







 本文介绍了pandas库的基础知识,包括Series数据类型的创建、属性及操作,如通过pd.Series()函数定义Series,使用.values、.index和.name属性获取数据。接着讲解了DataFrame,它是由Series组成的字典,具备行和列索引。最后提到了.loc函数用于按行索引获取DataFrame数据。
本文介绍了pandas库的基础知识,包括Series数据类型的创建、属性及操作,如通过pd.Series()函数定义Series,使用.values、.index和.name属性获取数据。接着讲解了DataFrame,它是由Series组成的字典,具备行和列索引。最后提到了.loc函数用于按行索引获取DataFrame数据。
1.介绍
pandas 库可谓是数据分析十分强大的库,接下来几天我会开始着手写pandas库的基础知识。一般导入格式为 :import pandas as pd
2.数据类型Series
函数原型:pd.Series( data, index, dtype, name, copy)
参数解读:data:ndarray数据或字典
index:数据索引标签,如果不指定,默认从 0 开始。
其中index未指定时为RangeIndex[start,stop,end)对象
dtype:数据类型
name:类似于excel表头名,可以不加
copy:拷贝数据,默认为 False
Series类型常用操作:
| 属性 | 作用 |
|---|---|
| 对象.values | 返回ndarray数组 |
| 对象.index | 返回index索引 |
| 对象.name | 放回name名字 |
| 对象.index.name | index索引的名字 |
import pandas as pd
a = pd.Series([1, 2, 3], index=[1, 2, 3], name='test')
a_values = a.values
a_index = a.index
a_name = a.name
index_name = a.index.name # None
print('a的ndarray数组是{}\na的index是{}\na的name是{}'.format(a_values, a_index,a_name))
"""
结果是:
a的ndarray数组是[1 2 3]
a的index是Int64Index([1, 2, 3], dtype='int64')
a的name是test
"""3.数据类型 DataFrame
DataFrame数据类型具有行索引和列索引,本质是Series组成的字典。
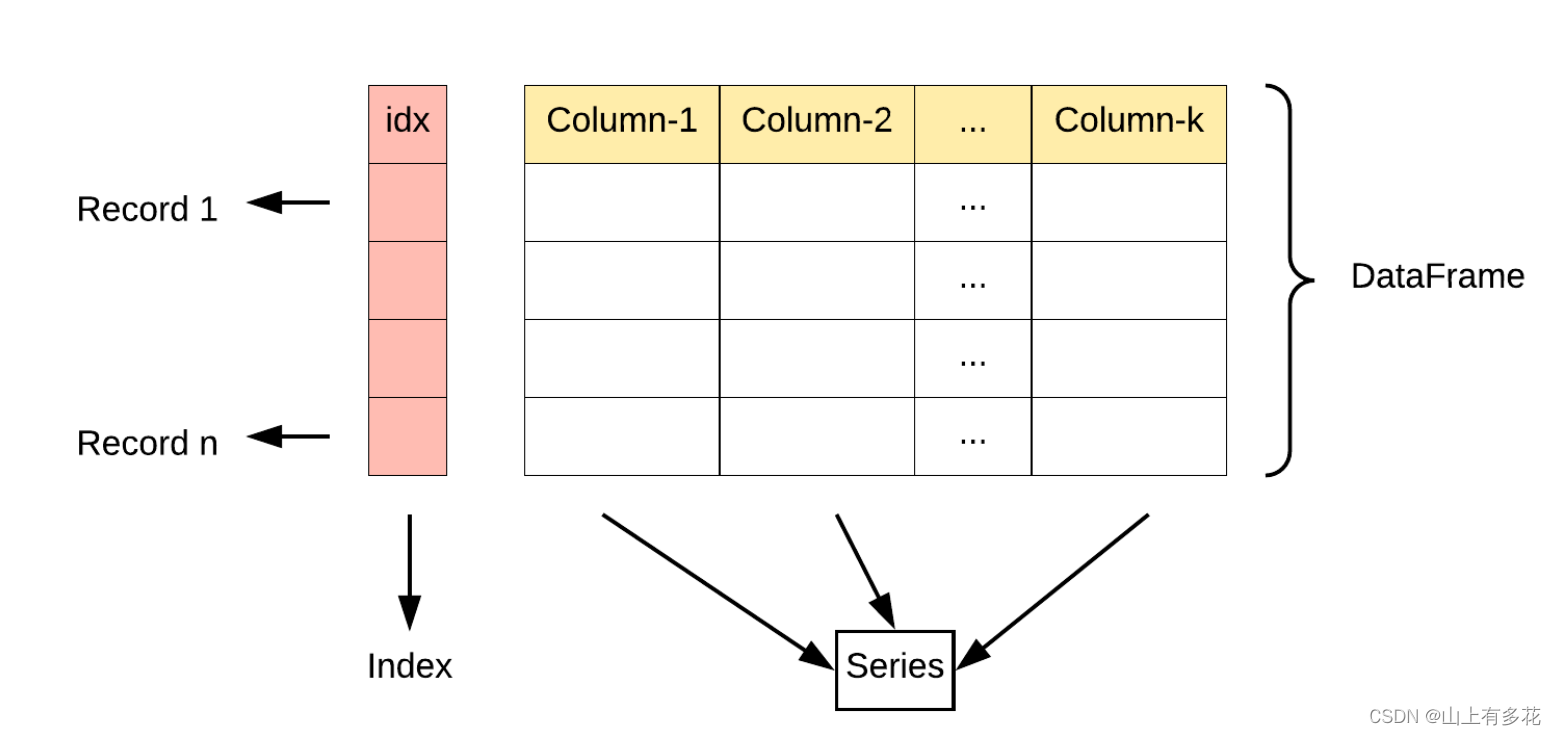
具体例子如下:,最左边即为index
函数原型:pd.DataFrame( data, index, columns, dtype, copy)
参数解读:data:ndarray、series, map, lists, dict类型
index:数据索引行标签,如果不指定,默认从 0 开始。
其中index未指定时为RangeIndex[start,stop,end)对象
columns:数据索引列标签,如果不指定,默认从 0 开始
其中index未指定时为RangeIndex[start,stop,end)对象
dtype:数据类型
copy:拷贝数据,默认为 False
4. loc函数
使用格式:对象.loc[行索引]
可以使用 loc函数获得某行的数据,获得是Series对象的数据。


















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











