







 本文详细探讨了Linux操作系统中程序的虚拟地址空间,包括mm_struct结构体、数据代码与虚拟地址的关系,以及虚拟地址如何通过页表和MMU转化为物理地址。通过实例解释了写时拷贝原理,阐述了地址空间对于内存管理和进程隔离的重要性。
本文详细探讨了Linux操作系统中程序的虚拟地址空间,包括mm_struct结构体、数据代码与虚拟地址的关系,以及虚拟地址如何通过页表和MMU转化为物理地址。通过实例解释了写时拷贝原理,阐述了地址空间对于内存管理和进程隔离的重要性。
目录
虚拟地址的内部结构

这张图中可以看到内存地址中按从低地址到高地址排列的内存块,分别是代码区,字符常量区,数据区包括未初始化的和已初始化的,堆。而栈的地址是从高地址到低地址。
可以通过代码来验证一下(Linux环境下)
int g_unval;
int g_val=100;
int main()
{
const char* s="hello world";
printf("code addr:%p\n",main);//代码区
printf("string rdonly addr:%p\n",s);//(字符串)常量区
printf("uninit addr:%p\n",&g_unval);//未初始化数据区
printf("init addr:%p\n",&g_val);//初始化数据区
char* heap =(char*)malloc(10);
printf("heap addr:%p\n",heap);//堆
printf("stack addr_string:%p\n",&s);//栈--栈上的临时空间
printf("stack addr_heap:%p\n",&heap);
int a=10,b=20;
printf("stack addr_a:%p\n",&a);//验证栈区地址是由大到小
printf("stack addr_b:%p\n",&b);
return 0;
}[wjy@VM-24-9-centos 407test]$ ./mycode
code addr:0x40057d //代码区
string rdonly addr:0x400700 //字符常量区
uninit addr:0x601044 //未初始化数据区
init addr:0x60103c //初始化
heap addr:0x199a010 //堆
stack addr_string:0x7ffd05938bc8 //栈
stack addr_heap:0x7ffd05938bc0
stack addr_a:0x7ffd05938bbc
stack addr_b:0x7ffd05938bb8
那么C/C++的程序地址空间,是内存吗?
验证一下,写一个mycode.c的C语言程序。定义一个全局变量,这样父子进程用到这个值都会是这个值。当fork()创建子进程,结果为0就是子进程,如果不为0,fork()值为子进程的pid,那么就是父进程。当两个进程一样的时候,二者共用一份代码,一份数据。当子进程有改变的时候,就会发生写时拷贝。
[wjy@VM-24-9-centos 407test]$ cat mycode.c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
int g_val=100;
int main()
{
//数据是各自有一份(写时拷贝)
if(fork()==0)
{
//child
int cnt=5;
while(cnt)
{
printf("I am child,times:%d,g_val=%d,&g_val:%p\n",cnt,g_val,&g_val);
cnt--;
sleep(1);
if(cnt==3)//当cnt值为3改变g_val的数据
{
printf("############### child changed data ################\n");
g_val=200;
printf("############### child changed done ################\n");
}
}
exit(0);
}
else{
//parent
while(1)
{
printf("I am parent,g_val=%d,&g_val=%p\n",g_val,&g_val);
sleep(1);
}
}
return 0;
}
打印结果
[wjy@VM-24-9-centos 407test]$ ./mycode
I am parent,g_val=100,&g_val=0x601054
I am child,times:5,g_val=100,&g_val:0x601054
I am parent,g_val=100,&g_val=0x601054
I am child,times:4,g_val=100,&g_val:0x601054
I am parent,g_val=100,&g_val=0x601054
############### child changed data ################
############### child changed done ################
I am child,times:3,g_val=200,&g_val:0x601054
I am parent,g_val=100,&g_val=0x601054
I am child,times:2,g_val=200,&g_val:0x601054
I am parent,g_val=100,&g_val=0x601054
I am child,times:1,g_val=200,&g_val:0x601054
I am parent,g_val=100,&g_val=0x601054
I am parent,g_val=100,&g_val=0x601054
I am parent,g_val=100,&g_val=0x601054
当cnt的值到3的时候,g_val的值发生了改变,此后子进程的所有g_val值都是200,但是父子进程并不干涉,因为发生了写时拷贝。但是我们发现,虽然父子进程的值已经不一样了,但是他们的地址竟然是一样的。为什么地址没有变化呢?
