







文章目录
前言
本综合指南主要参考《A Comprehensive Guide to Data Exploration》进行编写,用作日常学习。原文中将缺失值插补与异常值处理两大块作为数据探索部分,通过查阅资料及结合数据分析经验,本文将变量识别、单变量分析、双变量分析划为探索性数据分析(EDA) 部分,将缺失值插补、异常值处理、变量转化、特征/变量构造、特征筛选及降维划为特征工程部分。
一、探索性数据分析(EDA)
对于数据挖掘相关任务,数据输入的质量决定了输出的质量。数据探索、清理和准备可能占用总项目时间的70%。在这里花费大量时间和精力是有意义的。
EDA主要包括如下三个部分:变量识别、单变量分析、双变量分析。
1.变量识别
首先,确定预测变量(输入)和目标变量(输出)。接下来,确定变量的数据类型和类别。
示例:- 假设,我们想要预测,学生是否会打板球(参考下面的数据集)。在这里,您需要识别预测变量、目标变量、变量的数据类型和变量的类别。
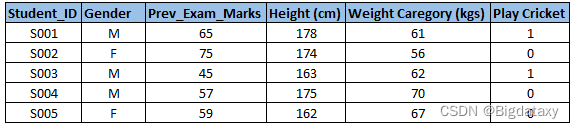
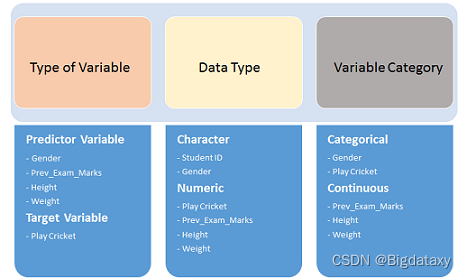
2.单变量分析
执行单变量分析的方法取决于变量类型是分类类型还是连续类型。下面是分类变量和连续变量的方法和统计度量:
- 连续变量:在连续变量的情况下,需要了解变量的集中趋势和扩散。可通过各种统计指标可视化方法测量,如下所示:

- 分类变量:对于分类变量,将使用频率表来了解每个类别的分布。还可以读取每个类别下值的百分比。可以使用两个指标来衡量它,即针对每个类别的计数和计数百分比。条形图可用作可视化效果。
注意:单变量分析还用于突出显示缺失值和异常值。
3.双变量分析
双变量分析是找出两个变量之间的关系。在预定义的显著性水平上寻找变量之间的关联和分离。我们可以对分类变量和连续变量的任意组合进行双变量分析。组合可以是:分类和分类,分类和连续以及连续和连续。在分析过程中,使用不同的方法来处理这些组合。
- 连续和连续: 在两个连续变量之间进行双变量分析时,应该查看散点图。这是找出两个变量之间关系的好方法。散点图的模式指示变量之间的关系。关系可以是线性的,也可以是非线性的。
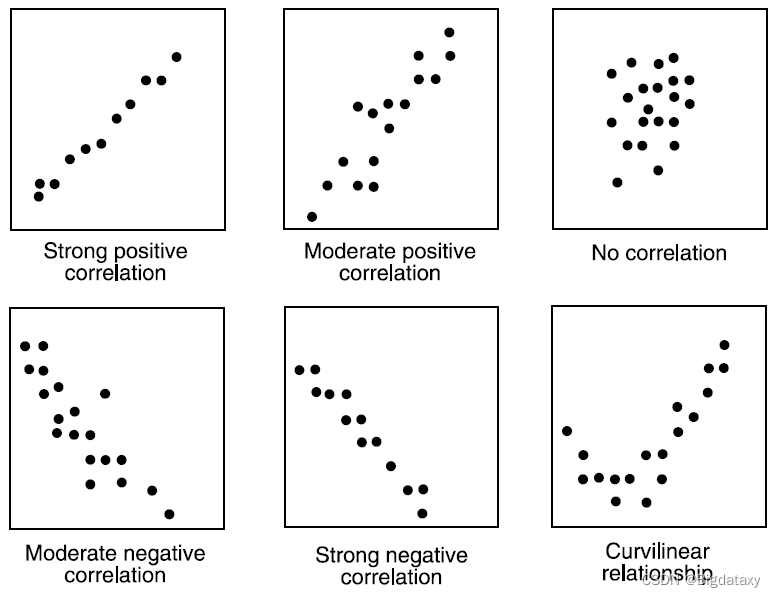
散点图显示两个变量之间的关系,但不指示它们之间的关系强度。为了找到关系的强度,我们使用相关性。相关性在 -1 和 +1 之间变化。
相关性公式推导,查看博客协方差,协方差矩阵理论(机器学习)
-
分类和分类: 要找到两个分类变量之间的关系,可以使用以下方法:
-
双向表:可以通过创建计数和计数的双向表来开始分析关系。行表示一个变量的类别,列表示另一个变量的类别。我们显示了行和列类别的每个组合中可用的观测值的计数或计数百分比。
-
堆积柱形图: 这种方法更像是双向表的视觉形式。

-
卡方检验:该检验用于推导变量之间关系的统计显著性。此外,它还测试样本中的证据是否足够强大,可以概括更大人群的关系。卡方基于双向表中一个或多个类别中预期频率和观测频率之间的差异。它返回计算的卡方分布的概率和自由度。
-
-
分类和连续: 在探索分类变量和连续变量之间的关系时,可以为每个级别的分类变量绘制箱形图。如果水平数量较少,则不会显示统计显著性。要查看统计显著性,我们可以执行 Z 检验、T 检验或方差分析。
- Z 检验/ T 检验:-任一检验均值评估两组的均值在统计上是否彼此不同。
<
- Z 检验/ T 检验:-任一检验均值评估两组的均值在统计上是否彼此不同。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











