







目录
前几期我们已经学习了大部分哈希的知识点,除此之外还有位图,布隆过滤器和哈希切分这些知识点,本期我们将展开学习这些内容。
位图
何为位图?通过一个情景题为大家引入位图的概念。
问题:给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。
针对这个问题我们有以下解决方法:
1. 将这些40亿个整数存在数组中,依次进行遍历,时间复杂度为O(N)。
2.先进行交换排序,时间复杂度为O(NlogN),然后再进行二分查找,时间复杂度为logN。
3.采用位图的方法来解决。
什么是位图?
简单来说就是使用比特位表示一个整数在不在,在就将此位置1,不在就将此位置0。针对上述情景,40亿个整数,一个整数4个字节,所以如果用前两种方法将这40亿个整数存储在数组中,所消耗的空间总共就是16GB;如果一个比特位表示一个整数,最大的整数不过是42亿9000万,所以我们用42亿9000万个比特位就表示完所有整数,42亿9000万个比特位就是0.5GB,第3种方法比起前两种方法省去了很大一部分空间,所以使用第3种方法的优势就体现出来了。
位图的实现
位图的set
位图的set接口其实就是将当前int值所对应的比特位标记为存在,即比特位置1。
void set(int data)
{
//1.先查找是第几个字节
size_t num = data / 8;
//2.在当前字节的第几个位置
size_t index = data % 8;
_V[num] |= (1 << index);
}通过除和取模确定对应比特位的位置,然后通过按位或实现对应的比特位置1。
位图的reset
位图的reset就是将当前int值所对应的比特位标记为不存在,即比特位置0。
void reset(int data)
{
size_t num = data / 8;
size_t index = data % 8;
_V[num] &= ~(1 << index);
}通过除和取模确定对应比特位的位置,然后通过按位与实现对应的比特位置0。
位图的test
位图的test就是检测当前的int值所对应的比特位是0还是1,即判断比特位是0还是1。
bool test(int data)
{
size_t num = data / 8;
size_t index = data % 8;
return _V[num] & (1 << index);
}位图的整体代码
#pragma once
#include<iostream>
#include<vector>
namespace yjd
{
template<size_t N> //非类型模板参数,用来表示比特位的个数
class BitSet
{
public:
BitSet()
{
_V.resize(N / 8 + 1, 0);
}
void set(int data)
{
//1.先查找是第几个字节
size_t num = data / 8;
//2.在当前字节的第几个位置
size_t index = data % 8;
_V[num] |= (1 << index);
}
void reset(int data)
{
size_t num = data / 8;
size_t index = data % 8;
_V[num] &= ~(1 << index);
}
bool test(int data)
{
size_t num = data / 8;
size_t index = data % 8;
return _V[num] & (1 << index);
}
private:
std::vector<char> _V;
};
void testbitset()
{
BitSet<0XFFFFFFFF> bitset;
bitset.set(100);
bitset.set(200);
bitset.set(300);
std::cout << bitset.test(101) << std::endl;
std::cout << bitset.test(200) << std::endl;
std::cout << bitset.test(300) << std::endl;
bitset.reset(200);
std::cout << bitset.test(200) << std::endl;
}
}一般情况下,我们申请的比特位的个数就是int整型的个数,大约为42亿9千万个,42亿9千万即为-1或者0XFFFFFFFF。
运行结果如下。
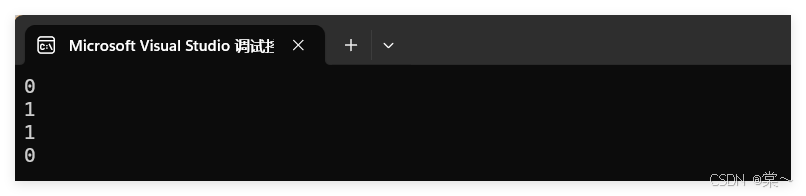
运行结果符合预期。
布隆过滤器
位图的优势很明显,就是节省内存空间,但同时缺点也很明显,就是只能存储整数,面对字符串时就显得无能为力,若我们把字符串通过哈希函数转成整型存储在位图之中,因为字符串是无限的,而整型是有限的,这就可能导致,不同的字符串通过哈希函数会转化成相同的整型值,所以此时就会产生哈希冲突,导致误判,即存在是误判的,不存在是准确的。
针对上述情景,名为布隆的大佬研究出了布隆过滤器。布隆过滤器底层其实还是位图,是封装了位图之后实现的,即通过不同的哈希算法,将字符串转成不同的整型值,然后再对这些整型值在位图里进行映射,只有当每个映射的比特位都为1时,才能表明当前字符串存在。这样哈希冲突的概率就会很大程度上降低,但是即使是这样,布隆过滤器也会存在误判,因为不能保证两个不同的字符串通过不同的哈希函数得到不同的整型。
