







一、卷积神经网络
以下内容将从基本概念、核心组件、工作原理、数学基础、优势与局限性等方面介绍CNN。
1. 什么是卷积神经网络(CNN)
卷积神经网络(Convolutional Neural Networks, CNN)是一类专门用于处理具有类似网格结构的数据(如图像)的深度学习模型。CNN在计算机视觉领域表现尤为出色,广泛应用于图像分类、目标检测、图像分割等任务。
主要特点:
- 局部连接:每个神经元仅与输入数据的一个局部区域相连,减少参数数量。
- 权重共享:同一卷积核在整个输入上滑动,减少参数并提取共性特征。
- 多层结构:通过多层卷积和池化操作,逐步提取从低级到高级的特征。
与传统的全连接神经网络相比,CNN更适合处理高维数据,如图像,因为其结构能够有效捕捉空间层次信息,减少计算复杂度并提升模型的泛化能力。
2. 卷积神经网络的核心组件
CNN由多个不同类型的层组成,每种层在网络中扮演不同的角色。以下是CNN的主要组成部分及其作用。
卷积层(Convolutional Layer)
作用:提取输入数据的局部特征。通过多个卷积核(滤波器)在输入数据上进行滑动卷积操作,生成特征图(Feature Maps)。
关键参数:
- 卷积核大小(Kernel Size):通常为3x3、5x5等,决定了每次卷积操作覆盖的区域。
- 步幅(Stride):卷积核滑动的步伐,影响特征图的尺寸。
- 填充(Padding):在输入边缘填充额外的像素,控制输出尺寸,常见的填充方式有“same”(保持尺寸)和“valid”(无填充)。
示例:
假设输入图像为32x32x3(高x宽x通道),使用卷积核大小为3x3,步幅为1,填充为1,输出特征图为32x32x16(假设有16个卷积核)。
激活函数(Activation Function)
作用:引入非线性,使神经网络能够学习和表示更复杂的函数关系。
常用激活函数:
- ReLU(Rectified Linear Unit): f ( x ) = m a x ( 0 , x ) f(x) = max(0, x) f(x)=max(0,x),计算简单且有效,常用在卷积层和全连接层之后。
