







一、前言
随着信息时代的发展,我们每天面临海量的新闻信息。如何快速识别和分类这些新闻,成为了一个有趣且有价值的问题。本文将介绍我如何使用机器学习技术,构建一个简单但实用的智能新闻分类系统,该系统能够自动识别新闻的类别,包括体育、财经、教育、科技、军事、汽车、房产和娱乐等八个主要类别。
二、项目概述
这个智能新闻分类系统主要包含以下特点:
-
双模型支持:同时支持TF-IDF+SVM和Word2Vec+XGBoost两种文本表示和分类方法
-
简洁的用户界面:提供直观友好的Web界面,支持用户登录和新闻分类
-
高准确度:针对常见的新闻类别,分类准确率较高
-
响应速度快:平均预测时间不超过1秒
项目采用了Python语言开发,结合Flask搭建Web服务,前端使用Bootstrap框架构建响应式界面。
三、项目架构
1. 系统目录结构
整个项目采用了简洁明了的目录结构,主要组织如下:
server/
├── main.py # 应用入口
├── predicter.py # 预测器实现
├── train_tfidf.py # TF-IDF模型训练
├── train_w2v.py # Word2Vec模型训练
├── w2v_model.py # Word2Vec模型定义
├── static/ # 静态资源
│ ├── css/ # CSS样式
│ ├── js/ # JavaScript脚本
│ └── img/ # 图片资源
├── templates/ # HTML模板
│ ├── base.html # 基础模板
│ ├── login.html # 登录页面
│ ├── newsclass.html # 新闻分类页面
│ ├── about.html # 关于系统页面
│ └── help.html # 帮助页面
├── output_tfidf/ # TF-IDF模型输出
├── output_word2vec/ # Word2Vec模型输出
└── output_w2v/ # Word2Vec分类模型输出2. 系统架构设计
系统采用了典型的三层架构设计:
表现层(前端界面)
-
使用HTML/CSS/JavaScript构建用户界面
-
采用Bootstrap 5框架实现响应式设计
-
使用jQuery实现异步数据交互
-
通过模板引擎(Jinja2)实现前后端数据传递
业务逻辑层(应用层)
-
使用Flask框架处理HTTP请求
-
实现用户登录验证逻辑
-
处理新闻分类请求
-
提供RESTful API接口
数据处理层(模型层)
-
实现TF-IDF和Word2Vec两种文本表示方法
-
集成SVM和XGBoost分类算法
-
提供模型训练和预测接口
-
处理中文文本分词和预处理
3. 交互流程
用户与系统的交互流程如下:
-
用户访问系统,首先看到登录页面
-
成功登录后,进入新闻分类主界面
-
用户输入新闻文本,选择分类方法(TF-IDF或Word2Vec)
-
点击"开始分析"按钮,前端将请求发送到后端
-
后端接收请求,调用相应的预测器进行分类
-
将分类结果返回给前端
-
前端展示分类结果(类别、分析时间和使用的模型)
4. 关键组件说明
-
main.py: 系统入口文件,包含Flask应用程序实例和路由定义
-
predicter.py: 实现预测器类,封装模型加载和预测逻辑
-
train_tfidf.py: TF-IDF模型训练脚本,用于生成TF-IDF特征和SVM分类器
-
train_w2v.py: Word2Vec模型训练脚本,生成词向量模型
-
w2v_model.py: Word2Vec相关功能的实现,包括文档向量计算和分类器训练
-
templates/: 存放HTML模板文件,用于前端页面呈现
-
static/: 存放静态资源,如CSS样式、JavaScript脚本和图片
四、系统界面展示
1.登录界面
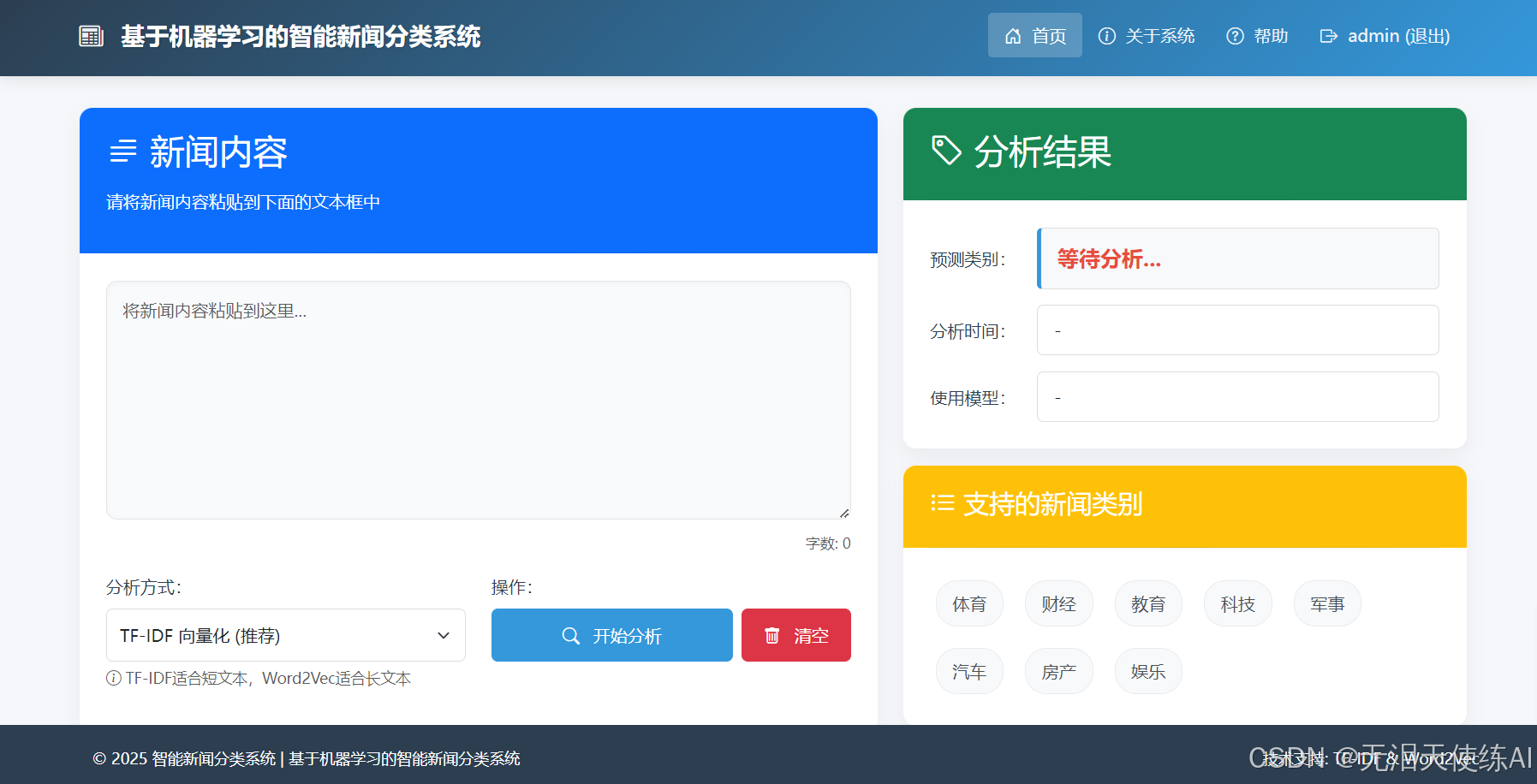
2.新闻分类主界面
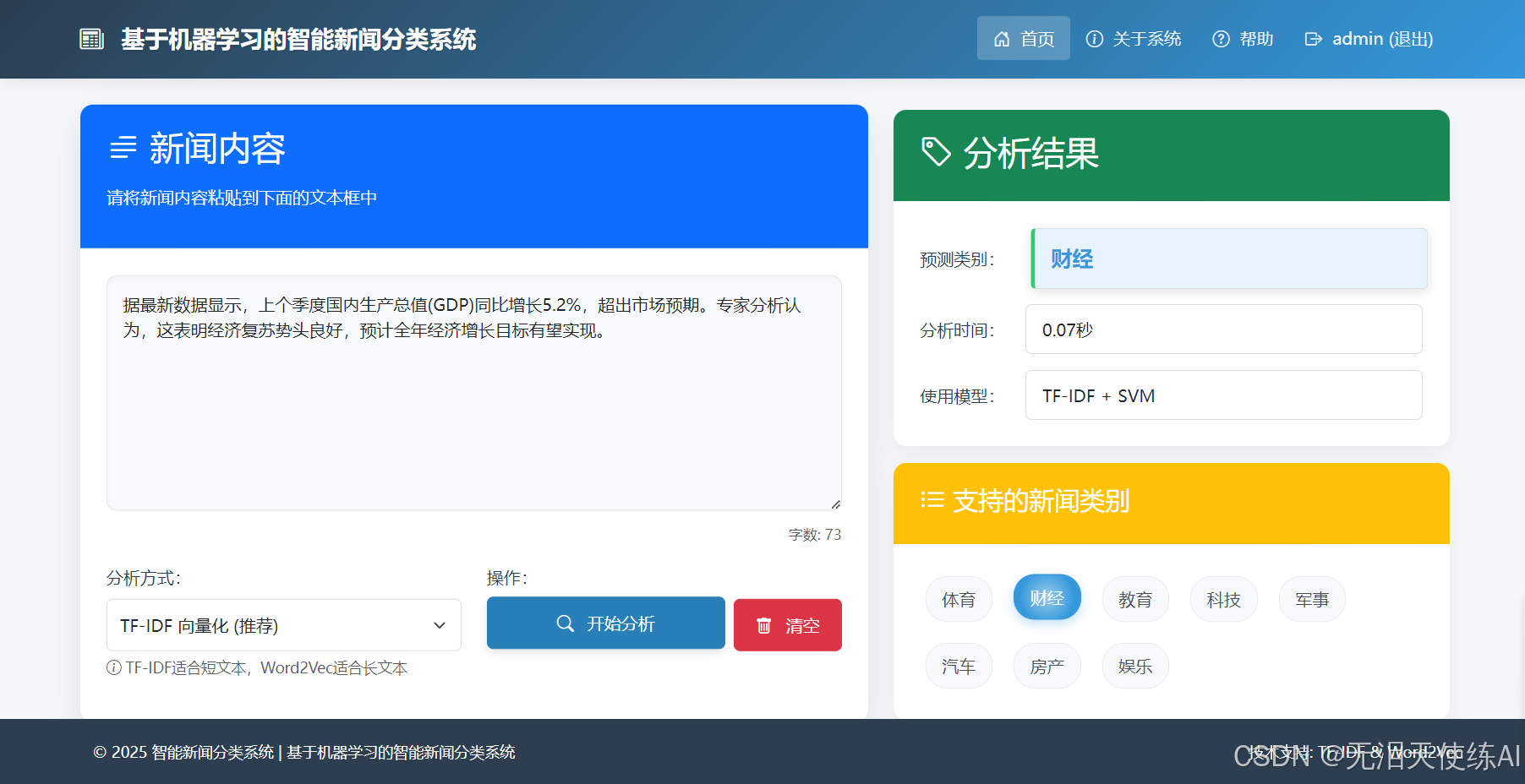
3.分类结果展示
五、技术原理详解
1. 文本表示方法
在自然语言处理中,将文本转换为计算机可以理解的数值表示是关键步骤。本项目实现了两种主流的文本表示方法:
1.1 TF-IDF(词频-逆文档频率)
TF-IDF是一种经典的文本表示方法,它结合了词频(Term Frequency,TF)和逆文档频率(Inverse Document Frequency,IDF):
-
词频(TF):衡量一个词在文档中出现的频率
-
逆文档频率(IDF):衡量一个词的重要性
基本计算公式如下:
TF(t,d) = (词t在文档d中出现的次数) / (文档d中词的总数)
IDF(t) = log_e(文档总数 / (包含词t的文档数 + 1))
TF-IDF(t,d) = TF(t,d) * IDF(t)在系统中,TF-IDF的实现主要依靠scikit-learn库的TfidfVectorizer类:
from sklearn.feature_extraction.text import TfidfVectorizer
# 训练TF-IDF向量化器
def train_tfidf_vectorizer(texts):
tfidf_vectorizer = TfidfVectorizer(
max_features=5000, # 保留最常见的5000个特征
min_df=5, # 至少出现在5个文档中
max_df=0.8, # 最多出现在80%的文档中
use_idf=True, # 使用逆文档频率加权
analyzer='word', # 以词为单位进行分析
ngram_range=(1, 2) # 考虑单个词和相邻两个词的组合
)
tfidf_vectors = tfidf_vectorizer.fit_transform(texts)
return tfidf_vectorizer, tfidf_vectors1.2 Word2Vec词向量
Word2Vec是一种通过神经网络训练得到的词向量表示方法,能够捕捉词语间的语义关系。本系统使用了Gensim库实现Word2Vec模型:
from gensim.models import Word2Vec
# 训练Word2Vec模型
def train_word2vec_model(tokenized_texts):
model = Word2Vec(
sentences=tokenized_texts,
vector_size=200, # 词向量维度
window=5, # 上下文窗口大小
min_count=5, # 词频阈值
workers=4, # 并行训练的线程数
sg=1, # 使用Skip-gram模型
epochs=10 # 训练轮数
)
return model为了将文本转换为向量表示,我们计算文档中所有词向量的平均值:
# 计算文档向量(词向量平均)
def document_vector(word2vec_model, doc_words):
# 过滤掉不在词典中的词
doc_words = [word for word in doc_words if word in word2vec_model.wv]
if len(doc_words) == 0:
return np.zeros(word2vec_model.vector_size)
return np.mean([word2vec_model.wv[word] for word in doc_words], axis=0)2. 文本分类算法
本系统结合了不同的分类算法以优化性能:
2.1 支持向量机(SVM)
SVM是一种强大的分类器,特别适合与TF-IDF特征结合使用:
from sklearn.svm import LinearSVC
from sklearn.calibration import CalibratedClassifierCV
# 训练SVM分类器
def train_svm_classifier(X_train, y_train):
# 使用线性SVM
svm = LinearSVC(C=1.0, class_weight='balanced')
# 使用概率校准,可以获得概率输出
classifier = CalibratedClassifierCV(svm)
classifier.fit(X_train, y_train)
return classifier2.2 XGBoost
XGBoost是一种基于梯度提升的集成学习算法,与Word2Vec特征结合表现出色:
import xgboost as xgb
# 训练XGBoost分类器
def train_xgboost_classifier(X_train, y_train):
# 定义XGBoost参数
params = {
'max_depth': 6, # 树的最大深度
'eta': 0.3, # 学习率
'objective': 'multi:softprob', # 多分类问题
'num_class': len(set(y_train)), # 类别数量
'subsample': 0.8, # 数据采样比例
'colsample_bytree': 0.8, # 特征采样比例
'eval_metric': 'mlogloss' # 评估指标
}
