







词法分析
一、实验目的
通过编写一个具体的词法分析程序,加深对词法分析原理的理解。掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数(整数和浮点数)、运算符(单符号运算符和组合运算符)、分隔符五大类。依次输出各个单词的内部编码及单词符号自身值。要能处理注释(/* …*/)。
二、实验预习提示
1、词法分析器的功能和输出格式
词法分析器的功能是输入源程序,输出单词符号。词法分析器的单词符号常常表示成以下的二元式(单词种别码,单词符号的属性值)。
2、单词的BNF表示
<标识符>----> <字母><字母数字串>
<无符号整数>----> <数字><数字串>
<加法运算符>----> +
<减法运算符>----> - 等等(需要大家自行找出各类单词的定义,可以是正规文法、有穷自动机或者正规式,最后都要转换成最小DFA再使用)
3、模块结构(见课本第四章)(适当修改)
三、实验过程和指导
(一)准备:
1.阅读课本有关章节,明确语言的语法,写出基本保留字、标识符、常数(整数,浮点数)、运算符、分隔符。
2.初步编制好程序。
3.准备好多组测试数据。
(二)上机:
(三)程序要求:
1.要求用可视化编程工具编写;要求可视化有界面(即一般windows下应用程序界面)。源程序可以放在文件里,打开可编辑;识别出的单词符号,可以输出到显示器上,并以文件形式存放。可以有“读入源程序”,“词法分析”等类似这样的功能按钮。
2.输入为c语言源代码。
程序输入/输出示例:
如源程序为C语言。输入如下一段:
main() /lex/
{
int a1,b2;
a1=10;
b2=a1+20.35;
/* com begin
Com end
/
123+++;
a1+=110;
1.2.3
}
要求输出如下(也可以以文件形式输出)。
(2,”main”)
(5,”(“)
(5,”)“)
(5,”{“}
(1,”int”)
(2,”a1”)
(5,”,”)
(2,”b2”)
(5,”;”)
(2,”a1”)
(4,”=”)
(3,”10”)
(5,”;”)
(2,”b2”)
(4,”=”)
(2,”a1”)
(4,”+”)
(3,”20.35”)
(5,”;”)
……
(5,”}“) 注:为右大括号
要求(可根据实际情况加以扩充和修改):
识别保留字:if、int、for、while、do、return、break、continue等等;单词种别码为1。
其他的都识别为标识符;单词种别码为2。
常数为无符号数;单词种别码为3。
运算符包括:+、-、、/、=、>、<等;可以考虑更复杂情况>=、<=、!= ;单词种别码为4。
分隔符包括: “,”“;”“(”“)”“{”“}”等; 单词种别码为5。
(四)程序思路(仅供参考):
0.定义部分:定义常量、变量、数据结构。
1.初始化:从文件将源程序输入到字符缓冲区中。
2.取单词前:去掉多余空白。调用过程GETNB();
3.提取字符组成单词,利用课本介绍的转换图构,造单词扫描过程SCAN(),可根据实际情况加以修改。
4.判断单词的种别码,调用过程LOOKUP();
5.显示(导出)结果。
四、实验原理
本实验通过有限状态机实现对用户输入的程序代码进行词法分析并打印出来。
当程序获取用户输入后,首先将输入的代码程序进行单词分离,对每一个单词依次加入到有限状态机中进行分析。
状态机工作流程如下图所示:
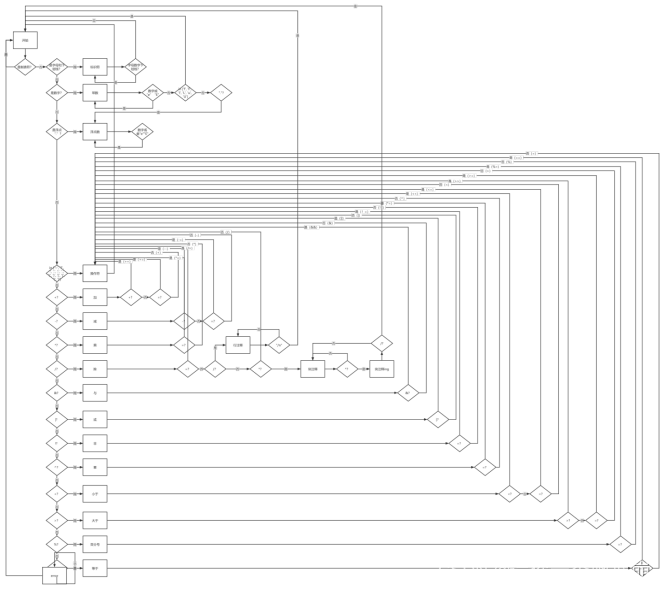
程序界面(效果图)
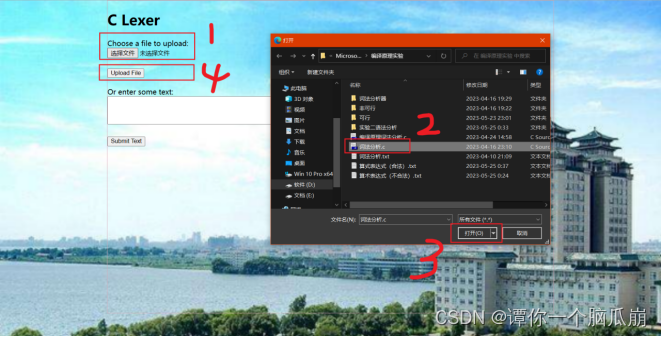
运行代码后访问网址:http://127.0.0.1:8000
按如下图中步骤,可对文件中的C语言程序进行词法分析
如下图为词法分析结果:
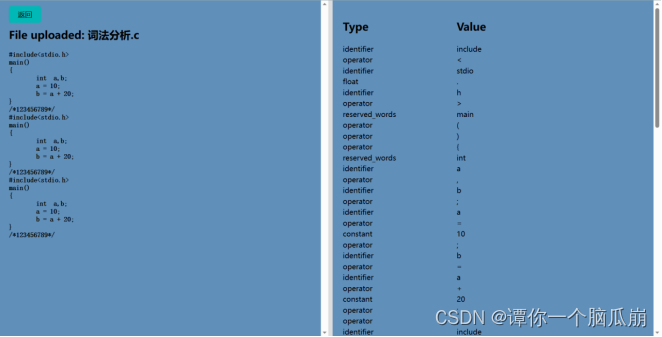
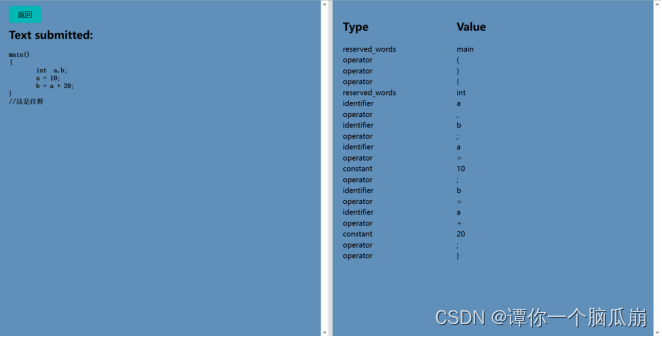
或者如下图选择自己手动需要进行词法分析的程序

分析结果如下:
程序代码
main.py
from fastapi import FastAPI, Request, Form, File, UploadFile
from fastapi.templating import Jinja2Templates
import uvicorn
app = FastAPI()
templates = Jinja2Templates(directory="templates")
from fastapi import Response
reserved_words = [
'main','if','int','for','while','do','return','break','continue',
'auto','break','case','char','const','continue','default','do',
'double','else','enum','extern','float','for','goto','if','int',