- Sigmoid: f ( x ) = 1 / ( 1 + e − x ) f(x) = 1 / (1 + e^{-x}) f(x)=1/(1+e−x),通常用于输出层,适用于二分类任务。
- Tanh: f ( x ) = t a n h ( x ) f(x) = tanh(x) f(x)=tanh(x),输出范围为-1到1,适用于隐藏层。
示例:
ReLU是最常用的激活函数,因为它有助于缓解梯度消失问题,加速训练过程。
池化层(Pooling Layer)
作用:下采样特征图,减少数据的空间维度,降低计算量,同时提取主要特征,控制过拟合。
常见类型:
- 最大池化(Max Pooling):取池化窗口内的最大值,保留最显著特征。
- 平均池化(Average Pooling):取池化窗口内的平均值,保留整体信息。
关键参数:
- 池化窗口大小(Pool Size):如2x2、3x3等。
- 步幅(Stride):通常与池化窗口大小相同,避免重叠。
示例:
2x2的最大池化将输入的4个像素缩减为1个最大值,将特征图的尺寸减半。
全连接层(Fully Connected Layer)
作用:将高层次的特征图展平,并连接到输出层,实现最终的分类或回归任务。
特点:
- 参数量大:每个神经元与上一层的所有神经元相连,参数数量为上一层神经元数量与本层神经元数量的乘积。
- 处理高层特征:通常位于网络的后部,结合多层卷积和池化提取的特征进行决策。
示例:
在图像分类任务中,最后一个全连接层的输出维度通常等于分类类别数。
归一化层(Normalization Layer)
作用:加速训练过程,稳定模型,防止梯度消失或爆炸。
常见类型:
- 批量归一化(Batch Normalization):对每一小批量的数据进行归一化,减少内部协变量偏移(Internal Covariate Shift)。
- 层归一化(Layer Normalization):对每一层的所有激活进行归一化,常用于循环神经网络。