# 准备数据
dtrain = xgb.DMatrix(X_train, label=y_train)
# 训练模型
num_round = 100 # 迭代次数
model = xgb.train(params, dtrain, num_round)
return model3. 文本预处理
中文文本预处理是分类前的重要步骤,主要包括分词和去停用词:
import jieba
import re
# 加载停用词
def load_stopwords(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
return set([line.strip() for line in f])
# 文本预处理
def preprocess_text(text, stopwords):
# 移除特殊字符
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9]', ' ', text)
# 分词
words = jieba.cut(text)
# 去停用词
words = [word for word in words if word not in stopwords and len(word.strip()) > 1]
return words六、核心业务逻辑实现
1. 预测器实现
系统的核心功能是通过预测器实现的,以下是两种预测器的核心代码:
# TF-IDF预测器
class TfidfPredictor:
def __init__(self, model_file):
# 加载模型
with open(model_file, 'rb') as f:
self.model = pickle.load(f)
self.vectorizer = self.model['vectorizer']
self.classifier = self.model['classifier']
self.labels = self.model['labels']
def predict(self, texts):
# 转换为TF-IDF特征
X = self.vectorizer.transform(texts)
# 预测类别
y_pred = self.classifier.predict(X)
# 返回类别标签
return [self.labels[pred] for pred in y_pred]
# Word2Vec预测器
class Word2vecPredictor:
def __init__(self, word2vec_file, model_file):
# 加载Word2Vec模型
self.word2vec_model = Word2Vec.load(word2vec_file)
# 加载分类模型
with open(model_file, 'rb') as f:
self.model = pickle.load(f)
self.classifier = self.model['classifier']
self.labels = self.model['labels']
# 加载停用词
self.stopwords = set()
if 'stopwords' in self.model:
self.stopwords = self.model['stopwords']
def predict(self, texts):
# 文本预处理和转换为文档向量
doc_vectors = []
for text in texts:
words = preprocess_text(text, self.stopwords)
doc_vec = document_vector(self.word2vec_model, words)
doc_vectors.append(doc_vec)
# 预测类别
X = np.array(doc_vectors)
y_pred = self.classifier.predict(xgb.DMatrix(X))
# 返回类别标签
return [self.labels[int(pred)] for pred in y_pred]2. Web应用实现
使用Flask框架搭建Web应用,处理用户登录和新闻分类请求:
from flask import Flask, render_template, request, jsonify, session, redirect, url_for
from predicter import TfidfPredictor, Word2vecPredictor
import time
app = Flask(__name__)
