







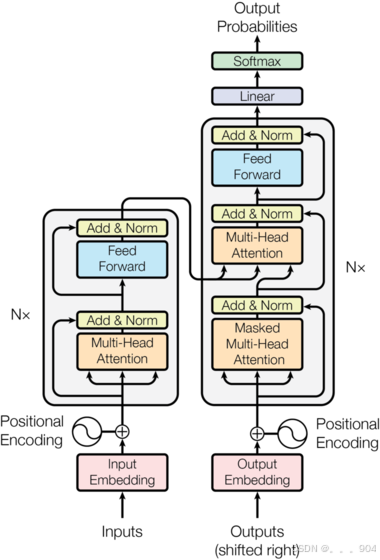
transformer架构
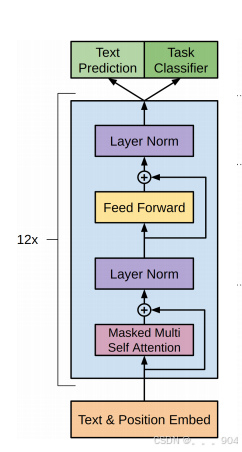
GPT架构
GPT的训练过程
数据准备阶段
训练GPT模型需要怎么的输入和标签?
解答这个问题,让我们回到GPT是如何根据一段话生成回答的,我们输入一个问题,然后GPT会根据这句话,预测回答,预测的时候,gpt其实是一个字一个字回答的,然后GPT每生成后一个字,都是根据我们的问题,以及它之前的回答组成上下文信息来进行生成新的一个字。根据这个流程,所以训练输入是一段话的前n-1个字组成的序列(这个序列是这段话中每个词在词表中的索引值),然后标签是后n-1个字组成的序列。注意输入GPT的序列长度都是相同的(如果我们输入的话大于规定的序列长度,会进行截断,小于规定的长度会进行填充,<pad>填充。输入模型的是这句话中每个词在索引表中索引值组成的序列,模型输出的是词表中每个词的概率。
2、GPT的模型架构
想想主要包括什么过程,每个过程有哪些模块?
输入模型的是一段话的序列,该序列已经经历数据准备阶段。首先该序列会经过词嵌入层,词嵌入层的形状是(vocab_size, embedding_size),词嵌入层会根据序列中每个词的索引值查找对应的行向量作为每个词的词嵌入向量,同时会对输入序列进行位置编码,位置编码层的形状为(seq_len, embedding_size),得到词嵌入向量和位置编码向量后,然后二者进行对应元素相加。然后将相加后的向量输入多头掩码自注意力模块,然后经历自注意力模块的输出和自注意力模块的输入进行残差连接,并进行层归一化。然后归一化层的输出进入前馈神经网络,前馈神经网络的输出和输入再进行残差连接,并进行层归一化。最后通过全连接网络得到预测结果。
多头掩码自注意力
公式:
首先对于掩码部分,掩码部分包括序列掩码和上下文掩码。序列掩码,由于我们需要保持输入的序列长度一致,所以队医一些比较短的数据,我们在数据准备阶段进行了pad填充,pad字符对应的索引值为0,所以序列掩码会将序列值为0的部分进行掩码,为了后续方便计算,序列掩码的形状为(seq_len, seq_len),比如模型规定输入的序列长度为4,但是我这段话只有2个词元,所以后面五个位置进行了pad填充,该序列掩码就为:
0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1
上下文掩码,在训练过程中,由于我们的输入序列和标签只是错开一位的关系,所以为了使模型不会使用未来的信息,提高泛化能力,所以进行了上下文掩码,上下文掩码是一个上三角矩阵,对角线的值为0,比如:
0 1 1 1 0 0 1 1 0 0 0 1 0 0 0 0
在得到序列掩码和上下文掩码后,将二者进行相加,然后将相加的结果中值不为0的位置的数值置为无穷小,值为0的位置依旧保持为0,得到公式中的Mask,比如:
0 1 2 2 0 -inv -inv -inv 0 0 2 2 0 0 -inv -inv 0 0 1 2----->0 0 -inv -inv 0 0 1 1 0 0 -inv -inv
也就是Mask引用在自注意力分数计算后,Softmax归一化之前。使得模型的自注意力矩阵不包含未来信息和空(pad填充)信息
代码:
# 序列掩码 def get_attn_pad_mask(seq_q, seq_k): # seq_q: [batch_size, seq_len] ,seq_k: [batch_size, seq_len] ''' 这里seq_q是查询序列(用于生成查询向量的序列,里面的值是每个词在词表中对应索引值), 这里seq_q是键值序列(用于生成键值向量的序列,里面的值是每个词在词表中对应索引值) ''' batch_size, len_q = seq_q.size() batch_size, len_k = seq_k.size() pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # 判断 输入那些含有P(=0),用1标记 ,[batch_size, 1, len_k] return pad_attn_mask.expand(batch_size, len_q, len_k) # 上下文掩码 def get_attn_subsequence_mask(seq): # seq: [batch_size, tgt_len] ''' seq是输入序列(里面的值还未经词嵌入,是每个词在词表中对应的索引值) 返回一个上三角矩阵,对角线的值为0 ''' attn_shape = [seq.size(0), seq.size(1), seq.size(1)] subsequence_mask = np.triu(np.ones(attn_shape), k=1) # 生成上三角矩阵,[batch_size, tgt_len, tgt_len] subsequence_mask = torch.from_numpy(subsequence_mask).byte() # [batch_size, tgt_len, tgt_len] subsequence_mask = subsequence_mask.to(device) return subsequence_mask # 缩放点积注意力计算 class ScaledDotProductAttention(nn.Module): def __init__(self): super(ScaledDotProductAttention, self).__init__() def forward(self, Q, K, V, attn_mask): ''' Q: [batch_size, n_heads, len_q, d_k] K: [batch_size, n_heads, len_k, d_k] V: [batch_size, n_heads, len_v(=len_k), d_v] attn_mask: [batch_size, n_heads, seq_len, seq_len] ''' scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k] scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True. attn = nn.Softmax(dim=-1)(scores) context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v] return context, attn #多头注意力计算 class MultiHeadAttention(nn.Module): def __init__(self): super(MultiHeadAttention, self).