






常用算法
雪花算法的实现原理


用来实现全局唯一的业务主键
解决分库分表之后主键id的唯一性的问题(UUID,Redis的原子递增,数据库全局表的自增id)(只需要满足有序递增,高性能,高可用,带时间戳)
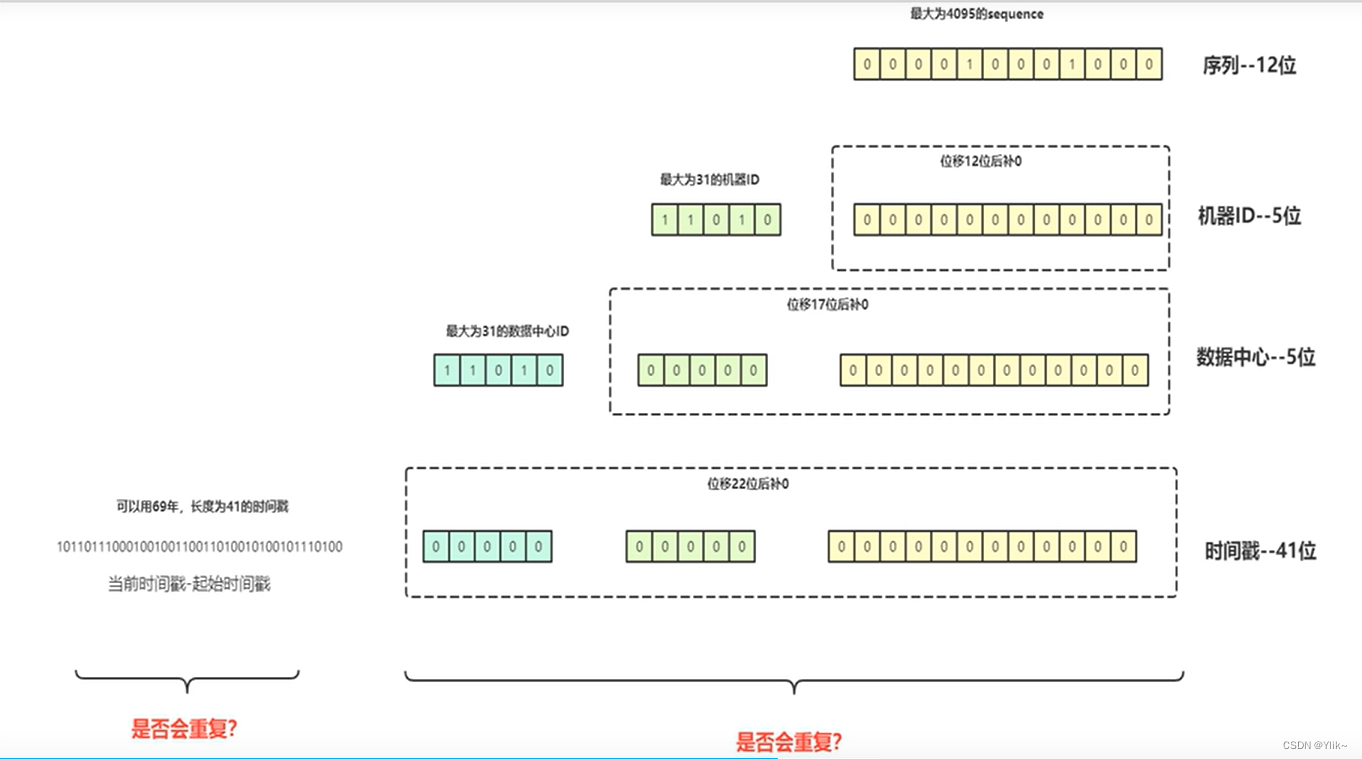
他是一个通过64个bit位组成的long类型的数字
四部分:
1、用一个bit位来表示一个符号位一般情况下为0(因为id不会是负数).
