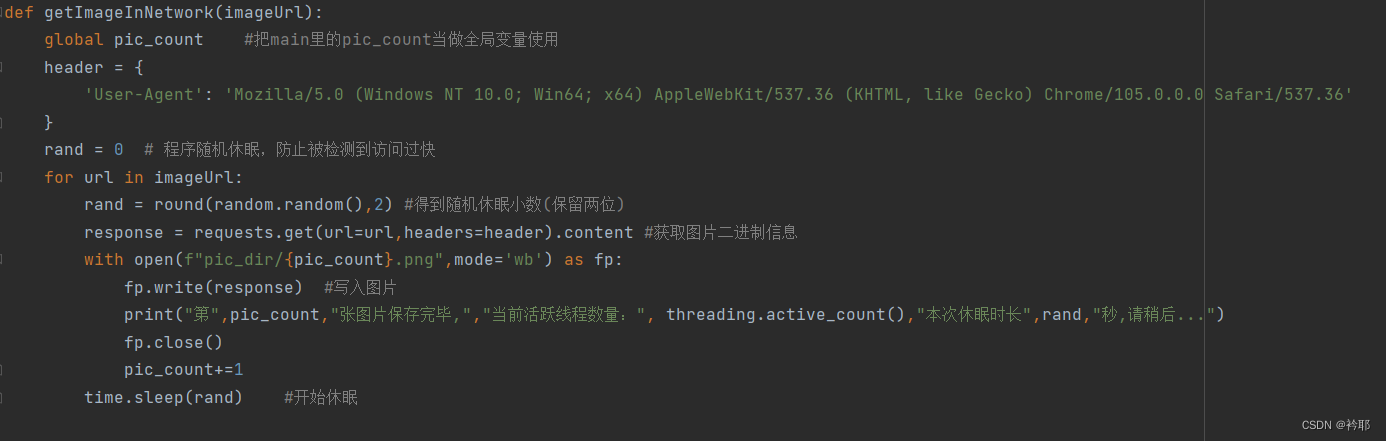
def getImageInNetwork(imageUrl):
global pic_count #把main里的pic_count当做全局变量使用
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
rand = 0 # 程序随机休眠,防止被检测到访问过快
for url in imageUrl:
rand = round(random.random(),2) #得到随机休眠小数(保留两位)
response = requests.get(url=url,headers=header).content #获取图片二进制信息
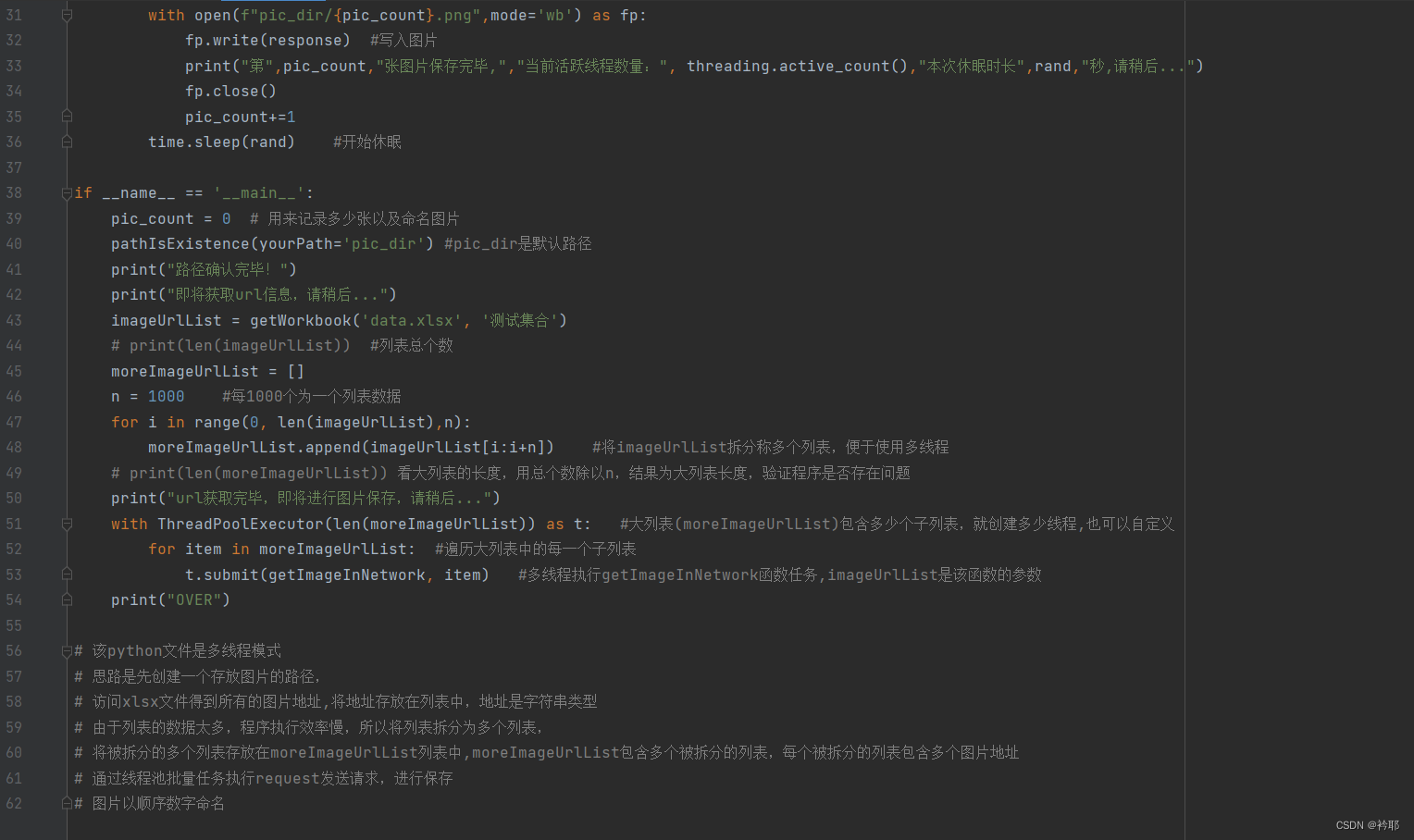
with open(f"pic_dir/{pic_count}.png",mode='wb') as fp:
fp.write(response) #写入图片
print("第",pic_count,"张图片保存完毕,","当前活跃线程数量:", threading.active_count(),"本次休眠时长",rand,"秒,请稍后...")
fp.close()
pic_count+=1
time.sleep(rand) #开始休眠
if __name__ == '__main__':
pic_count = 0 # 用来记录多少张以及命名图片
pathIsExistence(yourPath='pic_dir') #pic_dir是默认路径
print("路径确认完毕!")
print("即将获取url信息,请稍后...")
imageUrlList = getWorkbook('data.xlsx', '测试集合')
# print(len(imageUrlList)) #列表总个数
moreImageUrlList = []
n = 1000 #每1000个为一个列表数据
for i in range(0, len(imageUrlList),n):
moreImageUrlList.append(imageUrlList[i:i+n]) #将imageUrlList拆分称多个列表,便于使用多线程
# print(len(moreImageUrlList)) 看大列表的长度,用总个数除以n,结果为大列表长度,验证程序是否存在问题
print("url获取完毕,即将进行图片保存,请稍后...")
