







目录
常见的二叉树类型
二叉树是一种树形结构:
1
/ \
2 3
/ / \
4 5 6
/ \
7 81、每个节点下方直接相连的节点称为子节点,上方直接相连的节点称为父节点。比方说节点 3 的父节点是 1,左子节点是 5,右子节点是 6;节点 5 的父节点是 3,左子节点是 7,没有右子节点。
2、我们称最上方那个没有父节点的节点 1 为根节点,称最下层没有子节点的节点 4、7、8 为叶子节点。
3、我们称从根节点到最下方叶子节点经过的节点个数为二叉树的最大深度/高度,上面这棵树的最大深度是 4,即从根节点 1 到叶子节点 7 或 8 的路径上的节点个数。
满二叉树
满二叉树就是每一层节点都是满的,整棵树像一个正三角形:
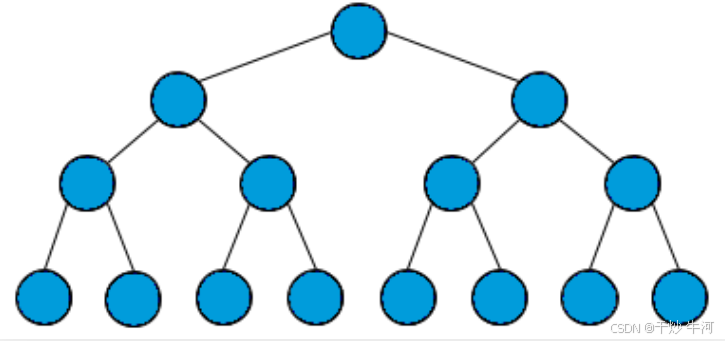
满二叉树有个优势,就是它的节点个数很好算。假设深度为 h,那么总节点数就是 2^h - 1(等比数列求和)。
完全二叉树
完全二叉树是指,二叉树的每一层的节点都紧凑靠左排列,且除了最后一层,其他每层都必须是满的: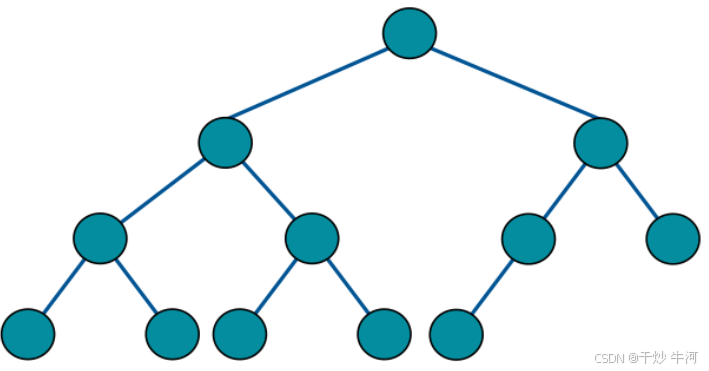
不难看出,满二叉树是一种特殊的完全二叉树。
完全二叉树的特点:由于它的节点紧凑排列,如果从左到右从上到下对它的每个节点编号,那么父子节点的索引存在明显的规律。因此完全二叉树可以用数组来存储,不需要真的构建链式节点。
完全二叉树还有个比较难发觉的性质:完全二叉树的左右子树也是完全二叉树。
或者更准确地说应该是:完全二叉树的左右子树中,至少有一棵是满二叉树。
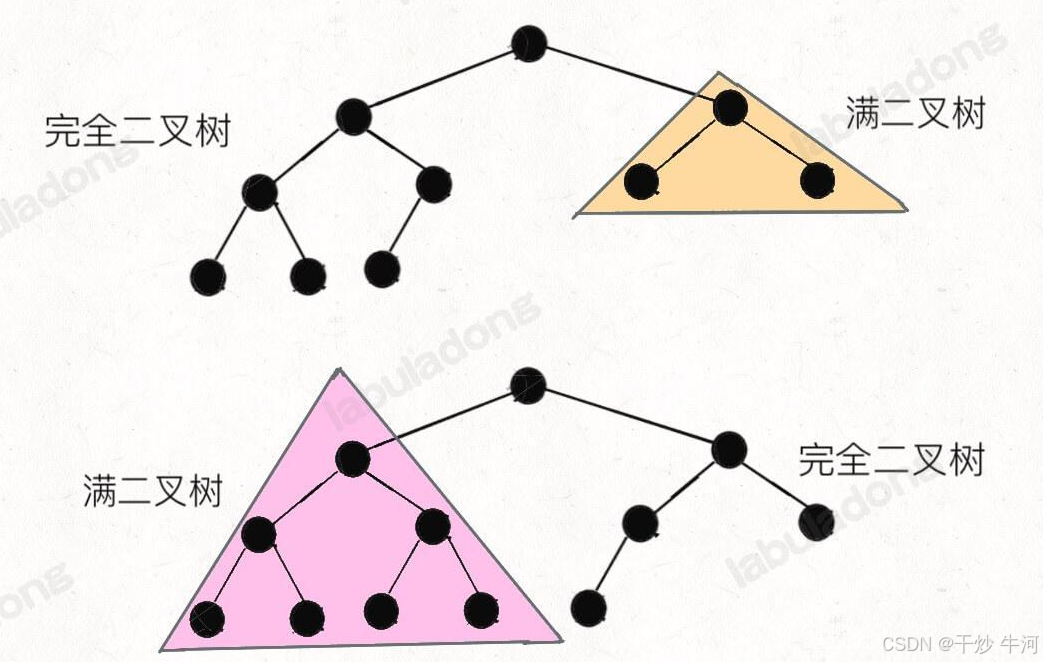
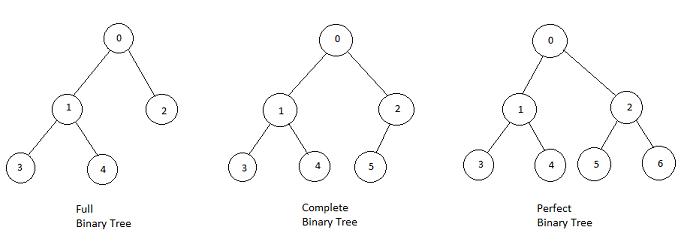
中英文的定义有区别
关于完全二叉树和满二叉树的定义,中文语境和英文语境似乎有点区别。
我们说的完全二叉树对应英文 Complete Binary Tree,这个没问题,说的是同一种树。
我们说的满二叉树,按理说应该翻译成 Full Binary Tree 对吧,但其实不是,满二叉树的定义对应英文的 Perfect Binary Tree。
而英文中的 Full Binary Tree 是指一棵二叉树的所有节点要么没有孩子节点,要么有两个孩子节点。
以上定义出自 wikipedia。
平衡二叉树
平衡二叉树(Balanced Binary Tree)是一种特殊的二叉树,它的「每个节点」的左右子树的高度差不超过 1。要注意是每个节点,而不仅仅是根节点。
比如下面这棵二叉树树,根节点 1 的左子树高度是 2,右子树高度是 3;节点 2 的左子树高度是 1,右子树高度是 0;节点 3 的左子树高度是 2,右子树高度是 1,以此类推,每个节点的左右子树高度差都不超过 1,所以这是一棵平衡二叉树:
1
/ \
2 3
/ / \
4 5 6
\
7下面这棵树就不是平衡二叉树,因为节点 2 的左子树高度是 2,右子树高度是 0,高度差超过 1,不符合条件:
1
/ \
2 3
/ / \
4 5 6
\ \
8 7假设平衡二叉树中共有 NN 个节点,那么平衡二叉树的高度是 O(logN)。
二叉搜索树