2、用41个bit位来表示一个时间戳,这个时间戳是系统时间的毫秒数
3、用10个bit来记录工作机器的id,2的10次方,1024台机器
这样就可以保证在多个服务器上生成id的唯一性,如果存在跨机房部署的情况下,还可以把这10个bit位拆分成两个5bit,前5bit可以表示机房id,后5bit表示机器的id
4、用12个bit来表示一个递增的序列用来实现同毫秒内产生不同id的能力,2的12次方4096,
package com.systop.linked_list;
import java.util.Set;
import java.util.TreeSet;
/**
* @Author Ysl
* @Date 2023/7/18
* @name SuanFa
**/
public class SnowFlakeGenerateIdWorker {
/**
* 开始时间截
*/
private final long twepoch = 1420041600000L;
/**
* 机器id所占的位数
*/
private final long workerIdBits = 5L;
/**
* 数据标识id所占的位数
*/
private final long datacenterIdBits = 5L;
/**
* 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)
*/
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/**
* 支持的最大数据标识id,结果是31
*/
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/**
* 序列在id中占的位数
*/
private final long sequenceBits = 12L;//序列号占用的位数,左位移向左补12个0
/**
* 机器ID向左移12位
*/
private final long workerIdShift = sequenceBits;
/**
* 数据标识id向左移17位(12+5)
*/
private final long datacenterIdShift = sequenceBits + workerIdBits;
/**
* 时间截向左移22位(5+5+12)
*/
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/**
* 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)
* -1L
* 1111111111111111111111111111111111111111111111111111111111111111。
* 注意,由于-1L是一个64位的长整型数,因此在二进制表示中有63个1。
* <<左位移
*/
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/**
* 工作机器ID(0~31)
*/
private long workerId;
/**
* 数据中心ID(0~31)
*/
private long datacenterId;
/**
* 毫秒内序列(0~4095)
*/
private long sequence = 0L;
/**
* 上次生成ID的时间截
*/
private long lastTimestamp = -1L;
/**
* 构造函数
*
* @param workerId 工作ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public SnowFlakeGenerateIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 获得下一个ID (该方法是线程安全的)
*
* @return long
*/
public synchronized long nextId() {
long timestamp = timeGen();//拿到当前的时间戳
timestamp = generateId(timestamp);
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
private long generateId(long timestamp) {
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
//相同毫秒内,序列号自增
//0111111111
//1000000000
//0000000000 = 0
sequence = (sequence + 1) & sequenceMask;//与运算
//毫秒内序列溢出
if (sequence == 0)
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
} else//时间戳改变,毫秒内序列重置
{
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
return timestamp;
}
/**
* 获得下一个ID (string)
**/
public synchronized String generateNextId() {
long timestamp = timeGen();
timestamp = generateId(timestamp);
//移位并通过或运算拼到一起组成64位的ID
return String.valueOf(((timestamp - twepoch) << timestampLeftShift)//时间戳部分
| (datacenterId << datacenterIdShift)//数据中心部分(机房序列号)
| (workerId << workerIdShift)//机器标识部分