虚拟地址
如果C/C++打印出来的地址是物理内存地址,这种现象是不可能存在的。所以这里我们使用的地址不是物理地址,而是虚拟地址。所以上面提到的C/C++程序地址空间,实际上就是进程虚拟地址空间。
进程地址空间作为操作系统的地址空间,它是非常大的,进程在获取地址空间的时候,每个地址空间都认为自己独占这份进程地址空间,并且进程地址空间也给进程画了个大饼,告诉他们只有此进程独占进程地址空间。然而并非如此,因为进程地址空间非常大,他们不可能独占,而是让进程先描述,它能够干什么,需要从进程地址空间中拿走多少空间。然后再去申请空间,这也就是先描述再组织。
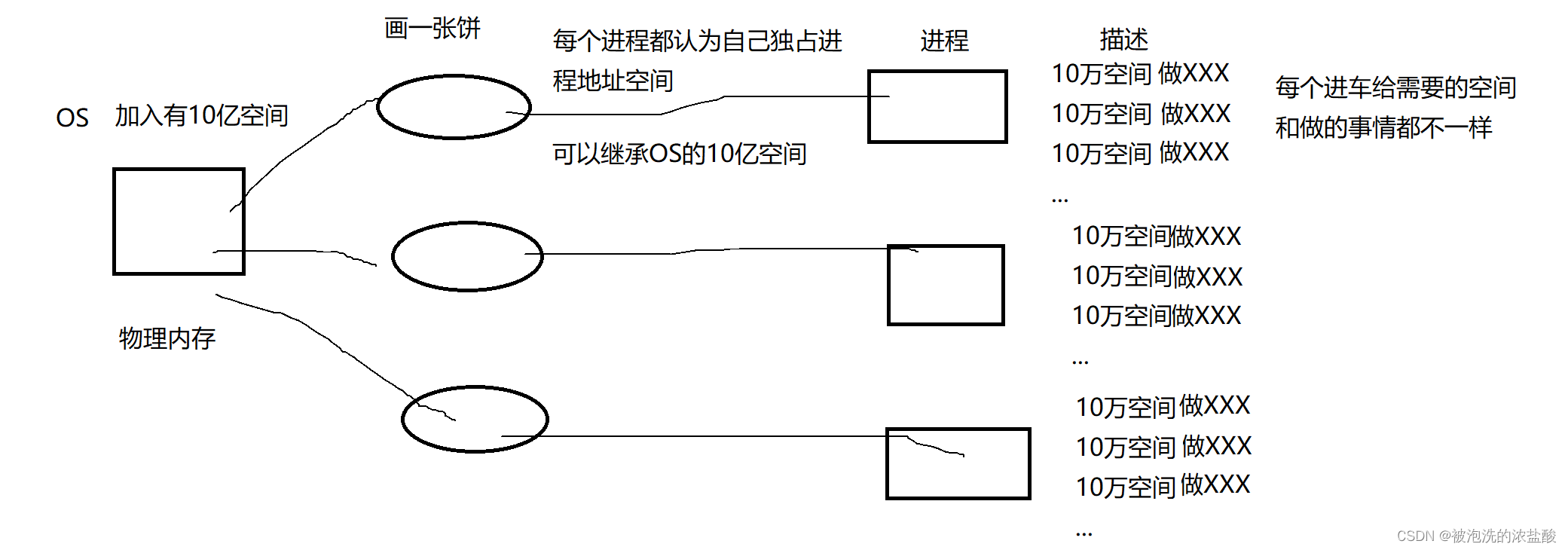
所以这里的先描述也是一个结构体,叫mm_struct,他是一个在内核中的数据结构类型,是一个具体进程的地址空间变量。这里包括了什么时候分配,如何分配等等。task_struct是描述进程信息的控制块,那么mm_struct就是描述进程分配地址空间信息的结构体。
但是还有一个疑问,会不会有这种情况,每个进程需要的空间大小和进程地址空间一样大?比如进程地址空间有10亿大小,进程需要10亿。这种情况是非常少的,几乎不存在。如果进程想要申请10亿,可能进程地址空间也不会给,申请会失败。
mm_struct虚拟地址结构体
地址空间本质是内核中一种数据类型。这个mm_struct可以看作很多区域的划分,里面划分了很多由start和end划分开来的数据。而这个mm_struct可以看作是操作系统的所有地址,因为每个进程都认为自己独占整个虚拟地址空间,在32位操作系统下,每个进程都认为地址空间的划分是按照4GB空间划分的,都是从0x00000000-0xFFFFFFFF。因为这些虚拟地址是连续的,所以也可以叫做线性地址。