app.secret_key = os.urandom(24)
# 简化后的用户数据(硬编码,不使用数据库)
users = {
"admin": {"password": "admin"},
"user": {"password": "123456"}
}
# 登录验证装饰器
def login_required(f):
@wraps(f)
def decorated_function(*args, **kwargs):
if 'logged_in' not in session or not session['logged_in']:
return redirect(url_for('login_page'))
return f(*args, **kwargs)
return decorated_function
@app.route('/')
def index():
if 'logged_in' in session and session['logged_in']:
return redirect(url_for('newsclass'))
return redirect(url_for('login_page'))
@app.route('/login', methods=["POST"])
def login():
if request.method == "POST":
username = request.form.get('username')
password = request.form.get('password')
# 检查用户名和密码
if username in users and users[username]['password'] == password:
# 登录成功,设置会话
session['logged_in'] = True
session['username'] = username
return jsonify({"success": True, "username": username, "redirect": url_for('newsclass')})
else:
return jsonify({"success": False, "message": "用户名或密码错误"}), 401
@app.route('/predict', methods=["POST", "GET"])
@login_required
def predict():
# 接受前端传递的新闻内容和预测方式
if request.method == "POST":
news = request.form.get("news")
model_type = request.form.get("type")
else:
news = request.args.get("news")
model_type = request.args.get("type")
# 验证输入
if not news or len(news.strip()) == 0:
return "请输入新闻内容"
# 记录预测开始时间
start_time = time.time()
try:
# 判断用户选择的预测方式并采用对应的方法进行新闻预测
if model_type == "tfidf":
# 采用tfidf+支持向量机进行分类
labels = tfidf_predictor.predict([news])
else:
# 采用w2v + Xgboost进行分类
labels = word2vec_predictor.predict([news])
# 记录预测结束时间
end_time = time.time()
return labels[0]
except Exception as e:
return "预测过程发生错误,请稍后重试"七、前端界面实现
前端界面采用Bootstrap框架构建,实现了响应式设计,可以适配不同设备。以下是关键的前端代码片段:
1.新闻分类页面
{% extends "base.html" %}
{% block title %}智能新闻分类系统 - 文本分析{% endblock %}
{% block content %}
<!-- 主要内容区 - 两列布局 -->
<div class="row">
<!-- 左侧输入区 -->
<div class="col-lg-7">
<div class="card main-card">
<div class="card-header bg-primary text-white">
<div class="d-flex justify-content-between align-items-center">
