







1 目前主流的开源模型体系有哪些?
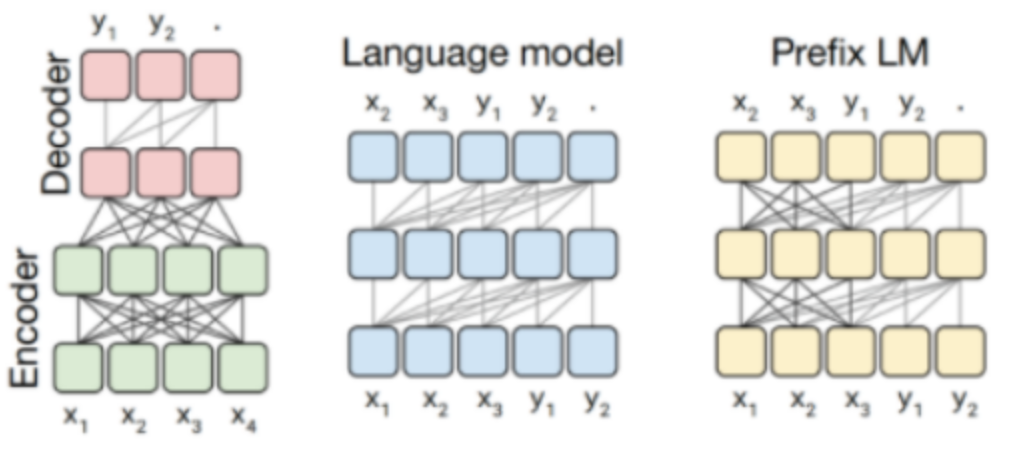
Prefix Decoder 系列模型
核心点: 输入采用双向注意力机制,输出为单向注意力。双向注意力意味着输入的每个部分都可以关注到输入的所有其他部分,这在理解上下文时具有很强的优势。
代表模型:ChatGLM、ChatGLM2、U-PaLM
补充知识:Prefix Decoder 类的模型常用于对话生成任务,因为这种架构能够更好地捕捉输入的上下文信息,同时在输出时保留生成内容的顺序依赖性。ChatGLM 系列模型在中文对话生成任务中表现优异,特别是在对中文语义的理解和生成方面有较好表现。而 U-PaLM 则代表了一种基于 Google PaLM 的预训练模型优化版本,拥有强大的多任务、多语言处理能力。
Causal Decoder 系列模型
核心点: 输入和输出都采用从左到右的单向注意力机制。输入只能依赖于其之前的部分,输出也是逐步生成的。这种架构适合生成类任务,因为每一步的输出都依赖于前面的内容。
代表模型:LLama 系列模型
补充知识:Causal Decoder 是经典的自回归生成模型结构。LLaMA 模型通过减少参数规模,同时保持高质量的内容生成能力,成为了当前开源社区中非常受欢迎的轻量级大模型。自回归模型虽然计算开销较小,但由于只能逐步生成,对于长文本生成,速度可能会较慢。
Encoder-Decoder 系列模型
核心点: 输入使用双向注意力,输出则采用单向注意力。这种架构结合了双向注意力在理解输入上下文的优势和单向注意力在生成输出时的顺序依赖特性。
代表模型:T5、Flan-T5、BART
补充知识:Encoder-Decoder 结构在机器翻译、文本摘要、问答等任务中应用广泛。T5模型通过“Text-To-Text”框架,将几乎所有任务转化为文本生成问题,大大提升了其通用性和任务迁移能力。BART 则通过加入降噪自编码器的预训练方式,在生成过程中能够有效修复输入噪声,适合需要对输入进行修正的生成任务。
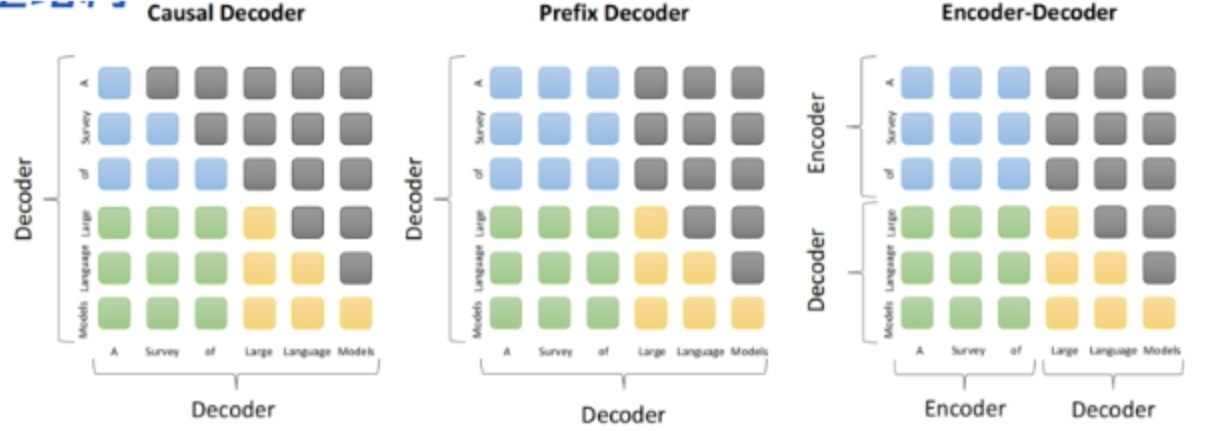
2 prefix Decoder 和 causal Decoder 和 Encoder-Decoder 区别是什么?
答:三者的主要区别在于 attention mask 不同。
- Encoder-Decoder
- 在输入上采用双向注意力,对输入的编码和理解更加充分
- 适用任务:在偏重文本理解的 NLP 任务上表现很好
- 缺点:在长文本生成任务上效果较差,且训练效率较低
- causal Decoder
- 自回归语言模型,预训练和下游应用是完全一致的,严格遵守只有后面的 token 才能看到前面的 token 的原则
- 适用任务:文本生成任务
- 缺点:训练效率高,zero-shot 能力强,具有涌现能力
- prefix Decoder
- prefix 部分的 token 能相互看到,属于是 causal Decoder 和 Encoder-Decoder 的折中方案
- 适用任务:机器翻译、文本摘要、问答
- 缺点:训练效率低。
3 大模型 LLM 的训练目标是什么?
1. 最大似然函数
根据 已有词 预测下一个词,训练目标为最大似然函数:
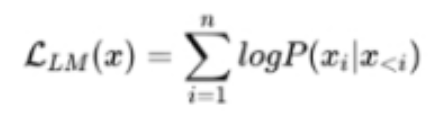
训练效率:Prefix Decoder < Causal Decoder
Causal Decoder 结构会在所有 token 上计算损失,而 Prefix Decoder 只会在 输出上计算损失。
2. 去噪自编码器
随机替换掉一些文本段,训练语言模型去恢复被打乱的文本段。目标函数为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