| sequence);//序列号部分 0-4095
}
/**
* 阻塞到下一个毫秒,直到获得新的时间戳
*
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以毫秒为单位的当前时间
*
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowFlakeGenerateIdWorker snowFlakeGenerateIdWorker =
new SnowFlakeGenerateIdWorker(0L, 0L);
//String类型id
String s = snowFlakeGenerateIdWorker.generateNextId();
System.out.println(s);
//long类型id
long l = snowFlakeGenerateIdWorker.nextId();
System.out.println(l);
// 验证生成1000万个id需要多久
long startTime = System.currentTimeMillis();
// 生成1000万个id,塞入set,测试是否有重复id
Set<Long> set = new TreeSet<>();
for (int i = 0; i < 10000000; i++) {
set.add(snowFlakeGenerateIdWorker.nextId());
}
System.out.println(set.size());
System.out.println("耗时" + (System.currentTimeMillis() - startTime) + "毫秒");
}
}
线性搜索算法(Linear Search),
也称为顺序搜索,是一种简单直观的搜索算法。它逐个检查数据集中的元素,直到找到目标元素或遍历完整个数据集。
以下是线性搜索算法的基本步骤:
- 从数据集的第一个元素开始,依次比较每个元素与目标值是否相等。
- 如果找到了匹配的元素,则返回该元素的索引或其他相关信息。
- 如果遍历完整个数据集仍未找到匹配的元素,则表示目标值不存在于数据集中。
public class LinearSearch {
public static int linearSearch(int[] array, int target) {
for (int i = 0; i < array.length; i++) {
if (array[i] == target) {
return i; // 返回匹配元素的索引
}
}
return -1; // 表示未找到匹配元素
}
public static void main(String[] args) {
int[] array = {5, 2, 9, 7, 3};
int target = 7;
int index = linearSearch(array, target);
if (index != -1) {
System.out.println("目标值 " + target + " 在索引 " + index + " 处找到了。");
} else {
System.out.println("目标值 " + target + " 未找到。");
}
}
}
二分查找算法
如果正常遍历查找的话,时间复杂度为O(N)
针对一组单调(增,减)的数列,时间复杂度为O(logN)
/**
* @Author Ysl
* @Date 2023/7/18
* @name SuanFa
**/
public class binarySearchCode {
public static int binarySearch(int[] srcArray, int des ){
//定义初始最小,最大索引
int left = 0;
int right = srcArray.length-1;
//确保不会出现重复查找,越界
while(left <= right){
//计算出中间值
int mid = (left+right)/2;
if (des == srcArray[mid]){
return mid;
} else if (des < srcArray[mid]) {
right = right - 1;
}else {
left = left + 1;
}
}
//如果没有则返回-1
return -1;
}
public static void main(String[] args) {
int[] srcArray = {1,2,3,4,6,9};
int des = 6;
int result = binarySearch(srcArray, des);
if (result == -1){
System.out.println("该数字不存在");
}else {
System.out.println("该数字为:"+srcArray[result]);
System.out.println("该数字的下标为:"+result);
}
}
}
哈希查找
public static void main(String[] args) {
// 定义数组和目标元素
int[] array = {5, 12, 8, 3, 9, 6};
int target = 9;
// 调用哈希查找算法进行查找
int index = hashSearch(array, target);
// 判断查找结果并输出对应信息
if (index != -1) {
System.out.println("目标元素 " + target + " 在数组中的索引为:" + index);
} else {
System.out.println("目标元素 " + target + " 不在数组中");
}
}
private static int hashSearch(int[] array, int target) {
// 构建哈希表