布隆过滤器的实现
三个HashFunc仿函数
struct BKDRHash
{
size_t operator()(const string& s)
{
// BKDR
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
struct APHash
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (long i = 0; i < s.size(); i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
布隆过滤器的set
void set(const K& data)
{
BKDRHash hashfunc1;
APHash hashfunc2;
DJBHash hashfunc3;
size_t len = N * M;
int number1 = hashfunc1(data) % len;
int number2 = hashfunc2(data) % len;
int number3 = hashfunc3(data) % len;
_bitset.set(number1);
_bitset.set(number2);
_bitset.set(number3);
}set就是将字符串转为整型值之后,先将这些整型值置于比特位可以表示的范围,然后,再将这些整型值在位图中所对应的比特位置为1。
布隆过滤器的reset
void reset(const K& data)
{
BKDRHash hashfunc1;
APHash hashfunc2;
DJBHash hashfunc3;
size_t len = N * M;
int number1 = hashfunc1(data) % len;
int number2 = hashfunc2(data) % len;
int number3 = hashfunc3(data) % len;
_bitset.reset(number1);
_bitset.reset(number2);
_bitset.reset(number3);
}reset与set功能相反我们不做过多阐述。
布隆过滤器的test
bool test(const K& data)
{
BKDRHash hashfunc1;
APHash hashfunc2;
DJBHash hashfunc3;
size_t len = N * M;
int number1 = hashfunc1(data) % len;
int number2 = hashfunc2(data) % len;
int number3 = hashfunc3(data) % len;
return _bitset.test(number1) &&
_bitset.test(number2) &&
_bitset.test(number3);
}test需要测得每一个number在位图中的存在与否,必须都在才能保证当前字符串是出于布隆过滤器中的,如果一个number不在,那么就证明当前字符串是不在布隆过滤器中的。
布隆过滤器整体代码
#pragma once
#include"BitSet.h"
#include<string>
using namespace std;
using namespace yjd;
struct BKDRHash
{
size_t operator()(const string& s)
{
// BKDR
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
struct APHash
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (long i = 0; i < s.size(); i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
namespace yjd
{
template<size_t N ,size_t M=5,class K=string,
class HashFunc1=BKDRHash,class HashFunc2=APHash,class HashFunc3=DJBHash> //表示布隆过滤器元素的个数,字符串的个数
class BloomFilter
{
public:
void set(const K& data)
{
BKDRHash hashfunc1;
APHash hashfunc2;
DJBHash hashfunc3;
size_t len = N * M;
int number1 = hashfunc1(data) % len;
int number2 = hashfunc2(data) % len;
int number3 = hashfunc3(data) % len;
_bitset.set(number1);
_bitset.set(number2);
_bitset.set(number3);
}
void reset(const K& data)
{
BKDRHash hashfunc1;
APHash hashfunc2;
DJBHash hashfunc3;