struct mm_struct{
unsigned int code_start;
unsigned int code_end;
unsigned int init_data_start;
unsigned int init_data_end;
unsigned int uninit_data_start;
unsigned int uninit_data_end;
unsigned int heap_start;
unsigned int heap_end;
unsigned int stack_start;
unsigned int stack_end;
}数据代码和虚拟地址的结合
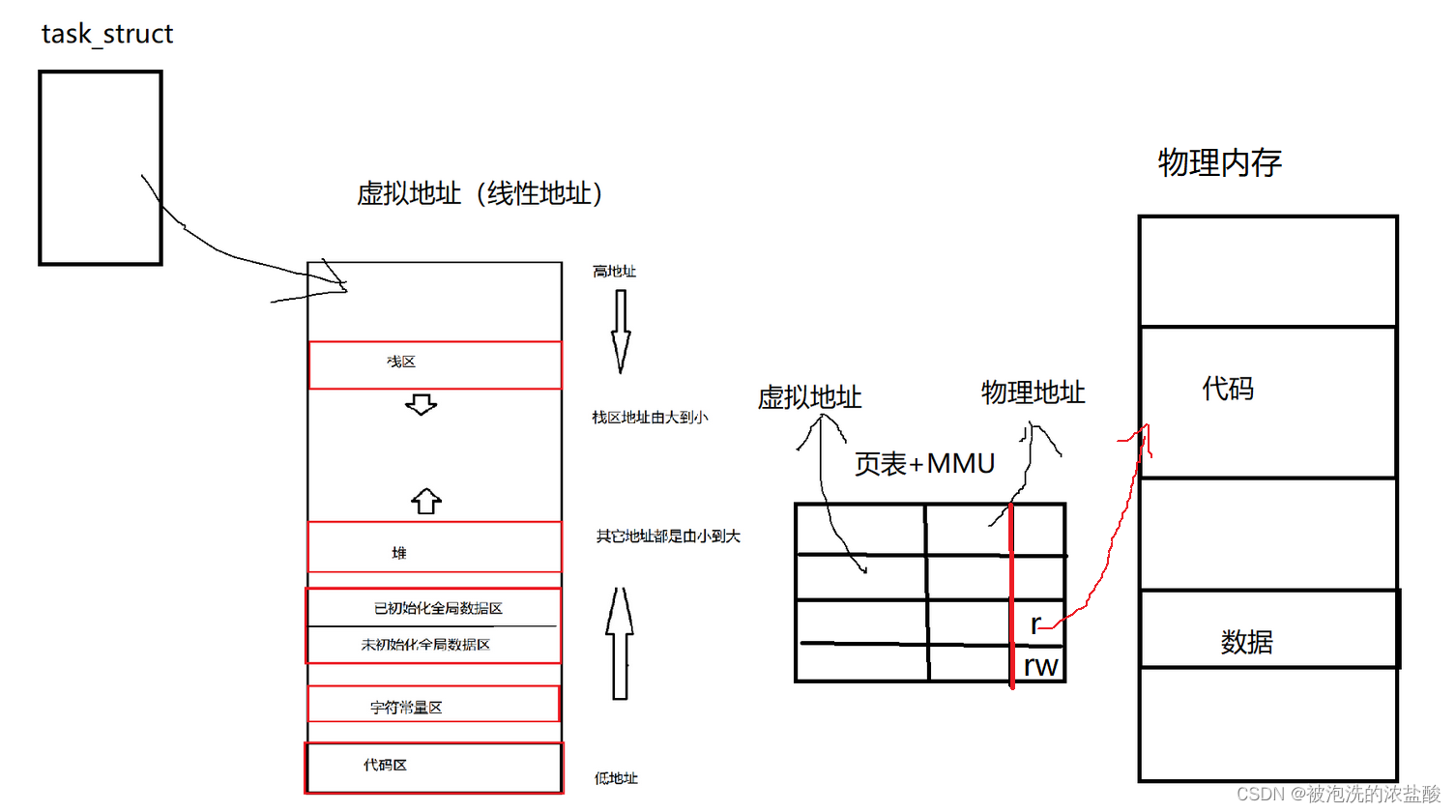
那么通过上面的虚拟内存将空间地址划分,我们知道了将数据和代码放在哪,但这都是理论阶段。就像你逛某宝,上面的界面图已经将商品划分好,你知道怎么购买,但是这个商品还没有到你的手上。所以代码数据和虚拟地址的结合也需要某种介质来完成。
这个介质就是页表+MMU,MMU是一个硬件,是用来查页表的,一般MMU是集成在CPU当中的。页表是由操作系统维护进程的一张表,这个表可以看作左边是虚拟地址,右边是物理地址。
页表的作用:将虚拟地址转化为物理地址。这个页表就是一张映射表。那么mm_struct中的各个区域,代码区,字符常量区,数据区,栈区,堆区等等这些都是通过页表,先在页表中寻找虚拟地址,然后再根据页表中的映射找到对应的物理地址,从而找到对应的代码和数据。
那么为什么一定要加这个虚拟地址和页表呢?进程直接找物理地址不好吗?
