






在学了一个月的爬虫,也看了很多视频,基本了解了大概思路,但是还是有一些疑问,这里小结一下我自己的感受
首先就是要导入一些第三方库,请求数据的requests,解析数据的re,BeatuifulSoup,Xpath........
安装第三方库,可以看https://blog.youkuaiyun.com/qq_54641516/article/details/124697321
import bs4 #网页解析,获取数据(将网页进行数据拆分)
from bs4 import BeautifulSoup #只调用BeautifulSoup这个模块
import re #正则表达式,进行文字匹配 (进行数据的提炼)
import requests #制定URL,获取网页数据(给网页就可以爬取数据)
import xlwt #进行excel操作(将数据存放到excel中)
import sqlite3 #进行SQLite数据库操作(将数据库存放到数据库中)
import csv #可以将数据存为csv格式
from lxml import etree #用Xpath解析数据
然后我们拿到一个网,可以先看一下页面源代码,最简单的是源代码里有我们想要的数据,数据就在html里面,那我们就可以在获取网页信息后直接进行解析提炼
import requests
import re
url = 'https://movie.douban.com/top250?start='
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
res = requests.get(url,headers = headers)
#if result.status_code == 200: #当请求的状态码为200时,则说明请求成功
# print(res.text)
page = res.text
#解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
#开始匹配
result = obj.finditer(page)
for i in result:
print(i.group("name"))
这里简单爬取了豆瓣评分 Top250第一页的电影名
例子很简单,headers简单模拟了一下浏览器的头部,小小的处理了一下反爬。
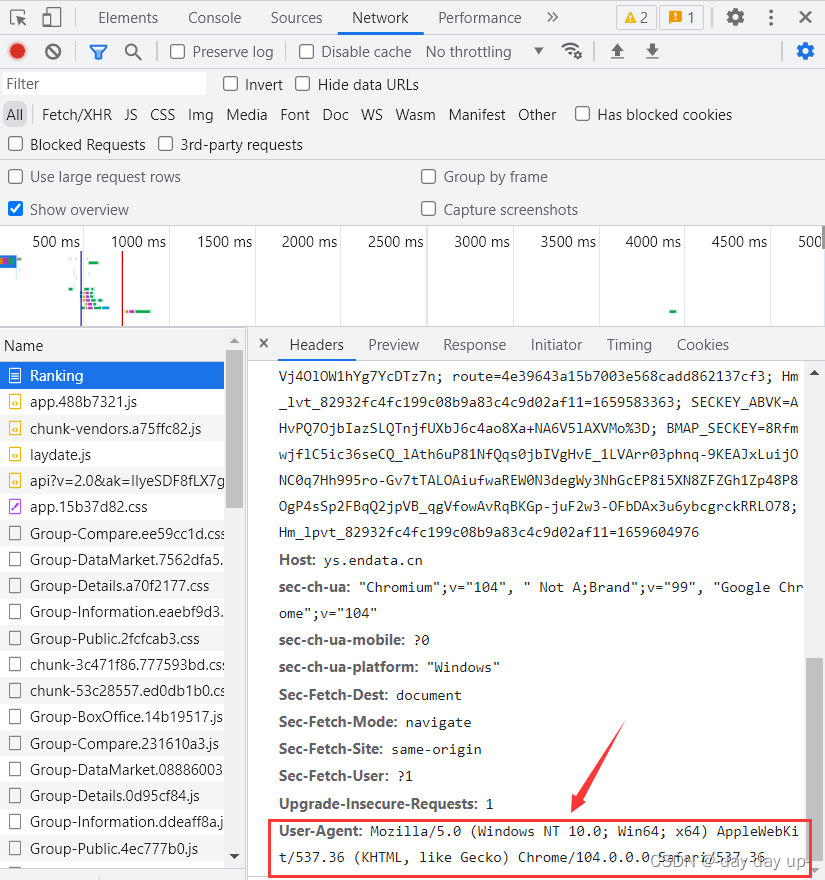
headers是让网站不要把我们的爬虫程序当成爬虫,把我们的程序伪装成浏览器,设置方法就是网页主页--检查--Network -- all -- header -- 找到对应信息复制粘贴过来,一般只加user agent就够了,但是有些网站会加入防盗链referer等,我们可以尽可能多的在headers中加入信息(如下图的信息都可以添加)
在解析数据时有很多方法,比如正则表达式,Xpath,bs4......相比较我认为正则表达式比较难分析,上图的例子就是正则表达式的运用
当网页的页面源代码和检查中的Elements一样时,也可以用Xpath解析,下面附一个例子
import requests
from lxml import etree #会报错,不影响
#etree可以加载很多东西,etree.HTML() , etree.parse() 加载文件 ,etree.xml()
#etree包含Xpath()的功能,Xpath在XML文档中查找信息
#如果要从script里取内容最好用re,不符合Xpath(script是JS代码,不是HTML标签)
url = 'https://shenzhen.zbj.com/search/service/?kw=java&r=1'
res = requests.get(url)
#print(res.text)
html = etree.HTML(res.text)
divs = html.xpath('//*[@id="__layout"]/div/div[3]/div/div[3]/div[4]/div[1]/div[1]')
#divs = html.xpath('/html/body/div[2]/div/div/div[3]/div/div[3]/div[4]/div[1]/div')
for div in divs:
#text()拿文本内容
comment = "".join(div.xpath("./div[3]/div[2]/div[1]/span/text()"))
title = div.xpath("./div[3]/a[1]/text()")[0] #[0]将数据从列表中拿出来
price = div.xpath("./div[3]/div[1]/span/text()")[0].strip('¥') #将¥去掉
number = ":".join(div.xpath("./div[3]/div[2]/div[2]/span/text()")) #用”:“将列表中两个数据连接起来
print(title)
print(comment)
print(number)
print(price)
这些是一些基础的爬虫解析
如果碰到比较复杂的网页,即数据不在源代码中,而是在子链接中,这时我们要先将子链接爬取下来,再进行请求解析
后面还有多任务异步,解密......
我在处理当数据存在Elements时,但源代码中几乎没有数据 时还是比较困难,嗯,继续学习,希望可以继续写下去


















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