size_t len = N * M;
int number1 = hashfunc1(data) % len;
int number2 = hashfunc2(data) % len;
int number3 = hashfunc3(data) % len;
_bitset.reset(number1);
_bitset.reset(number2);
_bitset.reset(number3);
}
bool test(const K& data)
{
BKDRHash hashfunc1;
APHash hashfunc2;
DJBHash hashfunc3;
size_t len = N * M;
int number1 = hashfunc1(data) % len;
int number2 = hashfunc2(data) % len;
int number3 = hashfunc3(data) % len;
return _bitset.test(number1) &&
_bitset.test(number2) &&
_bitset.test(number3);
}
private:
BitSet<N * M> _bitset;
};
void BloomFilterTest()
{
BloomFilter<100> bf;
srand(time(0));
size_t N = 100;
vector<string> v1;
for (size_t i = 0; i < N; ++i)
{
string url = "https://mp.youkuaiyun.com/mp_blog/creation/editor?spm=1000.2115.3001.4503";
url += to_string(1234 + i);
v1.push_back(url);
}
for (auto& str : v1)
{
bf.set(str);
}
for (auto& str : v1)
{
cout << bf.test(str) << endl;
}
cout << endl << endl;
vector<string> v2;
for (size_t i = 0; i < N; ++i)
{
string url = "https://mp.youkuaiyun.com/mp_blog/creation/editor?spm=1000.2115.3001.4503";
url += to_string(5678 + i);
v2.push_back(url);
}
size_t n2 = 0;
for (auto& str : v2)
{
if (bf.test(str))
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
}
}
运行结果如下。
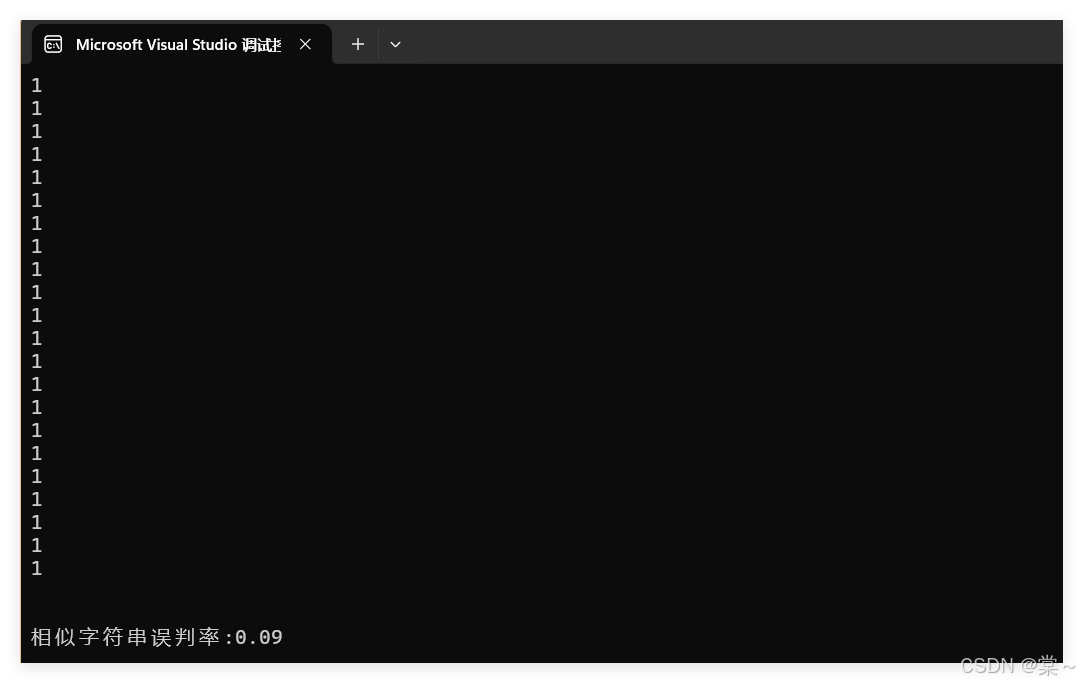
运行结果符合预期,但是可能有小伙伴会疑惑,这个误判率是什么,怎么样降低误判率?
其实这个误判其实就是存在误判了,原因是不同的字符串通过三个HashFunc函数得到了三个相同的值,所以当第一个字符串set之后,其实第二个字符串没有set,但是因为其三个整型值与第一个字符相同,第一个字符已经set了,所以就会导致第二个字符串及时没有set也得到了存在的误判。这个误判率其实可以通过第二个非类型模板参数的值进行降低,因为第二个非类型模板参数的值决定了位图中比特位的个数,比特位的个数越多,字符串通过HashFunc函数得到的整型值取模之后得到的值的排列也就越松散,也就越不可能与其他字符串得到整型值冲突,所以就可以适当地给定较大的第二个非类型模板参数的值,这样就可以很大程度上降低误判率。
总的来说,布隆过滤器不在一定不在,在不一定在。
布隆过滤器的应用
我们在多数应用登录时会遇到下面的界面,使用手机号和动态密码进行登录。
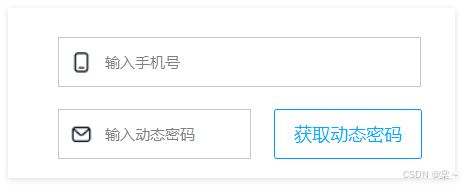
布隆过滤器的应用就是,把所有的用户的手机号先加载到布隆过滤器中,然后再前端输入手机号时,去布隆过滤器里查找当前手机号是否存在,存在再去数据库中去查找,不存在就不用去数据库查找,因为布隆过滤器在不一定在(存在误判),不在一定不在,可以大大提升数据检测效率。
哈希切分
通过一个情景为大家引入哈希切分的概念。
给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
如果我们直接使用map或者unordered_map去统计每个ip字符串出现的次数代价太大,在红黑树中有额外的颜色和三叉链节点指针的消耗,在哈希表中有节点指针的消耗,所以就更不用说原本总共数据100G的大小。所以我们可以把总共的文件分成200份,每一份的大小就是500MB,然后可以使用HashFunc函数计算出每个ip对应的整型值,然后将对应的ip放入对应的小内存中去,这样最终相同的ip一定会进入同一块小内存,然后统计每一块小内存中的ip的次数就是每种ip的次数。图示如下。

这便是哈希切分,通过哈希切分可以使数据离散化,然后统计离散区域的数据就可以得到整体的数据。
以上便是哈希剩余的全部内容。
本期内容到此结束^_^



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