__init__() self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False) self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False) self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False) self.fc = nn.Linear(n_heads * d_v, d_model, bias=False) self.layernorm = nn.LayerNorm(d_model) def forward(self, input_Q, input_K, input_V, attn_mask): ''' input_Q: [batch_size, len_q, d_model] input_K: [batch_size, len_k, d_model] input_V: [batch_size, len_v(=len_k), d_model] attn_mask: [batch_size, seq_len, seq_len] ''' residual, batch_size = input_Q, input_Q.size(0) # (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W) Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # Q: [batch_size, n_heads, len_q, d_k] K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # K: [batch_size, n_heads, len_k, d_k] V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # V: [batch_size, n_heads, len_v(=len_k), d_v] attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len] # context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k] context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask) context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v] output = self.fc(context) # [batch_size, len_q, d_model] return self.layernorm(output + residual), attn
前馈神经网络层
代码:代码实现中体现了残差连接和层归一化
class PoswiseFeedForwardNet(nn.Module): def __init__(self): super(PoswiseFeedForwardNet, self).__init__() self.fc = nn.Sequential( nn.Linear(d_model, d_ff, bias=False), nn.ReLU(), nn.Linear(d_ff, d_model, bias=False)) self.layernorm = nn.LayerNorm(d_model) def forward(self, inputs): # inputs: [batch_size, seq_len, d_model] residual = inputs output = self.fc(inputs) return self.layernorm(output + residual) # 残差 + LayerNorm
解码器
GPT模型中包含了12个相同的解码器层
代码:
# 解码器层 class DecoderLayer(nn.Module): def __init__(self): super(DecoderLayer, self).__init__() self.dec_self_attn = MultiHeadAttention() self.pos_ffn = PoswiseFeedForwardNet() def forward(self, dec_inputs, dec_self_attn_mask): ''' dec_inputs: [batch_size, tgt_len, d_model] dec_self_attn_mask: [batch_size, tgt_len, tgt_len] ''' # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len] dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask) dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model] return dec_outputs, dec_self_attn # 解码器模块 class Decoder(nn.Module): def __init__(self): super(Decoder, self).__init__() self.tgt_emb = nn.Embedding(vocab_size, d_model) self.pos_emb = nn.Embedding(seq_len, d_model) self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) def forward(self, dec_inputs): ''' dec_inputs: [batch_size, tgt_len] ''' # 构建position embedding seq_len = dec_inputs.size(1) pos = torch.arange(seq_len, dtype=torch.long, device=device) pos = pos.unsqueeze(0).expand_as(dec_inputs) # [seq_len] -> [batch_size, seq_len] word_emb = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model] pos_emb = self.pos_emb(pos) # [batch_size, tgt_len, d_model] dec_outputs = word_emb + pos_emb dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) # [batch_size, tgt_len, tgt_len] dec_self_attn_subsequent_mask = get_attn_subsequence_mask(dec_inputs) # [batch_size, tgt_len] dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0) # [batch_size, tgt_len, tgt_len] dec_self_attns = [] for layer in self.layers: # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len] dec_outputs, dec_self_attn = layer(dec_outputs, dec_self_attn_mask) dec_self_attns.append(dec_self_attn) return dec_outputs, dec_self_attns
问答GPT构建
