






 本文详细介绍了Hive中的UDF(用户自定义函数)、UDAF(用户自定义聚合函数)和UDTF(用户自定义表函数),包括它们的产生背景、解决的问题和实现步骤。UDF用于一对一的转换,UDAF处理多对一的聚合操作,而UDTF则解决一行输入多行输出的需求。通过自定义Java类并实现相应接口,可以扩展Hive的功能,满足复杂业务需求。
本文详细介绍了Hive中的UDF(用户自定义函数)、UDAF(用户自定义聚合函数)和UDTF(用户自定义表函数),包括它们的产生背景、解决的问题和实现步骤。UDF用于一对一的转换,UDAF处理多对一的聚合操作,而UDTF则解决一行输入多行输出的需求。通过自定义Java类并实现相应接口,可以扩展Hive的功能,满足复杂业务需求。
一.UDF
1.1产生背景和意义
因为系统的内置函数无法满足所有的业务需求,所以需要我们自己编写函数去实现,应用场景广泛,解决了函数的扩展问题,丰富了可定制化的业务需求
1.2要求-要解决的问题
in:out=1:1 输入一条记录,同时产生一条结果,属于最常见的自定义函数
1.3实现步骤
自定义一个java类继承UDF类
约定俗成的重写evaluate方法
打包并上传到hive环境下
创建模板函数,在后面可以使用该函数名称进行调用
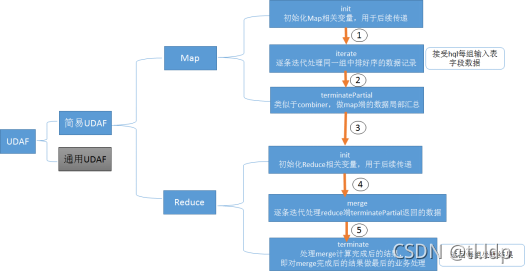
二.UDAF
2.1要求-要解决的问题
in:out=N:1 输入多条记录,同时产生一条结果,即列转行
2.2实现步骤
自定义一个java类继承UDAF类
内部定义一个静态类,实现UDAFEvaluator接口
实现init,iterate,terminatePartial,merge,terminate方法
打包并上传到hive环境下
创建模板函数,在后面可以使用该函数名称进行调用
三.UDTF
3.1要求-要解决的问题
解决一行输入多行输出的问题,即1:N,,一般由UDF+lateral view explode替代
lateral view explode实现行转列(一行输入多行输出)
UDF实现业务需求
3.2UDTF之实现
3.2.1继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF类
3.2.2实现initialize, process, close三个方法
3.2.3UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)
3.2.4初始化完成后,会调用process方法,真正的处理过程在process函数中
在process中,每一次forward()调用产生一行;
如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数
3.2.5最后close()方法调用,对需要清理的方法进行清理


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









