







- 学习:知识的初次邂逅
- 复习:知识的温故知新
- 练习:知识的实践应用
目录
一,原题力扣链接
Pandas
二,题干
表:
Drivers+-------------+---------+ | Column Name | Type | +-------------+---------+ | driver_id | int | | join_date | date | +-------------+---------+ driver_id 是该表具有唯一值的列。 该表的每一行均包含驾驶员的 ID 以及他们加入 Hopper 公司的日期。表:
Rides+--------------+---------+ | Column Name | Type | +--------------+---------+ | ride_id | int | | user_id | int | | requested_at | date | +--------------+---------+ ride_id 是该表具有唯一值的列。 该表的每一行均包含行程 ID(ride_id),用户 ID(user_id) 以及该行程的日期(requested_at)。 该表中可能有一些不被接受的乘车请求。表:
AcceptedRides+---------------+---------+ | Column Name | Type | +---------------+---------+ | ride_id | int | | driver_id | int | | ride_distance | int | | ride_duration | int | +---------------+---------+ ride_id 是该表具有唯一值的列。 该表的每一行都包含已接受的行程信息。 表中的行程信息都在 "Rides" 表中存在。编写一个解决方案,计算出从 2020 年 1 月至 3 月 至 2020 年 10 月至 12 月 的每三个月窗口的
