







 这篇博客主要介绍了使用Python的requests库进行网络请求,包括获取百度网页内容、下载美女图片和视频、百度关键词搜索及爬取百度翻译。在过程中,博主遇到了编码问题和爬取结果不符的情况,并邀请读者一起探讨解决方案。
这篇博客主要介绍了使用Python的requests库进行网络请求,包括获取百度网页内容、下载美女图片和视频、百度关键词搜索及爬取百度翻译。在过程中,博主遇到了编码问题和爬取结果不符的情况,并邀请读者一起探讨解决方案。
目录
一、获取百度网页并打印
代码如下:
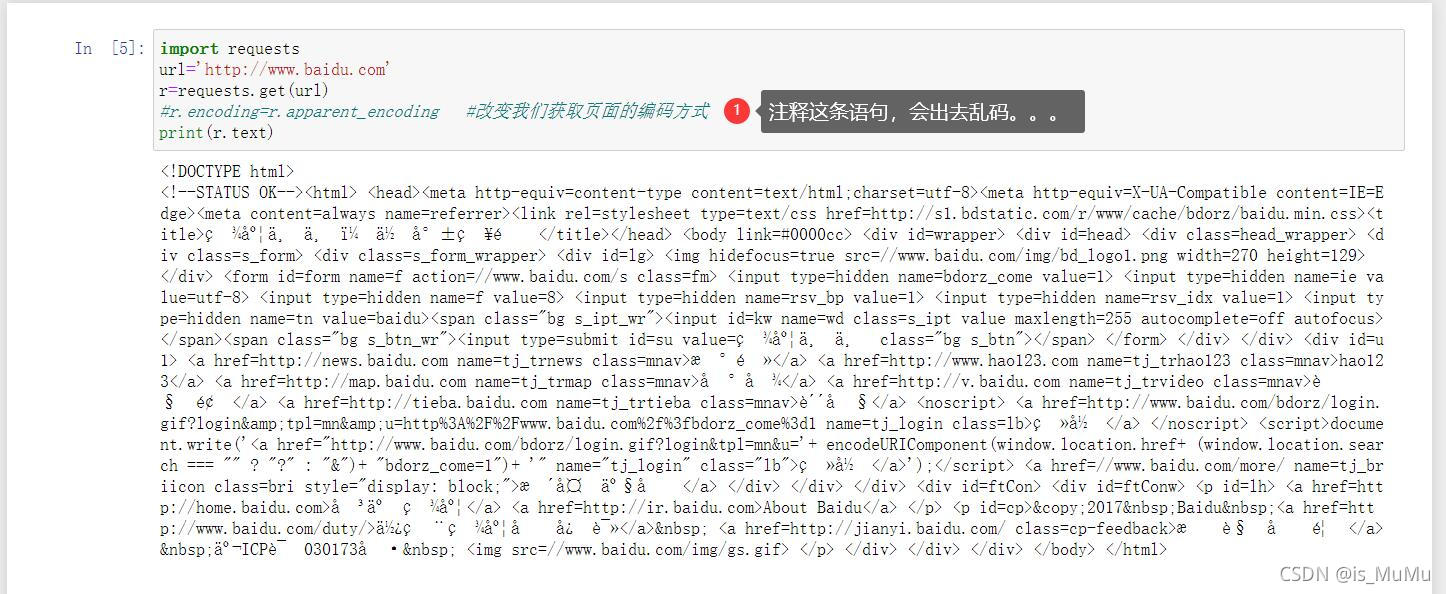
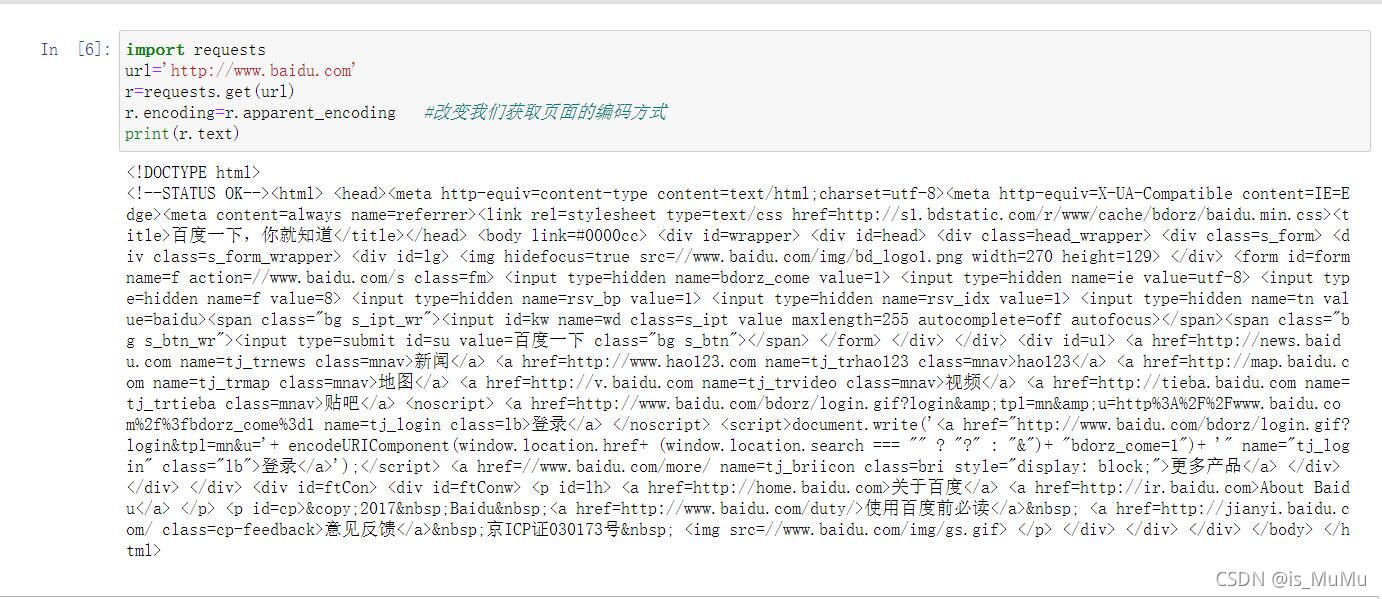
import requests
url='http://www.baidu.com'
r=requests.get(url)
r.encoding=r.apparent_encoding #改变我们获取页面的编码方式
print(r.text)r.encoding=r.apparent_encoding
r.encoding:从HTTP header中猜测的内容响应编码方式
r.apparent_encoding:从内容中分析出响应的编码方式
出现乱码的原因:
header中没有charset字段则默认为ISO-8859-1编码模式,无法解析中文
二、获取美女图片并下载到本地
import requests