前面所有的模块已经构建好,这里就是拼接模块使之成为完整的GPT
class GPT(nn.Module):
def __init__(self):
super(GPT, self).__init__()
self.decoder = Decoder()
self.projection = nn.Linear(d_model, vocab_size, bias=False)
def forward(self, dec_inputs):
"""
dec_inputs: [batch_size, tgt_len]
"""
# dec_outpus: [batch_size, tgt_len, d_model], dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len]
dec_outputs, dec_self_attns = self.decoder(dec_inputs)
# dec_logits: [batch_size, tgt_len, tgt_vocab_size]
dec_logits = self.projection(dec_outputs)
return dec_logits.view(-1, dec_logits.size(-1)), dec_self_attns
def answer(self, above): # 生成回复
dec_input = [vocab[word] for word in above]
dec_input.append(vocab['<sep>']) # 原始句子后面增加<sep>
dec_input = torch.tensor(dec_input, dtype=torch.long, device=device).unsqueeze(0)
# 循环生成下一个单词
for i in range(100):
dec_outputs, _ = self.decoder(dec_input)
projected = self.projection(dec_outputs)
prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
next_id = prob.data[-1]
if next_id == vocab["<sep>"]: # 到出现"<sep>"结束
break
dec_input = torch.cat(
[dec_input.detach(), torch.tensor([[next_id]], dtype=dec_input.dtype, device=device)], -1)
output = dec_input.squeeze(0)
sequence = [vocab[int(id)] for id in output] # id转文字
answer = "".join(sequence)
answer = answer[answer.rindex("<sep>")+5: ] # 取最后一个<sep>后面部分, +5 是加上<seq>本身的长度
return answer
构建一个最简单的问答GPT完整代码:
# 1、数据准备
with open('弱智吧语料.txt', 'r', encoding='utf-8') as f:
datas = f.readlines()
datas[:3]
# 数据清洗,只保留中文 content = ''.join(datas) # 拼接所有的字符串,并不使用分隔符 special_char = re.sub(r'[\u4e00-\u9fa5]', ' ', content) # [\u4e00-\u9fa5]代表所有中文,取出所有不是中文的字符并放在special_char中 print(set(special_char) - set(string.ascii_letters) - set(string.digits)) # string.ascii_letters表示所有英文,string.digits表示所有数字
# 词元化,也就是tokenizer,这里暂时用到的语料中,\t表示分离两人的对话,\n表示分开两段对话
def tokenizer(datas):
tokens = []
for data in datas:
data = data.strip().replace('\n', '') # 将\n替换为空
token = [i if i!='\t' else "<sep>" for i in data]+['<sep>']
tokens.append(token)
return tokens
tokens = tokenizer(datas)
# 这里模拟构建词表,真实场景往往有现有的大词表,不需要我们自己构建
flatten = lambda l: [item for sublist in l for item in sublist] # 展平数组
# 构建词表
class Vocab:
def __init__(self, tokens):
self.tokens = tokens # 传入的tokens是二维列表
self.token2index = {'<pad>': 0, '<unk>': 1, '<seq>': 2} # 先存好特殊词元
# 将词元按词频排序后生成列表
self.token2index.update({
token: index + 3
for index, (token, freq) in enumerate(
sorted(Counter(flatten(self.tokens)).items(), key=lambda x: x[1], reverse=True))
})
# 构建id到词元字典
self.index2token = {index: token for token, index in self.token2index.items()}
def __getitem__(self, query):
# 单一索引
if isinstance(query, (str, int)):
if isinstance(query, str):
return self.token2index.get(query, 0)