这是因为加上虚拟地址和页表方便管理,并且如果直接访问物理地址可能会有一些非法操作和错误,当进程直接访问物理地址,我们通过指针访问,进程A的数据,但是如果指针知错了直接指向进程B的地址,那么本来要修改A的数据,直接把B的地址修改了,造成了非法访问。
就像我们有了压岁钱,但是需要交给妈妈保管,如果自己保管压岁钱,出去话可能被骗了,妈妈都不知道。所以进程也需要通过虚拟地址,让页表来保存,实际上,这个页表也就是操作系统的代名词,这个进程的虚拟地址还是交给操作系统管理的。
举个例子,这里有一个char* 类型的字符串,char* str="hello world";但是这里的str指向的内容不能随意被改变,*str='H'。这是因为本质上OS给字符常量区的权限只有读操作r,在页表中,硬件对应的页表指向的字符常量区只有r权限,如果进行了写w操作,那么系统直接将程序崩溃。
为什么要有地址空间?
1.通过添加一层软件层,完成有效的对进程操作内存进行风险管理(权限管理),本质目的是为了保护物理内存及各个进程的数据安全!(通过操作系统管理)
2.将内存申请和内存使用的概念在时间上划分清楚,通过虚拟地址空间,来屏蔽底层申请内存过程,达到进程读写内存和OS内存管理操作,进行软件上面的分离。(物理空间滞后性开辟--写实拷贝是经典的之后开辟空间)