二叉搜索树(Binary Search Tree,简称 BST)是一种很常见的二叉树,它的定义是:
对于树中的每个节点,其左子树的每个节点的值都要小于这个节点的值,右子树的每个节点的值都要大于这个节点的值。你可以简单记为「左小右大」。
例如,下面这棵树就是一棵 BST:
7
/ \
4 9
/ \ \
1 5 10节点 7 的左子树所有节点的值都小于 7,右子树所有节点的值都大于 7;节点 4 的左子树所有节点的值都小于 4,右子树所有节点的值都大于 4,以此类推。
相反的,下面这棵树就不是 BST:
7
/ \
4 9
/ \ \
1 8 10BST 是非常常用的数据结构。因为左小右大的特性,可以让我们在 BST 中快速找到某个节点,或者找到某个范围内的所有节点,这是 BST 的优势所在。
比方说,对于一棵普通的二叉树,其中的节点大小没有任何规律可言,那么你要找到某个值为 x 的节点,只能从根节点开始遍历整棵树。
而对于 BST,你可以先对比根节点和 x 的大小关系,如果 x 比根节点大,那么根节点的整棵左子树就可以直接排除了,直接从右子树开始找,这样就可以快速定位到值为 x 的那个节点。
二叉树的实现方式
最常见的二叉树就是类似链表那样的链式存储结构,每个二叉树节点有指向左右子节点的指针,这种方式比较简单直观。力扣/LeetCode 上给你输入的二叉树一般都是用这种方式构建的,二叉树节点类 TreeNode 一般长这样:
class TreeNode {
public:
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
};
// 你可以这样构建一棵二叉树:
TreeNode* root = new TreeNode(1);
root->left = new TreeNode(2);
root->right = new TreeNode(3);
root->left->left = new TreeNode(4);
root->right->left = new TreeNode(5);
root->right->right = new TreeNode(6);
// 构建出来的二叉树是这样的:
// 1
// / \
// 2 3
// / / \
// 4 5 6另外,在一般的算法题中,我们可能会把实际问题抽象成二叉树结构,但我们并不需要真的用 TreeNode 创建一棵二叉树出来,而是直接用类似 哈希表 的结构来表示二叉树/多叉树。
1
/ \
2 3
/ / \
4 5 6对于以上树可以用一个哈希表,其中的键是父节点 id,值是子节点 id 的列表(每个节点的 id 是唯一的),那么一个键值对就是一个多叉树节点了,这棵多叉树就可以表示成这样:
// 1 -> {2, 3}
// 2 -> {4}
// 3 -> {5, 6}
unordered_map<int, vector<int>> tree;
tree[1] = {2, 3};
tree[2] = {4};
tree[3] = {5, 6};这样就可以模拟和操作二叉树/多叉树结构,后文讲到图论的时候你就会知道,它有一个新的名字叫做邻接表。
二叉树的遍历
