







- 学习:知识的初次邂逅
- 复习:知识的温故知新
- 练习:知识的实践应用
目录
一,原题力扣链接
二,题干
表:
Drivers+-------------+---------+ | Column Name | Type | +-------------+---------+ | driver_id | int | | join_date | date | +-------------+---------+ driver_id 是该表具有唯一值的列。 该表的每一行均包含驾驶员的ID以及他们加入 Hopper 公司的日期。表:
Rides+--------------+---------+ | Column Name | Type | +--------------+---------+ | ride_id | int | | user_id | int | | requested_at | date | +--------------+---------+ ride_id 是该表具有唯一值的列。 该表的每一行均包含行程 ID(ride_id),用户 ID(user_id) 以及该行程的日期 (requested_at)。 该表中可能有一些不被接受的乘车请求。表:
AcceptedRides+---------------+---------+ | Column Name | Type | +---------------+---------+ | ride_id | int | | driver_id | int | | ride_distance | int | | ride_duration | int | +---------------+---------+ ride_id 是该表具有唯一值的列。 该表的每一行都包含已接受的行程信息。 表中的行程信息都在 "Rides" 表中存在。编写解决方案以报告 2020 年每个月的工作驱动因素 百分比(
working_percentage),其中:注意:如果一个月内可用驾驶员的数量为零,我们认为
working_percentage为0。返回按
month升序 排列的结果表,其中month是月份的编号(一月是1,二月是2,等等)。将working_percentage四舍五入至 小数点后两位。结果格式如下例所示。
示例 1:
输入: 表 Drivers: +-----------+------------+ | driver_id | join_date | +-----------+------------+ | 10 | 2019-12-10 | | 8 | 2020-1-13 | | 5 | 2020-2-16 | | 7 | 2020-3-8 | | 4 | 2020-5-17 | | 1 | 2020-10-24 | | 6 | 2021-1-5 | +-----------+------------+ 表 Rides: +---------+---------+--------------+ | ride_id | user_id | requested_at | +---------+---------+--------------+ | 6 | 75 | 2019-12-9 | | 1 | 54 | 2020-2-9 | | 10 | 63 | 2020-3-4 | | 19 | 39 | 2020-4-6 | | 3 | 41 | 2020-6-3 | | 13 | 52 | 2020-6-22 | | 7 | 69 | 2020-7-16 | | 17 | 70 | 2020-8-25 | | 20 | 81 | 2020-11-2 | | 5 | 57 | 2020-11-9 | | 2 | 42 | 2020-12-9 | | 11 | 68 | 2021-1-11 | | 15 | 32 | 2021-1-17 | | 12 | 11 | 2021-1-19 | | 14 | 18 | 2021-1-27 | +---------+---------+--------------+ 表 AcceptedRides: +---------+-----------+---------------+---------------+ | ride_id | driver_id | ride_distance | ride_duration | +---------+-----------+---------------+---------------+ | 10 | 10 | 63 | 38 | | 13 | 10 | 73 | 96 | | 7 | 8 | 100 | 28 | | 17 | 7 | 119 | 68 | | 20 | 1 | 121 | 92 | | 5 | 7 | 42 | 101 | | 2 | 4 | 6 | 38 | | 11 | 8 | 37 | 43 | | 15 | 8 | 108 | 82 | | 12 | 8 | 38 | 34 | | 14 | 1 | 90 | 74 | +---------+-----------+---------------+---------------+ 输出: +-------+--------------------+ | month | working_percentage | +-------+--------------------+ | 1 | 0.00 | | 2 | 0.00 | | 3 | 25.00 | | 4 | 0.00 | | 5 | 0.00 | | 6 | 20.00 | | 7 | 20.00 | | 8 | 20.00 | | 9 | 0.00 | | 10 | 0.00 | | 11 | 33.33 | | 12 | 16.67 | +-------+--------------------+ 解释: 截至 1 月底 --> 2 个活跃的驾驶员 (10, 8),无被接受的行程。百分比是0%。 截至 2 月底 --> 3 个活跃的驾驶员 (10, 8, 5),无被接受的行程。百分比是0%。 截至 3 月底 --> 4 个活跃的驾驶员 (10, 8, 5, 7),1 个被接受的行程 (10)。百分比是 (1 / 4) * 100 = 25%。 截至 4 月底 --> 4 个活跃的驾驶员 (10, 8, 5, 7),无被接受的行程。百分比是 0%。 截至 5 月底 --> 5 个活跃的驾驶员 (10, 8, 5, 7, 4),无被接受的行程。百分比是 0%。 截至 6 月底 --> 5 个活跃的驾驶员 (10, 8, 5, 7, 4),1 个被接受的行程 (10)。 百分比是 (1 / 5) * 100 = 20%。 截至 7 月底 --> 5 个活跃的驾驶员 (10, 8, 5, 7, 4),1 个被接受的行程 (8)。百分比是 (1 / 5) * 100 = 20%。 截至 8 月底 --> 5 个活跃的驾驶员 (10, 8, 5, 7, 4),1 个被接受的行程 (7)。百分比是 (1 / 5) * 100 = 20%。 截至 9 月底 --> 5 个活跃的驾驶员 (10, 8, 5, 7, 4),无被接受的行程。百分比是 0%。 截至 10 月底 --> 6 个活跃的驾驶员 (10, 8, 5, 7, 4, 1) 无被接受的行程。百分比是 0%。 截至 11 月底 --> 6 个活跃的驾驶员 (10, 8, 5, 7, 4, 1),2 个被接受的行程 (1, 7)。百分比是 (2 / 6) * 100 = 33.33%。 截至 12 月底 --> 6 个活跃的驾驶员 (10, 8, 5, 7, 4, 1),1 个被接受的行程 (4)。百分比是 (1 / 6) * 100 = 16.67%。
三,建表语句
import pandas as pd
data = [[10, '2019-12-10'], [8, '2020-1-13'], [5, '2020-2-16'], [7, '2020-3-8'], [4, '2020-5-17'], [1, '2020-10-24'], [6, '2021-1-5']]
drivers = pd.DataFrame(data, columns=['driver_id', 'join_date']).astype({'driver_id':'Int64', 'join_date':'datetime64[ns]'})
data = [[6, 75, '2019-12-9'], [1, 54, '2020-2-9'], [10, 63, '2020-3-4'], [19, 39, '2020-4-6'], [3, 41, '2020-6-3'], [13, 52, '2020-6-22'], [7, 69, '2020-7-16'], [17, 70, '2020-8-25'], [20, 81, '2020-11-2'], [5, 57, '2020-11-9'], [2, 42, '2020-12-9'], [11, 68, '2021-1-11'], [15, 32, '2021-1-17'], [12, 11, '2021-1-19'], [14, 18, '2021-1-27']]