Map<Integer, Integer> map = new HashMap<>();
// 遍历数组,将数组元素作为键,数组索引作为值存入哈希表
for (int i = 0; i < array.length; i++) {
map.put(array[i], i);
}
// 查找目标元素
if (map.containsKey(target)) {
return map.get(target); // 返回目标元素在数组中的索引
} else {
return -1; // 目标元素不在数组中,返回-1
}
}
冒泡排序算法
/**
* @Author Ysl
* @Date 2023/7/18
* @name SuanFa
* 谁大谁往后交换
**/
public class BubbleSort {
public static void bubbleSort(int[] arr) {
int n = arr.length;
boolean swapped; // 用于检查是否发生了交换
//0 ~ n-1
//0 ~ n-2
//0 ~ n-3
for (int i = n-1; i >= 0; i--) {
swapped = false;
//0 ~ i 干事
//0 1 1 2 2 3 3 4 (i i-1)要不要换
for (int j = 1; j <= i; j++) {
if (arr[j-1] > arr[j]) {
// swap arr[j] and arr[j+1]
int temp = arr[j-1];
arr[j-1] = arr[j];
arr[j] = temp;
swapped = true;
}
}
// 如果在这次遍历中没有发生交换,那么序列已经排序完成
if (!swapped) {
break;
}
}
}
public static void printArray(int[] arr) {
int n = arr.length;
for (int i=0; i<n; ++i)
System.out.print(arr[i] + " ");
System.out.println();
}
public static void main(String[] args) {
int[] arr = {64, 34, 25, 12, 22, 11, 90};
System.out.println("排序前:");
printArray(arr);
bubbleSort(arr);
System.out.println("排序后:");
printArray(arr);
}
}
快速排序算法
/**
* @Author Ysl
* @Date 2023/7/18
* @name SuanFa
**/
public class QuickSort {
/*
比较v元素是否小于w元素
*/
private static boolean less(Comparable v, Comparable w) {
return v.compareTo(w) < 0;
}
/*
数组元素i和j交换位置
*/
private static void exch(Comparable[] a, int i, int j) {
Comparable t = a[i];
a[i] = a[j];
a[j] = t;
}
//对数组内的元素进行排序
public static void sort(Comparable[] a) {
int lo = 0;
int hi = a.length-1;
sort(a,lo,hi);
}
//对数组a中从索引lo到索引hi之间的元素进行排序
private static void sort(Comparable[] a, int lo, int hi) {
//安全性校验
if (hi<=lo){
return;
}
//需要对数组中lo索引到hi索引处的元素进行分组(左子组和右子组);
int partition = partition(a, lo, hi);//返回的是分组的分界值所在的索引,分界值位置变换后的索引
//让左子组有序
sort(a,lo,partition-1);
//让右子组有序
sort(a,partition+1,hi);
}
//对数组a中,从索引 lo到索引 hi之间的元素进行分组,并返回分组界限对应的索引
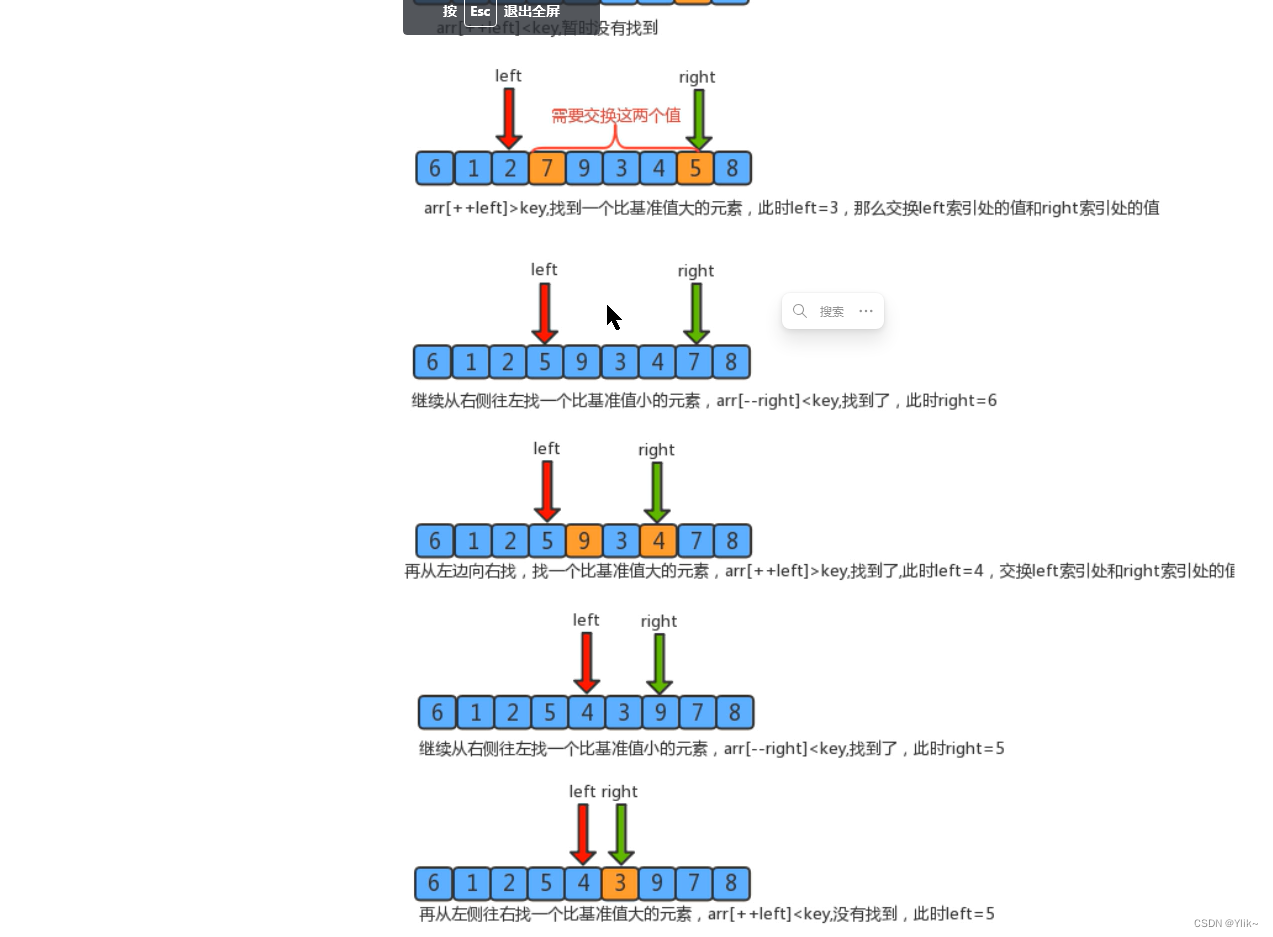
public static int partition(Comparable[] a, int lo, int hi) {
//确定分界值
Comparable key = a[lo];
//定义两个指针,分别指向待切分元素的最小索引处和最大索引处的下一个位置
int left=lo;
int right=hi+1;
//切分
while(true){
//先从右往左扫描,移动right指针,找到一个比分界值小的元素,停止
while(less(key,a[--right])){
if (right==lo){
break;
}
}
//再从左往右扫描,移动left指针,找到一个比分界值大的元素,停止
while(less(a[++left],key)){
if (left==hi){
break;
}
}
//判断 left>=right,如果是,则证明元素扫描完毕,结束循环,如果不是,则交换元素即可
if (left>=right){
break;
}else{
exch(a,left,right);
}
}
//交换分界值
exch(a,lo,right);
return right;
}
public static void main(String[] args) {
Integer[] a = {6,1,2,5,4,3,7,8,9};
QuickSort.sort(a);
System.out.println(Arrays.toString(a));
}
}
二叉树的深度遍历算法(递归序)

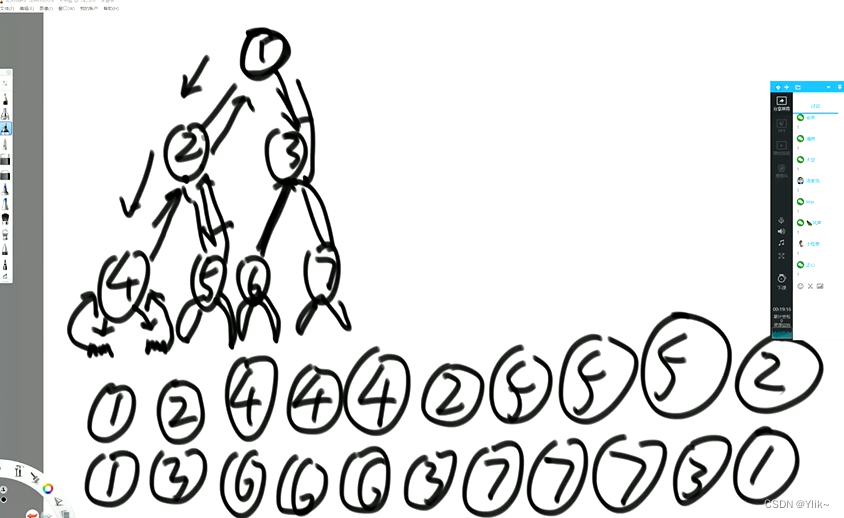

