




目录
思路:
1.通过输入的网页链接进行下载源码,比如这个链接
https:/xxxx/s/PZMAOvbgmnJUdjAQ3E9xig?scene=1&click_id=2
2.然后根据源码是否对应上面图片的格式来提取图片链接,然后下载到当前脚本文件所在的文件夹image中(自己新建)
3.最后下载保存在有日期命名的文件中,名称用1.2.3这样的命名。后缀格式为.png
效果:
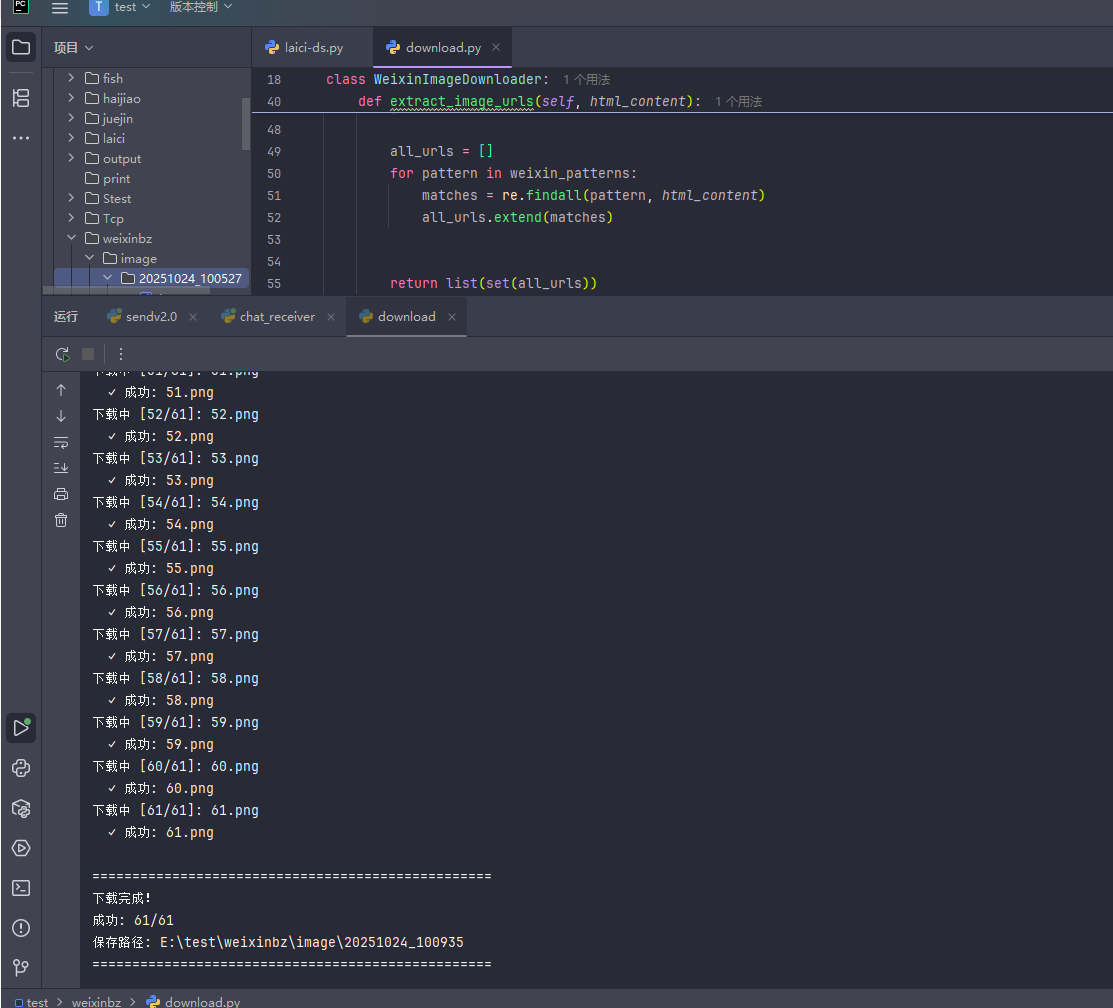
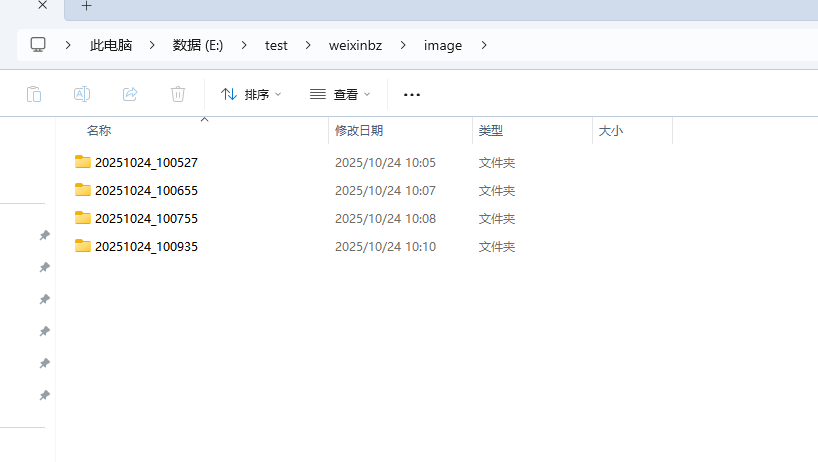
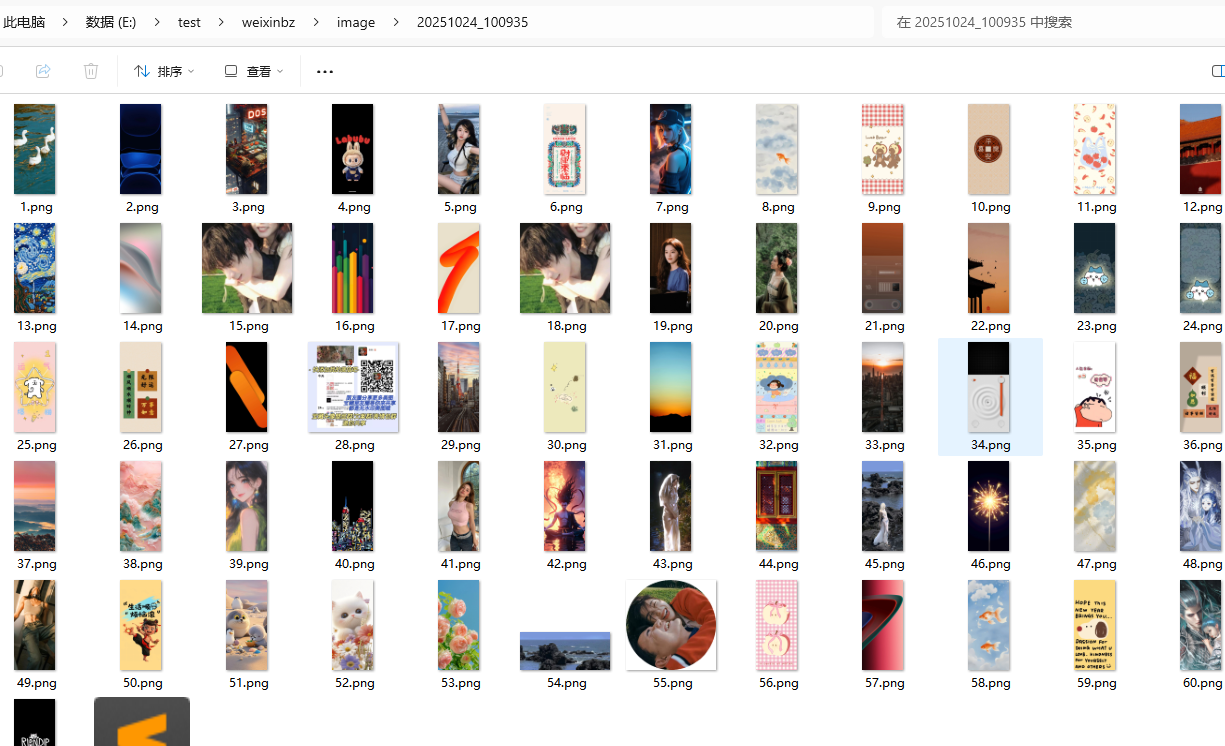
代码:
"""
@Project :test
@File :download.py
@IDE :PyCharm
@Author :随风万里无云
@Date :2025/10/24 10:04
"""
import os
import re
import requests
from datetime import datetime
from urllib.parse import urljoin, urlparse
import time
import json
class WeixinImageDownloader:
def __init__(self):
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Referer': 'https://mp.weixin.qq.com/'
})
def get_html_content(self, url):
try:
response = self.session.get(url, timeout=10)
response.raise_for_status()
if response.encoding == 'ISO-8859-1':
response.encoding = response.apparent_encoding or 'utf-8'
return response.text
except Exception as e:
raise Exception(f"获取网页内容失败: {e}")
def extract_image_urls(self, html_content):
weixin_patterns = [
r'data-src="(https?://mmbiz\.qpic\.cn/[^"]+)"',
r'src="(https?://mmbiz\.qpic\.cn/[^"]+)"',
r'data-src="(https?://[^"]*wx_fmt=[^"]*)"',
]