'long','register','return','short','signed','sizeof','static',
'struct','switch','typedef','union','unsigned','void','volatile',
'while'
]
# C语言词法分析器状态机
class LexerStateMachine:
def __init__(self):
self.current_state = 'start'
self.current_token = ''
self.tokens = []
# 状态转移函数
def transition(self, char):
#首先在start状态时遇到各种字符应该怎么跳转
if self.current_state == 'start':
if char in ['#',' ','\t', '\n', '\r']:
pass # 空格、制表符、换行符和回车符不是单词的一部分,忽略它们
elif char.isalpha() or char == '_':
self.current_state = 'identifier'
self.current_token += char
elif char.isdigit():
self.current_state = 'constant'
self.current_token += char
#小数浮点数
elif char in ['.']:
self.current_state = 'float'
self.current_token += char
elif char in ['~', '?', ':', ',', ';', '.', '(', ')', '[', ']', '{', '}']:
self.tokens.append(('operator', char))
self.current_state = 'start'
self.current_token = ''
#此后为对运算符的详细状态转换
elif char == '+':
self.current_state = '加'
self.current_token += char
elif char == '-':
self.current_state = '减'
self.current_token += char
elif char == '*':
self.current_state = '乘'
self.current_token += char
elif char == '/':
self.current_state = '除'
self.current_token += char
elif char == '&':
self.current_state = '&'
self.current_token += char
elif char == '|':
self.current_state = '或'
self.current_token += char
elif char == '!':
self.current_state = '非'
self.current_token += char
elif char == '^':
self.current_state = '幂'
self.current_token += char
elif char == '<':
self.current_state = '小于'
self.current_token += char
elif char == '>':
self.current_state = '大于'
self.current_token += char
elif char == '%':
self.current_state = '百分号'
self.current_token += char
elif char == '=':
self.current_state = '等于'
self.current_token += char
#以上是对运算符的详细
else:
self.tokens.append(('error', char))
self.current_state = 'start'
self.current_token = ''
#以下是对运算符的二次判断
elif self.current_state == '加':
if char =='+':
self.current_token += char
self.tokens.append(('operator', self.current_token))
self.current_state = 'start'
self.current_token = ''
elif char =='=':
self.current_token  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7061
7061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











