







本节主要介绍和了解KNN算法。
前言
k近邻法(k-nearest neighbor ,k-NN)是一种基本分类与回归方法,本节只讨论分类问题中的k近邻法。k近邻法的输入为实例的特征向量,对应于特征空间的点,输出为实例的类别,可以取多类。
思想:k近邻假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻不具有显示的学习过程。k近邻实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。
k值的选择,距离的度量即分类决策规则是k邻近法的三要素。
一、k邻近算法

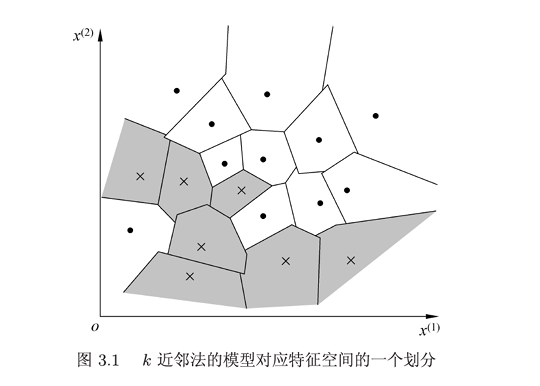
二、k近邻模型
k近邻法使用的模型实际上对应于对特征空间的划分。模型由三个基本要素:1.距离度量2.k值选择3.分类决策规则决定。
1.模型

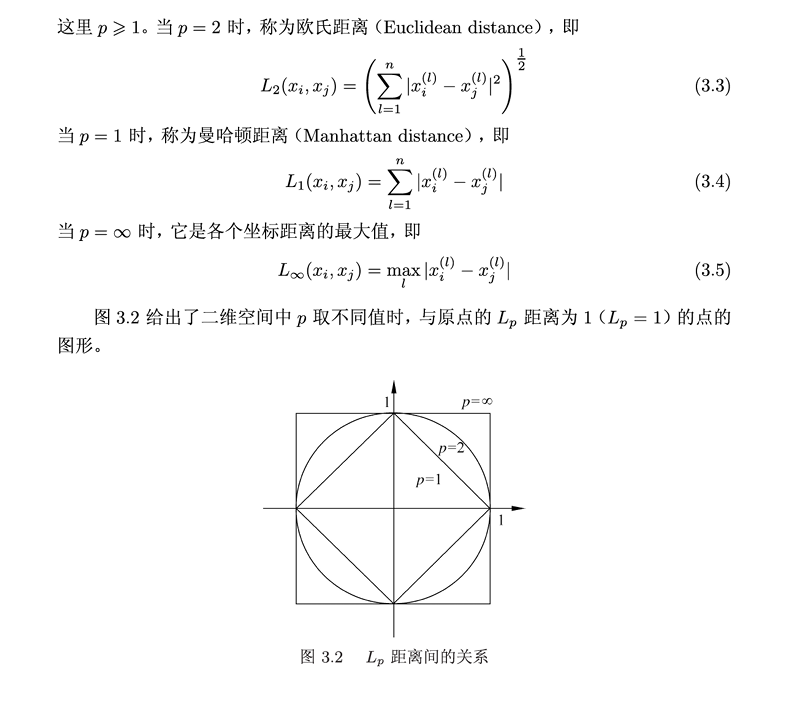
2.距离度量
书上只介绍了三种距离用公式表达出,还是比较好理解的,能看懂公式就能理解,后续我还会补充各种距离和每种距离的区别。工作量有点大。


