






1.学习率lr
找到最佳学习速度以加快收敛,决定了更新权重的速度。
- 如果学习率太小,则需要很长时间才能达到最低点 ,容易过拟合,也容易陷入“局部最优”点;
- 如果学习率太大,它可能会从底部摆动。梯度容易爆炸,loss的振幅较大,模型难以收敛;
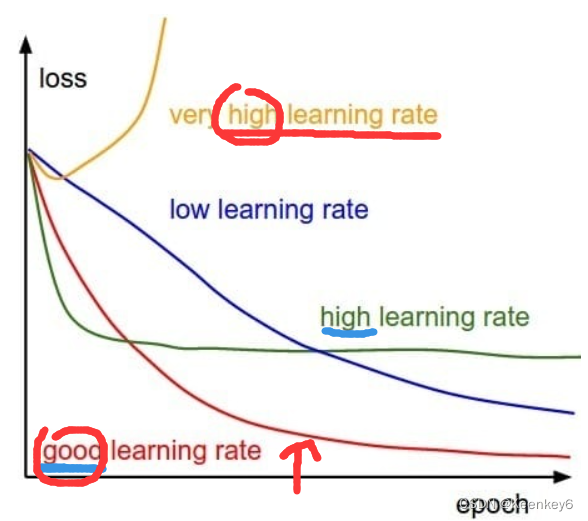
这个学习率就不是很好,还没调好
根据lr的理论有效区间,我们最大可以设置最小为0.000001,最大为1。当然不同的模型会有不同的区间,一般情况下NLP的有效区间值会更小一些,可以适当调低最大lr;CV的可以适当调高最小lr,具体模型根据具体情况来设置。
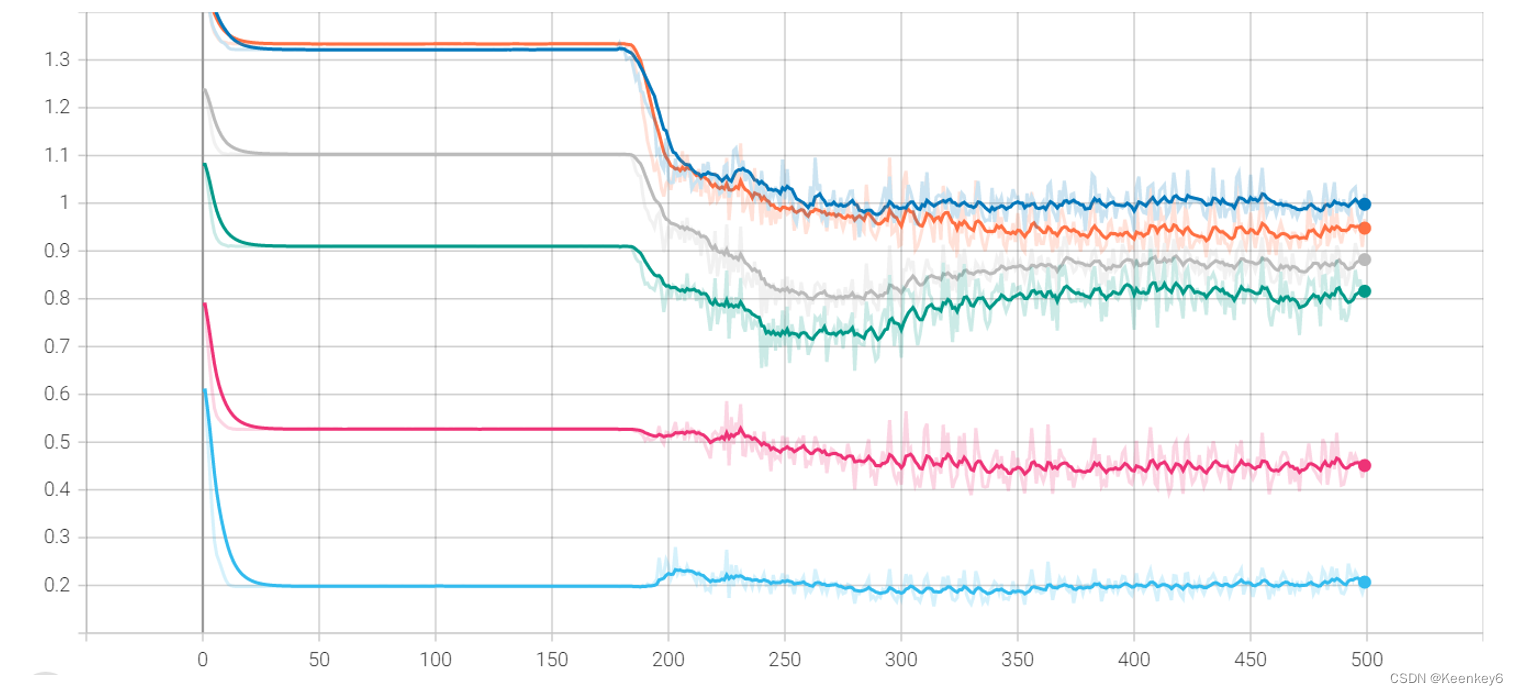
PS:loss下降后又上升
当前遇到的问题:loss下降到0.23之后,又上升到0.27了
原本不断下降的,但是这里是不断下降之后,到达一个临界点,又上升了:
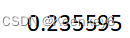
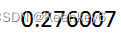
分析方向:
- 模型可以学习到,只是剃度震荡导致降不到最优,这种可以考虑降低学习率,增大batch的大小。
- 数据可以学习到,但是模型拟合能力不够强。可以考虑增大深度
- 增大训练数据,或正则方法比如bn,dropout等
- 脏数据,有白边
batchsize过小,或者学习率太大,动态降低学习率
2.epoch
跟数据有关系
在神经网络中传递完整的数据集一次是不够的,而且我们需要将完整的数据集在同样的神经网络中传递多次。我们使用的是有限的数据集,并且我们使用一个迭代过程即梯度下降,优化学习过程和图示。因此仅仅更新权重一次或者说使用一个 epoch 是不够的。
3.batch_size
batchsize 的正确选择是为了在内存效率和内存容量之间寻找最佳平衡。Batch Size的大小影响模型的优化程度和速度。同时其直接影响到GPU内存的使用情况,假如你GPU内存不大,该数值最好设置小一点
- 样本量N<=2000时,用batch梯度下降
- 样本量很大时,用mini-batch梯度下降,batch_size的大小通常取64,128,256,512.
保证符合CPU\GPU的数据存储的方式,这样读取数据更快吧?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