二叉树的遍历算法主要分为递归遍历和层序遍历两种,都有代码模板。递归代码模板可以延伸出后面要讲的 DFS 算法、回溯算法,层序代码模板可以延伸出后面要讲的 BFS 算法,所以我经常强调二叉树结构的重要性。
大家熟知的先序遍历、中序遍历、后序遍历,都属于二叉树的递归遍历,只不过是把自定义代码插入到了代码模板的不同位置而已。
递归遍历(dfs)
先序遍历(根左右):
// 基本的二叉树节点
class TreeNode {
public:
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
};
// 二叉树的递归遍历框架
void traverse(TreeNode* root) {
if (root == nullptr) {
return;
}
traverse(root->left);
traverse(root->right);
}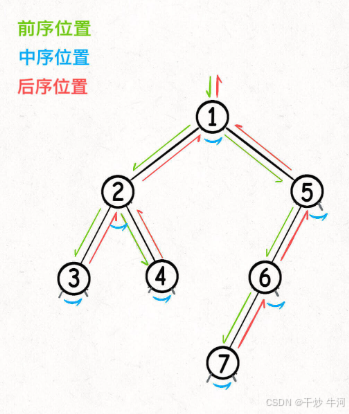
对于不同的遍历位置根遍历代码如下:
// 二叉树的遍历框架
void traverse(TreeNode* root) {
if (root == nullptr) {
return;
}
// 前序位置
traverse(root->left);
// 中序位置
traverse(root->right);
// 后序位置
}层序遍历(bfs)
上面讲的递归遍历是依赖函数堆栈递归遍历二叉树的,遍历顺序是从最左侧开始,一列一列地走到最右侧。
二叉树的层序遍历,顾名思义,就是一层一层地遍历二叉树。这个遍历方式需要借助队列来实现,而且根据不同的需求,主要有三种不同的写法,下面一一列举。
写法一:
void levelOrderTraverse(TreeNode* root) {
if (root == nullptr) {
return;
}
std::queue<TreeNode*> q;
q.push(root);
while (!q.empty()) {
TreeNode* cur = q.front();
q.pop();
// 访问 cur 节点
std::cout << cur->val << std::endl;
// 把 cur 的左右子节点加入队列
if (cur->left != nullptr) {
q.push(cur->left);
}
if (cur->right != nullptr) {
q.push(cur->right);
}
}
}这种写法的优缺点
这种写法最大的优势就是简单。每次把队头元素拿出来,然后把它的左右子节点加入队列,就完事了。
但是这种写法的缺点是,无法知道当前节点在第几层。知道节点的层数是个常见的需求,比方说让你收集每一层的节点,或者计算二叉树的最小深度等等。
所以这种写法虽然简单,但用的不多,下面介绍的写法会更常见一些。
写法二:
void levelOrderTraverse(TreeNode* root) {
if (root == nullptr) {
return;
}
queue<TreeNode*> q;
q.push(root);
// 记录当前遍历到的层数(根节点视为第 1 层)
int depth = 1;
while (!q.empty()) {