elif isinstance(query, (int)):
return self.index2token.get(query, '<unk>')
# 数组索引
elif isinstance(query, (list, tuple)):
return [self.__getitem__(item) for item in query]
def __len__(self):
return len(self.index2token)
#实例化词表
vocab = Vocab(tokens)
vocab_size = len(vocab)
# 构造数据集和加载器
# 构建自己的数据集类
class MyDataSet(Data.Dataset):
def __init__(self,datas,vocab):
self.vocab = vocab
self.datas = [[vocab[word] for word in line] for line in datas] # 把输入的tokens转成其在词表中对应的序列表示,方便后续输入模型
def __getitem__(self, item):
data = self.datas[item]
decoder_input = data[:-1]
decoder_output = data[1:]
decoder_input_len = len(decoder_input)
decoder_output_len = len(decoder_output)
return {"decoder_input":decoder_input,"decoder_input_len":decoder_input_len,
"decoder_output":decoder_output,"decoder_output_len":decoder_output_len}
def __len__(self):
return len(self.datas)
def padding_batch(self,batch):
# 批处理, 对每个批次的数据中,长度不够的序列填充<pad>
decoder_input_lens = [d["decoder_input_len"] for d in batch]
decoder_output_lens = [d["decoder_output_len"] for d in batch]
decoder_input_maxlen = max(decoder_input_lens)
decoder_output_maxlen = max(decoder_output_lens)
for d in batch:
d["decoder_input"].extend([vocab["<pad>"]]*(decoder_input_maxlen-d["decoder_input_len"]))
d["decoder_output"].extend([vocab["<pad>"]]*(decoder_output_maxlen-d["decoder_output_len"]))
decoder_inputs = torch.tensor([d["decoder_input"] for d in batch], dtype=torch.long)
decoder_outputs = torch.tensor([d["decoder_output"] for d in batch], dtype=torch.long)
return decoder_inputs,decoder_outputs
# 数据加载器 batch_size = 2 dataset = MyDataSet(tokens, vocab) data_loader = Data.DataLoader(dataset, batch_size=batch_size, collate_fn=dataset.padding_batch)
# mask掉没有意义的占位符 def get_attn_pad_mask(seq_q, seq_k): # seq_q: [batch_size, seq_len] ,seq_k: [batch_size, seq_len] ''' 这里seq_q是查询序列(用于生成查询向量的序列,里面的值是每个词在词表中对应索引值), 这里seq_q是键值序列(用于生成键值向量的序列,里面的值是每个词在词表中对应索引值) ''' batch_size, len_q = seq_q.size() batch_size, len_k = seq_k.size() pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # 判断 输入那些含有P(=0),用1标记 ,[batch_size, 1, len_k] return pad_attn_mask.expand(batch_size, len_q, len_k) # mask掉未来信息 def get_attn_subsequence_mask(seq): # seq: [batch_size, tgt_len] ''' seq是输入序列(里面的值还未经词嵌入,是每个词在词表中对应的索引值) 返回一个上三角矩阵,对角线的值为0 ''' attn_shape = [seq.size(0), seq.size(1), seq.size(1)] subsequence_mask = np.triu(np.ones(attn_shape), k=1) # 生成上三角矩阵,[batch_size, tgt_len, tgt_len] subsequence_mask = torch.from_numpy(subsequence_mask).byte() # [batch_size, tgt_len, tgt_len] subsequence_mask = subsequence_mask.to(device) return subsequence_mask
# 缩放点积注意力计算 class ScaledDotProductAttention(nn.Module): def __init__(self): super(ScaledDotProductAttention, self).__init__() def forward(self, Q, K, V, attn_mask): ''' Q: [batch_size, n_heads, len_q, d_k] K: [batch_size, n_heads, len_k, d_k] V: [batch_size, n_heads, len_v(=len_k), d_v] attn_mask: [batch_size, n_heads, seq_len, seq_len] ''' scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k] scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True. attn = nn.Softmax(dim=-1)(scores) context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v] return context, attn
#多头注意力计算 class MultiHeadAttention(nn.Module): def __init__(self): super(MultiHeadAttention, self).