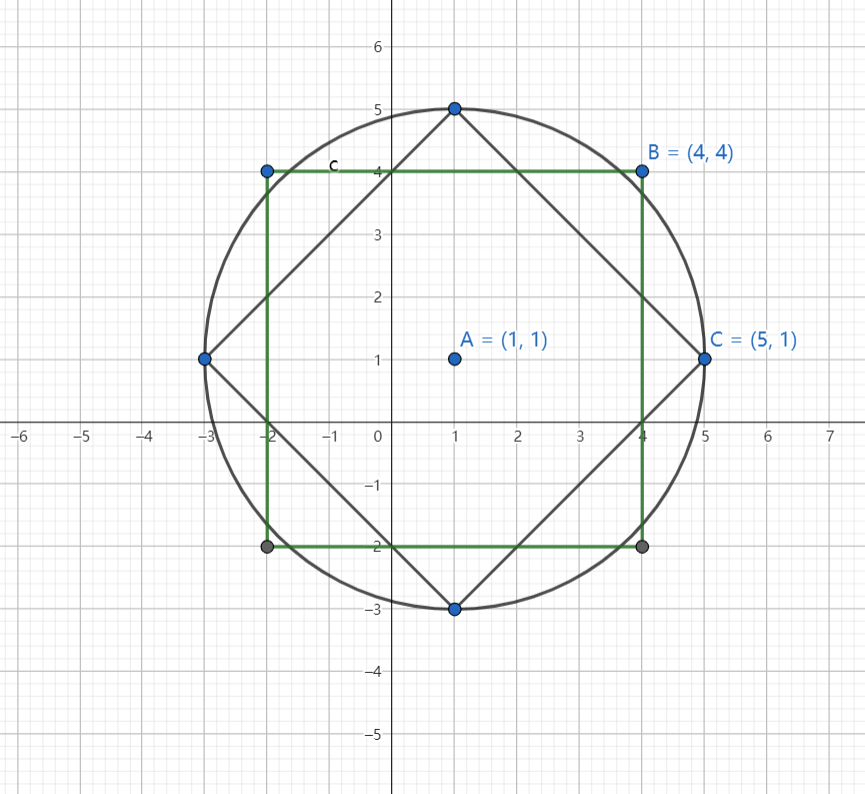
3.k值的选择

4.分类决策规则

三、k近邻的实现:kd树

1.构造kd树




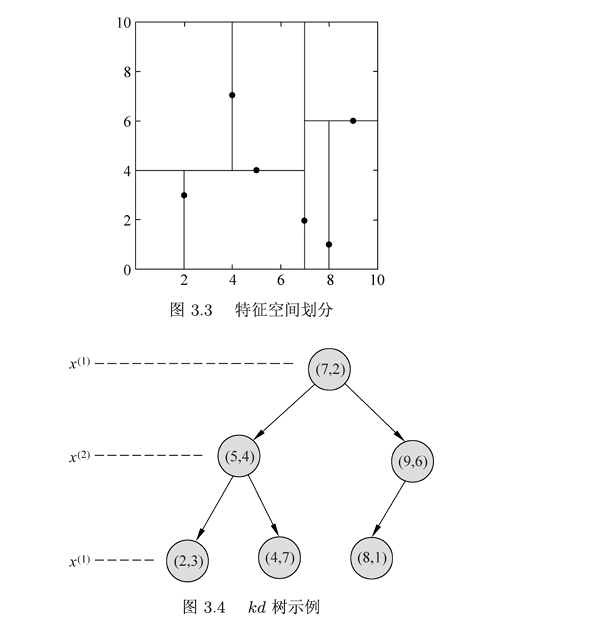
2.kd树的搜索
kd树的最近邻搜索



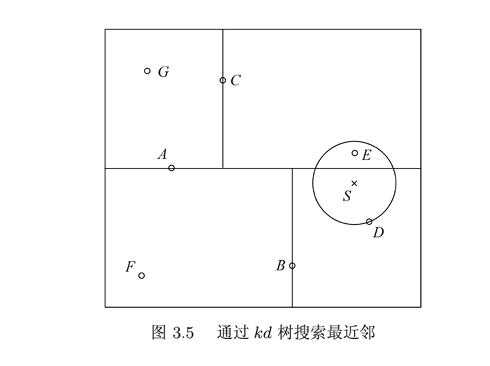
kd树的k邻近搜索
思想:在kd树的最邻近搜索上挑选k个临近点,kd树的深度优先遍历,这块经过寻找资料很少,有几篇博客还有点难懂,大部分都只是讲讲kd树的最邻近搜索,给出例子,只是通过做题的思想,还是欠缺。
说说我的思想:(不知道自己有没有想错)
1.首先根据深度优先遍历找到所要判断的点所在的叶节点,叶节点中如果个数大于k,选取k个距离最小的节点。
2.向上遍历看根节点的另一个子树是否可能成为k近邻的点,判断方法就是:判断的点与边界的距离和k个最小节点中的最大距离比较,在图形上显示就是圆是否与边界相交,相交则在另一个子树继续寻找,不相交那就说明另一个子树的点不可能成为k近邻的点。
3.判断根节点是否可以成为k近邻的点。如此往复,最后遍历到最顶根节点结束。
这个文字写起来传达的信息还是不够清楚,有时间会出一个视频拿个例子来讲一下。
总结




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