每个节点都会返回三次:
- 先序:头左右,第一次出现该节点打印
- 中序:左头右,第二次出现该节点打印
- 后序:左右头,第三次出现该节点打印
//递归法
public class Code01_PreInPosTraversal {
public static class Node {
public int value;
public Node left;
public Node right;
public Node(int data) {
this.value = data;
}
}
/**
* 处理head时,head会回到这个函数三次
*
* @param head
*/
public static void f(Node head){
if (head == null){
return;
}
//1前
f(head.left);
//2中
f(head.right);
//3后
}
//先序打印所有节点
public static void preOrderRecur(Node head) {
if (head == null) {
return;
}
System.out.print(head.value + " ");
preOrderRecur(head.left);
preOrderRecur(head.right);
}
// 中序
public static void inOrderRecur(Node head) {
if (head == null) {
return;
}
inOrderRecur(head.left);
System.out.print(head.value + " ");
inOrderRecur(head.right);
}
//后续
public static void posOrderRecur(Node head) {
if (head == null) {
return;
}
posOrderRecur(head.left);
posOrderRecur(head.right);
System.out.print(head.value + " ");
}
public static void main(String[] args) {
Node head = new Node(3);
head.left = new Node(4);
head.right = new Node(5);
head.left.left = new Node(7);
head.right.left = new Node(6);
// recursive
System.out.println("==============recursive==============");
System.out.print("pre-order前序: ");
preOrderRecur(head);
System.out.println();
System.out.print("in-order中序: ");
inOrderRecur(head);
System.out.println();
System.out.print("pos-order后续: ");
posOrderRecur(head);
System.out.println();
}
}
二叉树的广度(层次)遍历算法
按照从上到下,从左到右的顺序逐层访问二叉树节点的方法
用队列实现:根节点进入就弹出,先加左再加右,再打印
public static class Node {
public int value;
public Node left;
public Node right;
public Node(int data) {
this.value = data;
}
}
//层序遍历
public static void w(Node head){
if (head == null){
return;
}
Queue<Node> queue = new LinkedList<>();
queue.add(head);
//hash表记录层数和节点数
//当前层数,当前层的结点,那一层最多
while (!queue.isEmpty()){
Node cur = queue.poll();
//弹出节点时先知道它的层数,如果当前遍历到的结点所在的层和现在来到的想统计的层一样的话,结点数++
System.out.println(cur.value);
if (cur.left != null){
queue.add(cur.left);
}if (cur.right != null){
queue.add(cur.right);
}
}
}
//最大宽度
public static int getMaxWidth(Node head) {
if (head == null) {
return 0;
}
Queue<Node> queue = new LinkedList<>();
queue.add(head);
//key在哪一层value
HashMap<Node,Integer> levelMap = new HashMap<>();
levelMap.put(head,1);
int curLevel = 1;//当前在那一层统计3
int curLevelNodes = 0;//当前层curLevel宽度目前是多少
int max = 0;
while (!queue.isEmpty()){
Node cur = queue.poll();
int curNodeLevel = levelMap.get(cur);2
if (cur.left != null){
levelMap.put(cur.left,curNodeLevel+1);
queue.add(cur.left);
}
if (cur.right != null){
levelMap.put(cur.right,curNodeLevel+1);
queue.add(cur.right);
}