__init__() self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False) self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False) self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False) self.fc = nn.Linear(n_heads * d_v, d_model, bias=False) self.layernorm = nn.LayerNorm(d_model) def forward(self, input_Q, input_K, input_V, attn_mask): ''' input_Q: [batch_size, len_q, d_model] input_K: [batch_size, len_k, d_model] input_V: [batch_size, len_v(=len_k), d_model] attn_mask: [batch_size, seq_len, seq_len] ''' residual, batch_size = input_Q, input_Q.size(0) # (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W) Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # Q: [batch_size, n_heads, len_q, d_k] K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # K: [batch_size, n_heads, len_k, d_k] V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # V: [batch_size, n_heads, len_v(=len_k), d_v] attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len] # context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k] context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask) context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v] output = self.fc(context) # [batch_size, len_q, d_model] return self.layernorm(output + residual), attn
class PoswiseFeedForwardNet(nn.Module): def __init__(self): super(PoswiseFeedForwardNet, self).__init__() self.fc = nn.Sequential( nn.Linear(d_model, d_ff, bias=False), nn.ReLU(), nn.Linear(d_ff, d_model, bias=False)) self.layernorm = nn.LayerNorm(d_model) def forward(self, inputs): # inputs: [batch_size, seq_len, d_model] residual = inputs output = self.fc(inputs) return self.layernorm(output + residual)
# 解码器层 class DecoderLayer(nn.Module): def __init__(self): super(DecoderLayer, self).__init__() self.dec_self_attn = MultiHeadAttention() self.pos_ffn = PoswiseFeedForwardNet() def forward(self, dec_inputs, dec_self_attn_mask): ''' dec_inputs: [batch_size, tgt_len, d_model] dec_self_attn_mask: [batch_size, tgt_len, tgt_len] ''' # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len] dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask) dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model] return dec_outputs, dec_self_attn
# 解码器模块 class Decoder(nn.Module): def __init__(self): super(Decoder, self).__init__() self.tgt_emb = nn.Embedding(vocab_size, d_model) self.pos_emb = nn.Embedding(seq_len, d_model) self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) def forward(self, dec_inputs): ''' dec_inputs: [batch_size, tgt_len] ''' # 构建position embedding seq_len = dec_inputs.size(1) pos = torch.arange(seq_len, dtype=torch.long, device=device) pos = pos.unsqueeze(0).expand_as(dec_inputs) # [seq_len] -> [batch_size, seq_len] word_emb = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model] pos_emb = self.pos_emb(pos) # [batch_size, tgt_len, d_model] dec_outputs = word_emb + pos_emb dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) # [batch_size, tgt_len, tgt_len] dec_self_attn_subsequent_mask = get_attn_subsequence_mask(dec_inputs) # [batch_size, tgt_len] dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0) # [batch_size, tgt_len, tgt_len] dec_self_attns = [] for layer in self.layers: # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len] dec_outputs, dec_self_attn = layer(dec_outputs, dec_self_attn_mask) dec_self_attns.append(dec_self_attn) return dec_outputs, dec_self_attns
class GPT(nn.Module):
def __init__(self):
super(GPT, self).__init__()
self.decoder = Decoder()
self.projection = nn.Linear(d_model, vocab_size, bias=False)
def forward(self, dec_inputs):
"""
dec_inputs: [batch_size, tgt_len]
"""
# dec_outpus: [batch_size, tgt_len, d_model], dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len]
dec_outputs, dec_self_attns = self.decoder(dec_inputs)
# dec_logits: [batch_size, tgt_len, tgt_vocab_size]
dec_logits = self.projection(dec_outputs)
return dec_logits.view(-1, dec_logits.size(-1)), dec_self_attns
def answer(self, above): # 生成回复
dec_input = [vocab[word] for word in above]
dec_input.append(vocab['<sep>']) # 原始句子后面增加<sep>
dec_input = torch.tensor(dec_input, dtype=torch.long, device=device).unsqueeze(0)
# 循环生成下一个单词
for i in range(100):
dec_outputs, _ = self.decoder(dec_input)
projected = self.projection(dec_outputs)
prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
next_id = prob.data[-1]
if next_id == vocab["<sep>"]: # 到出现"<sep>"结束
break
dec_input = torch.cat(
[dec_input.detach(), torch.tensor([[next_id]], dtype=dec_input.dtype, device=device)], -1)
output = dec_input.squeeze(0)
sequence = [vocab[int(id)] for id in output] # id转文字
answer = "".join(sequence)
answer = answer[answer.rindex("<sep>")+5: ] # 取最后一个<sep>后面部分, +5 是加上<seq>本身的长度
return answer
# 定义超参数
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
seq_len = 300 # 序列最大长度
d_model = 768 # Embedding维度
d_ff = 2048 # 前馈层维度
d_k = d_v = 64 # QKV维度
n_layers = 6 # 解码器层数
n_heads = 8 # 多头注意力头数
batch_size = 64
epochs = 30
# 定义模型
model = GPT().to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss(ignore_index=0).to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-4)
loss_history = [] # 记录损失变化
for epoch in range(epochs):
model.train()
epoch_loss = 0
for i, (dec_inputs, dec_outputs) in enumerate(tqdm(data_loader)):
optimizer.zero_grad()
dec_inputs, dec_outputs =dec_inputs.to(device), dec_outputs.to(device)
# outputs: [batch_size * tgt_len, tgt_vocab_size]
outputs, dec_self_attns = model(dec_inputs)
loss = criterion(outputs, dec_outputs.view(-1))
epoch_loss += loss.item()
loss.backward()
optimizer.step()
train_loss = epoch_loss / len(data_loader)
loss_history.append(train_loss) # 记录损失变化
print(f'\tTrain Loss: {train_loss:.3f}')
torch.save(model.state_dict(), 'gpt_chat.pt') # 保存模型
model = GPT().to(device)
model.load_state_dict(torch.load('gpt_chat.pt')) # 加载训练好的模型
model.eval()
ask = "只剩一个心脏了还能活吗?"
print(model.answer(ask))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