当我们申请1000字节,我们不一定能立马使用全部字节,在OS角度,如果空间立马给你,那么整个申请的空间,,本来可以给别人立马用的,但是现在被你闲置着。这就意味着,虽然你有了空间,但是有的空间从来就没有被读写。所以操作系统会基于缺页中断进行物理内存,也就是当这部分闲置的空间没有立马被使用,操作系统不会先给你,如果你要使用的时候,操作系统再给你。但是你并不知道操作系统其实在这中间,还把内存给别人使用了。
那么当A进程要申请空间时候,物理内存已经满了,这时候操作系统还是可以申请到内存的,这就是内存管理算法。当磁盘满的时候,会将别的没有使用空间的进程置换到磁盘中,将空间开辟出来,申请给A进程使用。这时候A进程并不知道操作系统给你的空间是从哪里来的,是物理内存剩余申请过来的?还是物理内存已经满了,将别的进程与磁盘置换申请来的?这就是地址空间从中起到的重要作用。
3.站在CPU和应用层的角度,进程统一可以统一使用4GB空间,而且每个空间区域的相对应位置,是比较明确的。(CPU统一看待同一个区域的进程)
如果没有页表这样的地址空间,用main函数来说,每个程序都有main函数,CPU得每次都要对应各个main函数的物理地址空间,而且物理内存位置不能改变,改变的话CPU每次都要重新找,非常麻烦。即使位置没有改变,这样找的话也比较凌乱,因为还有其它区域的代码。所以操作系统建立页表,让CPU每次找main函数都从一个地址去找,这个地址就是所有main函数的地址,然后页表建立映射,找到各个进程的main函数,这样对CPU来说非常香,也很容易管理,main函数的物理内存也可以随便改变。