- 实例归一化(Instance Normalization):对每一个样本的每一个通道进行归一化,常用于生成对抗网络(GAN)中。
示例:
批量归一化通常插入在卷积层和激活函数之间,可显著提升训练速度和模型性能。
3. 卷积神经网络的工作原理
理解CNN的工作原理,有助于深入把握其优势和应用场景。以下几个关键概念是理解CNN工作机制的基础。
局部感受野(Receptive Field)
定义:局部感受野是指一个神经元在输入数据上的感知范围。在卷积层中,每个神经元仅关注输入数据的一个局部区域,通过多层堆叠,神经元的感受野可以覆盖更大的区域。
作用:
- 参数共享:每个卷积核在局部感受野内提取特征,减少模型参数。
- 空间局部性:利用数据的空间结构,提升特征提取效率。
示例:
在图像处理中,一个3x3的卷积核每次滑动覆盖输入图像的3x3区域,提取局部特征。
权重共享(Weight Sharing)
定义:在卷积层中,同一卷积核(权重集合)在整个输入数据上进行滑动卷积操作,这意味着多个神经元共享相同的权重。
作用:
- 减少参数数量:相比于全连接层,每个卷积核的参数数目固定,独立于输入数据的尺寸。
- 学习共性特征:同一卷积核适用于整个输入区域,学习到的特征对位置具有不变性。
示例:
一个3x3的卷积核在输入图像上滑动,每次提取一个3x3区域的特征,共享相同的9个权重。
平移不变性(Translation Invariance)
定义:平移不变性指模型对输入数据的平移(移动)具有相应的鲁棒性,即特征的位置变化不会显著影响模型的输出。
实现机制:
- 池化层:通过下采样操作,减少特征图的空间维度,保留主要特征,提高对位置变化的鲁棒性。
- 多层结构:通过多层卷积和池化,逐步提取更高级、更具抽象性的特征,增强平移不变性。
示例:
即使物体在图像中的位置发生变化,经过多层卷积和池化后,模型仍能准确识别该物体。
4. 卷积操作的数学基础
理解卷积操作的数学原理,有助于深入了解CNN的工作机制。
一维卷积与二维卷积
一维卷积:
用于处理序列数据(如时间序列、文本),其中卷积核在输入序列上滑动,进行逐元素的乘积和求和。