average_ride_distance和average_ride_duration。并将average_ride_distance和average_ride_duration四舍五入至 小数点后两位 。
通过将三个月的总ride_distance相加并除以3来计算average_ride_distance。average_ride_duration的计算方法与此类似。
返回按month升序排列的结果表,其中month是起始月份的编号(一月为 1,二月为 2 ...)。查询结果格式如下示例所示。
示例 1:
输入: Drivers table: +-----------+------------+ | driver_id | join_date | +-----------+------------+ | 10 | 2019-12-10 | | 8 | 2020-1-13 | | 5 | 2020-2-16 | | 7 | 2020-3-8 | | 4 | 2020-5-17 | | 1 | 2020-10-24 | | 6 | 2021-1-5 | +-----------+------------+ Rides table: +---------+---------+--------------+ | ride_id | user_id | requested_at | +---------+---------+--------------+ | 6 | 75 | 2019-12-9 | | 1 | 54 | 2020-2-9 | | 10 | 63 | 2020-3-4 | | 19 | 39 | 2020-4-6 | | 3 | 41 | 2020-6-3 | | 13 | 52 | 2020-6-22 | | 7 | 69 | 2020-7-16 | | 17 | 70 | 2020-8-25 | | 20 | 81 | 2020-11-2 | | 5 | 57 | 2020-11-9 | | 2 | 42 | 2020-12-9 | | 11 | 68 | 2021-1-11 | | 15 | 32 | 2021-1-17 | | 12 | 11 | 2021-1-19 | | 14 | 18 | 2021-1-27 | +---------+---------+--------------+ AcceptedRides table: +---------+-----------+---------------+---------------+ | ride_id | driver_id | ride_distance | ride_duration | +---------+-----------+---------------+---------------+ | 10 | 10 | 63 | 38 | | 13 | 10 | 73 | 96 | | 7 | 8 | 100 | 28 | | 17 | 7 | 119 | 68 | | 20 | 1 | 121 | 92 | | 5 | 7 | 42 | 101 | | 2 | 4 | 6 | 38 | | 11 | 8 | 37 | 43 | | 15 | 8 | 108 | 82 | | 12 | 8 | 38 | 34 | | 14 | 1 | 90 | 74 | +---------+-----------+---------------+---------------+ 输出: +-------+-----------------------+-----------------------+ | month | average_ride_distance | average_ride_duration | +-------+-----------------------+-----------------------+ | 1 | 21.00 | 12.67 | | 2 | 21.00 | 12.67 | | 3 | 21.00 | 12.67 | | 4 | 24.33 | 32.00 | | 5 | 57.67 | 41.33 | | 6 | 97.33 | 64.00 | | 7 | 73.00 | 32.00 | | 8 | 39.67 | 22.67 | | 9 | 54.33 | 64.33 | | 10 | 56.33 | 77.00 | +-------+-----------------------+-----------------------+ 解释: 到1月底-->平均骑行距离=(0+0+63)/3=21,平均骑行持续时间=(0+0+38)/3=12.67 到2月底-->平均骑行距离=(0+63+0)/3=21,平均骑行持续时间=(0+38+0)/3=12.67 到3月底-->平均骑行距离=(63+0+0)/3=21,平均骑行持续时间=(38+0+0)/3=12.67 到4月底-->平均骑行距离=(0+0+73)/3=24.33,平均骑行持续时间=(0+0+96)/3=32.00 到5月底-->平均骑行距离=(0+73+100)/3=57.67,平均骑行持续时间=(0+96+28)/3=41.33 到6月底-->平均骑行距离=(73+100+119)/3=97.33,平均骑行持续时间=(96+28+68)/3=64.00 到7月底-->平均骑行距离=(100+119+0)/3=73.00,平均骑行持续时间=(28+68+0)/3=32.00 到8月底-->平均骑行距离=(119+0+0)/3=39.67,平均骑行持续时间=(68+0+0)/3=22.67 9月底-->平均骑行距离=(0+0+163)/3=54.33,平均骑行持续时间=(0+0+193)/3=64.33 到10月底-->平均骑行距离=(0+163+6)/3=56.33,平均骑行持续时间=(0+193+38)/3=77.00