下图并不是一个虚拟地址能找两个物理地址,因为一个CPU只能运行一个进程,但是他们是通过时间片,交叉进行运作的。而这些物理地址都是可以通过同一个虚拟地址找到,从而达到CPU只访问一个地址就能找到main函数。
所以进程=PCB+地址空间+页表+代码和数据
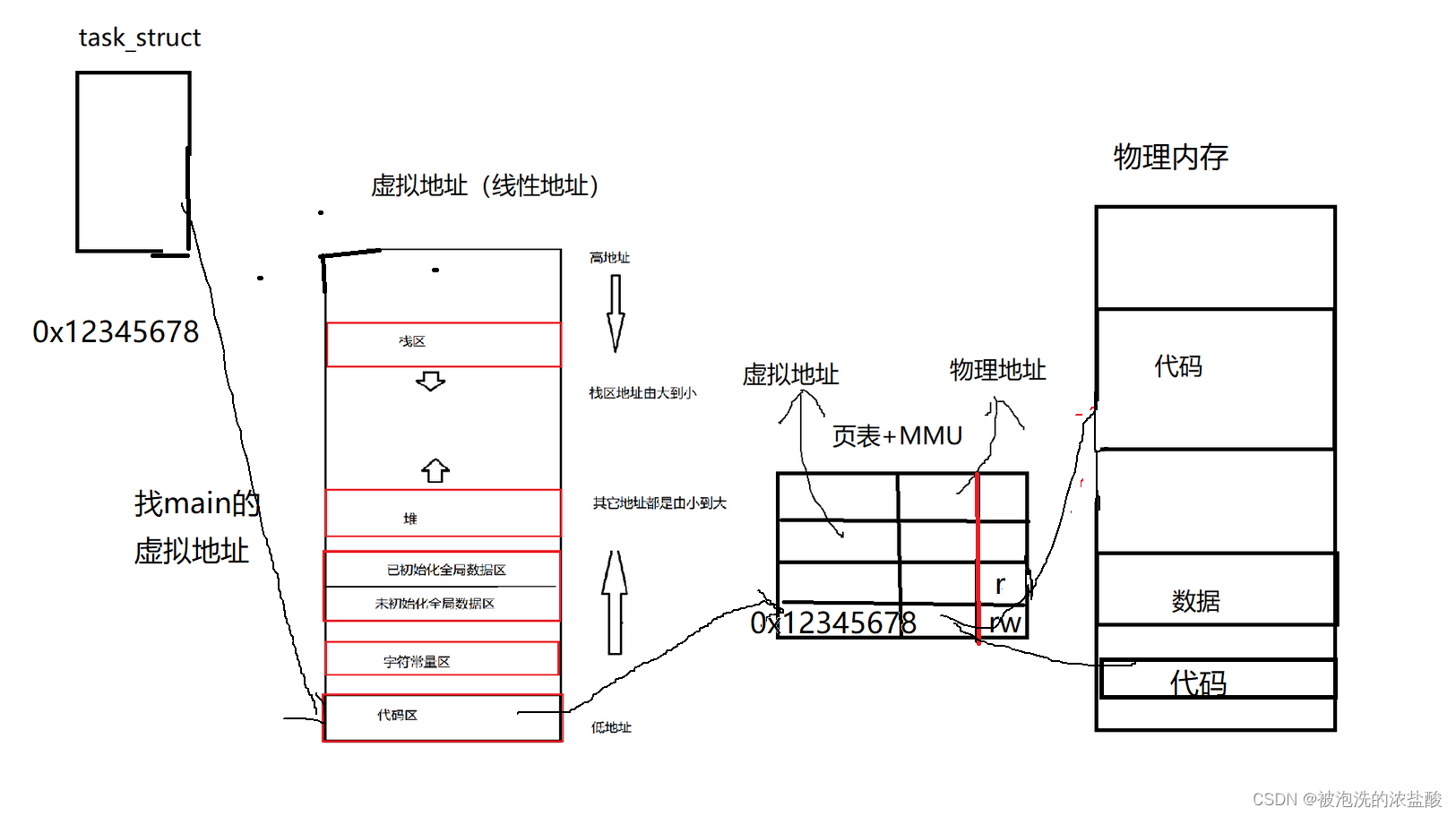
所以回归上面的问题,为什么父子进程的结果已经不一样了,但是他们指向的空间还是一样的?
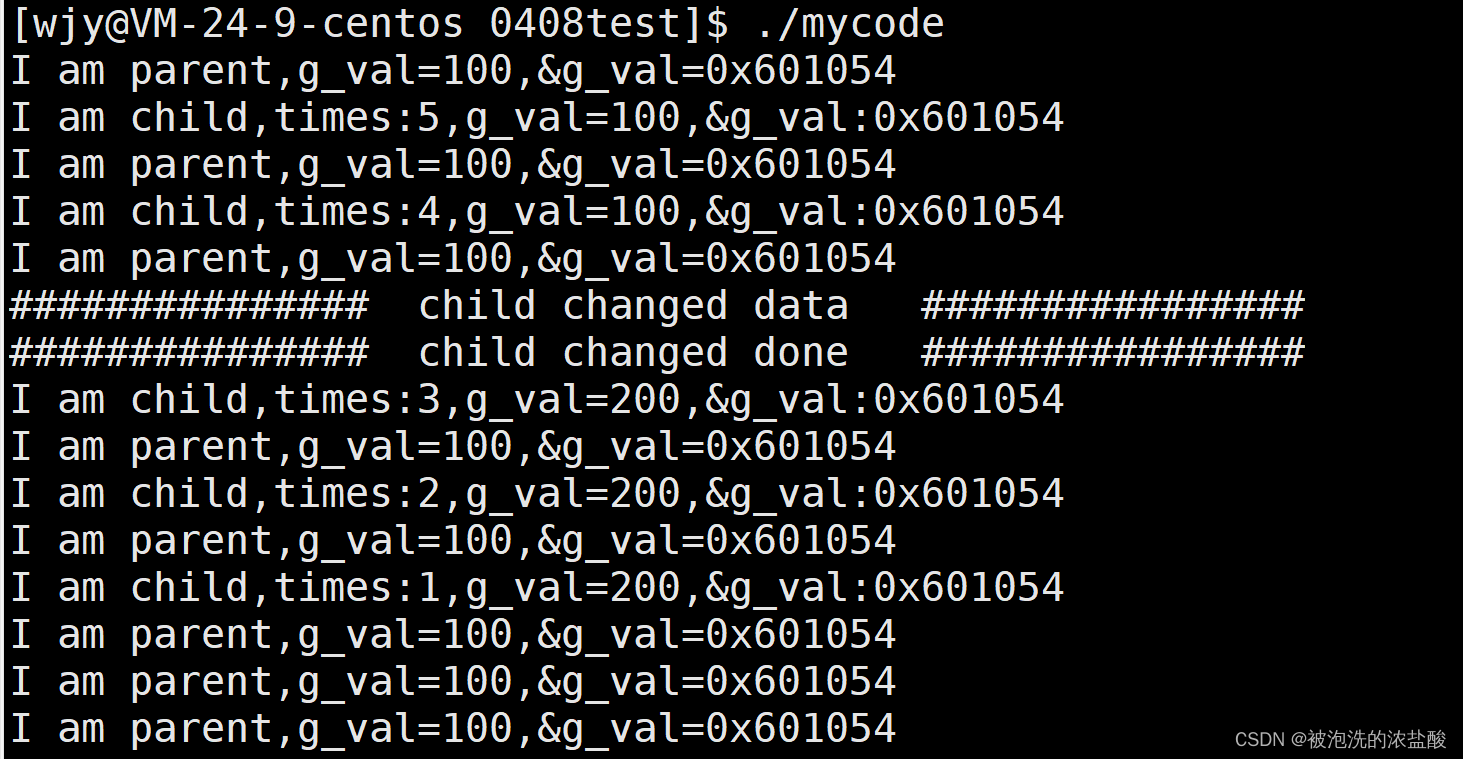
子进程的创建是以父进程为模板的,所以父子共用一份代码,它们所指向的物理地址也是一样的(红色实线和红色虚线),同样指向虚拟地址也是一样的。当子进程发生改变,进程具有独立性,发生了写时拷贝,这时候子进程指向的物理空间也发生改变(蓝色线),但是映射这些物理地址的页表中的虚拟地址没有发生改变。所以上面问题代码所指向的同一个地址是虚拟地址。
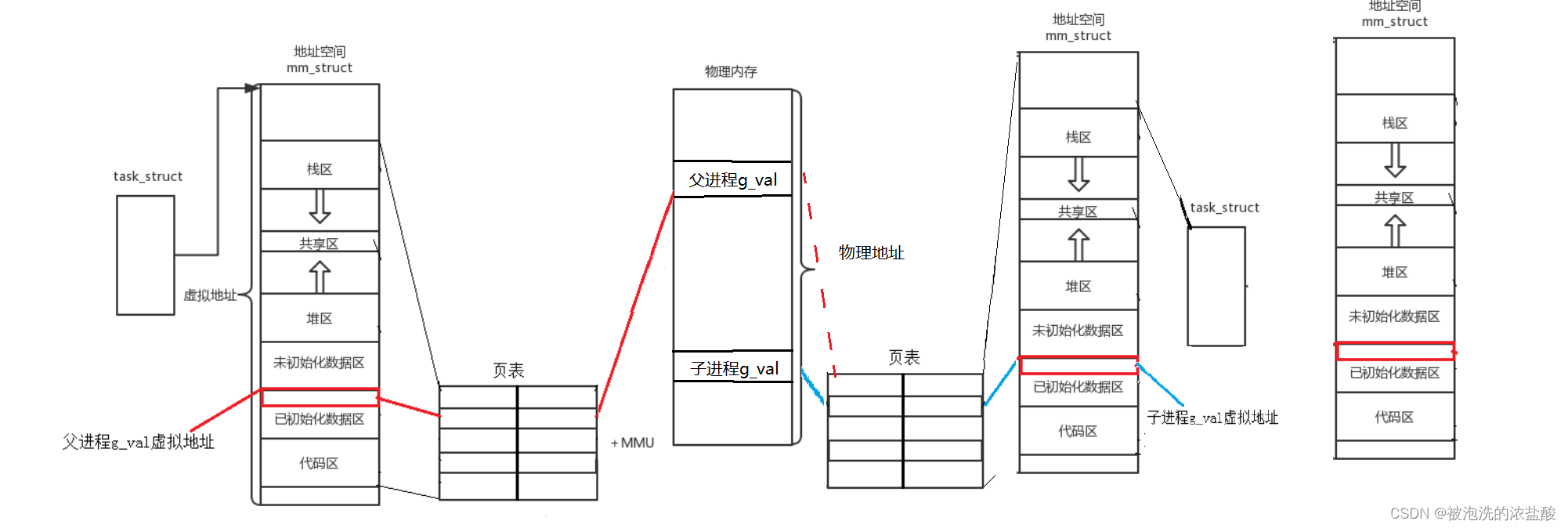
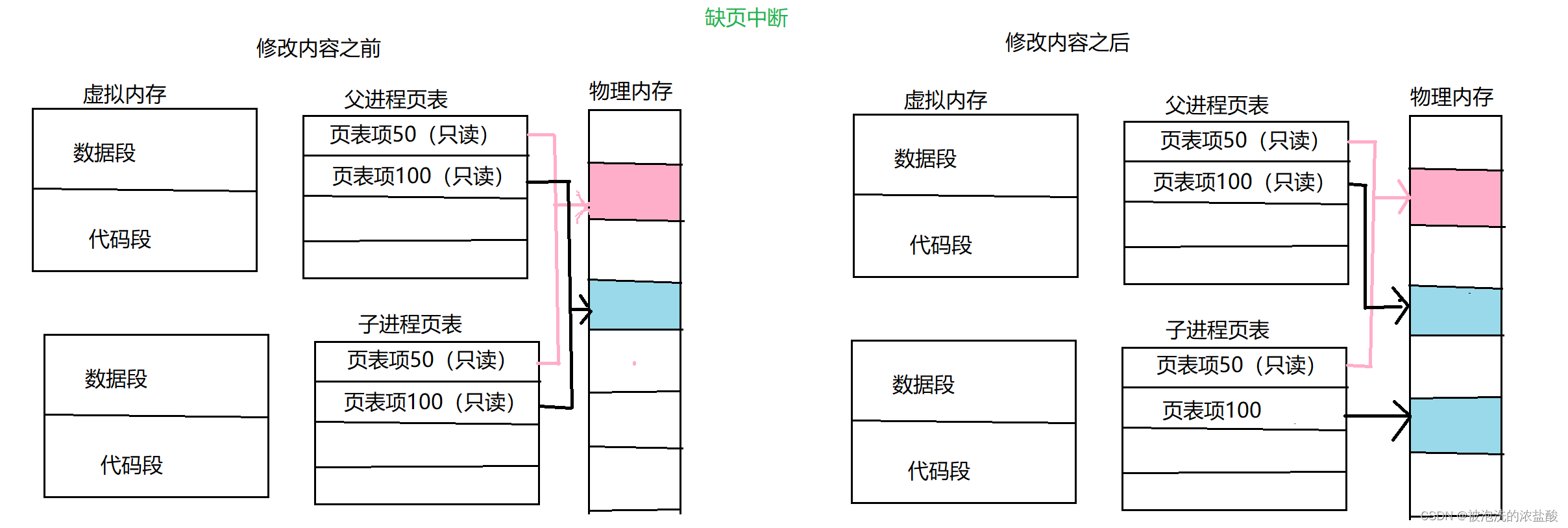
所有的只读数据,一般只有一份,比如定义两个指针,两个指针指向的内容都是一样的字符串,那么他们地址测试之后,也是一样的 。操作系统维护一份是成本最低的。
