









 本文通过实验展示了如何使用Python和sklearn库在泰坦尼克数据集中构建决策树和逻辑回归模型,比较了它们在处理缺失值、特征编码及交叉验证下的性能,发现逻辑回归模型在F1-score上稍优。
本文通过实验展示了如何使用Python和sklearn库在泰坦尼克数据集中构建决策树和逻辑回归模型,比较了它们在处理缺失值、特征编码及交叉验证下的性能,发现逻辑回归模型在F1-score上稍优。
知识点
1.决策树模型可以用于分类预测
实验目的
1.学习建立决策树分类预测模型,比较决策树和逻辑回归模型的差异
2.学习使用LabelEncoder对离散变量进行编码和简单的缺失值处理方法
实验环境
1.Oracle Linux 7.4
2.Python 3
实验数据
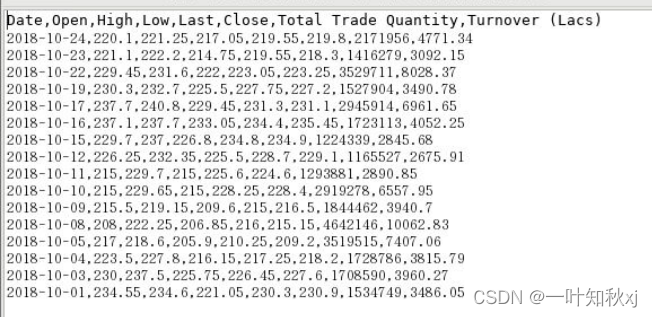
使用pandas读取文件
import pandas as pd
df = pd.read_csv('/root/experiment/datas/titanic.csv',index_col=0)
df.head()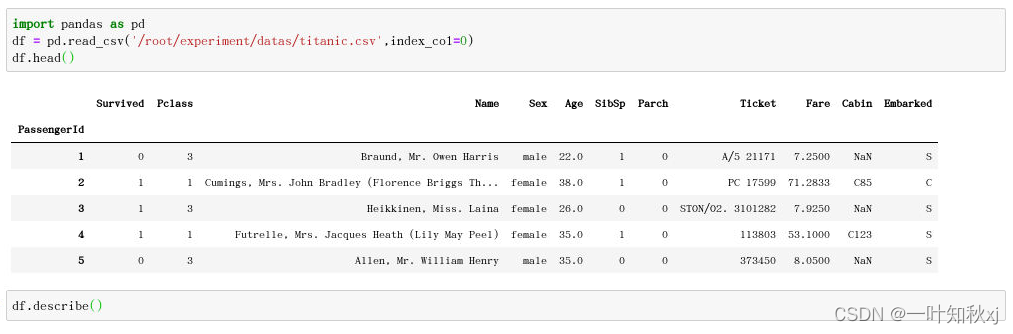
查看数据的统计描述
df.describe()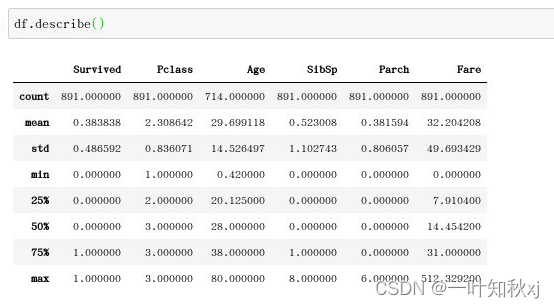
查看缺失值
df.isnull().sum()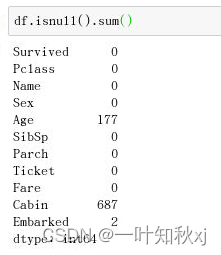
查看数据分布
import matplotlib.pyplot as plt
df.hist(figsize=(10,8))
plt.show()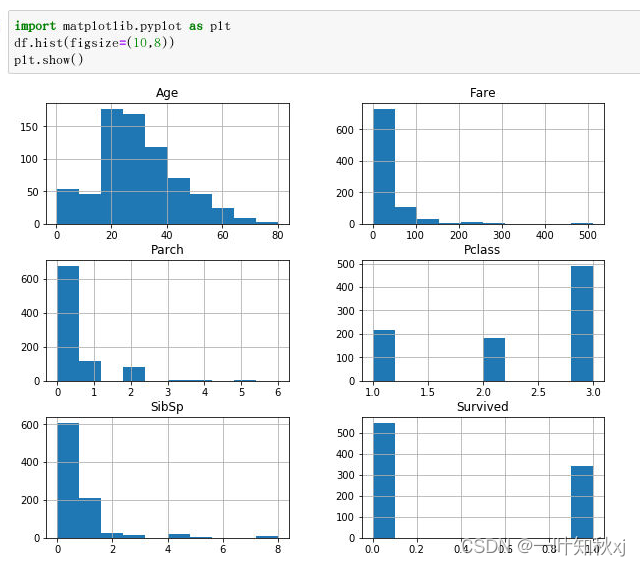
去掉无关字段
df = df.drop(['Name','Ticket','Cabin'],axis=1)
df.columns
填充Age缺失值
mean_age = df['Age'].mean()
tmp = df['Age'].copy()
tmp[df.Age.isnull()] = mean_age
df['Age_fill'] = tmp
del tmp
df = df.drop(['Age'],axis=1)
df.columns
使用LabelEncoder将离散变量转换为编码
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df_sex = le.fit(df['Sex'])
df['Sex'] = df_sex.transform(df['Sex'])
df = df.dropna()
df_embarked = le.fit(df['Embarked'])
df['Embarked'] = df_embarked.transform(df['Embarked'])
df.info()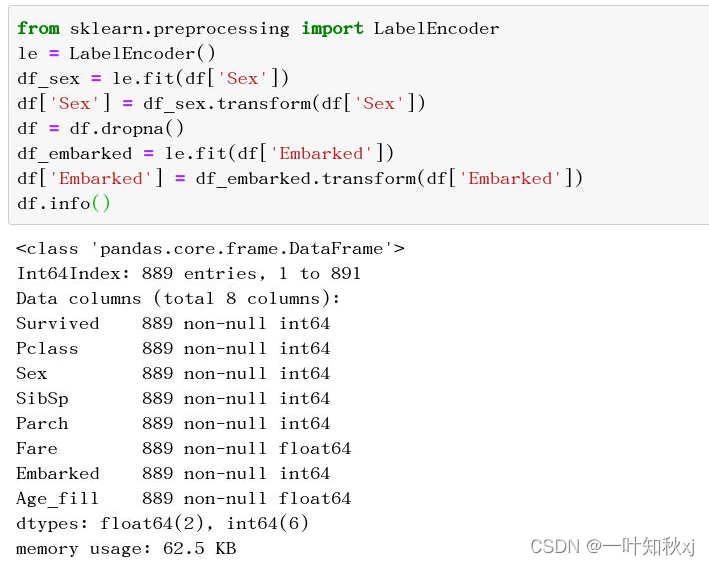
划分自变量和因变量
X = df.loc[:,df.columns!='Survived']