rides = pd.DataFrame(data, columns=['ride_id', 'user_id', 'requested_at']).astype({'ride_id':'Int64', 'user_id':'Int64', 'requested_at':'datetime64[ns]'})
data = [[10, 10, 63, 38], [13, 10, 73, 96], [7, 8, 100, 28], [17, 7, 119, 68], [20, 1, 121, 92], [5, 7, 42, 101], [2, 4, 6, 38], [11, 8, 37, 43], [15, 8, 108, 82], [12, 8, 38, 34], [14, 1, 90, 74]]
accepted_rides = pd.DataFrame(data, columns=['ride_id', 'driver_id', 'ride_distance', 'ride_duration']).astype({'ride_id':'Int64', 'driver_id':'Int64', 'ride_distance':'Int64', 'ride_duration':'Int64'})四,分析
思路
表格大法 这题上一题基本一样,最后求的是活跃司机数量与出勤司机数量的占比 所以需要变更一下指标计注意 出勤司机可能重复,有可能是同一个司机,所以统计出勤司机数量的时候需要去重一下
第一步:计算每个月的活跃司机数 (截至2020-12月)
第二步:计算每个月出勤司机数量 (2020年的每个月)
第三步:求出衍生指标 需要考虑null值的情况
表格与上一题基本一致
151,SQL训练之,力扣,1635. Hopper 公司查询 I-优快云博客
73,Python数分之Pandas训练,1635. Hopper 公司查询 I-优快云博客
解题过程
pandas和mysql题解 解题过程也和上一题基本一致 区别:
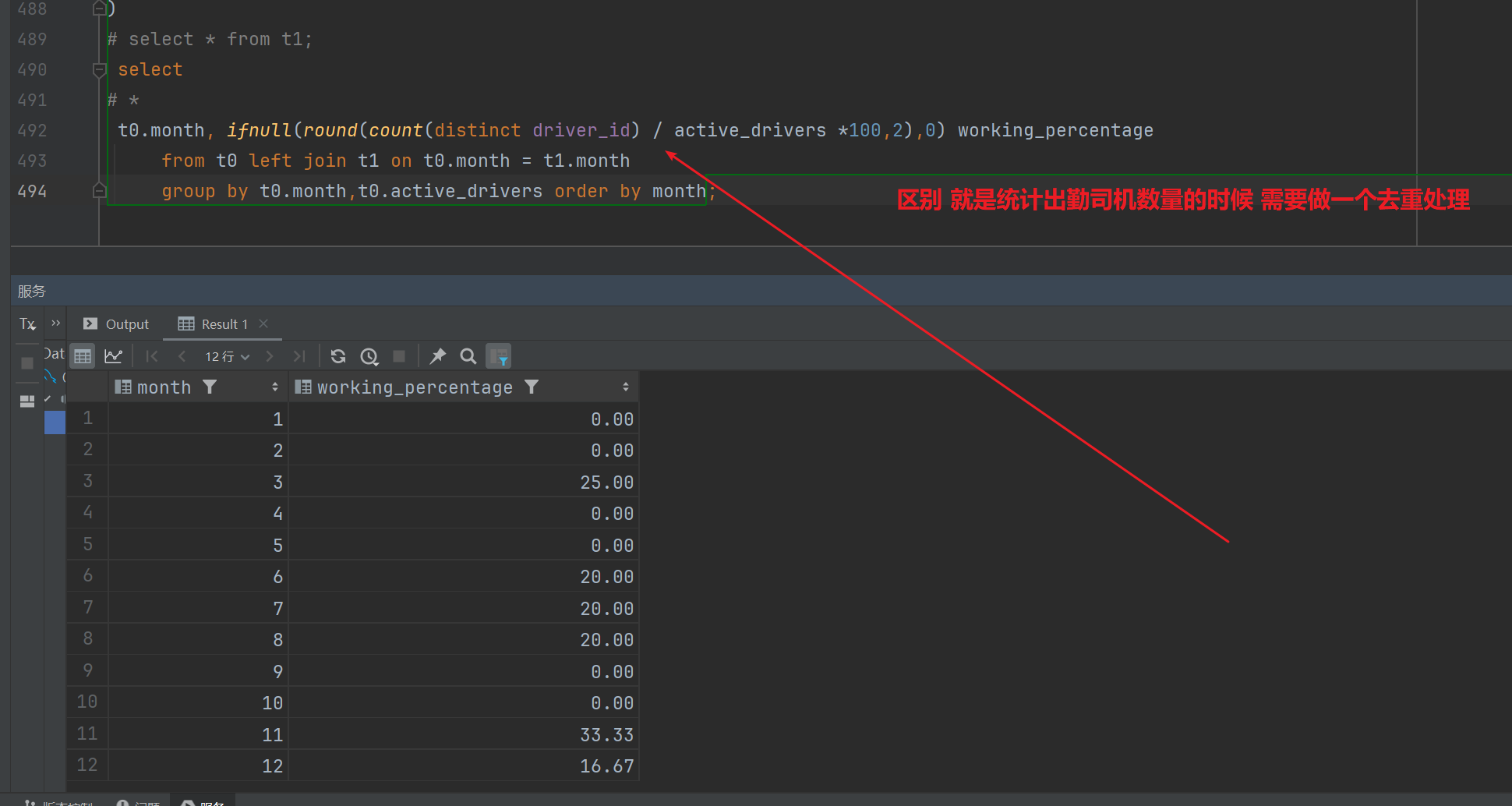
五,Pandas解答
import pandas as pd
def hopper_company_queries(drivers: pd.DataFrame, rides: pd.DataFrame, accepted_rides: pd.DataFrame) -> pd.DataFrame:
#计算1月
df1=pd.DataFrame()
df1['month'] =[1]
df1['active_drivers'] =[drivers[drivers['join_date'].astype(str).str[:7] <= '2020-01']['join_date'].count()]
#计算2月
df2=pd.DataFrame()
df2['month'] =[2]
df2['active_drivers'] =[drivers[drivers['join_date'].astype(str).str[:7] <= '2020-02']['join_date'].count()]
#计算3月
df3=pd.DataFrame()
df3['month'] =[3]
df3['active_drivers'] =[drivers[drivers['join_date'].astype(str).str[:7] <= '2020-03']['join_date'].count()]
#计算4月
df4=pd.DataFrame()
df4['month'] =[4]
df4['active_drivers'] =[drivers[drivers['join_date'].astype(str).str[:7] <= '2020-04']['join_date'].count()]
#计算5月
df5=pd.DataFrame()
df5['month'] =[5]
df5['active_drivers'] =[drivers[drivers['join_date'].astype(str).str[:7] <= '2020-05']['join_date'].count()]