这也是缺页中断的表现。本来父子进程共享一份代码,会读取同一个物理地址,当子进程要进行改变的时候,操作系统会对子进程进行中断,让页表指向的物理地址变成一块新的空间之后,再让子进程继续运行。而在中断的这一过程,子进程并没有发觉操作系统让你中断了,就像时间静止。在这之后,子进程写时拷贝和父进程分开了,可以进行写操作了。
[wjy@VM-24-9-centos 0408test]$ cat mytest.c
#include <stdio.h>
int main()
{
char* str="hello world";
char* p="hello world";
printf("%p\n",str);
printf("%p\n",p);
}
[wjy@VM-24-9-centos 0408test]$ ./mytest
0x400610
0x400610
虚拟地址的其他结构
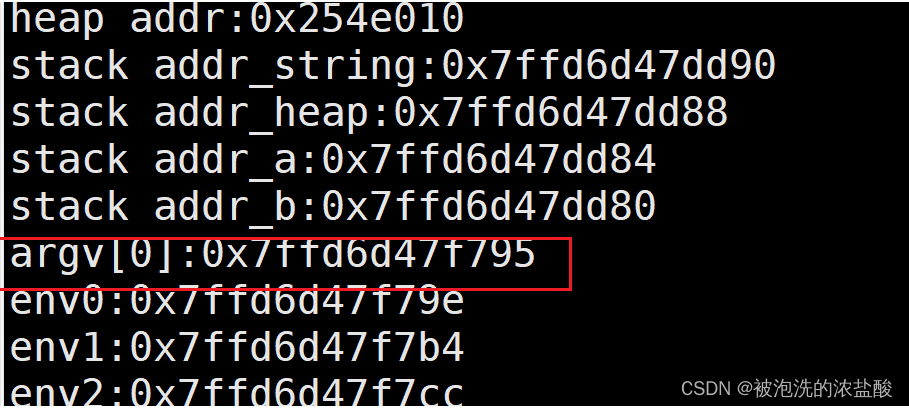
除了上面的虚拟地址结构,还有命令行参数和环境变量,他们也有地址。
当我们在原有代码上增加了命令行参数和环境变量,并将它们的地址打印出来,发现命令行参数和环境变量的地址比栈要大,也就说明命令行参数和环境变量的地址更高
int g_unval;
int g_val=100;
int main(int argc,char* argv[],char* env[])
{
const char* s="hello world";
printf("code addr:%p\n",main);//代码区