all_urls = []
for pattern in weixin_patterns:
matches = re.findall(pattern, html_content)
all_urls.extend(matches)
return list(set(all_urls))
def download_image(self, url, filepath):
try:
response = self.session.get(url, timeout=15, stream=True)
response.raise_for_status()
content_type = response.headers.get('content-type', '')
if not content_type.startswith('image/'):
return False, f"不是图片类型: {content_type}"
with open(filepath, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
return True, "下载成功"
except Exception as e:
return False, str(e)
def run(self, url):
print(f"开始处理: {url}")
today = datetime.now().strftime("%Y%m%d_%H%M%S")
save_dir = os.path.join("image", today)
os.makedirs(save_dir, exist_ok=True)
try:
html_content = self.get_html_content(url)
print("✓ 网页源码获取成功")
image_urls = self.extract_image_urls(html_content)
if not image_urls:
print("✗ 未找到符合格式的图片链接")
return
print(f"✓ 找到 {len(image_urls)} 个图片链接")
success_count = 0
download_log = []
for i, img_url in enumerate(image_urls, 1):
filename = f"{i}.png"
filepath = os.path.join(save_dir, filename)
print(f"下载中 [{i}/{len(image_urls)}]: {filename}")
success, message = self.download_image(img_url, filepath)
if success:
print(f" ✓ 成功: {filename}")
success_count += 1
else:
print(f" ✗ 失败: {message}")
download_log.append({
'index': i,
'url': img_url,
'filename': filename,
'success': success,
'message': message
})
time.sleep(0.5)
log_file = os.path.join(save_dir, "download_log.json")
with open(log_file, 'w', encoding='utf-8') as f:
json.dump(download_log, f, ensure_ascii=False, indent=2)
print(f"\n{'=' * 50}")
print(f"下载完成!")
print(f"成功: {success_count}/{len(image_urls)}")
print(f"保存路径: {os.path.abspath(save_dir)}")
print(f"{'=' * 50}")
except Exception as e:
print(f"处理失败: {e}")
def main():
downloader = WeixinImageDownloader()
url = input("请输入微信公众号文章链接: ").strip()
if not url:
print("使用示例链接...")
url = "https://mp.weixin.qq.com/s/PZMAOvbgmnJUdjAQ3E9xig?scene=1&click_id=2"
if not url.startswith(('http://', 'https://')):
print("错误:请输入有效的URL")
return
downloader.run(url)
if __name__ == "__main__":
main()后续计划优化:
动态下载进度条
保证只下载的是壁纸,不包含其他图片
移除json保存的文件
打包为exe或apk
注意事项:
如果出现代码报错,应该是没安装依赖库,下面两条命令选一条,推荐第二
只需要安装这一个库
pip install requests
或者使用清华镜像源
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple/


















 2466
2466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