with ThreadPoolExecutor(len(moreImageUrlList)) as t: #大列表(moreImageUrlList)包含多少个子列表,就创建多少线程,也可以自定义
for item in moreImageUrlList: #遍历大列表中的每一个子列表
t.submit(getImageInNetwork, item) #多线程执行getImageInNetwork函数任务,imageUrlList是该函数的参数
print("OVER")
# 该python文件是多线程模式
# 思路是先创建一个存放图片的路径,
# 访问xlsx文件得到所有的图片地址,将地址存放在列表中,地址是字符串类型
# 由于列表的数据太多,程序执行效率慢,所以将列表拆分为多个列表,
# 将被拆分的多个列表存放在moreImageUrlList列表中,moreImageUrlList包含多个被拆分的列表,每个被拆分的列表包含多个图片地址
# 通过线程池批量任务执行request发送请求,进行保存
# 图片以顺序数字命名截图(方便查看行号):
看一下运行效果吧
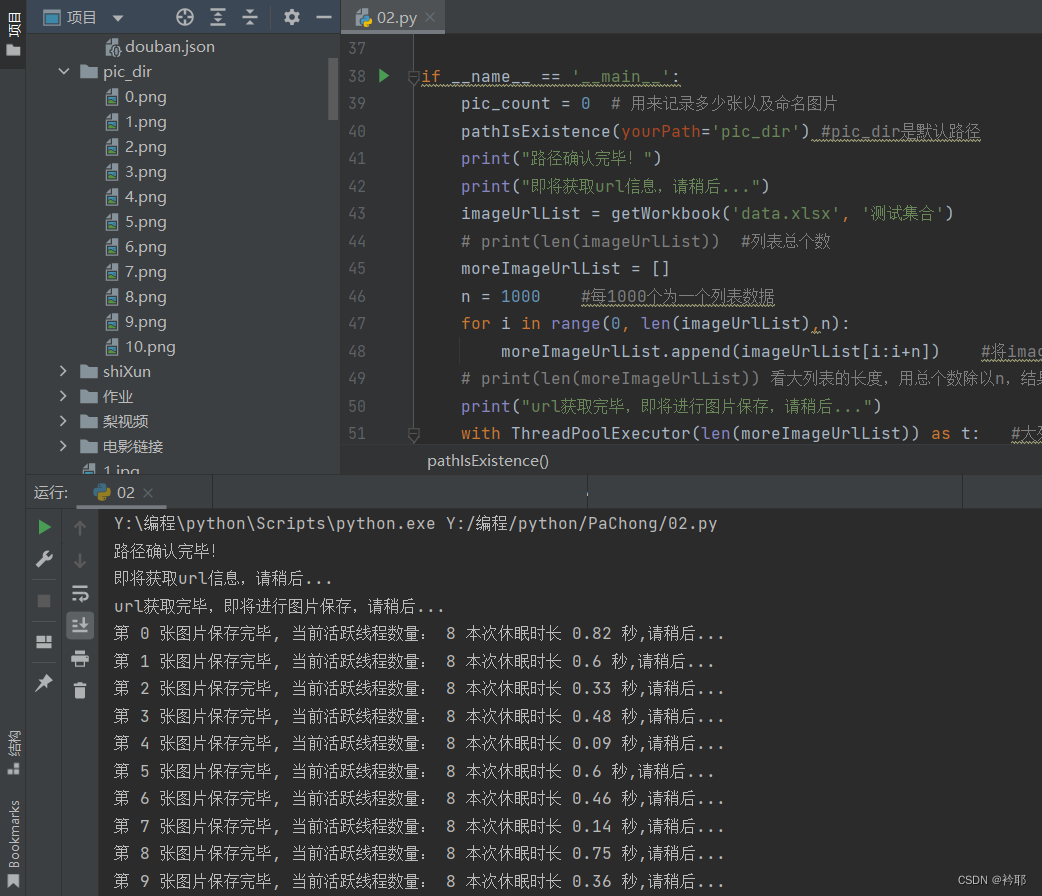
 用线程池还是很快滴
用线程池还是很快滴
说一下遇到的主要问题吧
1.调用线程池执行任务的时候,必须把包含所有图片地址链接的列表拆称多个子列表,才能用线程正常调用。否则只用一个包含所有地址链接的列表,用多线程调用它,就会产生多个线程执行同一任务的问题,多个线程请求同一张图片下载地址,造成资源浪费,保存效率低下,保存多张重复图片的问题。
2.线程池创建好后,需要用for循环为线程分配任务,否则会产生即使多个线程创建好,也没有被调用的问题。
3.用for循环为多线程分配任务时,for循环次数最好大于等于创建的线程个数。
注:部分库文件需要预先下载才能使用
通过设置的方法
也可以通过终端pip的方法(由于作者并不熟练,所以就不演示了)。

















 1412
1412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