三,建表语句
import pandas as pd
data = [[10, '2019-12-10'], [8, '2020-1-13'], [5, '2020-2-16'], [7, '2020-3-8'], [4, '2020-5-17'], [1, '2020-10-24'], [6, '2021-1-5']]
drivers = pd.DataFrame(data, columns=['driver_id', 'join_date']).astype({'driver_id':'Int64', 'join_date':'datetime64[ns]'})
data = [[6, 75, '2019-12-9'], [1, 54, '2020-2-9'], [10, 63, '2020-3-4'], [19, 39, '2020-4-6'], [3, 41, '2020-6-3'], [13, 52, '2020-6-22'], [7, 69, '2020-7-16'], [17, 70, '2020-8-25'], [20, 81, '2020-11-2'], [5, 57, '2020-11-9'], [2, 42, '2020-12-9'], [11, 68, '2021-1-11'], [15, 32, '2021-1-17'], [12, 11, '2021-1-19'], [14, 18, '2021-1-27']]
rides = pd.DataFrame(data, columns=['ride_id', 'user_id', 'requested_at']).astype({'ride_id':'Int64', 'user_id':'Int64', 'requested_at':'datetime64[ns]'})
data = [[10, 10, 63, 38], [13, 10, 73, 96], [7, 8, 100, 28], [17, 7, 119, 68], [20, 1, 121, 92], [5, 7, 42, 101], [2, 4, 6, 38], [11, 8, 37, 43], [15, 8, 108, 82], [12, 8, 38, 34], [14, 1, 90, 74]]
accepted_rides = pd.DataFrame(data, columns=['ride_id', 'driver_id', 'ride_distance', 'ride_duration']).astype({'ride_id':'Int64', 'driver_id':'Int64', 'ride_distance':'Int64', 'ride_duration':'Int64'})四,分析
- 第一步,递归求出12个月份
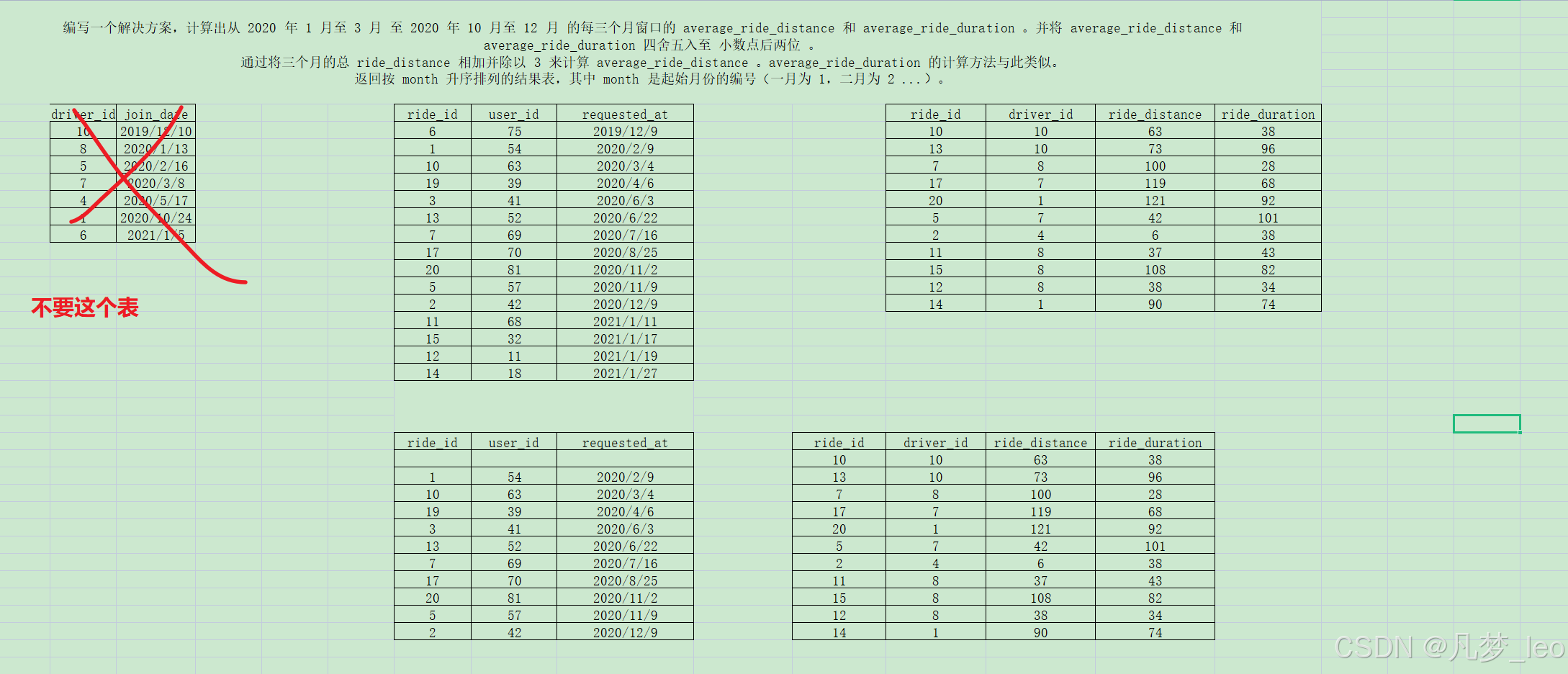
- 第二步:拿到2020年的数据
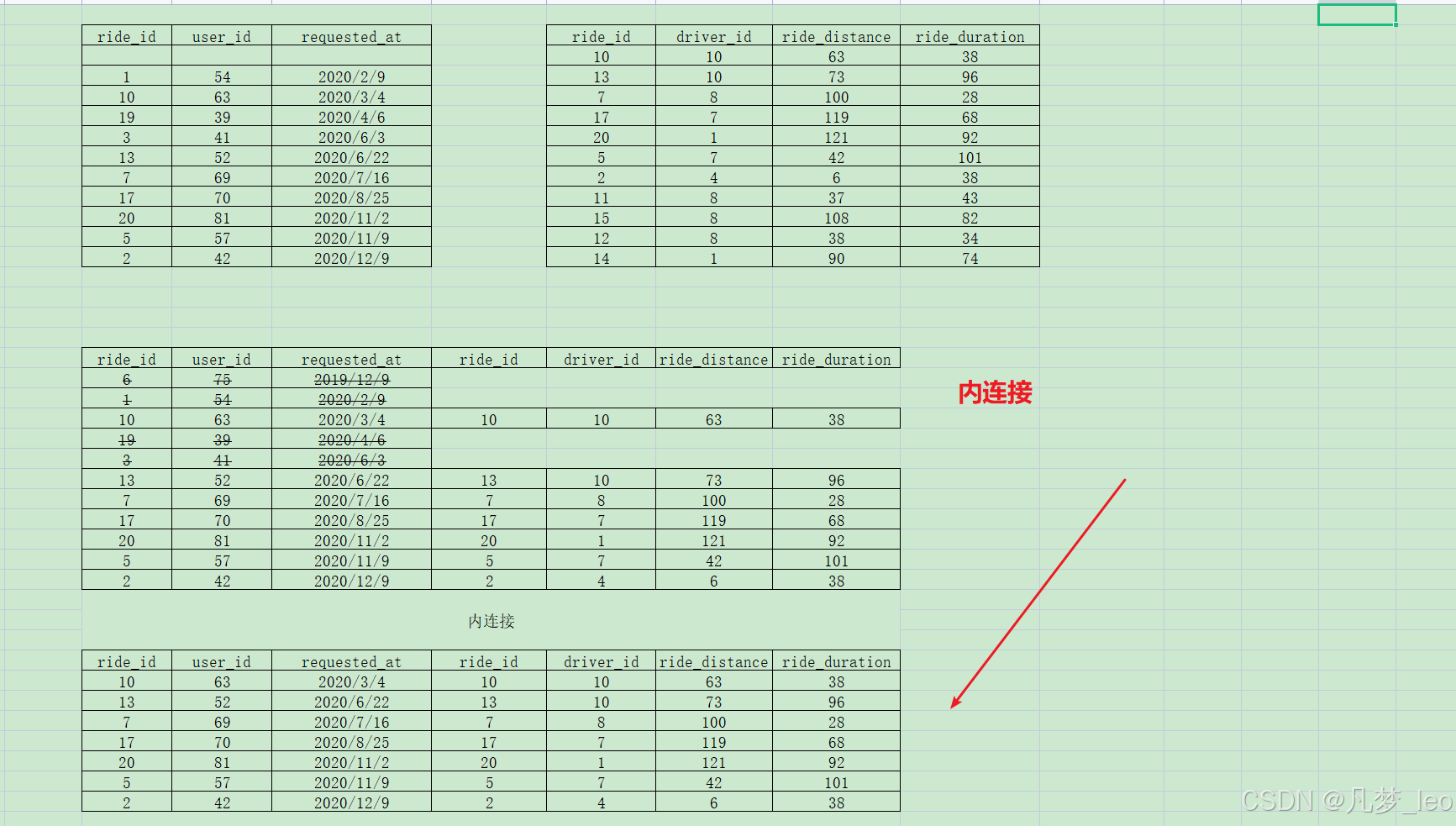
- 第三步:内连接,2020年的订单数据Rides和AcceptedRides
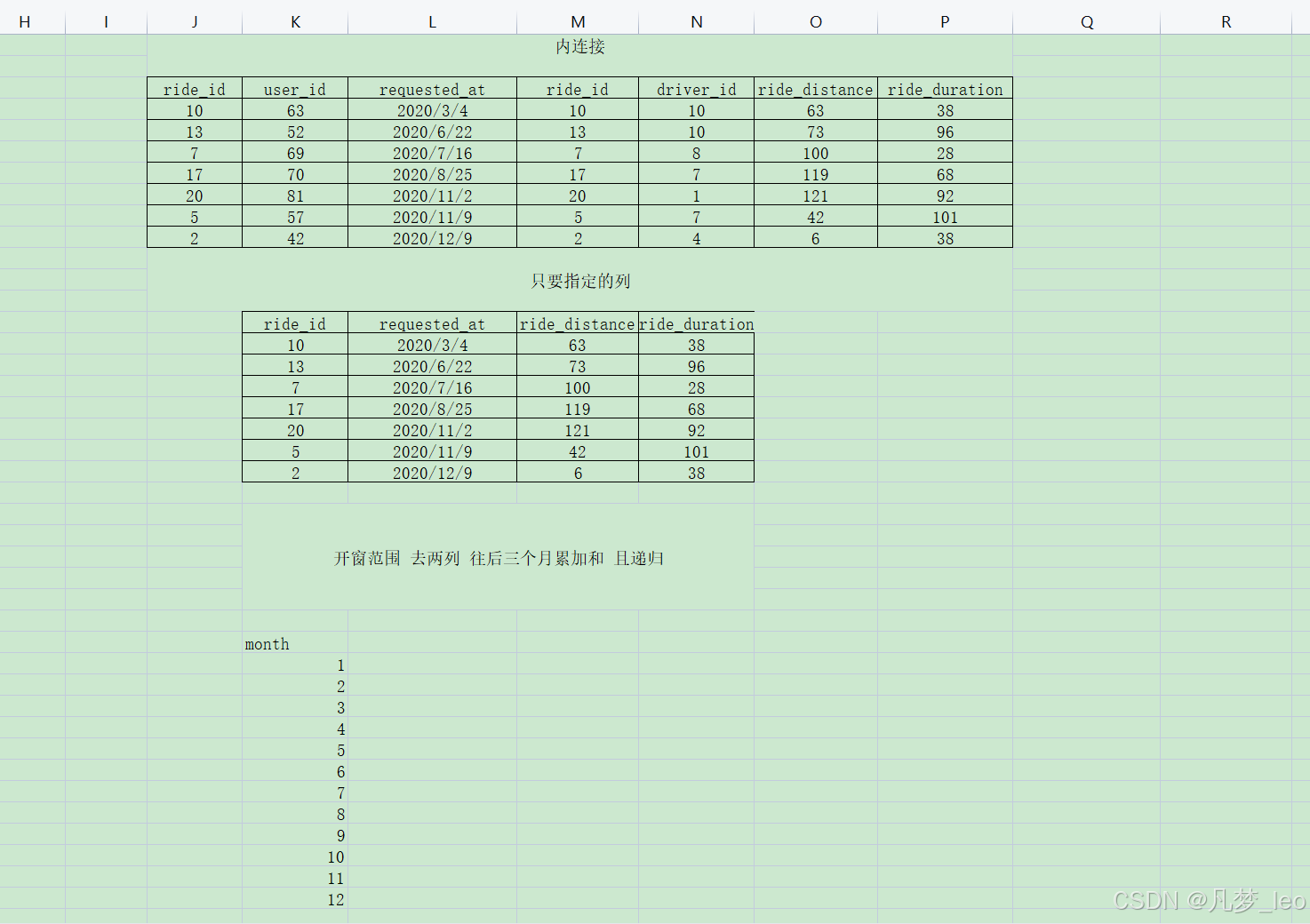
- 第四步:用第一步的递归表和第三步的表左连接;null更改为0;
- 第五步:用开窗range 求范围累加和
- 详细表格逻辑如下:
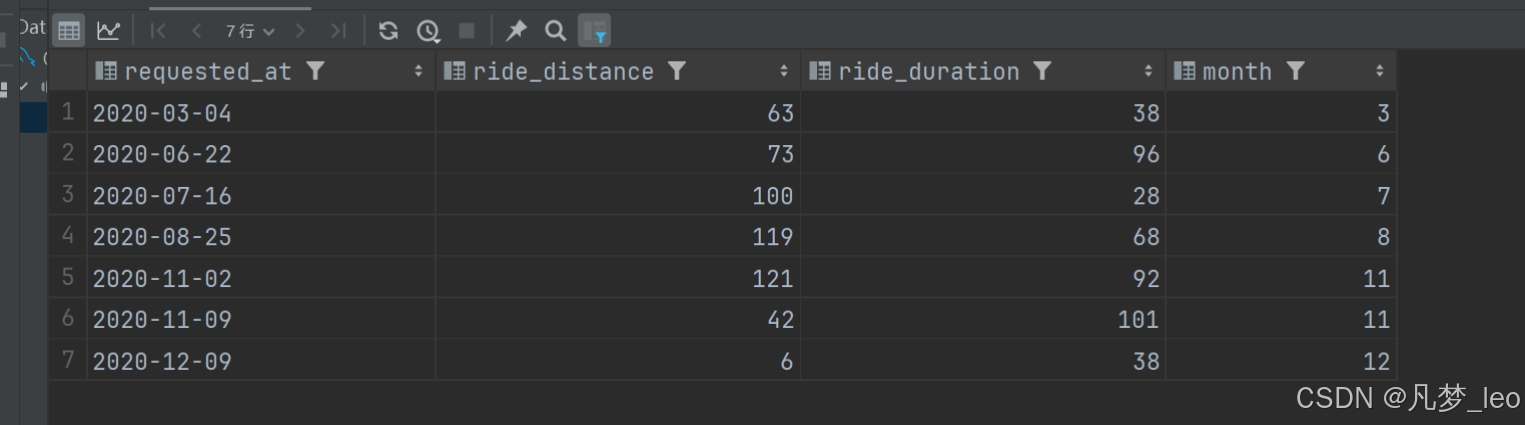
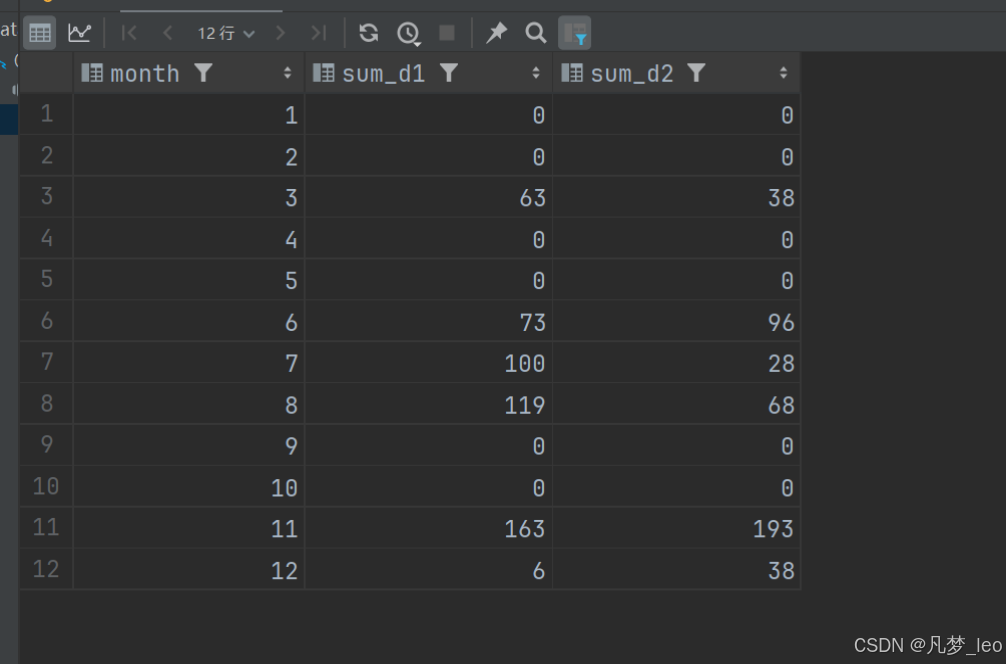
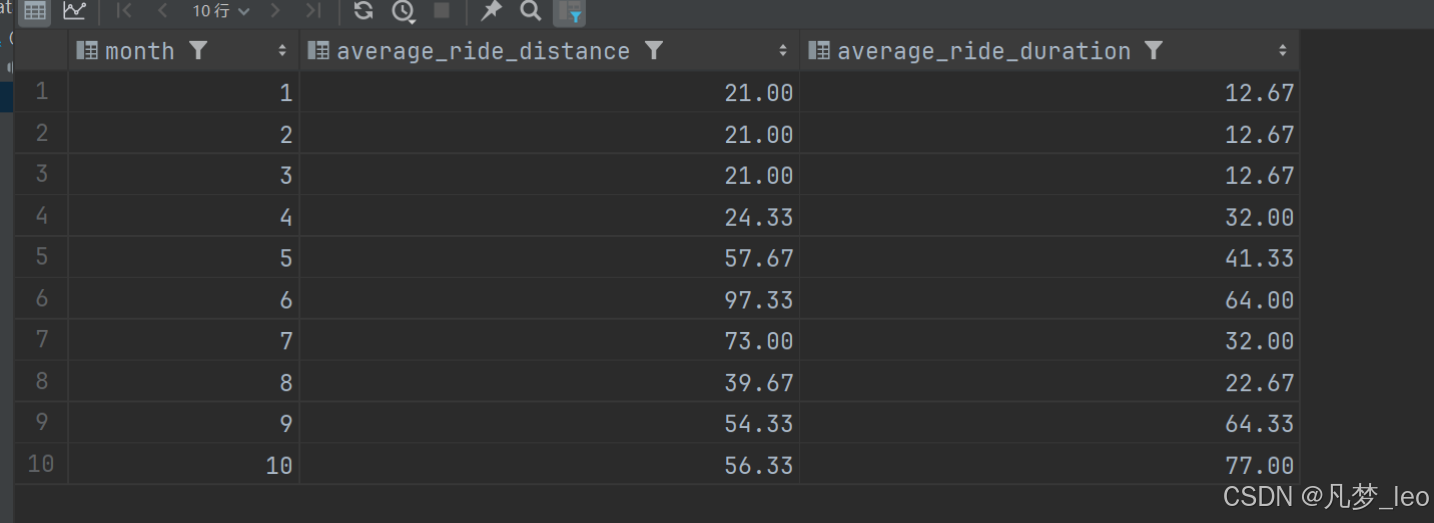
代码实现过程:pandas实现过程
第一步,直接求出12个月份
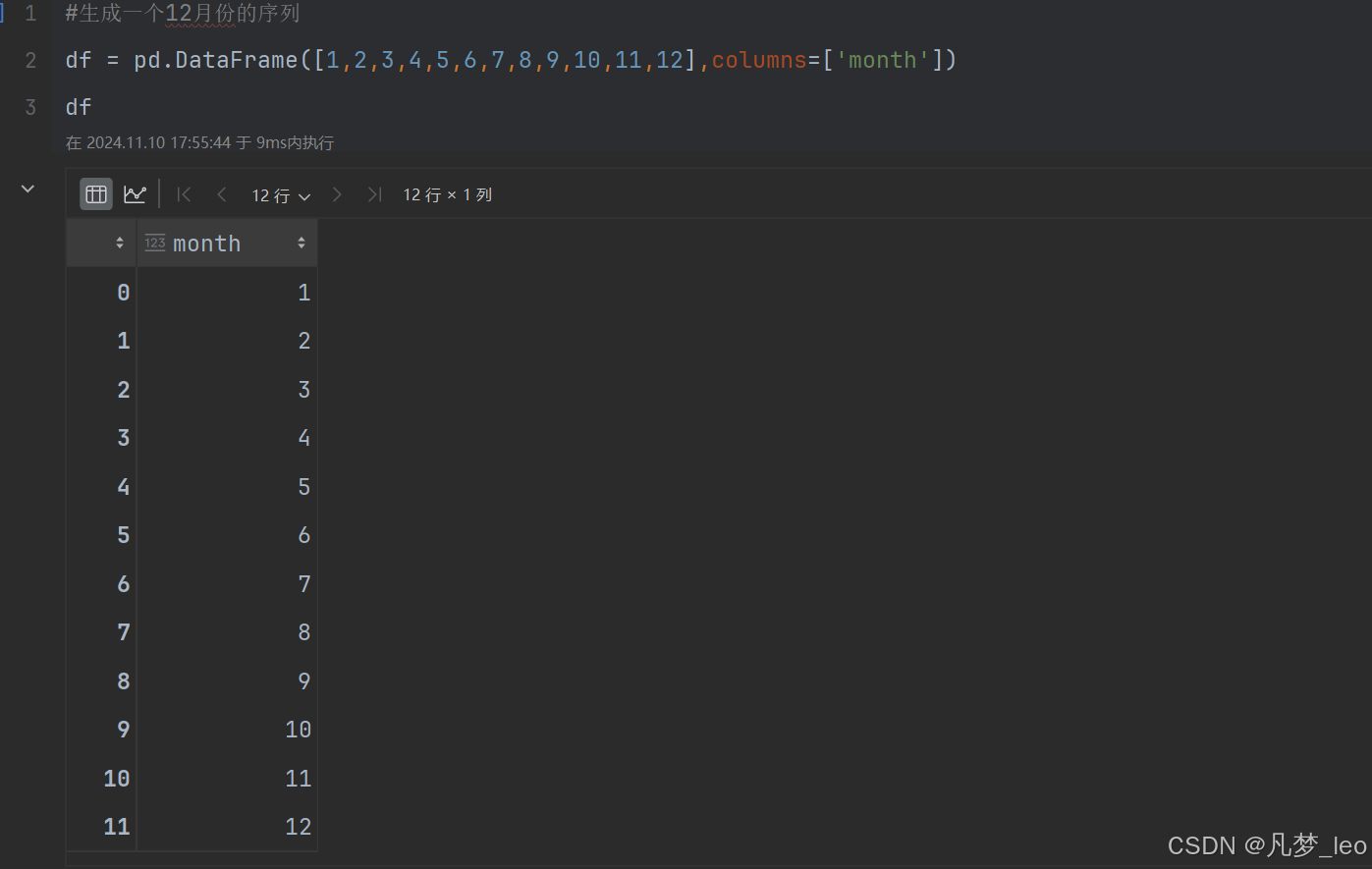
第二步:拿到2020年的数据