数学表达式:
对于输入序列 ( x ) 和卷积核 ( w ),一维卷积输出 ( y ) 的第 ( i ) 个元素为:
y [ i ] = ∑ k = 0 K − 1 x [ i + k ] ⋅ w [ k ] y[i] = \sum_{k=0}^{K-1} x[i+k] \cdot w[k] y[i]=k=0∑K−1x[i+k]⋅w[k]
二维卷积:
用于处理图像数据,其中卷积核在输入图像的高度和宽度维度上滑动,进行矩阵乘积和求和。
数学表达式:
对于输入矩阵 X X X 和卷积核 W W W ,二维卷积输出 Y Y Y 的位置 ( i , j ) (i, j) (i,j)为:
Y ( i , j ) = ∑ m = 0 M − 1 ∑ n = 0 N − 1 X ( i + m , j + n ) ⋅ W ( m , n ) Y(i, j) = \sum_{m=0}^{M-1} \sum_{n=0}^{N-1} X(i+m, j+n) \cdot W(m, n) Y(i,j)=m=0∑M−1n=0∑N−1X(i+m,j+n)⋅W(m,n)
其中, M × N M \times N M×N 是卷积核的尺寸。
卷积核(Filter/Kernels)
定义:卷积核是一个小尺寸的权重矩阵,用于提取输入数据的特定特征,如边缘、纹理等。
特点:
- 可学习:卷积核的权重在训练过程中通过反向传播算法进行更新,学习适合任务的特征。
- 多样性:一个卷积层通常包含多个卷积核,每个卷积核学习不同的特征。
示例:
在图像处理中,不同的卷积核可以检测垂直边缘、水平边缘、斜边、角点等不同特征。
步幅(Stride)与填充(Padding)
步幅(Stride):
定义了卷积核在输入数据上滑动的步伐大小。步幅越大,输出特征图的尺寸越小。
公式(以二维卷积为例):