src='https://www.faxianzhe66.com/upload/products/202106/26/14174160d6c685e8bc9EZDlqz.jpg'
r=requests.get(src)
with open('小姐姐.jpg','wb')as f:
f.write(r.content)
print('下载完成')
运行结果:
三、获取美女视频并下载到本地
import requests
src = 'https://apd-36ae3724d7c0b6835e09d09afc998cfa.v.smtcdns.com/om.tc.qq.com/Amu-xLH92Fdz3C-7PsjutQi_lMKUzCnkiicBjZ69cAqk/uwMROfz2r55oIaQXGdGnC2dePkfe0TtOFg8QaGVhJ2MPCPEj/svp_50001/szg_9711_50001_0bf26aabmaaaqyaarhnfdnqfd4gdc3yaafsa.f632.mp4?sdtfrom=v1010&guid=442bebcff8ab31b452c4a64140cd7f3a&vkey=762D67379522C89E3A76A0759F02B2905311E3FE385B3EC351571A1F2D5A0A6A58D5744F68F9C668211191507472C84F4D2B7D147B7F1BB833B04D6E0CC3945CA361CF9E63E01C277F08CD3D69B288562D33EB7EB83861585CB549B2D4EE38E50CA732275EE0B5ECD680378B2DBEBB0DBEE5B100998B1A83694140CF8588CABD91EB22B4369D5940'
r = requests.get(src)
with open('movie.mp4', 'wb') as f:
f.write(r.content)
print('下载完成')
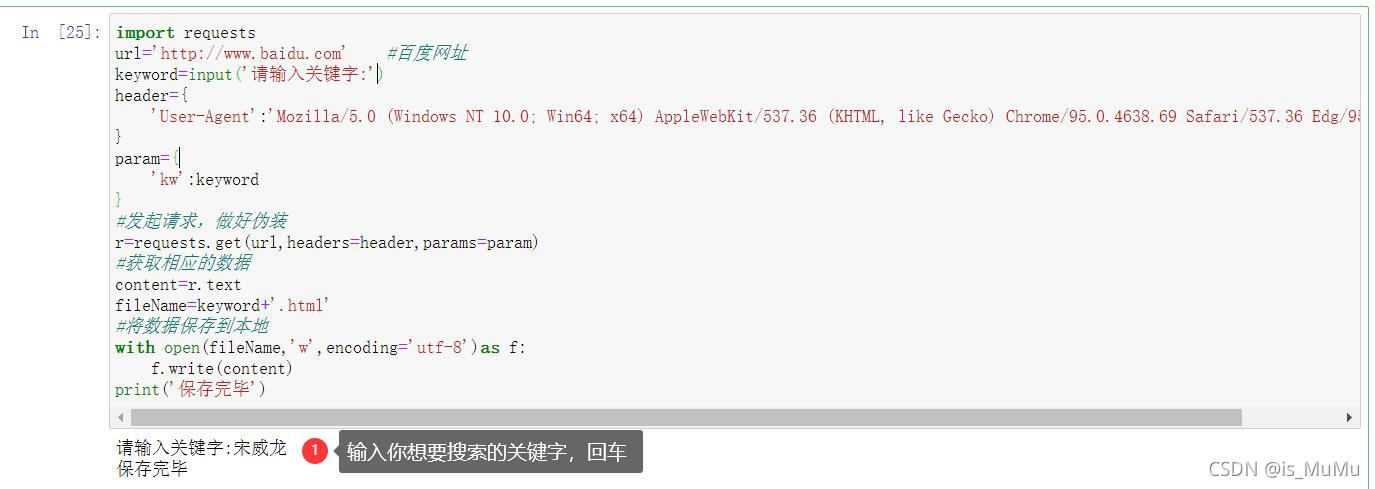
四、百度关键词搜索爬取
import requests
url='http://www.baidu.com' #百度网址
keyword=input('请输入关键字:') #keyword是个字符串
header={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53'
}
param={
'kw':keyword
}
#发起请求,做好伪装
r=requests.get(url,headers=header,params=param)
#获取相应的数据
content=r.text
fileName=keyword+'.html'
#将数据保存到本地
with open(fileName,'w',encoding='utf-8')as f:
f.write(content)
print('保存完毕')
