




 转置卷积,或称反卷积,是深度学习中用于图像处理和上采样的工具。它通过转置卷积核和调整参数来扩展特征图尺寸,尤其在语义分割和生成模型中有广泛应用。注意需根据任务需求适配参数和网络结构。
转置卷积,或称反卷积,是深度学习中用于图像处理和上采样的工具。它通过转置卷积核和调整参数来扩展特征图尺寸,尤其在语义分割和生成模型中有广泛应用。注意需根据任务需求适配参数和网络结构。
1. 转置卷积
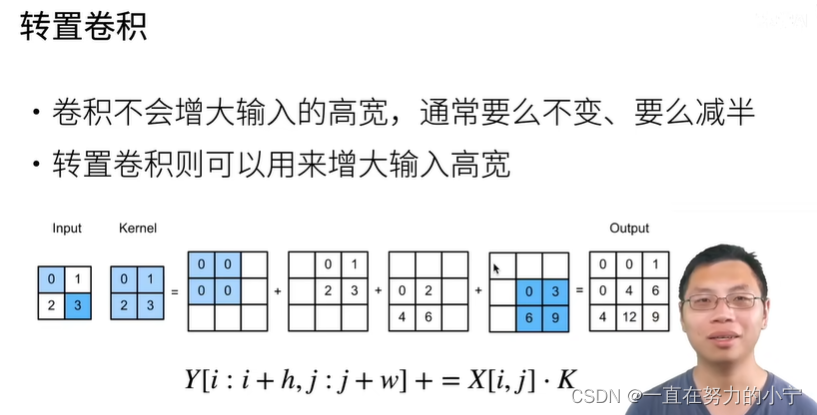 卷积层和汇聚层通常会减少下采样输入图像的空间维度(高和宽),卷积通常来说不会增大输入的高和宽,要么保持高和宽不变,要么会将高宽减半,很少会有卷积将高宽变大的。可以通过 padding 来增加高和宽,但是如果 padding 得比较多的话,因为填充的都是 0 ,所以最终的结果也是 0 ,因此无法有效地利用 padding 来增加高宽。
卷积层和汇聚层通常会减少下采样输入图像的空间维度(高和宽),卷积通常来说不会增大输入的高和宽,要么保持高和宽不变,要么会将高宽减半,很少会有卷积将高宽变大的。可以通过 padding 来增加高和宽,但是如果 padding 得比较多的话,因为填充的都是 0 ,所以最终的结果也是 0 ,因此无法有效地利用 padding 来增加高宽。
如果输入和输出图像的空间维度相同,会便于以像素级分类的语义分割:输出像素所处的通道维可以保有输入像素在同一位置上的分类结果(为实现输入和输出的空间维度的一致,在空间维度被卷积神经网络层缩小后,可以使用转置卷积增加上采样中间层特征图的空间维度)
语义分割的问题在于需要对输入进行像素级别的输出,但是卷积通过不断地减小高宽,不利于像素级别的输出,所以需要另外一种卷积能够将高宽变大




13.10. 转置卷积 https://zh-v2.d2l.ai/chapter_computer-vision/semantic-segmentation-and-dataset.html
https://zh-v2.d2l.ai/chapter_computer-vision/semantic-segmentation-and-dataset.html

转置卷积(Transpose Convolution),也被称为反卷积(Deconvolution),是一种用于图像处理和深度学习中的操作,用于将低维特征映射恢复到高维空间或进行上采样操作。尽管称之为"转置"卷积,但它实际上并不是卷积的逆操作。
转置卷积的过程类似于常规卷积操作,但卷积核的权重矩阵被转置。它可以将输入特征图扩展为更大尺寸的输出特征图,同时进行上采样操作。转置卷积在图像分割、目标检测、生成对抗网络(GANs)等任务中经常被使用。
使用转置卷积的一般步骤如下:
1. 定义转置卷积参数:包括卷积核大小、步幅、填充等。
2. 将输入特征图与转置卷积的权重矩阵进行卷积操作。这里的权重矩阵是转置的卷积核。
3. 对卷积结果进行激活函数处理,如ReLU。
4. 根据需要,可以进行进一步的转置卷积操作来增加特征图的尺寸。
转置卷积的关键特点是在卷积操作中使用了步幅和填充,使得输出特征图的尺寸可以与输入特征图不同。通过调整转置卷积的参数,可以控制输出特征图的尺寸和分辨率。
在深度学习中,转置卷积常用于生成模型中的上采样操作,例如将低分辨率特征图恢复到原始图像的尺寸,或者生成逼真的图像。此外,它还可以用于语义分割任务中的像素级预测,将低分辨率的特征图映射到高分辨率的预测结果。
需要注意的是,转置卷积的使用需要根据具体的任务和网络架构进行调整,包括选择合适的参数和结合其他操作。



















 2103
2103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