Output Size = ⌊ Input Size − Kernel Size + 2 × Padding Stride ⌋ + 1 \text{Output Size} = \left\lfloor \frac{\text{Input Size} - \text{Kernel Size} + 2 \times \text{Padding}}{\text{Stride}} \right\rfloor + 1 Output Size=⌊StrideInput Size−Kernel Size+2×Padding⌋+1
填充(Padding):
在输入数据的边缘添加额外的像素,以控制输出特征图的尺寸。
常见填充方式:
- 无填充(Valid Padding):不添加填充,输出特征图尺寸减小。
- 同填充(Same Padding):添加足够的填充,使输出特征图尺寸与输入相同。
示例:
对于一个32x32的输入图像,使用3x3的卷积核,步幅为1,填充为1,输出特征图尺寸为32x32。
5. 常见的卷积神经网络架构
卷积神经网络发展一览图
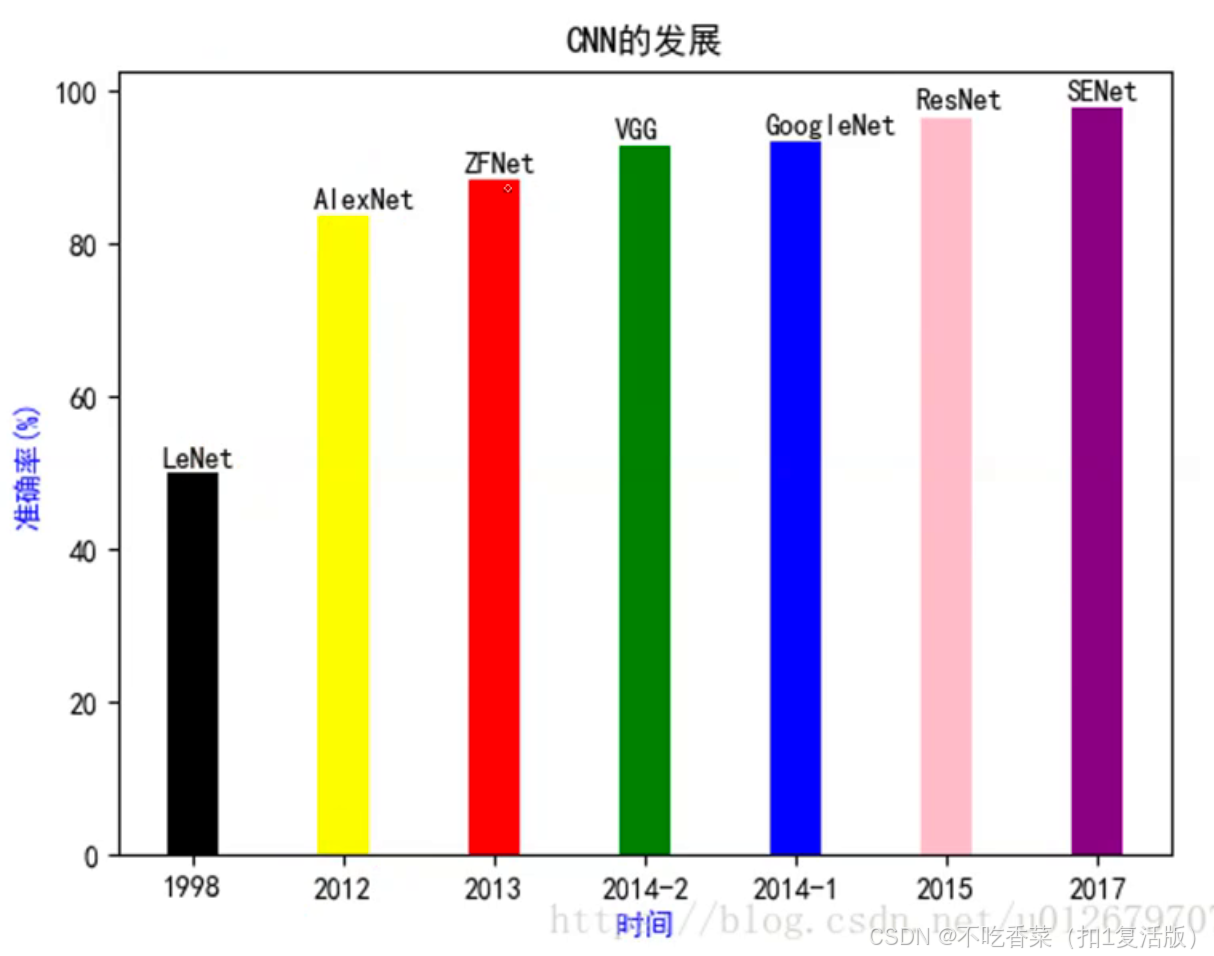
随着深度学习的发展,研究者设计了多种CNN架构,以提升模型的性能和效率。以下是几个具有代表性的CNN架构。
LeNet
提出者:Yann LeCun等人,1998年。
特点:
- 结构简单:包含两个卷积层和三个全连接层。
- 应用:最早用于手写数字识别(如MNIST数据集)。
- 贡献:奠定了现代CNN的基础,展示了卷积层和池化层的有效组合。
结构:
- 卷积层1:6个5x5卷积核,输出尺寸为28x28x6。
- 池化层1:2x2平均池化,输出尺寸为14x14x6。
- 卷积层2:16个5x5卷积核,输出尺寸为10x10x16。
- 池化层2:2x2平均池化,输出尺寸为5x5x16。
- 全连接层1:120个神经元。
- 全连接层2:84个神经元。
- 输出层:10个神经元(对应10个类别)。
AlexNet
提出者:Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton,2012年。
历史:
- AlexNet 在 ImageNet LSVRC-2012 的比赛中取得了 top-5 错误率为 15.3% 的成绩(第二名是 30% 的错误率)。