#计算6月
df6=pd.DataFrame()
df6['month'] =[6]
df6['active_drivers'] =[drivers[drivers['join_date'].astype(str).str[:7] <= '2020-06']['join_date'].count()]
#计算7月
df7=pd.DataFrame()
df7['month'] =[7]
df7['active_drivers'] =[drivers[drivers['join_date'].astype(str).str[:7] <= '2020-07']['join_date'].count()]
#计算8月
df8=pd.DataFrame()
df8['month'] =[8]
df8['active_drivers'] =[drivers[drivers['join_date'].astype(str).str[:7] <= '2020-08']['join_date'].count()]
#计算9月
df9=pd.DataFrame()
df9['month'] =[9]
df9['active_drivers'] =[drivers[drivers['join_date'].astype(str).str[:7] <= '2020-09']['join_date'].count()]
#计算10月
df10=pd.DataFrame()
df10['month'] =[10]
df10['active_drivers'] =[drivers[drivers['join_date'].astype(str).str[:7] <= '2020-10']['join_date'].count()]
#计算11月
df11=pd.DataFrame()
df11['month'] =[11]
df11['active_drivers'] =[drivers[drivers['join_date'].astype(str).str[:7] <= '2020-11']['join_date'].count()]
#计算12月
df12=pd.DataFrame()
df12['month'] =[12]
df12['active_drivers'] =[drivers[drivers['join_date'].astype(str).str[:7] <= '2020-12']['join_date'].count()]
#union all
df = pd.concat([df1,df2,df3,df4,df5,df6,df7,df8,df9,df10,df11,df12],axis=0)
rides = rides[rides['requested_at'].astype(str).str[:4] =='2020']
res = pd.merge(accepted_rides,rides,how='inner',on='ride_id')
res['requested_at'] = res['requested_at'].dt.month
res1 = pd.merge(df,res,how='left',left_on='month',right_on='requested_at')
# res1
res2 = res1.groupby(['month','active_drivers'])['driver_id'].nunique().reset_index(name='accepted_rides')
res2['working_percentage'] = round(res2['accepted_rides'] / res2['active_drivers'] *100,2)
return res2[['month','working_percentage']].fillna(0)
hopper_company_queries(drivers,rides,accepted_rides)六,验证
七,知识点总结
- Pandas中 unioall的运用
- Pandas中分组聚合的运用
- Pandas中时间函数的运用
- Pandas中切片的运用
- Pandas中内连接到运用
- Pandas中实现sql中 去重count的运用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