if (curNodeLevel == curLevel){
curLevelNodes++;
}else {
max = Math.max(max,curLevelNodes);
curLevel++;2
curLevelNodes=1;
}
}
max = Math.max(max,curLevelNodes);
return max;
}
## 第十五题:
>
>
>解题了解:[Java ArrayList | 菜鸟教程 (runoob.com)](https://www.runoob.com/java/java-arraylist.html)
```java
ArrayList<E> objectName =new ArrayList<>();// 初始化
objectName.add()//添加
objectName.get()//获取
objectName.set(2,"wiki")//修改
objectName.remove(0)//删除
objectName.size()//计算list中的元素数量
//遍历数组元素
for (int i = 0; i < objectName.size(); i++) {
System.out.println(objectName.get(i));
}
//排序:Collections 类也是一个非常有用的类,位于 java.util 包中,提供的 sort() 方法可以对字符或数字列表进行排序。
Collections.sort(objectName);
/**
ArrayList 方法
Java ArrayList 常用方法列表如下:
方法 描述
add() 将元素插入到指定位置的 arraylist 中
addAll() 添加集合中的所有元素到 arraylist 中
clear() 删除 arraylist 中的所有元素
clone() 复制一份 arraylist
contains() 判断元素是否在 arraylist
get() 通过索引值获取 arraylist 中的元素
indexOf() 返回 arraylist 中元素的索引值
removeAll() 删除存在于指定集合中的 arraylist 里的所有元素
remove() 删除 arraylist 里的单个元素
size() 返回 arraylist 里元素数量
isEmpty() 判断 arraylist 是否为空
subList() 截取部分 arraylist 的元素
set() 替换 arraylist 中指定索引的元素
sort() 对 arraylist 元素进行排序
toArray() 将 arraylist 转换为数组
toString() 将 arraylist 转换为字符串
ensureCapacity() 设置指定容量大小的 arraylist
lastIndexOf() 返回指定元素在 arraylist 中最后一次出现的位置
retainAll() 保留 arraylist 中在指定集合中也存在的那些元素
containsAll() 查看 arraylist 是否包含指定集合中的所有元素
trimToSize() 将 arraylist 中的容量调整为数组中的元素个数
removeRange() 删除 arraylist 中指定索引之间存在的元素
replaceAll() 将给定的操作内容替换掉数组中每一个元素
removeIf() 删除所有满足特定条件的 arraylist 元素
forEach() 遍历 arraylist 中每一个元素并执行特定操作
*/
/**
HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。
HashSet 允许有 null 值。
HashSet 是无序的,即不会记录插入的顺序。
HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的。 您必须在多线程访问时显式同步对 HashSet 的并发访问。
HashSet 实现了 Set 接口。
*/
//以下实例我们创建一个 HashSet 对象 sites,用于保存字符串元素:
HashSet<String> sites = new HashSet<String>();
//使用方法同上
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请
你返回所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组
public List<List<Integer>> threeSum(int[] nums) {
//数组排序
Arrays.sort(nums);
//创建一个HashSet
Set<List<Integer>> res = new HashSet<>();
//遍历循环
for (int i = 0; i < nums.length; i++) {
//从头
int l = i + 1;
//从尾
int r = nums.length - 1;
while (l < r) {
if (nums[i] + nums[l] + nums[r] == 0) {
res.add(Arrays.asList(nums[i], nums[l], nums[r]));
l++;
r--;
} else if (nums[i] + nums[l] + nums[r] < 0) {
//-4,-1,-1,0,1,2
l++;
} else if (nums[i] + nums[l] + nums[r] > 0) {
//-4,-1,-1,0,1,2
r--;
}
}
}
List<List<Integer>> ans = new ArrayList<>();
ans.addAll(res);
return ans;
}


















 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