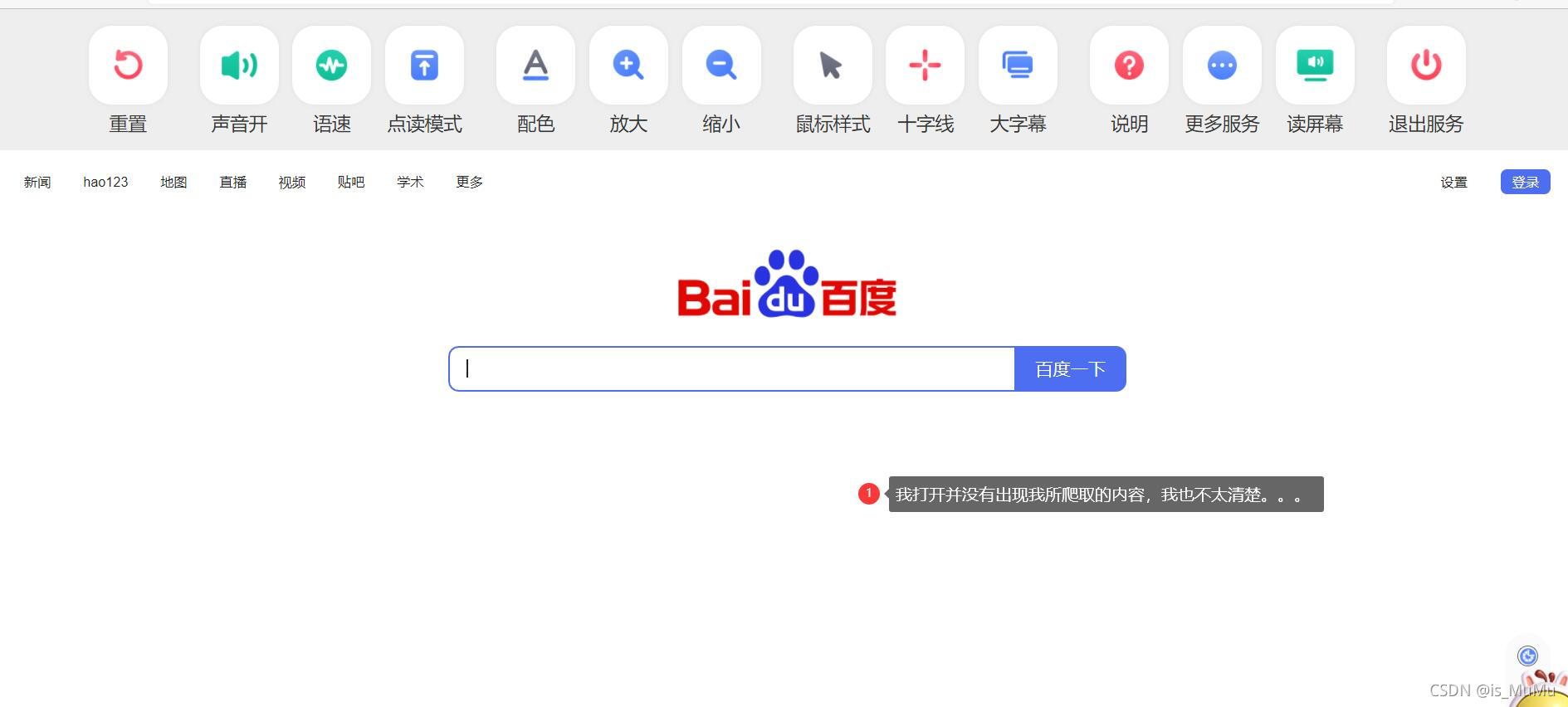
运行结果如下:

问题:我打开宋威龙.html并没有出现与他相关的网页,还是在百度首页。
互联网的广大朋友们,你们要是知道原因,欢迎留言!!!(如果后期我找到了,我会添加这块内容)
五、爬取百度翻译
import requests
import json
url='https://fanyi.baidu.com/sug'
kw=input('请输入翻译的单词:')
data={
'kw':kw
}
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2626.106 Safari/537.36'
}
r=requests.post(url,data=data,headers=headers)
content=r.json()
fileName=kw+'.json'
with open(fileName,'w',encoding='utf-8') as fp:
json.dump(content,fp=fp,ensure_ascii=False)
j=content['data'][1]['v']
print(j) 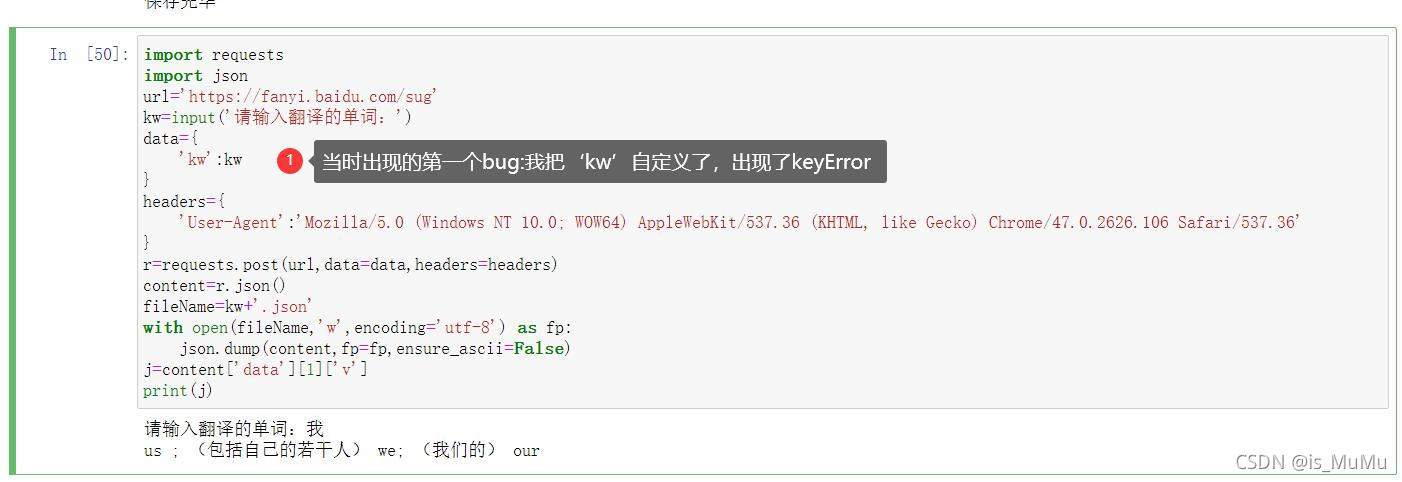


跟着川川学习爬虫的第四天,继续加油!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