printf("string rdonly addr:%p\n",s);//(字符串)常量区
printf("uninit addr:%p\n",&g_unval);//未初始化数据区
printf("init addr:%p\n",&g_val);//初始化数据区
char* heap =(char*)malloc(10);
printf("heap addr:%p\n",heap);//堆
printf("stack addr_string:%p\n",&s);//栈--栈上的临时空间
printf("stack addr_heap:%p\n",&heap);
int a=10,b=20;
printf("stack addr_a:%p\n",&a);//验证栈区地址是由大到小
printf("stack addr_b:%p\n",&b);
for(int i=0;argv[i];i++)
{
printf("argv[%d]:%p\n",i,argv[i]);
}
for(int i=0;env[i];++i)
{
printf("env%d:%p\n",i,env[i]);
}
return 0;
}
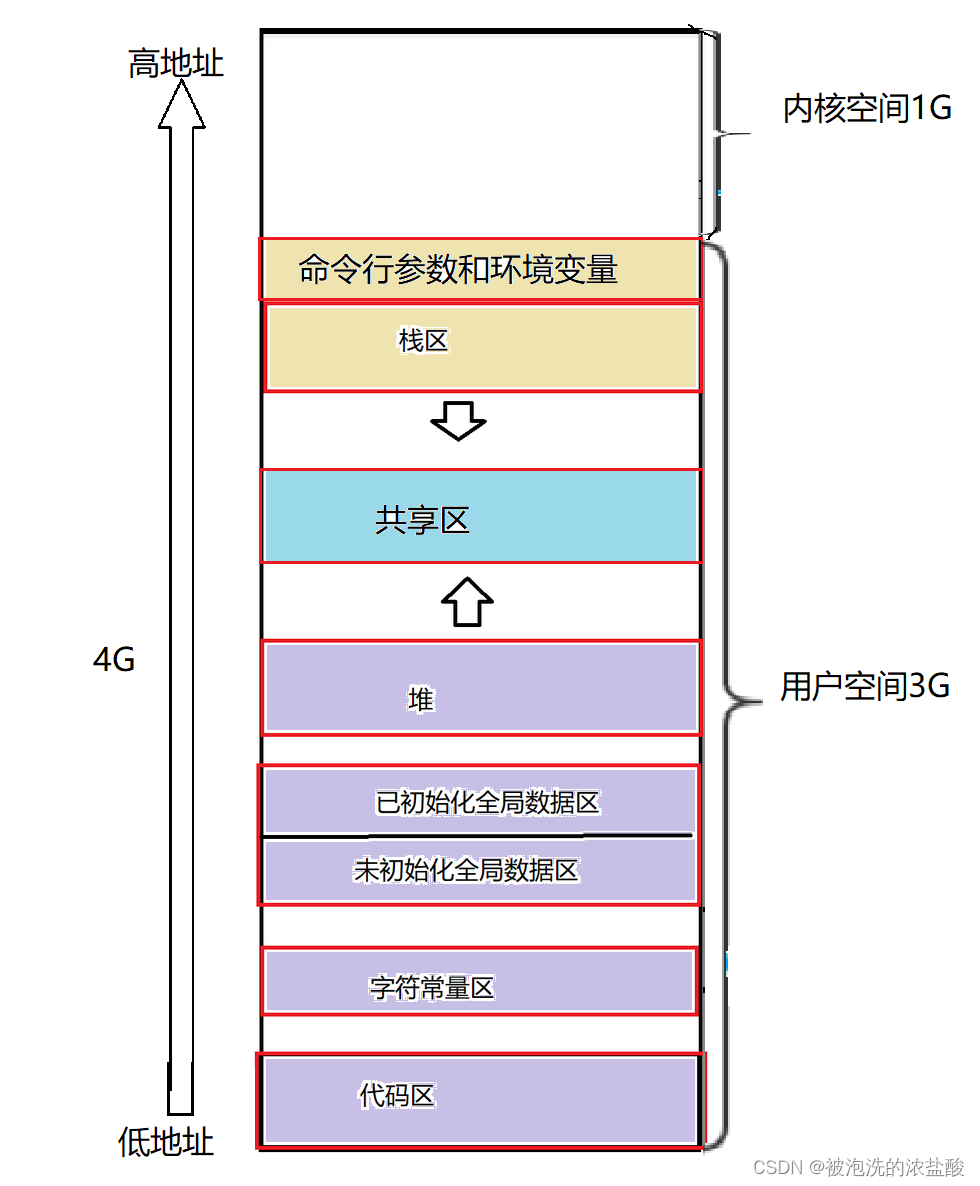
所以更准确的图是这样的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