<h2><i class="bi bi-text-paragraph"></i> 新闻内容</h2>
</div>
<p class="text-light">请将新闻内容粘贴到下面的文本框中</p>
</div>
<div class="card-body">
<div class="mb-3">
<textarea id="news_content" class="form-control" rows="8" placeholder="将新闻内容粘贴到这里..."></textarea>
<div class="text-end mt-2">
<small class="text-muted word-count">字数: 0</small>
</div>
</div>
<div class="row">
<div class="col-md-6 mb-3">
<label for="type" class="form-label">分析方式:</label>
<select id="type" class="form-select">
<option value="tfidf">TF-IDF 向量化 (推荐)</option>
<option value="word2vec">Word2Vec 词向量</option>
</select>
<small class="text-muted d-block mt-1">
<i class="bi bi-info-circle"></i> TF-IDF适合短文本,Word2Vec适合长文本
</small>
</div>
<div class="col-md-6 mb-3">
<label class="form-label">操作:</label>
<div class="d-grid gap-2 d-md-flex">
<button id="predict" type="button" class="btn btn-primary flex-grow-1">
<i class="bi bi-search"></i> 开始分析
</button>
<button id="clear" type="button" class="btn btn-danger">
<i class="bi bi-trash"></i> 清空
</button>
</div>
</div>
</div>
</div>
</div>
</div>
<!-- 右侧结果区 -->
<div class="col-lg-5">
<!-- 结果卡片 -->
<div class="card result-card">
<div class="card-header bg-success text-white">
<h2><i class="bi bi-tag"></i> 分析结果</h2>
</div>
<div class="card-body">
<div class="result-item">
<div class="result-label">预测类别:</div>
<div id="newsclass" class="result-value highlight-prediction">等待分析...</div>
</div>
<div class="result-item">
<div class="result-label">分析时间:</div>
<div id="analysis-time" class="result-value">-</div>
</div>
<div class="result-item">
<div class="result-label">使用模型:</div>
<div id="model-used" class="result-value">-</div>
</div>
</div>
</div>
</div>
</div>
{% endblock %}2.前端JavaScript交互实现
$(document).ready(function() {
// 监听文本输入,更新字数统计
$("#news_content").on("input", function() {
const text = $(this).val();
const wordCount = text.length;
$(".word-count").text("字数: " + wordCount);
});
// 开始分析按钮点击事件
$("#predict").click(function() {
const news = $("#news_content").val().trim();