int sz = q.size();
for (int i = 0; i < sz; i++) {
TreeNode* cur = q.front();
q.pop();
// 访问 cur 节点,同时知道它所在的层数
cout << "depth = " << depth << ", val = " << cur->val << endl;
// 把 cur 的左右子节点加入队列
if (cur->left != nullptr) {
q.push(cur->left);
}
if (cur->right != nullptr) {
q.push(cur->right);
}
}
depth++;
}
}注意队列的长度 sz 一定要在循环开始前保存下来,因为在循环过程中队列的长度是会变化的,不能直接用 q.size() 作为循环条件。
写法三:
回顾写法二,我们每向下遍历一层,就给 depth 加 1,可以理解为每条树枝的权重是 1,二叉树中每个节点的深度,其实就是从根节点到这个节点的路径权重和,且同一层的所有节点,路径权重和都是相同的。
那么假设,如果每条树枝的权重和可以是任意值,现在让你层序遍历整棵树,打印每个节点的路径权重和,你会怎么做?
这样的话,同一层节点的路径权重和就不一定相同了,写法二这样只维护一个 depth 变量就无法满足需求了。
写法三就是为了解决这个问题,在写法一的基础上添加一个 State 类,让每个节点自己负责维护自己的路径权重和,代码如下:
class State {
public:
TreeNode* node;
int depth;
State(TreeNode* node, int depth) : node(node), depth(depth) {}
};
void levelOrderTraverse(TreeNode* root) {
if (root == nullptr) {
return;
}
queue<State> q;
// 根节点的路径权重和是 1
q.push(State(root, 1));
while (!q.empty()) {
State cur = q.front();
q.pop();
// 访问 cur 节点,同时知道它的路径权重和
cout << "depth = " << cur.depth << ", val = " << cur.node->val << endl;
// 把 cur 的左右子节点加入队列
if (cur.node->left != nullptr) {
q.push(State(cur.node->left, cur.depth + 1));
}
if (cur.node->right != nullptr) {
q.push(State(cur.node->right, cur.depth + 1));
}
}
}这样每个节点都有了自己的 depth 变量,是最灵活的,可以满足所有 BFS 算法的需求。但是由于要额外定义一个 State 类比较麻烦,所以非必要的话,用写法二就够了。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