- AlexNet 有 6 亿个参数和 650,000 个神经元,包含 5 个卷积层,有些层后面跟了 max-pooling 层, 然后 3 个全连接层。
- 自 AlexNet ,引起了深度学习的狂潮。
结构:
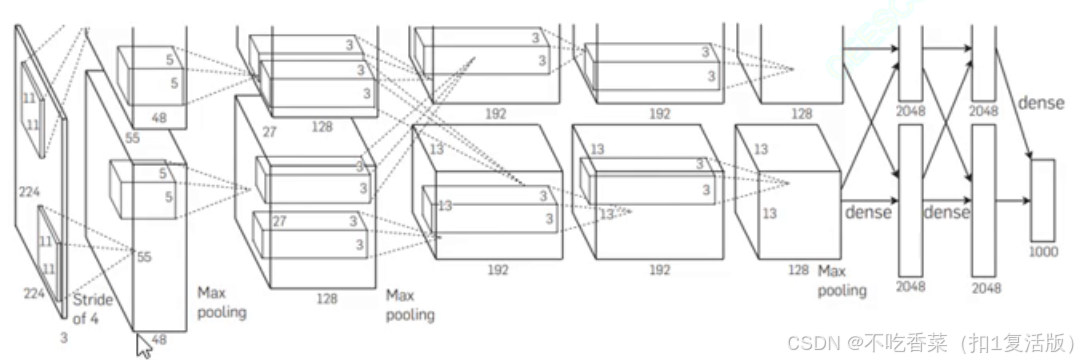
特点:
- 深度更深:包含5个卷积层和3个全连接层。
- 使用ReLU激活函数:引入ReLU加速训练。
- GPU加速训练:利用GPU进行大规模并行计算。
- 数据增强与Dropout:采用数据增强和Dropout减少过拟合。
- 池化与归一化:池化减轻计算复杂度,归一化让训练能够尽量少受到不同数据不同量纲的影响,让模型更加关注数据的分布,缓解梯度消失和梯度爆炸 。
- 突破ImageNet:在ImageNet竞赛中取得显著领先,推动深度学习的发展。
结构:
- 卷积层1:96个11x11卷积核,步幅4,输出尺寸为55x55x96。
- 池化层1:3x3最大池化,输出尺寸为27x27x96。
- 卷积层2:256个5x5卷积核,输出尺寸为27x27x256。
- 池化层2:3x3最大池化,输出尺寸为13x13x256。
- 卷积层3:384个3x3卷积核,输出尺寸为13x13x384。
- 卷积层4:384个3x3卷积核,输出尺寸为13x13x384。
- 卷积层5:256个3x3卷积核,输出尺寸为13x13x256。
- 池化层3:3x3最大池化,输出尺寸为6x6x256。
- 全连接层1:4096个神经元。
- 全连接层2:4096个神经元。
- 输出层:1000个神经元(对应1000个类别)。
VGGNet
提出者:Simonyan 和 Zisserman,2014年。
特点:
- 统一的卷积层结构:使用多个3x3的小卷积核堆叠代替大卷积核,增加网络深度。
- 深度加深:VGG16和VGG19分别包含16和19层。
- 参数量大:虽然深度增加,但参数量也显著增加。
- 迁移学习:预训练的VGG模型常用于迁移学习任务。
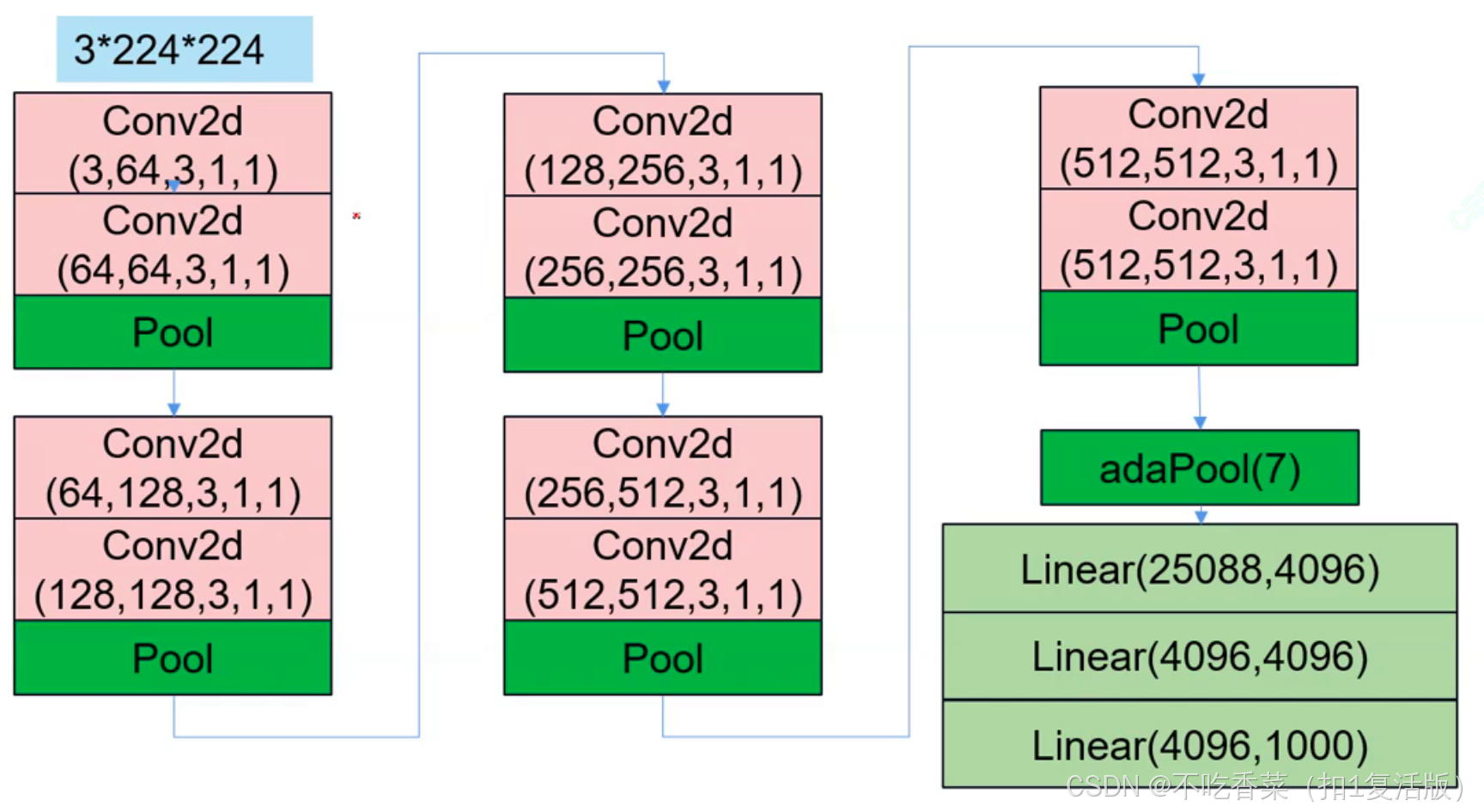