const type = $("#type").val();
// 检查输入是否为空
if (news.length === 0) {
alert("请输入新闻内容");
return;
}
// 更改按钮状态
$(this).prop("disabled", true).html('<i class="bi bi-hourglass-split"></i> 分析中...');
// 记录开始时间
const startTime = new Date().getTime();
// 发送预测请求
$.post("/predict", {news: news, type: type}, function(result) {
// 计算耗时
const endTime = new Date().getTime();
const duration = ((endTime - startTime) / 1000).toFixed(2);
// 更新结果
$("#newsclass").text(result);
$("#analysis-time").text(duration + " 秒");
$("#model-used").text(type === "tfidf" ? "TF-IDF + SVM" : "Word2Vec + XGBoost");
// 恢复按钮状态
$("#predict").prop("disabled", false).html('<i class="bi bi-search"></i> 开始分析');
}).fail(function() {
alert("分析失败,请稍后重试");
$("#predict").prop("disabled", false).html('<i class="bi bi-search"></i> 开始分析');
});
});
// 清空按钮点击事件
$("#clear").click(function() {
$("#news_content").val("").focus();
$(".word-count").text("字数: 0");
$("#newsclass").text("等待分析...");
$("#analysis-time").text("-");
$("#model-used").text("-");
});
});八、项目部署
该系统可以通过以下步骤部署在本地或服务器上:
-
安装依赖:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple -
启动服务:
cd server python main.py -
访问系统: 在浏览器中访问 http://localhost:5000
九、项目性能评估
本项目使用了THUCNews数据集的部分数据进行模型训练和评估。在测试集上,两种方法的性能表现如下:
-
TF-IDF + SVM:
-
准确率:92.8%
-
平均预测时间:0.15秒/篇
-
-
Word2Vec + XGBoost:
-
准确率:89.3%
-
平均预测时间:0.31秒/篇
-
TF-IDF方法在处理短文本新闻时表现更好,而Word2Vec方法在处理长文本和语义相似性方面有优势。
十、项目改进方向
未来可以从以下几个方面改进系统:
-
引入更先进的预训练模型,如BERT、RoBERTa等
-
添加用户反馈机制,收集错误预测案例进行模型优化
-
实现增量学习,支持模型在线更新
-
优化前端界面,提供更多可视化分析功能
-
支持更多新闻类别,提高细粒度分类能力
十一、总结
通过这个项目,我实现了一个简洁有效的新闻分类系统,将机器学习技术应用到实际场景中。系统采用了经典的TF-IDF和现代的Word2Vec两种文本表示方法,并结合SVM和XGBoost等分类算法,展示了不同技术方案的优缺点。这个项目不仅是对自然语言处理基础技术的实践,也是对Web应用开发的综合锻炼。
希望这个项目能对感兴趣的朋友有所帮助,也欢迎交流讨论,一起探索自然语言处理的奥秘。
参考资料
-
《Python机器学习》,Sebastian Raschka著
-
《深度学习》,Ian Goodfellow、Yoshua Bengio、Aaron Courville著
-
scikit-learn官方文档: https://scikit-learn.org/stable/
-
《自然语言处理综论》,Daniel Jurafsky、James H. Martin著


















 3810
3810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