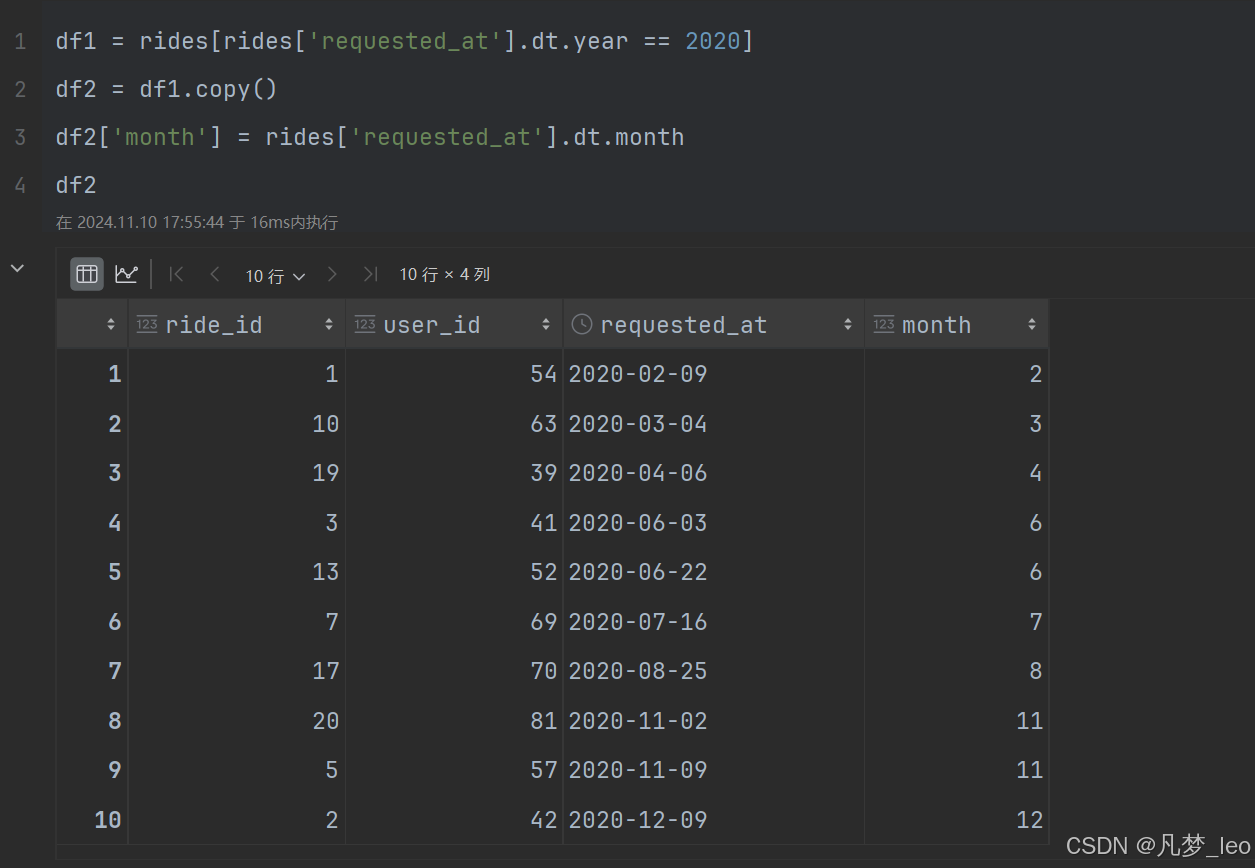
第三步:内连接,2020年的订单数据Rides和AcceptedRides
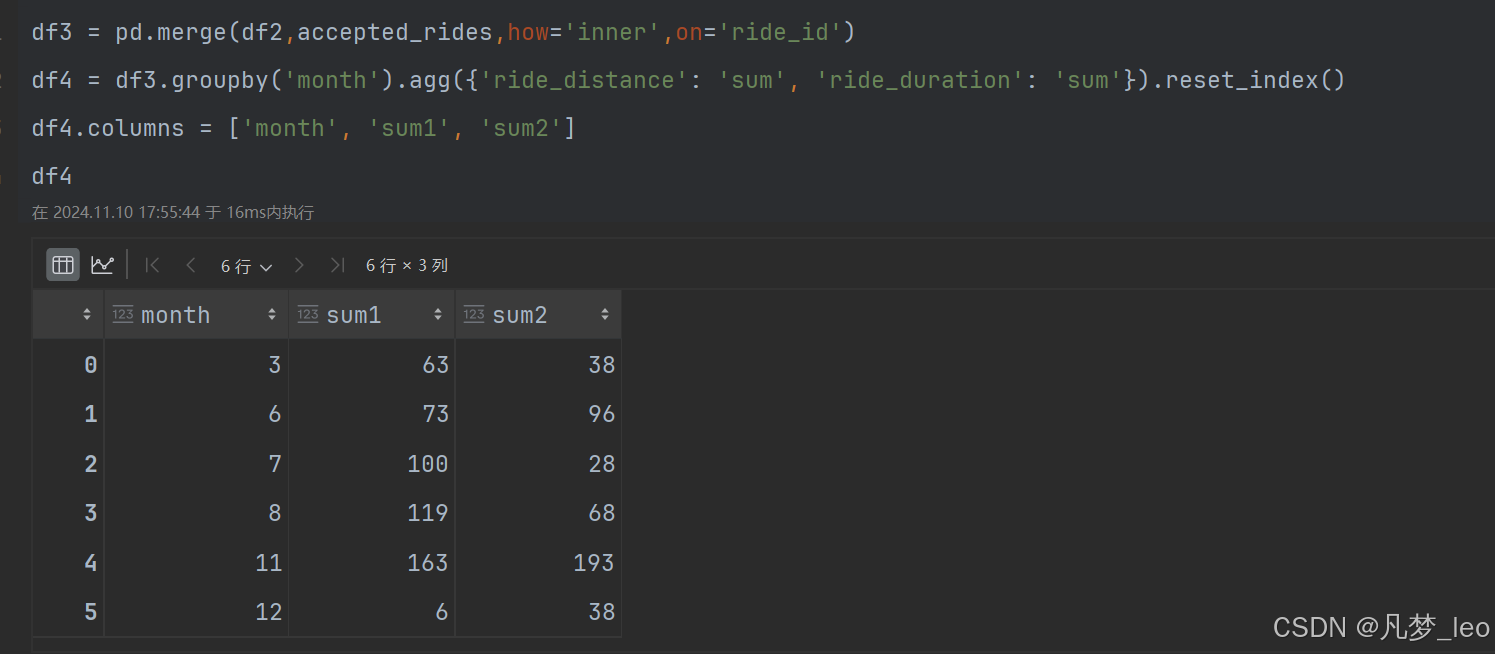
第四步:用第一步的递归表和第三步的表左连接;null更改为0;
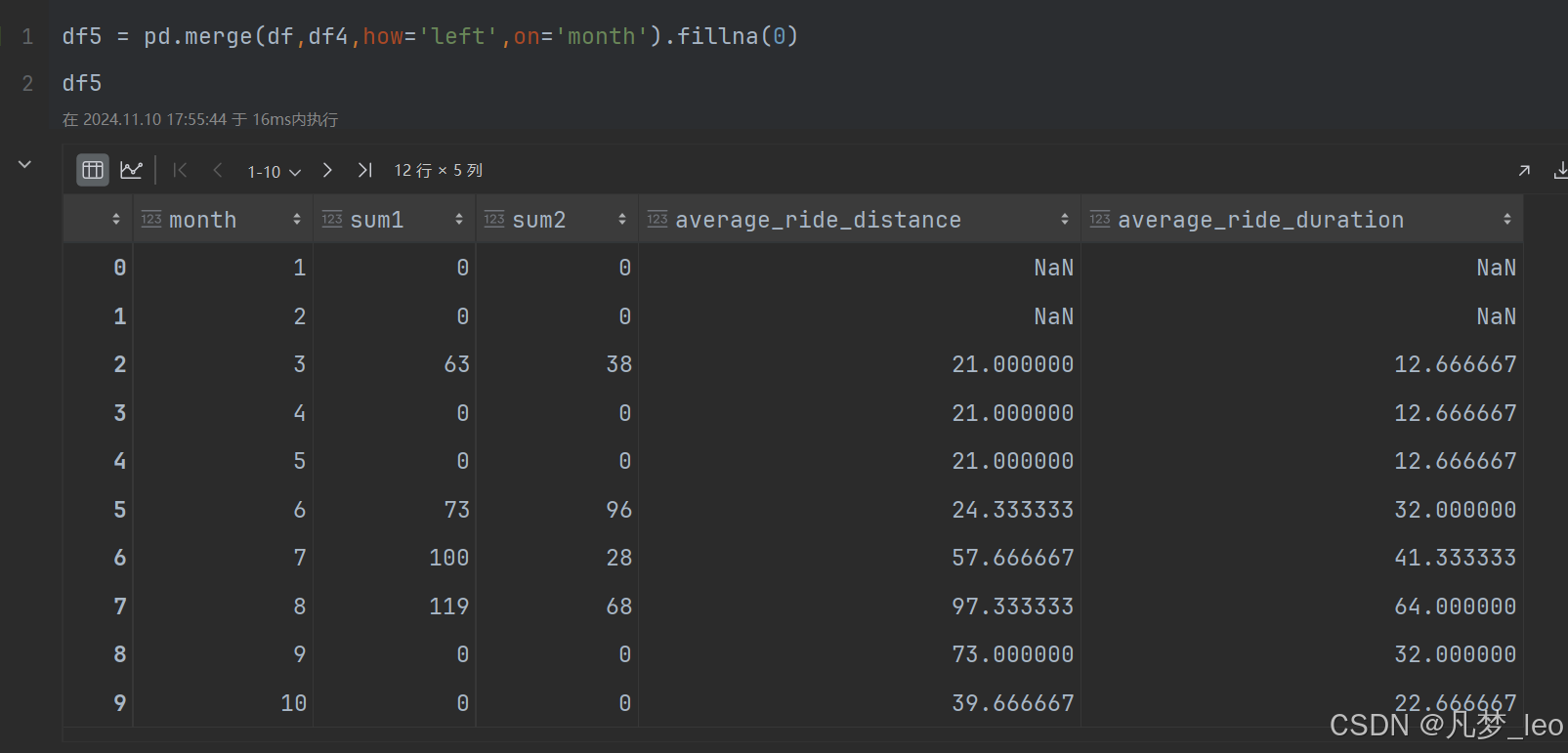
第五步:用开窗range 求范围累加和
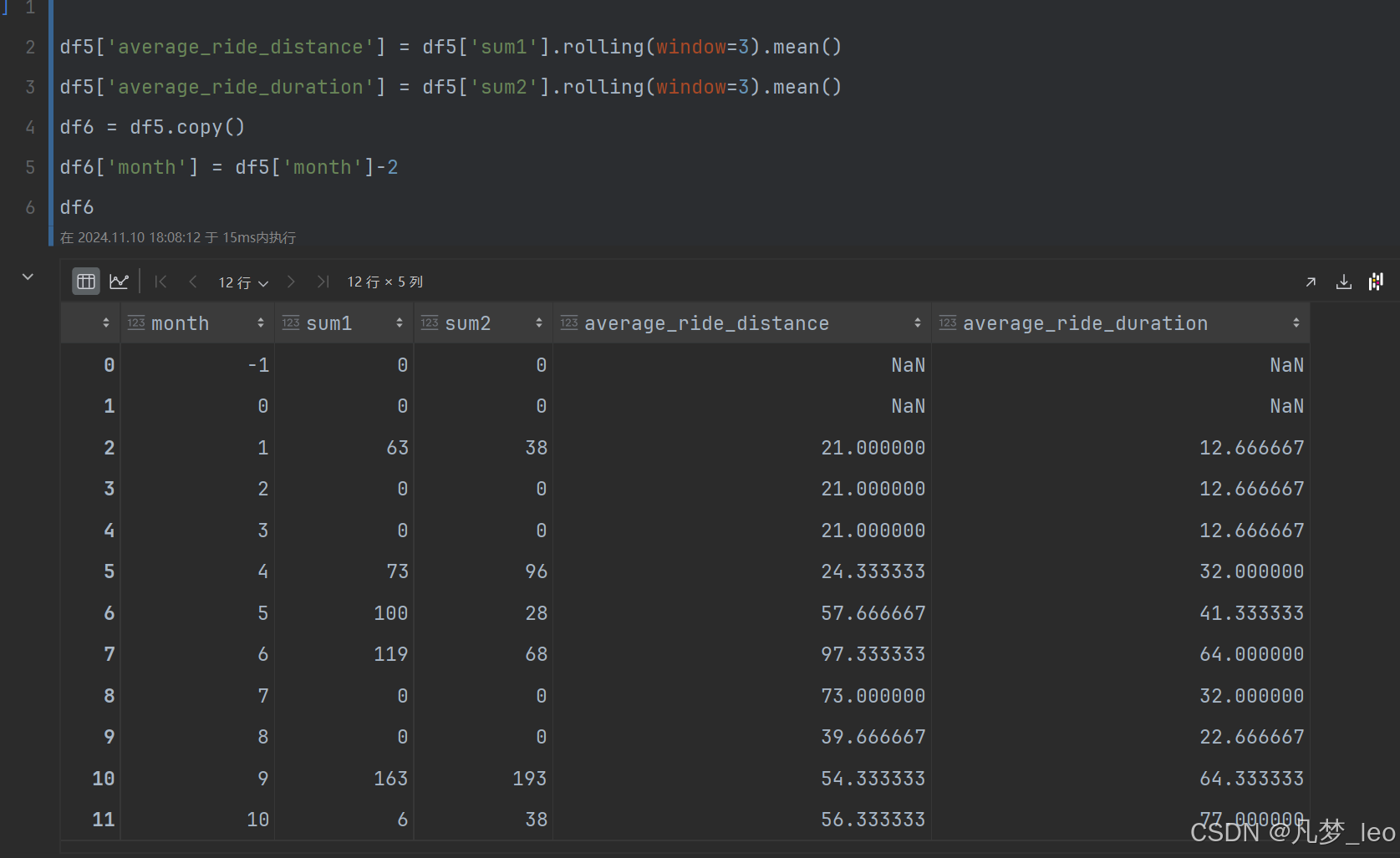
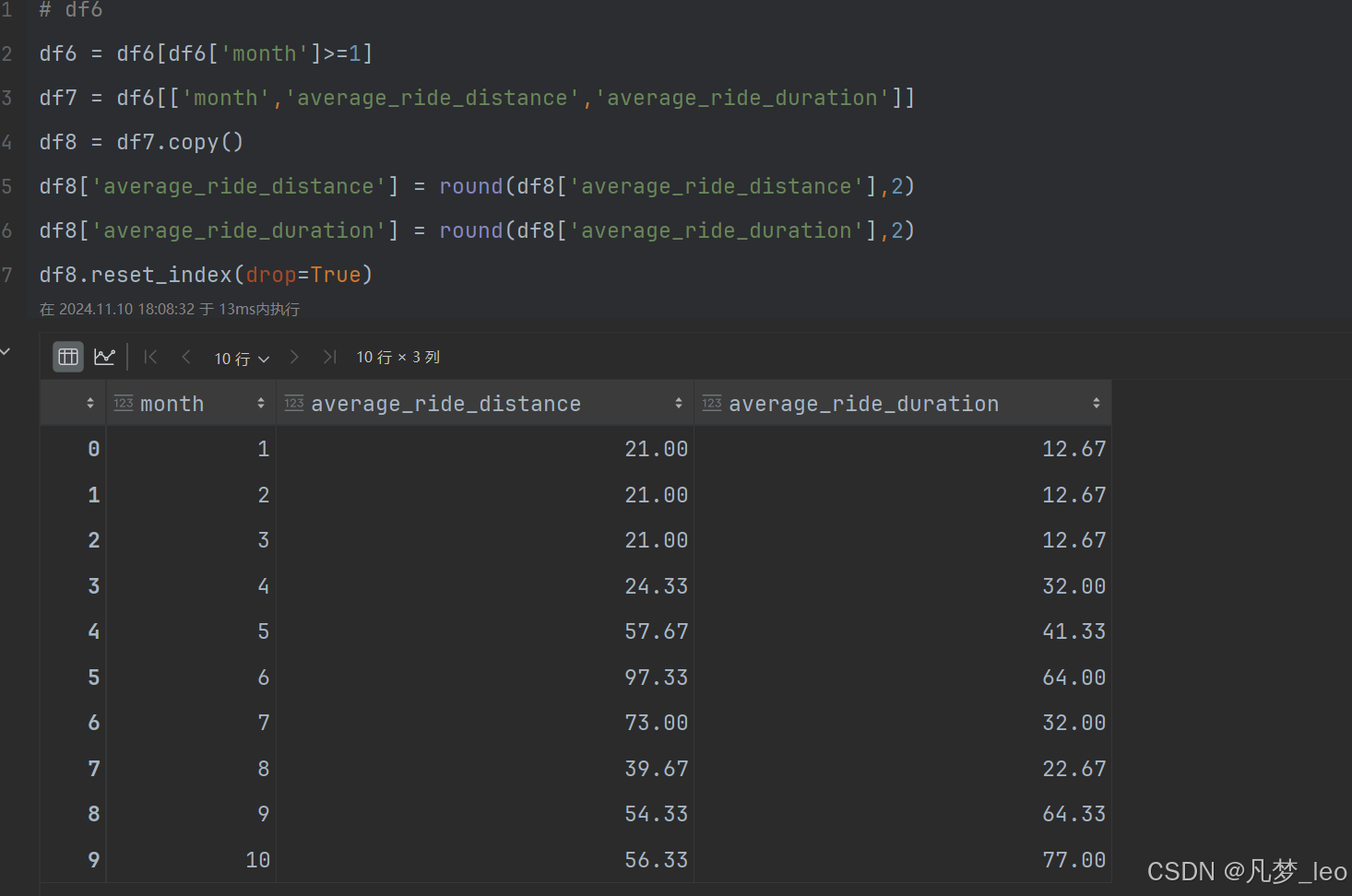
五,Pandas解答
import pandas as pd
def hopper_company_queries(drivers: pd.DataFrame, rides: pd.DataFrame, accepted_rides: pd.DataFrame) -> pd.DataFrame:
#生成一个12月份的序列
df = pd.DataFrame([1,2,3,4,5,6,7,8,9,10,11,12],columns=['month'])
df1 = rides[rides['requested_at'].dt.year == 2020]
df2 = df1.copy()
df2['month'] = rides['requested_at'].dt.month
df3 = pd.merge(df2,accepted_rides,how='inner',on='ride_id')
df4 = df3.groupby('month').agg({'ride_distance': 'sum', 'ride_duration': 'sum'}).reset_index()
df4.columns = ['month', 'sum1', 'sum2']
df5 = pd.merge(df,df4,how='left',on='month').fillna(0)
df5['average_ride_distance'] = df5['sum1'].rolling(window=3).mean()
df5['average_ride_duration'] = df5['sum2'].rolling(window=3).mean()
df6 = df5.copy()
df6['month'] = df5['month']-2
# df6
df6 = df6[df6['month']>=1]
df7 = df6[['month','average_ride_distance','average_ride_duration']]
df8 = df7.copy()
df8['average_ride_distance'] = round(df8['average_ride_distance'],2)
df8['average_ride_duration'] = round(df8['average_ride_duration'],2)
return df8.reset_index(drop=True)
hopper_company_queries(drivers,rides,accepted_rides)六,验证
七,知识点总结
- Pandas中复制的运用
- Pandas中时间函数的运用 求年 求月
- Pandas中内连接到运用
- Pandas中多列聚合的运用
- Pandas中左连接到运用
- Pandas中对null值的处理
- Pandas中窗口函数范围取值的运用
- Pandas中条件过滤的运用
- Pandas中四舍五入的运用
- Pandas中重置索引的运用
- 学习:知识的初次邂逅
- 复习:知识的温故知新
- 练习:知识的实践应用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