y = df.loc[:,df.columns=='Survived']划分训练集和测试集
from sklearn.model_selection import train_test_split
X_tr,X_ts,y_tr,y_ts = train_test_split(X,y)
X_tr.shape,X_ts.shape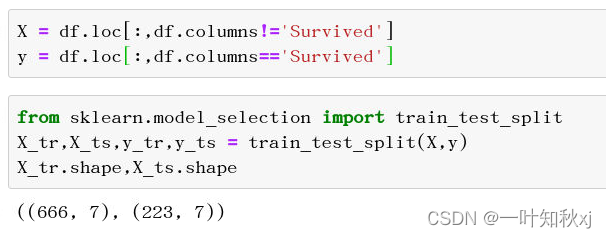
建立决策树模型
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc = dtc.fit(X_tr,y_tr)建立逻辑回归模型
from sklearn.linear_model import LogisticRegression
log = LogisticRegression(class_weight='balanced')
log.fit(X_tr,y_tr.values.ravel())
对测试集预测,查看混淆矩阵
y_dct_pred = dtc.predict(X_ts)
y_log_pred = log.predict(X_ts)查看决策树模型混淆矩阵
from sklearn.metrics import classification_report,confusion_matrix
confusion_matrix(y_ts,y_dct_pred)查看逻辑回归模型混淆矩阵
confusion_matrix(y_ts,y_log_pred)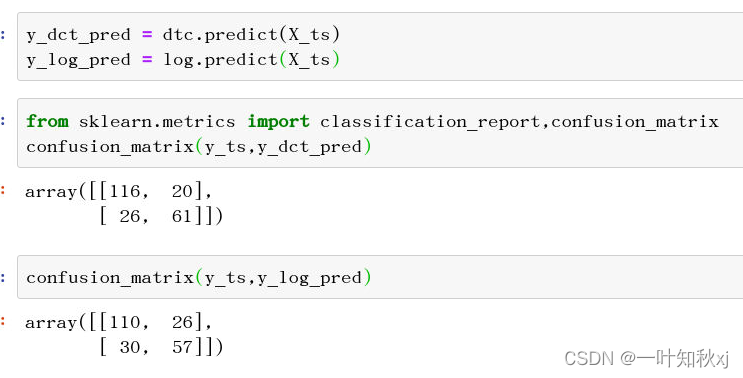
打印决策树模型混淆矩阵评分
print(classification_report(y_ts,y_dct_pred))打印逻辑回归模型混淆矩阵评分
print(classification_report(y_ts,y_log_pred))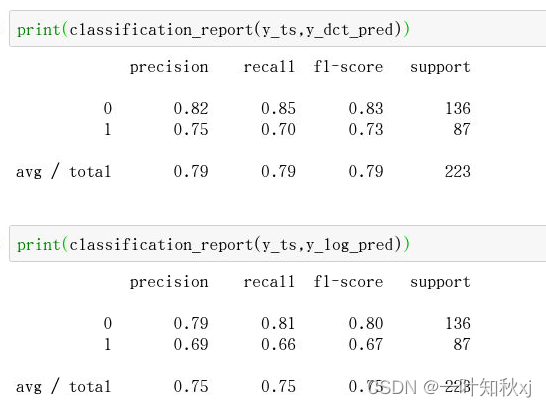
使用5折交叉验证计算决策树模型预测准确率
from sklearn.model_selection import cross_val_score
scores = cross_val_score(dtc,X,y,cv=5,scoring='accuracy')
scores.mean()使用5折交叉验证计算逻辑回归模型预测准确率
scores = cross_val_score(log,X,y.values.ravel(),cv=5,scoring='accuracy')
scores.mean()
.实验结论
1.本试验中,决策树模型在测试集上f1-score得分0.72
2.本试验中,逻辑回归模型在测试集上f1-score得分0.75,略好于决策树模型。
3.5折交叉验证显示,决策树模型准确率0.775。
4.5折交叉验证显示,逻辑回归模型准确率0.775。
5.综上,本试验中,逻辑回归模型和决策树模型差异不大。


















 1336
1336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