结构(以VGG16为例):
- 卷积块1:2个3x3卷积层,输出尺寸为224x224x64。
- 池化层1:2x2最大池化,输出尺寸为112x112x64。
- 卷积块2:2个3x3卷积层,输出尺寸为112x112x128。
- 池化层2:2x2最大池化,输出尺寸为56x56x128。
- 卷积块3:3个3x3卷积层,输出尺寸为56x56x256。
- 池化层3:2x2最大池化,输出尺寸为28x28x256。
- 卷积块4:3个3x3卷积层,输出尺寸为28x28x512。
- 池化层4:2x2最大池化,输出尺寸为14x14x512。
- 卷积块5:3个3x3卷积层,输出尺寸为14x14x512。
- 池化层5:2x2最大池化,输出尺寸为7x7x512。
- 全连接层1:4096个神经元。
- 全连接层2:4096个神经元。
- 输出层:1000个神经元。
ResNet
提出者:Kaiming He 等人,2015年。
特点:
- 残差连接(Residual Connections):引入跳跃连接,解决深层网络的退化、梯度消失梯度爆炸问题。
- 极深网络:ResNet-50、ResNet-101、ResNet-152等,包含数百层。
- 高效训练:通过残差学习,使得超深网络能够有效训练,并提升性能。
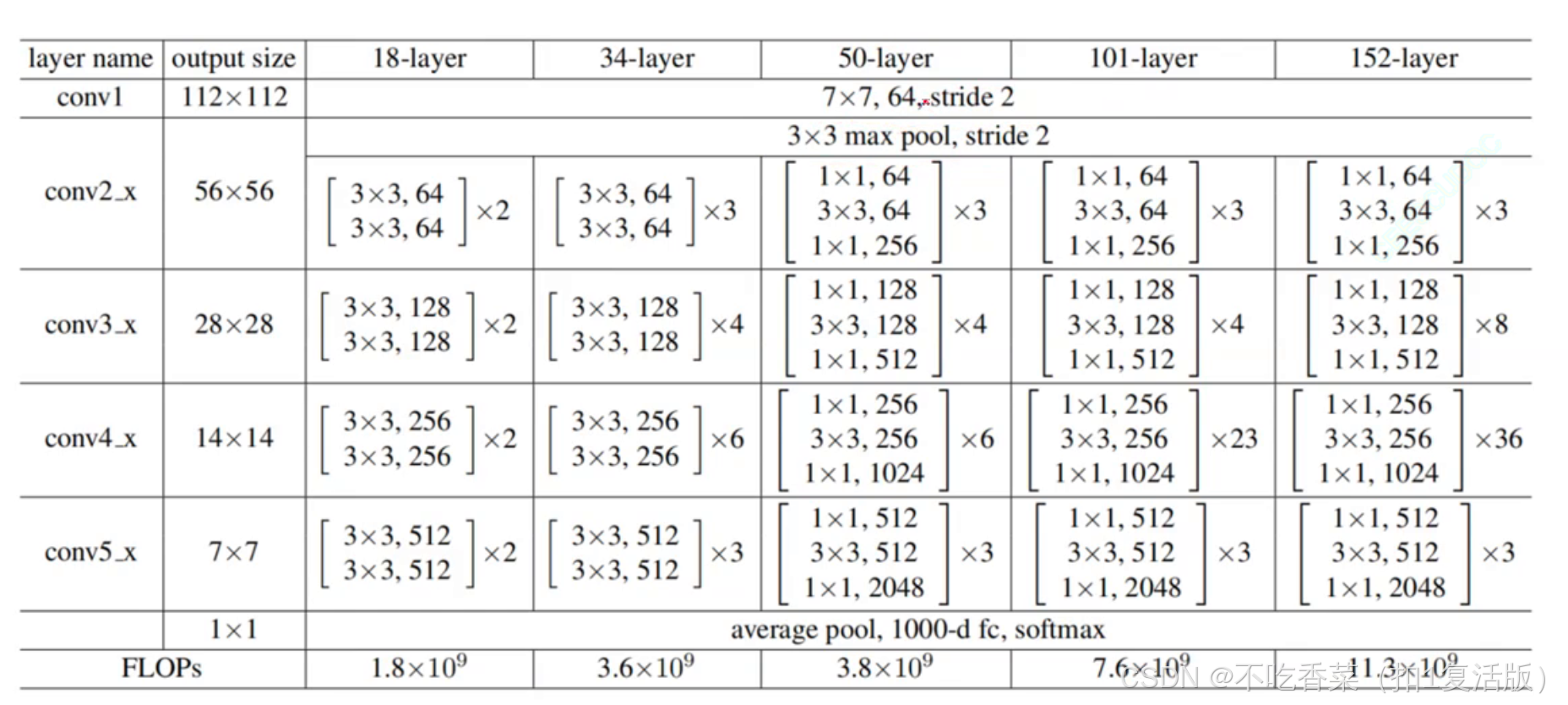
结构:
- 基础模块:基本的残差块(Residual Block),包含两个或三个卷积层,并通过恒等映射进行跳跃连接。
- 网络层次:多个残差块堆叠而成,每个阶段的特征图数量逐渐增加,空间尺寸逐渐减小。
残差块示意图:
输入 -> 卷积层1 -> 卷积层2 -> 输出
\__________________________/ (跳跃连接)
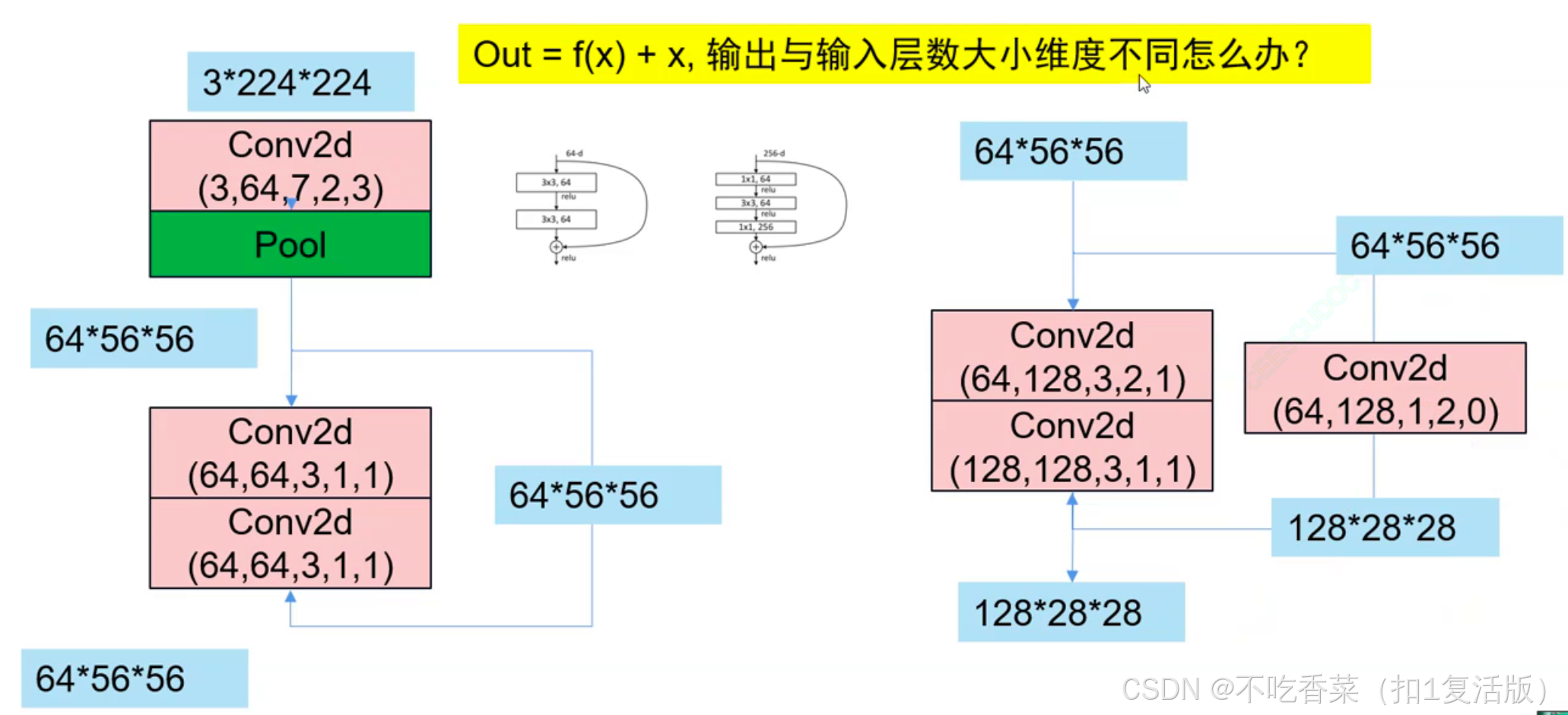
resnet残差计算的两种情况:
- 如果输入和输出维度一样,就可以直接相加,如左图所示。
- 但如果维度不同,如右图所示,则可以对输入进行一个
1
×
1
1\times1
1×1 的卷积得到和输出同样维度的数据,再相加(
1
×
1
1\times1
1×1 的卷积核可以通过很小的参数量来达到复杂卷积神经网络同样的输出数据的维度,所以
1
×
1
1\times1
1×1 常用于减小参数量)
Inception
提出者:Google团队,2014年。
特点:
- Inception模块:在同一层内并行使用多个不同尺寸的卷积核和池化操作,捕捉多尺度特征。
- 高效参数利用:通过瓶颈层(1x1卷积)减少计算量,提升网络效率。
- 多层次特征:集成不同尺度的特征,提高模型表达能力。
结构:
- Inception模块:包含1x1、3x3、5x5卷积核及3x3最大池化,并将各分支的输出拼接在一起。
- 网络层次:多个Inception模块堆叠而成,随着网络加深,特征图的数量和复杂度增加。
6. 卷积神经网络的优势与局限性
优势
- 参数效率高:通过卷积操作和权重共享,大大减少了模型参数数量,降低计算复杂度。
- 自动特征提取:无需手工设计特征提取器,CNN能够自动从数据中学习有用的特征。
- 空间层次信息:通过多层卷积和池化,CNN能够逐步提取从低级到高级的空间特征,捕捉复杂的模式。
- 平移不变性:对输入数据的平移具有鲁棒性,增强模型的泛化能力。
- 广泛应用:在计算机视觉领域取得了显著成果,广泛应用于图像分类、目标检测、语义分割等任务。
局限性
- 对旋转和尺度变化敏感:虽然具有平移不变性,但对旋转、尺度变化的鲁棒性较弱。
- 需要大量数据:深层CNN通常需要大量标注数据进行训练,数据获取和标注成本高。
- 计算资源需求高:训练深层CNN需要大量计算资源,尤其是GPU,限制了模型的训练和部署。
- 黑箱模型:CNN的决策过程不透明,难以解释模型的内部工作机制,影响其在某些领域的应用。
- 对输入噪声敏感:CNN在受到对抗样本攻击或输入噪声干扰时,性能可能显著下降。

















 948
948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









